Amazon Web Services ブログ
Amazon SageMaker、AWS Glue DataBrew、SAP S/4HANAで継続学習型機械学習パイプラインを構築する
機械学習は、デジタルトランスフォーメーションの中核的な役割を担うようになってきています。企業が大規模なパターンを認識し、顧客体験を向上する斬新な方法を見つけ業務を効率化したり、競争の激しい市場でビジネスを成功に導くことが出来ます。実際には、機械学習に基づくアーキテクチャを構築する際には、データを理解し、データセットを正しく理解するための課題を克服し、継続的なフィードバックループによってモデルの精度を維持する必要があります。このブログ記事では、SAP S/4HANAシステムとAmazon SageMaker間のエンドツーエンドの統合を、AWSの実質的に無制限のキャパシティを活用して高速なフィードバックループで構築する方法を説明します。
はじめに
まず最初に、SAP S/4HANAシステムからSAP OData、ABAP CDS、AWS Glueを組み合わせてSAPデータを抽出し、SAPからAmazon S3バケットにデータを移動します。その後、AWS Glue Databrewを使ってデータを準備し、Amazon SageMakerを使ってモデルをトレーニングします。最後に、私たちの予測結果をSAPシステムに返します。

前提条件
- 例として、クレジットカードのトランザクションデータを使用して、SAPシステム内のデータをシミュレートしています。これはKaggleからダウンロードできます。
- SAP S/4HANAのデプロイメント。これをデプロイする最も簡単な方法は、AWS LaunchWizard for SAPを使用することです。
ウォークスルー
ステップ1: SAPデータの準備
SAPシステムからAWSにデータを抽出する方法はいくつかありますが、ここではABAP Core Data Services (CDS)ビュー、RESTベースのOpen Data Protocol services (OData)、AWS Glueを使用します。
- SAP S/4HANAシステムで、SAPトランザクション
SE11を使用してカスタムデータベーステーブルを作成します。 - KaggleからのデータをSAP HANAテーブルにロードします。KaggleからのデータはCSV形式であり、
IMPORT FROM CSVステートメントを使用してSAP HANAにインポートすることができます。 - ABAP Development Tools (ADT)でSAP ABAP CDSビューを作成します。アノテーション
@OData.publish: trueを追加するだけで、OData サービスを作成することができます。この例は、AWS Sample Githubで公開されています。 - SAP トランザクション
/IWFND/MAINT_SERVICEで OData サービスを有効化します。 - SAP トランザクション
/IWFND/GW_CLIENTで SAP ゲートウェイクライアントの OData サービスをテストします(オプション)。 - AWS コンソールで、Python シェルジョブの作成に関する AWS ドキュメントに従って、データ抽出用の AWS Glue ジョブを作成します。Pythonスクリプトの例は、AWS Sample Githubで確認することができます。今回のシナリオでは、0.0625 Data Processing Unit(DPU)のみを使用してSAPから284,807エントリを抽出するのに1分以内でした。
ステップ2:AWS Glue DataBrewによるデータの洗い出し
不正検出モデリングのトレーニングを開始する前に、機械学習のトレーニングに対応できるようにデータセットを準備する必要があります。通常、これにはデータのクレンジング、正規化、エンコーディング、そして時には新しいデータの特徴をエンジニアリングするなど、多くのステップが必要です。AWS Glue DataBrewは、2020年11月にリリースされたビジュアルデータ準備ツールです。これにより、データアナリストやデータサイエンティストが容易にデータのクレンジングや正規化を行うことができ、最大80%の高速化に繋がります。250以上の事前に構築された変換を選択して、データ準備作業を自動化することができ、すべてコードを書く必要はありません。このセクションでは、簡単に設定できる方法をご紹介します。
ステップ2.1 プロジェクトの作成
- AWSコンソールにログインし、左上のserviceからAWS Glue DataBrewを選択し、Create projectを選択します。
- ナビゲーションペインで、Projectsを選択し、Create projectを選択します。
- Project details画面で、Project NameにSAP-MLと入力します。
- Select a datasetペインで、New dataset を選択します。
- Dataset nameに
CreditcardfraudDBと入力します。 - ここでは、ステップ 1 で作成したデータソースとして Amazon S3 を選択し、Select the entire folder を選択します。
- Access permissionsでは、Create New IAM roleを選択し、サフィックスには
fraud-detection-roleのように入力します。これは、DataBrewがAmazon S3の入力場所から読み取ることを許可する、サービスにリンクしたロールです。 - Create Projectを選択します。

- AWS Glue DataBrewは、初期状態では500行のサンプルデータセットを表示しますが、これを変更して最大5000行まで含めることができます。これは、最初の行、最後の行、またはランダムな行のいずれかにすることができます。
ステップ2.2 データプロファイルの作成
データプロファイルを作成することで、データセットの品質を評価し、データパターンを理解し、異常を検出することができます。この機能は非常に簡単で、AWSのドキュメントに沿って作成することができ、以下に出力例を示します。デフォルトでは、データプロファイルはデータセットの最初の20,000行に制限されています。しかし、より大きなデータセットに対しては、サービス制限の増加を要求することができます。今回のケースでは、300,000行までの制限の増加をリクエストしました。
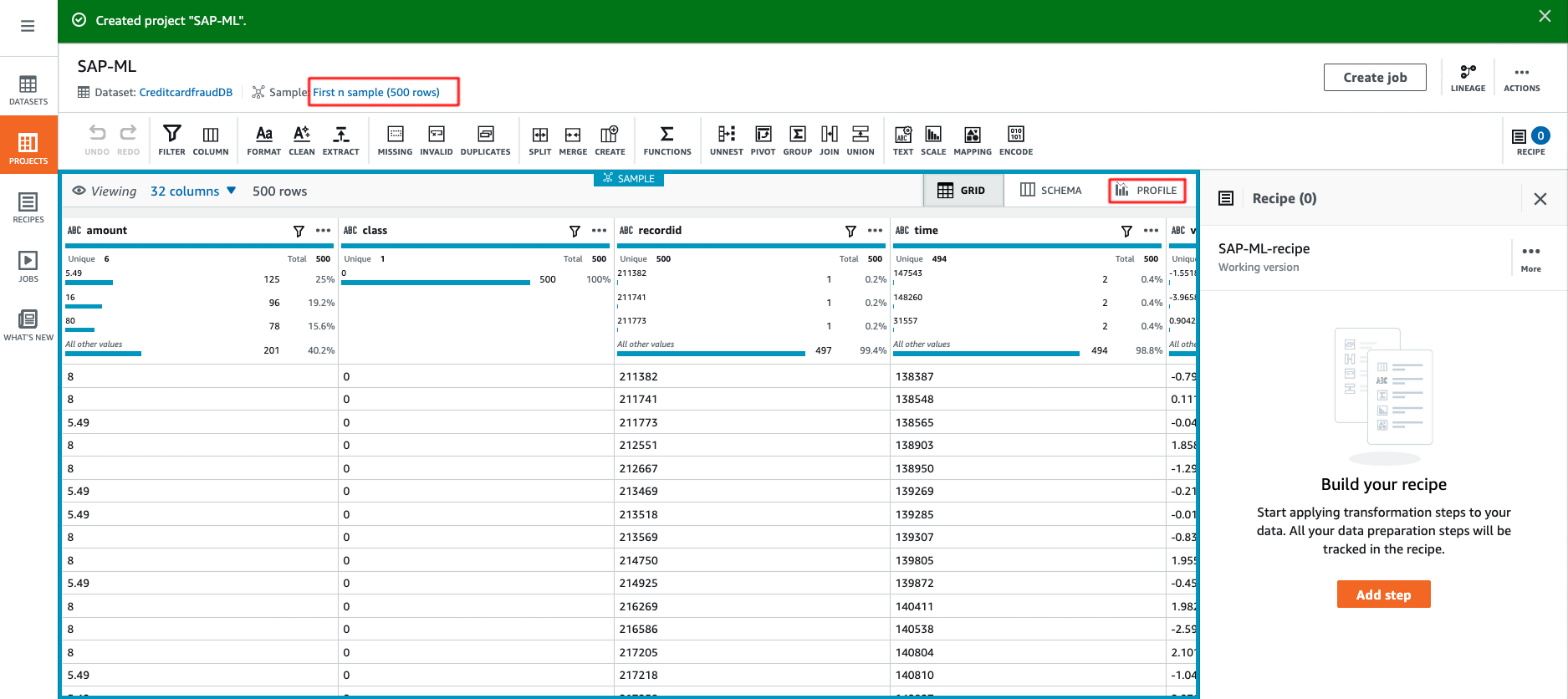
Glue DataBrewは、データセットに関するより深い洞察を提供します。より深く掘り下げてみましょう。合計32列、284,807行あります。欠損値がないというのは素晴らしいニュースです。データセットのスキーマが間違っているため、相関関係が空になっていますが、この修正がとても簡単なことを見てみましょう。
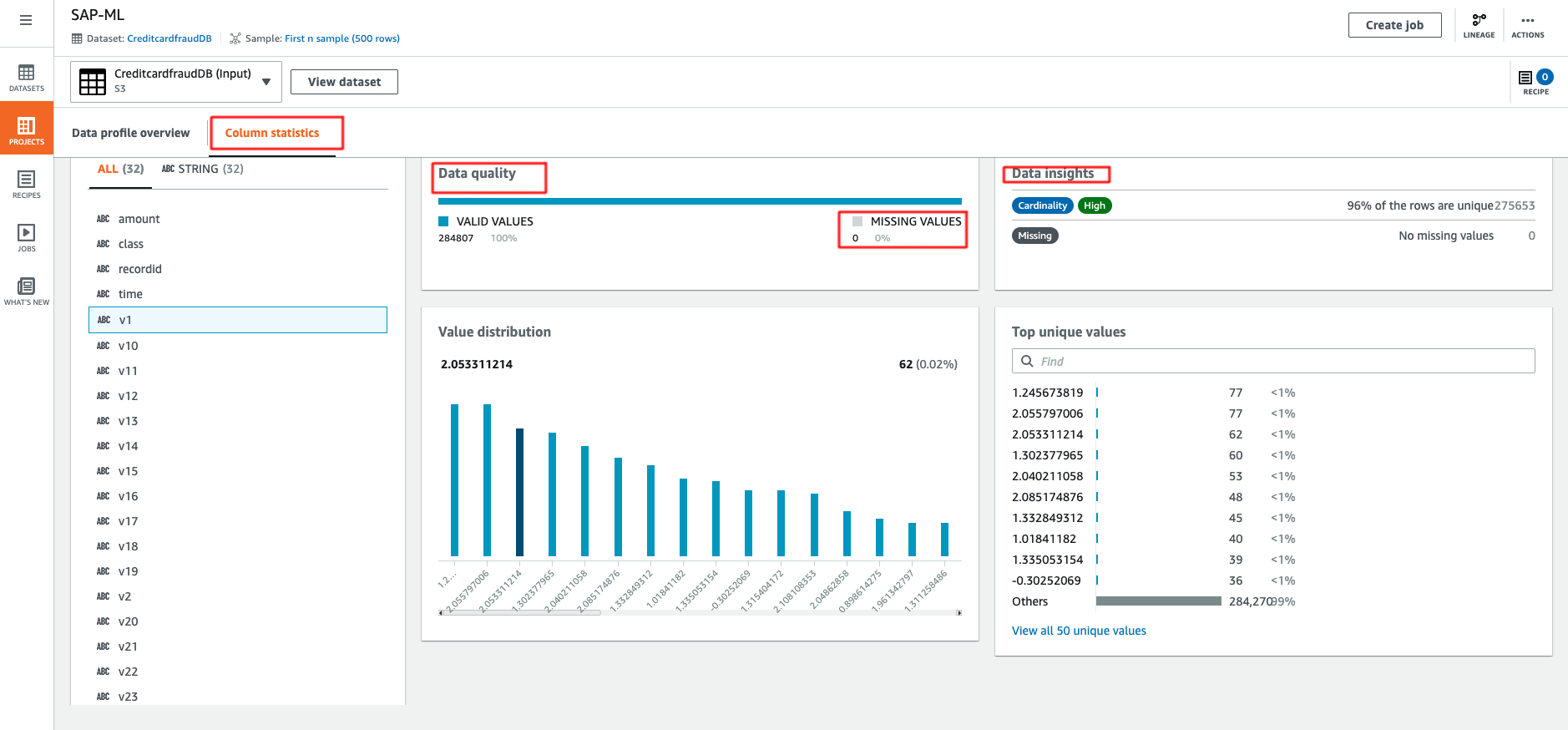
ステップ2.3 データの準備
- 最初のステップは、すべてのカラムのデータタイプを変更することです。Schemaを選択し、Data typeでtypeを
stringからnumberに変更します。AWS Glue DataBrewは、データタイプを変更すると、すぐにデータの統計を計算し、すべての列のボックスプロットを生成します。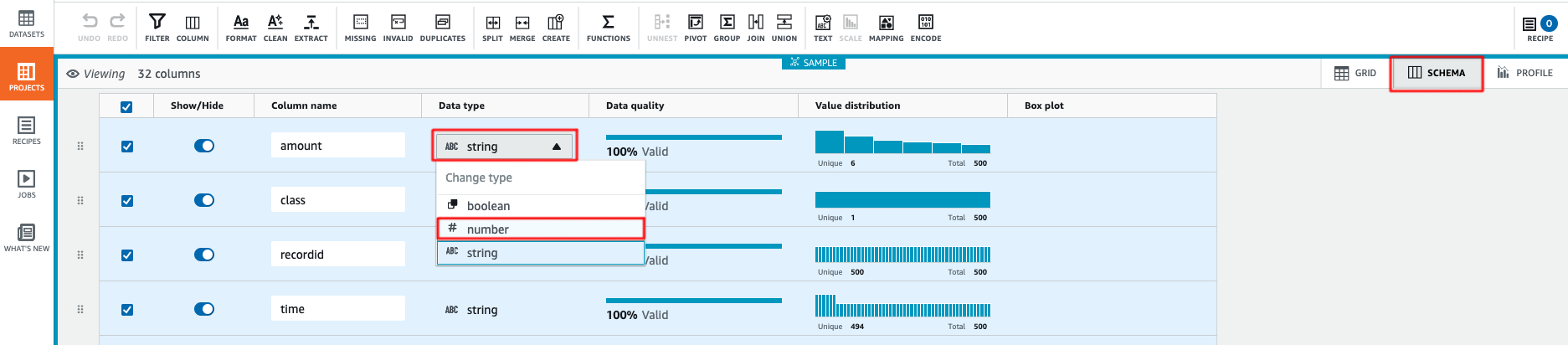
- 機械学習アルゴリズムの中には、特徴量のスケーリングに非常に繊細なものがあります。これは、アルゴリズムが大きな値に対して高い重みを与えたり、逆に大きな値に対して低い重みを与えたりする原因となります。私たちのデータセットでは、Zスコア正規化を使用して、データ内の金額と時間の列を同じ範囲に変換し、外れ値を処理します。Column Actionsを選択し、Z-score Normalization or Standardizationを選択してApplyを選択します。これにより、
amount_normalizedとtime_normalizedという2つの新しい列が作成されます。 - Column Actionで、
amount、time、recordを選択して冗長な列を削除し、Deleteを選択します。
class列の最後に移動します。Column Actionで、Move Column と End of the tableを選択します。- これで必要なデータ変換の手順が完了し、設定した変換をデータセット全体に適用する準備が整いました。Create Jobを選択し、ジョブ名を
fraud-detection-transformationと入力し、出力先を s3 フォルダ、ファイル形式をCSV とします。 - また、レシピを使って必要な変換を実行することもできます。この例は、AWS Sample Githubに掲載されています。レシピの作成方法については、AWSのドキュメントを参照してください。
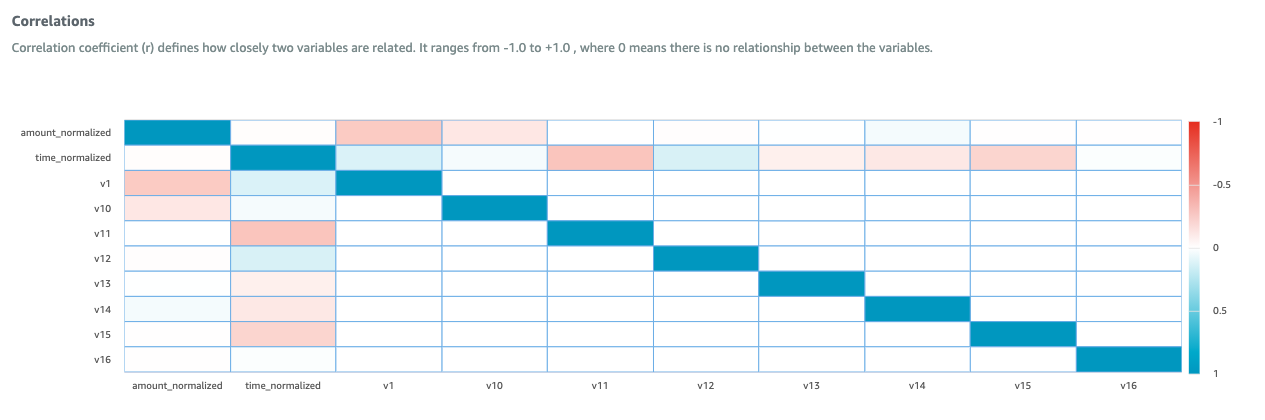
- オプションのステップとして、変換されたデータを新しいプロジェクトのAWS Glue DataBrewにインポートして、変換を検証し、特徴の相関行列を表示することができます。出力は以下の通りです。
ステップ3:Amazon SageMaker
AWSで機械学習(ML)ベースのワークロードを構築する場合、市場へのスピードとカスタマイズレベルおよびMLスキルレベルのバランスをとるために、異なる抽象化レベルから選択することができます。選択肢にはMLサービスおよび、MLフレームワークとインフラストラクチャがあります。このブログ記事では、Amazon SageMakerを使用しています。Amazon SageMakerは、開発者やデータサイエンティストが迅速かつ容易に機械学習を構築し、訓練し、デプロイすることができるフルマネージドプラットフォームです。この部分のソリューションでは、Amazon SageMaker Studioを使用しています。
- AWSドキュメントに従い、Amazon SageMaker Studioを起動します。
- AWS Sample GithubのJupyterノートブックをクローンします。
ml.ipynbのノートブック内のすべての指示に注意深く従います。Jupyterノートブックのすべてのステップを完了すると、出力がS3バケットに保存されます。
ステップ4:SAPデータのインポート
パート1のデータエクスポートと同様に、ABAP CDS View、OData、AWS Glueを使用します。ここでは、@OData.publish: trueというアノテーションがCREATE ENTITYやCREATE ENTITY SETをサポートしていないため、エントリを作成する手順が異なります。
- SAP S/4HANA システムで、SAP トランザクション
SE11を使用してカスタム Z テーブルを作成します。 - ABAP 開発ツール(ADT)で SAP ABAP CDS ビューを作成します。
- SAP トランザクション
SEGWを使用して OData サービスを作成し、CREATE ENTITYまたはCREATE ENTITY SETメソッドのコードを変更します。このブログのAWS Sample Githubに、この例があります。 - SAP トランザクション
/IWFND/MAINT_SERVICEで OData を有効化します。 - AWSコンソールで、AWS Glueのジョブを作成します。コードの例は、AWS Sample Githubにあります。
クリーンアップ
インフラのクリーンアップは簡単です。Amazon SageMaker clean up guideとAWS Glue DataBrew clean up guideに従って、不要な費用が発生しないようにしてください。また、SAP S/4HANAシステムやAmazon S3内のデータを忘れずに、別途削除する必要があります。
まとめ
データの価値は、それを素早く解釈してモデル化する能力に依存しており、この能力は競争上の優位性を維持する上で極めて重要です。このブログ記事では、SAPデータをデータソースとして使用して、継続的な機械学習パイプラインを構築する方法を紹介しています。特に、AWS Glue DataBrewとAmazon SageMakerに焦点を当て、これによって実世界からのフィードバックをより早く得ることができることを紹介しました。
重要なポイントとして、機械学習モデルの構築と利用は片道の旅ではないということです。予測結果をモデル構築にフィードバックする復路も同様に重要です。十分な精度を持つ機械学習モデルの構築に成功した後も、新しいデータや新しいビジネスシナリオがあれば、モデルの調整が必要になることも考えられます。その精度を維持し、さらに向上させていくためには、機械学習のフライホイールを作ることが重要です。
SAP on AWSのイノベーションについてご質問がある場合やお知りになりたい場合は、こちらのリンクからSAP on AWSチームにお問い合わせいただくか、aws.com/sap_japanやaws.com/mlで詳細をご覧ください。今すぐAWSでの構築を始めて、楽しんでください。
翻訳はPartner SA 松本が担当しました。原文はこちらです。