Amazon Web Services ブログ
Amazon FinSpace を用いてトレードストラテジーのための What-If シナリオ分析を実行する方法
本投稿は AWSのソリューションアーキテクトである Diego Colombatto と Oliver Steffmann による寄稿を翻訳したものです。
はじめに
以前のブログ記事では、AWS で機械学習ベースのトレードストラテジーをバックテストするためのアーキテクチャについて説明しました。このアーキテクチャの主要なコンポーネントの1つは、データマネジメントと分析のためのコンポーネントです。
特定のユースケースに応じて、これを実装するためのさまざまな選択肢があります。多くの企業は、データレイクに基づくソリューションを採用しており、最近ではレイクハウスアーキテクチャを採用しています。どのようなアプローチを選んでも、ソリューションは次の主要な機能領域(データマネジメント、データガバナンス、データ分析、機械学習)をカバーする必要があります。機械学習モデルの開発には、データ探索やデータ準備などの機能が必要です。さらに、顧客には、さまざまなソースからの金融データをクエリして結合するためのより高度なツールと、指標や金融時系列データを簡単に操作できる方法が必要です。
Amazon FinSpaceのローンチにより、金融データを扱うための安全、スケーラブルなデータ管理、および分析基盤をセットアップするための付加価値につながらない重い作業が不要になりました。利用者はマネージドサービスを活用できるため、これらのタスクは以前よりはるかに簡単になります。Amazon FinSpace には、分析や機械学習を目的としたデータ準備のための、タイムバーやボリンジャーバンドなど、100以上の関数ライブラリも含まれています。
アナリスト(クオンツを含む)がデータからインサイトを得るための一般的な方法の1つは、 What-If シナリオを実行することです。これは、分析される数学的モデルの潜在的な結果とリスクを調査するために広く使用されています。トレードストラテジーに適用すると、アナリストは過去のパフォーマンス(売買損益(PNL)、シャープレシオなど)をさまざまなストラテジー構成で比較し、取引のストラテジー決定のために機械学習モデルを使用することができます。追加のシナリオでは、異なる時間枠(終値 対 1分間の時価データなど)や、オルタナティブデータやニュース情報にも依存するストラテジーもカバーできます。
ストラテジー構成に関しては、移動平均収束発散(MACD:マックディー)のような統計的アプローチを考慮すると、設定値では、移動平均ごとに考慮すべき期間の数が考慮されます。一方、機械学習ベースのアプローチでは、機械学習アルゴリズム、特徴量、または学習に使用されるハイパーパラメーターが考慮されます。このブログでは、Amazon FinSpace でのトレードストラテジーのバックテストを再検討し、What-if シナリオを実行するための機能を拡張します。
ワークフロー
次の図は、このブログで説明されているソリューションの概要レベルのワークフローを示しています。

図 1: ソリューションの概要レベルの機能ワークフロー
- データの読み込み: 金融データが読み込まれ、探索に使用できるようになります。
- データの準備: データはモデルトレーニング用とバックテスト用に準備されます。
- モデルトレーニング: さまざまなアプローチが利用可能です。たとえば、単一のMLアルゴリズムを異なる構成で使用したり、同様の構成で異なる機械学習アルゴリズムを使用したり、混在したアプローチも選択できます。どのアプローチを使用する場合でも、インスタンスごとに1つのストラテジーが作成され、次のステップで使用されます。
- バックテストストラテジー: 各ストラテジーは、過去の金融時系列データに基づいてテストされます。
- ベンチマークストラテジー: ストラテジー構成ごとに、パフォーマンスメトリックを計算します。
- What-If 出力: すべてのストラテジー構成がテストされたら、最適なリスク/リターンメトリックを持つ構成を選択します。
アーキテクチャ
次の図は、ハイレベルのアーキテクチャを示しています。 Amazon FinSpace が提供するマネージド Spark クラスターと Jupyter notebook を使用しています。
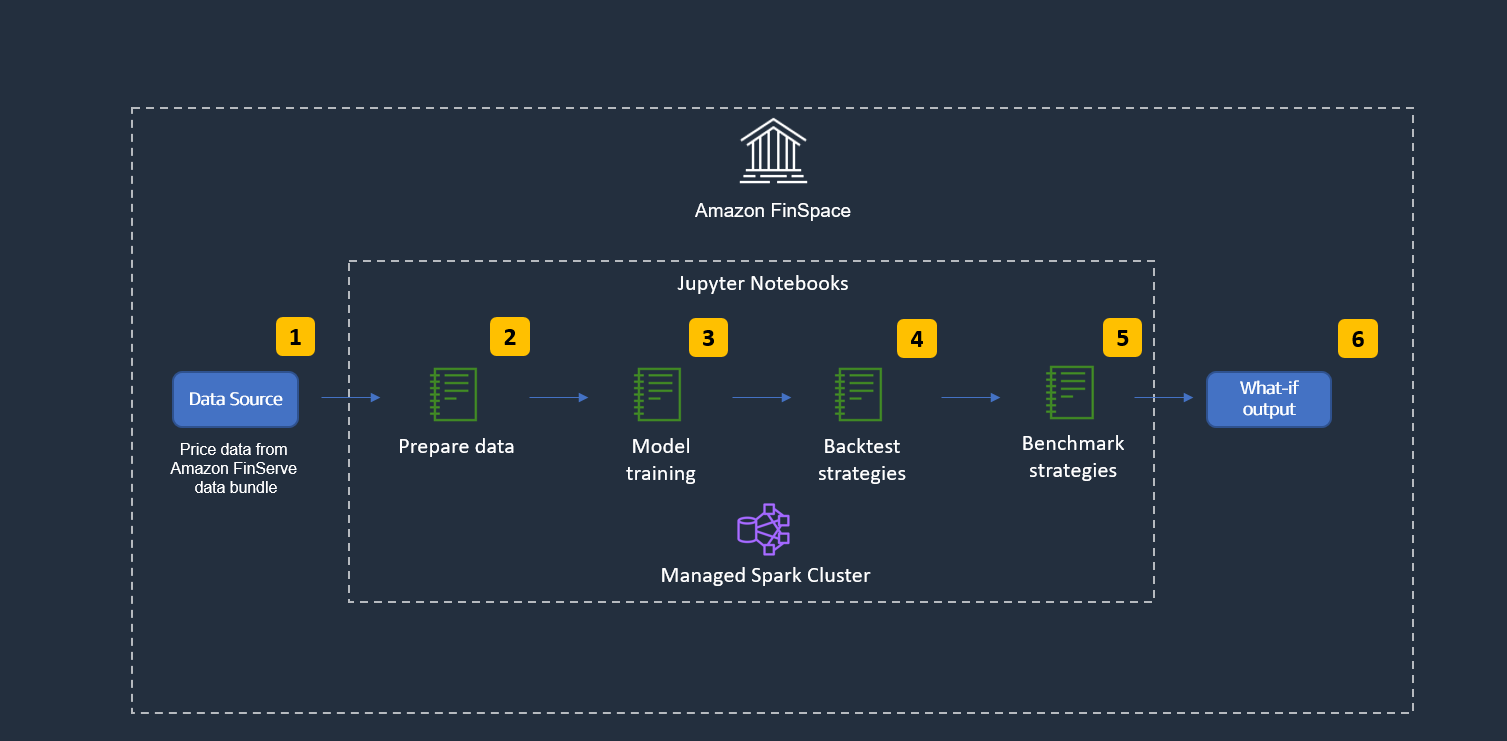
図 2: ソリューションに関するハイレベルなテクニカルワークフロー
- データの読み込み: キャピタルマーケットのサンプルデータバンドルの一部として提供される 1 分間隔の詳細な株式価格データをロードします。これは、AWS マネジメントコンソールから Amazon FinSpace 環境にインストールできる追加アイテムです。
- データの準備: モデルトレーニングとバックテスト用にデータセットをすばやく分析して準備し、Amazon FinSpace 関数のいずれかを使用して指数平滑移動平均線 (EMA) を計算します。
- モデルトレーニング: Spark ML を使用して、複数のランダムフォレスト機械学習アルゴリズムを学習します。
- バックテストストラテジー: 実際のバックテストには Backtrader フレームワークを使用し、各ストラテジーはすべてのシナリオで実行されます。
- ベンチマークストラテジー: ベンチマークが完成したら、(PNL に従って)最適なストラテジー構成を出力します。
このアーキテクチャの主な特徴は次のとおりです。
モジュール性と拡張性: このソリューションは、使用されるデータ、ストラテジー、およびストラテジー構成に依存しません。これらのいずれかを変更し、必要に応じて独自のものを使用できます。たとえば、PNL を使用して最適なモデルを獲得しましたが、他の指標も使用できます。このソリューションを拡張して、価格データの代わりに、ニュースデータなどのさまざまな種類のデータを管理するなど、追加の要件に対応することもできます。これは、他の専用の AWS サービスを活用することで実現できます。
弾力性: このソリューションは、変化する需要ニーズ(コンピューティングパワーとストレージ)に迅速に適応でき、”Working with Spark Cluster” ガイドで説明されているように、Spark リソースを簡単かつプログラム的に変更することができます。これは、クラウドソリューションを活用して需要の急増に対応しながら、ワークロードやデータの一部をオンプレミスで維持したいハイブリッドクラウドソリューションを設計する際の重要な側面です。
セキュリティとコンプライアンス: このソリューションは、包括的なセキュリティモデルに準拠し、特定のセキュリティ機能を提供するように設計されています。セキュリティ機能の例としては、Amazon FinSpace ウェブアプリケーションで使用可能なAWS CloudTrail ログ、監査レポートを使用したデータ暗号化(送信中および保存時)、ID オプション(SAML ベースの SSO、監査可能性)などがあります。セキュリティモデルとセキュリティ機能の詳細については、Amazon FinSpace セキュリティガイドを参照してください。
相互運用性: このブログで説明されているソリューションは、標準の PySpark 言語を使用し、Amazon FinSpace Spark クラスターからのみ利用可能な Amazon FinSpace 時系列 API を活用しています。Spark との互換性により、既存の Spark ソリューションを再利用して、弾力性や他の AWS サービス(不正検出やテキスト/ドキュメント分析のための AI サービスなど)との統合を活用できます。また、AWS またはオンプレミスで実行されているアプリケーションと Amazon FinSpace を統合するために使用できる API も提供され、ハイブリッドクラウドオプションを効果的に実現できます。
ステップバイステップの手順
このセクションでは、 Amazon FinSpace 環境の設定とサンプルデータのインストール手順について説明します。
- 続行するには AWS アカウントが必要です。AWS アカウントをお持ちでない場合は、新しいアカウントを開くことができます。
- AWS アカウントにログインし、Amazon FinSpace ランディングページに移動します。
- “Create an Amazon FinSpace Environment” ガイドに従って、Amazon FinSpaceの Environment とスーパーユーザーを作成します。 Environmet の認証方法を選択する手順に達したら、シングルサインオンを使用する必要がない限り、 “電子メールとパスワード” を選択します。
- スーパーユーザーアカウントを作成したときに電子メールで受け取った認証情報を使用して、Environment domainにログインします。環境ドメインの URL は、Amazon FinSpace メニューの”Environments”セクションにあります。
- ログインしたら、”Sample Data Bundle” ガイドの説明に従って、 “Capital Markets sample data” バンドルをインストールします。サンプルデータバンドルがインストールされると、Amazon FinSpace は次の画像のようになります。Amazon FinSpace の操作をより詳しく知りたい場合は、 “Using the Amazon FinSpace Homepage” を確認ください。
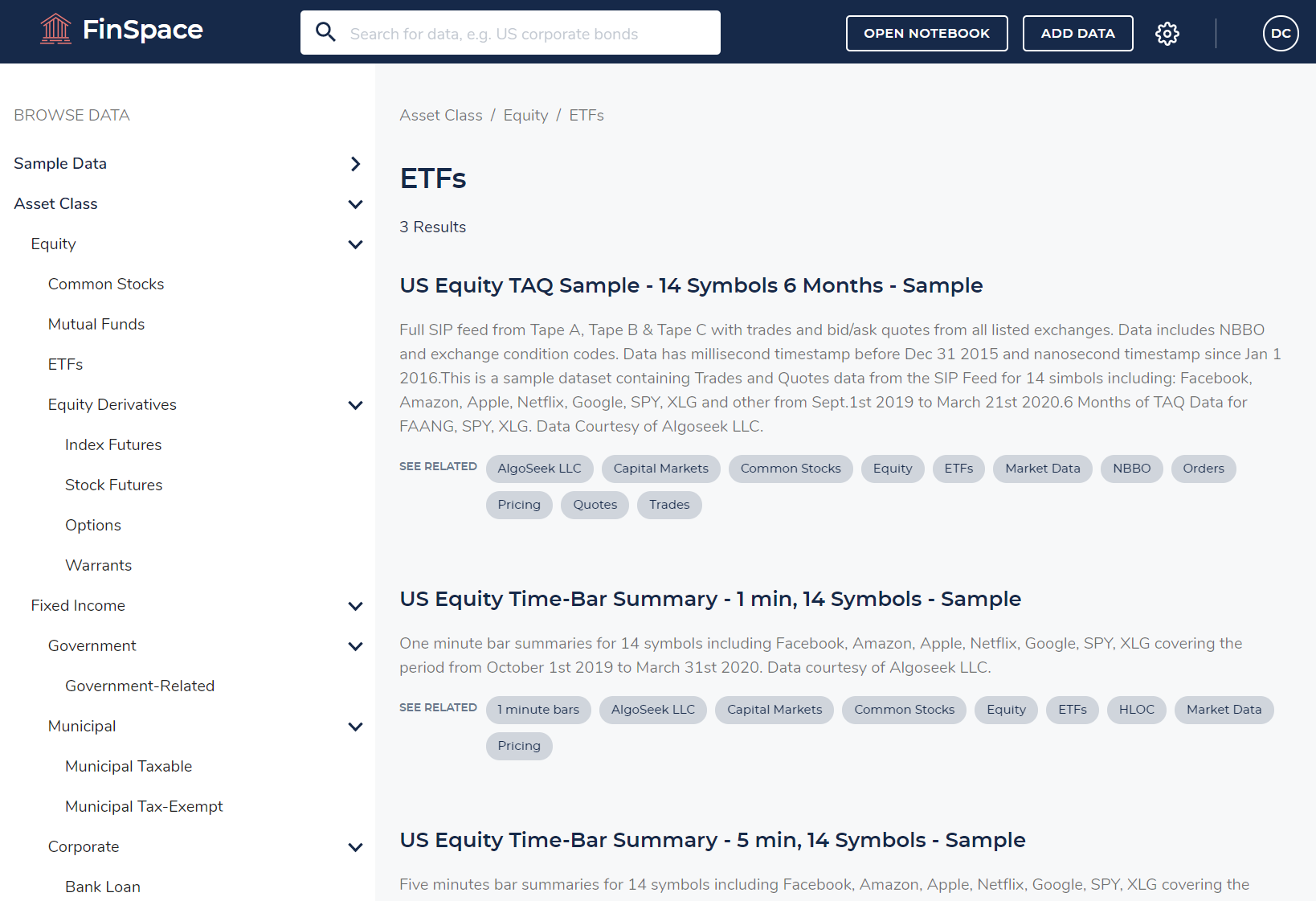
- ウィンドウの上部にある検索バーを使用して、”US Equity Time-Bar Summary – 1 min, 14 Symbols – Sample” データサンプルを検索します。検索結果リスト内で該当データをクリックします。そうすると次のようなページが表示されます。
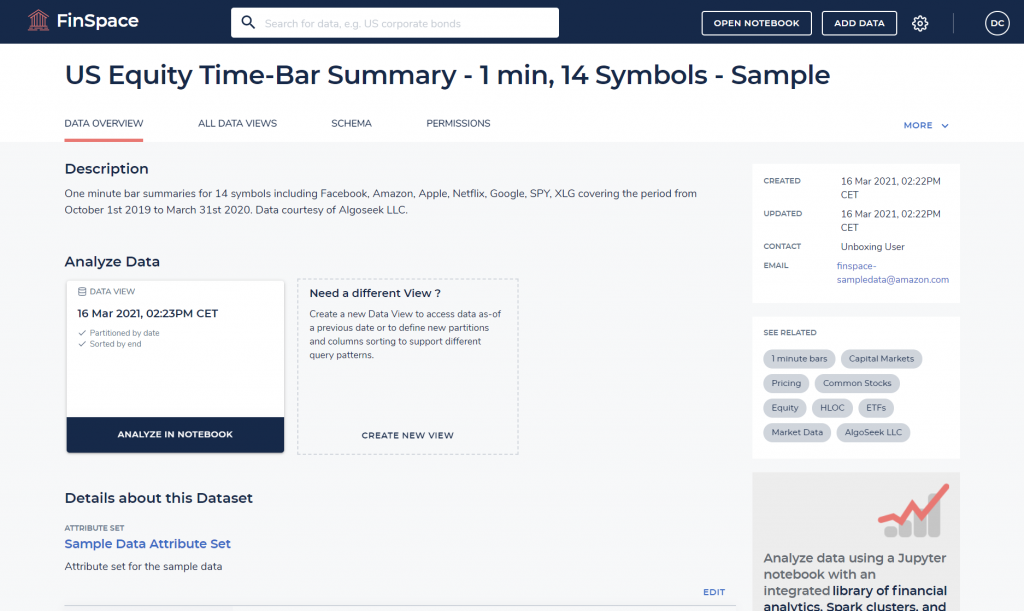
- ここから、スキーマ、属性、権限などのデータセットの詳細を確認できます。データセット構成を変更し、追加のビューを作成できます。
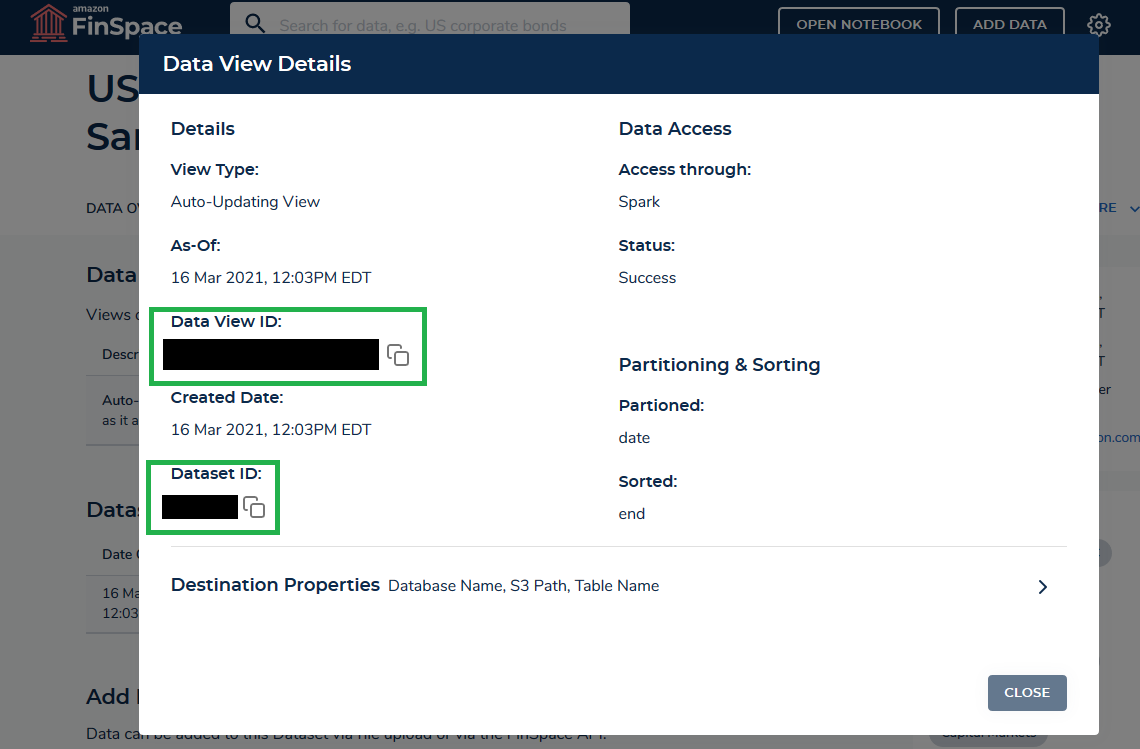
- “ALL DATA VIEWS” タブをクリックし、データビューの横にある “Details” リンクをクリックします。これにより、次の情報が表示されます。
- data_view_id と dataset_id を書き留めます。これらの詳細については後ほど Jupyter notebook で必要になります。
このブログで目指す目的のために、以前に説明した What-if 分析ソリューションを実行するために、事前に構築された別の notebook を使用します。
- この notebook をこの GitHub リポジトリからダウンロードし、以下の画像で強調表示されているアップロードアイコンを使用して環境にアップロードします。
- notebook がアップロードされると、使用するカーネルをポップアップで尋ねられるはずです。そうでない場合は、“No Kernel” ボタンをクリックしてカーネルを選択します。
- “FinSpace PySpark” カーネルを選択します。
このセクションでは、Amazon FinSpace で What-if 分析を実行する Jupyter notebook の手順について説明します。
- “データの読み込み” セクションで、前述した dataset_id と data_view_id を指定します。
- “データの準備” セクションでは、バックテストとモデルトレーニングに使用する日付範囲を変更できます。時間範囲を短くするとモデルの学習時間は短くなりますが、通常は目に見えないデータでのモデルのパフォーマンスが低下します。
- “モデルトレーニング” セクションでは、Spark ML を使用して、複数のランダムフォレストモデルを異なるパラメーターでトレーニングします。過去の価格データとEMA(指数平滑移動平均線)を機能として使用し、機械学習問題のラベルとして現在時刻から5分でVWAP(売買高加重平均価格)を使用しています。簡単にするために、包括的なデータ探索と特徴量エンジニアリングは実行しません。このデータセットをランダムフォレストアルゴリズムで学習に使用しています。ランダムフォレストアルゴリズムは、並列計算のためのクラスターの恩恵を受けることができ、異なるハイパーパラメーターを使用して 3 つのモデルに学習をさせます。モデルのパフォーマンスをさらに向上させたい場合は、データ準備と特徴量エンジニアリングの強化から始めることをお勧めします。また、Amazon FinSpace の組み込みテクニカルインジケータ(MACD、ボリンジャーバンド、RSI など)を調べることもできます。完全なリストはこのノートブックで入手でき、サンプルコードも用意されています。ハイパーパラメーターのチューニングでは、GridSearchCV や randomizedSearchCV などの一般的な scikit-learn 関数を試すことができます。
- “バックテストストラテジー” セクションでは、取引ストラテジーのバックテストのための Python フレームワークである Backtrader をインポートおよび設定します。また、さまざまな取引パフォーマンス指標を計算し、Amazon FinSpace からバックテストエンジンにデータを供給するためのヘルパークラスも定義しています。このトレードストラテジーは、モデルが現在の価格よりも高い価格を予測すると長くなり、モデルが低価格を予測すると短くなるシンプルな機械学習ベースのトレードストラテジーです。
- “ベンチマークストラテジー” セクションでは、(以前にトレーニングしたモデルを使用して)異なるストラテジー構成を作成し、バックテストエンジンにフィードします。すべてのストラテジー構成について、PNL をキャプチャします。
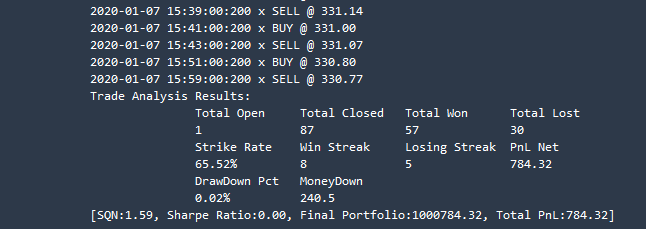
- 最後の“What-if 出力” では、次の出力が得られ、最良の PNL を使用したストラテジー構成が表示されます。
クリーンアップ
次の手順は、不要なコストが発生しないようにリソースをクリーンアップする方法を示しています。 Environment を削除すると、その環境にあるすべてのアセット (Jupyter notebook、データ) が削除されます。
- Amazon FinSpace のランディングページに移動し、”Environments” を選択します。
- 該当の “Environment name” をクリックし、次の図に示すように “Delete” ボタンをクリックします。作成した環境ごとに、前の手順を繰り返します。
さらに、不要な費用を防ぐ場合は、AWS コストの管理チュートリアルに従って、AWS コストを追跡し、アラートを設定する方法を確認できます。
まとめ
このブログ記事では、Amazon FinSpace のサンプルデータバンドルからの金融データのインポート、フルマネージド Spark クラスターを使用したデータ準備の実行、異なる実装の ML モデルのトレーニングを実行して、Amazon FinSpace によるトレードストラテジーの What-If 分析を実行する方法を説明しました。トレードストラテジーのバックテストを実行し、ストラテジーパフォーマンスのベンチマークを提供するWhat-If分析を完了します。
このブログで説明されているソリューションは基盤として使用でき、独自のストラテジーと構成を使用してパーソナライズできます。Amazon FinSpace で利用可能な他のデータセットを使用したり、独自のデータセットを読み込むこともできます。
可能性のある拡張機能と追加のユースケースに関するフィードバックを歓迎します。
この投稿は教育のみを目的としています。過去の取引実績は、将来の業績を保証するものではありません。
Amazon FinSpace のドキュメントとすぐに使用できる Jupyter notebook の詳細については、Amazon FinSpace GitHub を参照してください。

Diego Colombatto
Diego Colombatto は、AWS のシニアパートナーソリューションアーキテクトであり、エンタープライズ向けのデジタルトランスフォーメーションプロジェクトの設計とデリバリーにおいて 15 年以上の経験を有しています。AWS において、Diego はパートナーやお客様が AWS テクノロジーを理解して活用し、ビジネスニーズをソリューションに変えるための手助けをしています。彼が情熱を持って取り組んでいることの一つにIT アーキテクチャとアルゴリズム取引があり、いつでもこれらのトピックに関する会話を歓迎しています。

Oliver Steffmann
Oliver Steffmann は、ニューヨークを拠点とする AWS のエンタープライズソリューションアーキテクトです。IT アーキテクト、ソフトウェア開発マネージャー、および国際金融機関の管理コンサルタントとして 18 年以上の経験を有しています。コンサルタントとして勤務していた際には、ビッグデータ、機械学習、クラウドテクノロジーに関する豊富な知識を活用して、顧客がデジタルトランスフォーメーションを開始できるよう支援しました。それ以前は、ニューヨークにあるTier 1 投資銀行で地方自治体取引技術の責任者であり、ドイツで自身のスタートアップ企業を設立しキャリアを開始しました。
翻訳はソリューションアーキテクトの澤野佳伸が担当しました。原文はこちらです。