Amazon Web Services ブログ
Amazon OpenSearch Serverless のためのベクトルエンジンの紹介
vector engine for Amazon OpenSearch Serverless のプレビューリリースを発表できることを嬉しく思います。ベクトルエンジンは、Amazon OpenSearch Serverless でシンプルでスケーラブルでパフォーマンスの高い類似検索機能を提供します。これにより、最新の機械学習 (ML) 拡張検索エクスペリエンスと生成人工知能 (AI) アプリケーションを、基盤となるベクトルデータベースインフラストラクチャを管理することなく簡単に構築できるようになります。この投稿では、ベクトルエンジンの特徴と機能をご紹介します。
拡張 ML 検索とベクトル埋め込みによる生成 AI の使用
膨大なデータセットを処理し、自動化されたコンテンツを生成し、インタラクティブで人間のような応答を提供する機能を備えた生成 AI は、あらゆる業種の組織で急速に導入されています。現在多くの顧客は、チャットボット、質疑応答システム、パーソナライズされたレコメンデーションなどの高度な会話生成 AI アプリケーションを統合することにより、エンドユーザー体験とデジタルプラットフォームとのインタラクションを変革する方法を模索しています。これらの会話型アプリケーションを使用すると、自然言語で検索およびクエリを実行し、セマンティックな情報、ユーザーの意図、クエリのコンテキストを考慮して、人間に非常に似た応答を生成できます。
ML 拡張検索アプリケーションと生成 AI アプリケーションは、テキスト、画像、オーディオ、映像のデータの数値表現であるベクトル埋め込みを使用して、動的で関連性の高いコンテンツを生成します。ベクトル埋め込みは顧客が持つ独自のデータを利用してトレーニングされ、情報の意味属性とコンテキスト属性を表します。理想的には、これらの埋め込みは既存の検索エンジンやデータベース内など、ドメイン固有のデータセットの近くに保存および管理することです。これにより、結果を統合するための外部のデータソースや追加のアプリケーションコードに依存せずに、ユーザーのクエリを処理して最も近いベクトルを見つけ、それらを追加のメタデータと組み合わせることができます。多くの顧客は構築が簡単で、プロトタイプから本番環境に迅速に移行可能なベクトルデータベースの選択肢を求めています。それにより、本来の目的である差別化されたアプリケーションの作成に集中できます。OpenSearch Serverless のベクトルエンジンは、基盤となるインフラストラクチャを考慮することなく、数十億のベクトル埋め込みをリアルタイムで保存、検索、取得し、正確な類似性マッチングやセマンティック検索を実行できるようにすることで、OpenSearch の検索機能を拡張します。
ベクトルエンジンの機能と可能性
OpenSearch Serverless 上でベクトルエンジンを構築することで、OpenSearchの堅牢なアーキテクチャを継承し、恩恵を受けることができます。例えば、バックエンドインフラストラクチャのサイジング、チューニング、スケーリングについて心配する必要がなくなります。ベクトルエンジンは、変化するワークロードパターンと要求に適応してリソースを自動的に調整し、一貫して高速なパフォーマンスとスケールを提供します。ベクトルの数がプロトタイピング時の数千から本番環境では数億以上に増加するにつれて、ベクトルエンジンはシームレスに拡張され、インフラストラクチャを拡張するためにインデックスの再作成やデータを再度ロードする必要はありません。さらに、ベクトルエンジンはインデックス作成と検索ワークロード用に別個のコンピューティングを備えているため、ユーザーが体験するクエリのパフォーマンスに影響を与えずに、ベクトルをリアルタイムでシームレスに取り込み、更新、削除できます。全てのデータは Amazon Simple Storage Service (Amazon S3) に保存されているため、Amazon S3 (イレブンナイン) と同じデータ耐久性保証が得られます。まだプレビュー段階ではありますが、ベクトルエンジンはアベイラビリティ ゾーンの停止やインフラストラクチャ障害に備えた冗長性を備えた実稼働ワークロード向けに設計されています。
OpenSearch Serverless のベクトルエンジンは、信頼性が高く正確な結果を提供することが実証されている、オープンソース OpenSearch プロジェクトの k近傍法アルゴリズム (kNN) を利用しています。現在、多くのお客様はアプリケーションでセマンティック検索とパーソナライゼーションを提供するために、マネージドクラスターで OpenSearch kNN 検索を使用しています。ベクトル エンジンを使用すると、サーバーレス環境のシンプルさで同じ機能を得ることができます。ベクトルエンジンは、ユークリッド距離、コサイン類似度、ドット積などの一般的な距離メトリックをサポートし、16,000 次元に対応できるため、幅広い基盤モデルやその他の AI/ML モデルのサポートに適しています。また、数値、ブール値、日付、キーワード、ジオポイントといったメタデータや、保存されたベクトルにさらにコンテキストを追加するための説明情報のテキストなど、さまざまなデータ型を持つフィールドを保存することができます。複数のデータ型を同じ場所に配置すると、複雑さと保守性が軽減され、データの重複やバージョン互換性の問題、ライセンスの問題が回避されアプリケーションスタックが効果的に簡素化されます。ベクトルエンジンは、オープンソース OpenSearch と同様の API をサポートしているため、全文検索、高度なフィルタリング、集計、地理空間クエリ、データを高速に取得するためのネストされたクエリ、高度な検索結果などの豊富なクエリ機能を利用できます。たとえば、ユースケースとしてリクエストを投げたユーザーから 15 マイル以内の結果を見つける必要がある場合、ベクトルエンジンはこれを 1 つのクエリで実行できるため、2 つの異なるシステムを維持し、アプリケーションロジックを通じて結果を結合する必要がなくなります。LangChain やAmazon Bedrock、Amazon SageMaker を使用すると、好みの ML および AI システムをベクトルエンジンと簡単に統合できます。
ベクトルエンジンは、画像検索、ドキュメント検索、音楽検索、製品のレコメンド、ビデオ検索、位置ベースの検索、不正検出、異常検出など、さまざまなドメインにわたる幅広いユースケースをサポートします。また、我々は語彙検索手法と高度な ML および生成 AI 機能を組み合わせたハイブリッド検索の傾向が高まると予想しています。たとえば、ユーザーが電子商取引 Web サイトで「赤いシャツ」を検索する場合、セマンティック検索は語彙 (BM25) 検索に実装されている調整および強化ロジックを維持しながら、赤のすべての色合いを取得することで検索範囲を拡大するのに役立ちます。OpenSearch フィルタリングを使用すると、サイズ、ブランド、価格帯、近くの店舗の在庫状況に基づいて検索を絞り込むオプションをユーザーに提供することで検索結果の関連性をさらに高めることができるため、さらにパーソナライズされた正確なエクスペリエンスが可能になります。ベクトル エンジンのハイブリッド検索サポートにより、単一のクエリ呼び出し内でベクトルの埋め込み、メタデータ、説明情報をクエリできるため、複雑なアプリケーションコードを構築することなく、より正確でコンテキストに関連した検索結果を簡単に提供できるようになります。
AWS マネジメントコンソール、AWS コマンドラインインターフェイス(AWS CLI)、または AWS ソフトウェア開発キット (AWS SDK) を使用して、OpenSearch Serverless でベクトル検索のコレクションを作成することで、ベクトルエンジンを数分で開始できます。コレクションは、ワークロードをサポートするためのインデクシングされたデータの論理グループであり、物理リソースはバックエンドで自動的に管理されます。必要なコンピューティングまたはストレージの量をあらかじめ決定したり、システムが正常に実行されていることを確認するためにシステムを監視する必要はありません。OpenSearch Serverless は、Time-series、Search、ベクトル検索という 3 つの使用可能なコレクションタイプに対して、さまざまなシャーディングおよびインデックス作成戦略を適用します。データの取り込み、検索およびクエリに使用されるベクトルエンジンのコンピューティング能力は、OpenSearch コンピューティングユニット (OCU) で測定されます。1 つの OCU は、128 次元の場合は 400 万のベクトル、768 次元の場合は 50 万のベクトルを 99 % の再現率で処理できます。ベクトルエンジンは可用性の高いサービスである OpenSearch サーバーレス上に構築されており、少なくとも 4 つの OCU (プライマリとスタンバイを含む取り込み用の 2 つの OCU、およびアベイラビリティーゾーン全体にわたる 2 つのアクティブなレプリカによる検索用の 2 つの OCU) がアカウント内の最初のコレクションに対して必要です。同じ AWS Key Management Service (AWS KMS) キーを使用する後続のすべてのコレクションはそれらの OCU を共有できます。
ベクトル埋め込みを始める
コンソールを使用してベクトル埋め込みの使用を開始するには、次の手順を実行します。
-
- OpenSearch Serverless コンソールで新しいコレクションを作成します。
- 名前とオプションの説明を入力します。
- 現在、ベクトル埋め込みはベクトル検索コレクションによってのみサポートされています。したがって、Collection type で Vector search を選択します。

-
- 次に暗号化、ネットワーク、データアクセス ポリシーなどのセキュリティポリシーを構成する必要があります。
今回は新しい Easy create オプションを利用していきます。これによりセキュリティ構成が最適化され、迅速にオンボーディングできます。ベクトルエンジン内のすべてのデータはデフォルトで転送中も保存中も暗号化されます。独自の暗号化キーを使用するか、コレクションまたはアカウント専用のサービスによって提供される暗号化キーを使用するかを選択できます。コレクションをパブリックエンドポイントまたは VPC 内でホストすることを選択できます。ベクトルエンジンはきめ細かい AWS Identity and Access Management (IAM) アクセス許可をサポートしているため、暗号化、ネットワーク、コレクション、インデックスを作成、更新、削除できるユーザーを定義でき、組織の権限統制を行えます。
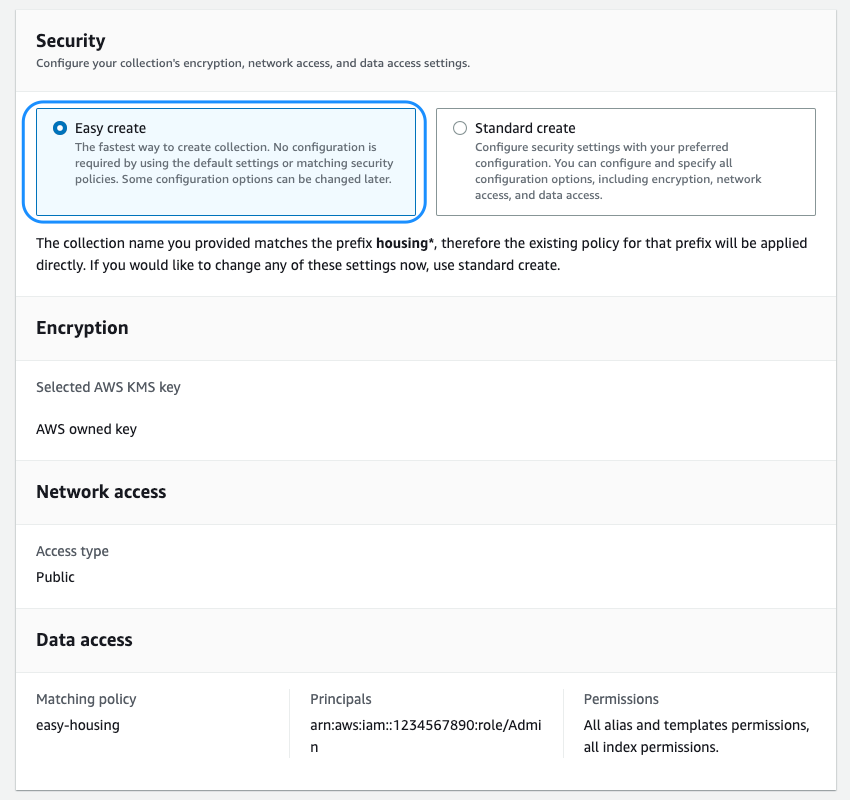
-
- セキュリティ設定を適切に行ったら、コレクションの作成をします。
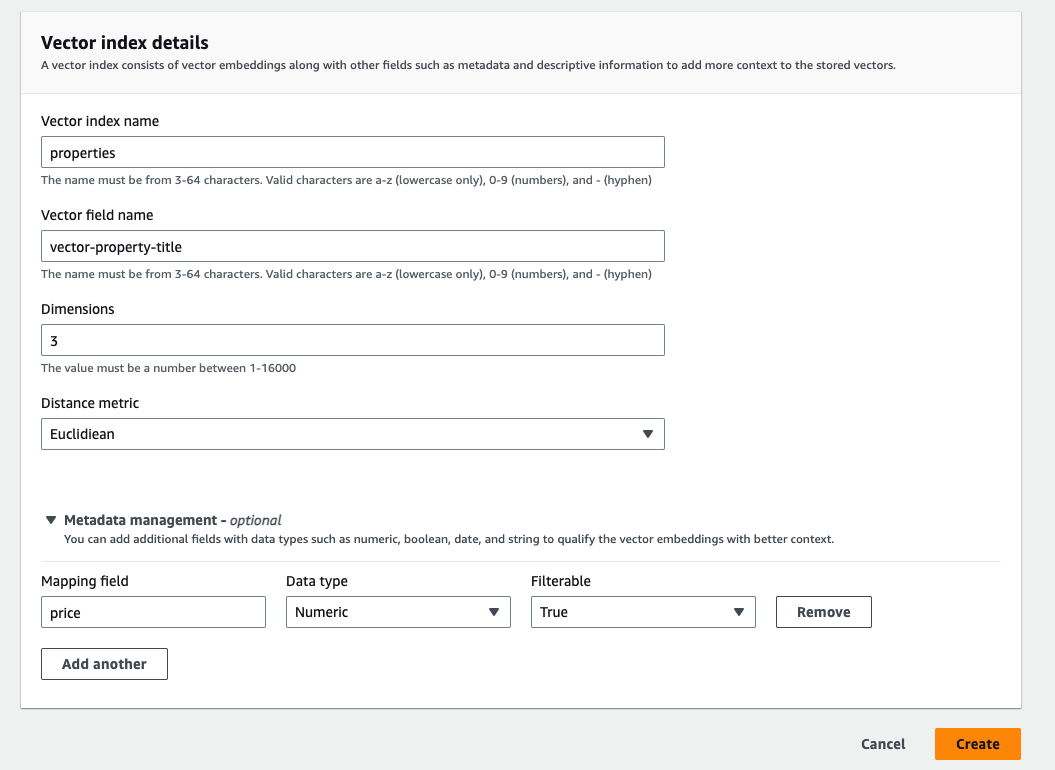
コレクションが正常に作成されたら、ベクトルインデックスを作成できます。この時点で、API またはコンソールを使用してインデックスを作成できます。インデックスは、共通のデータスキーマを持つドキュメントのコレクションであり、ベクトル埋め込みやその他のフィールドを保存、検索、取得する方法を提供します。ベクトルインデックスは最大 1,000 フィールドをサポートします。
-
- ベクトル インデックスを作成するには、ベクトルフィールド名、次元、距離メトリックを定義する必要があります。
ベクトルインデックスは、最大 16,000 次元と 3 種類の距離メトリック (ユークリッド、コサイン、ドット積) をサポートします。
インデックスが正常に作成されたら、OpenSearch の強力なクエリ機能を使用して包括的な検索結果を取得できます。
次の例は OpenSearch API を使用して、タイトル、説明、価格、場所の詳細をフィールドとして持つ単純な不動産の情報を持ったインデックスを簡単に作成できることを示しています。このインデックスはクエリ API を使用することで、「シアトルにある 3000 ドル未満の 2 ベッドルームのアパートを探してください」などの検索リクエストに一致する正確な結果を効率的に提供できます。
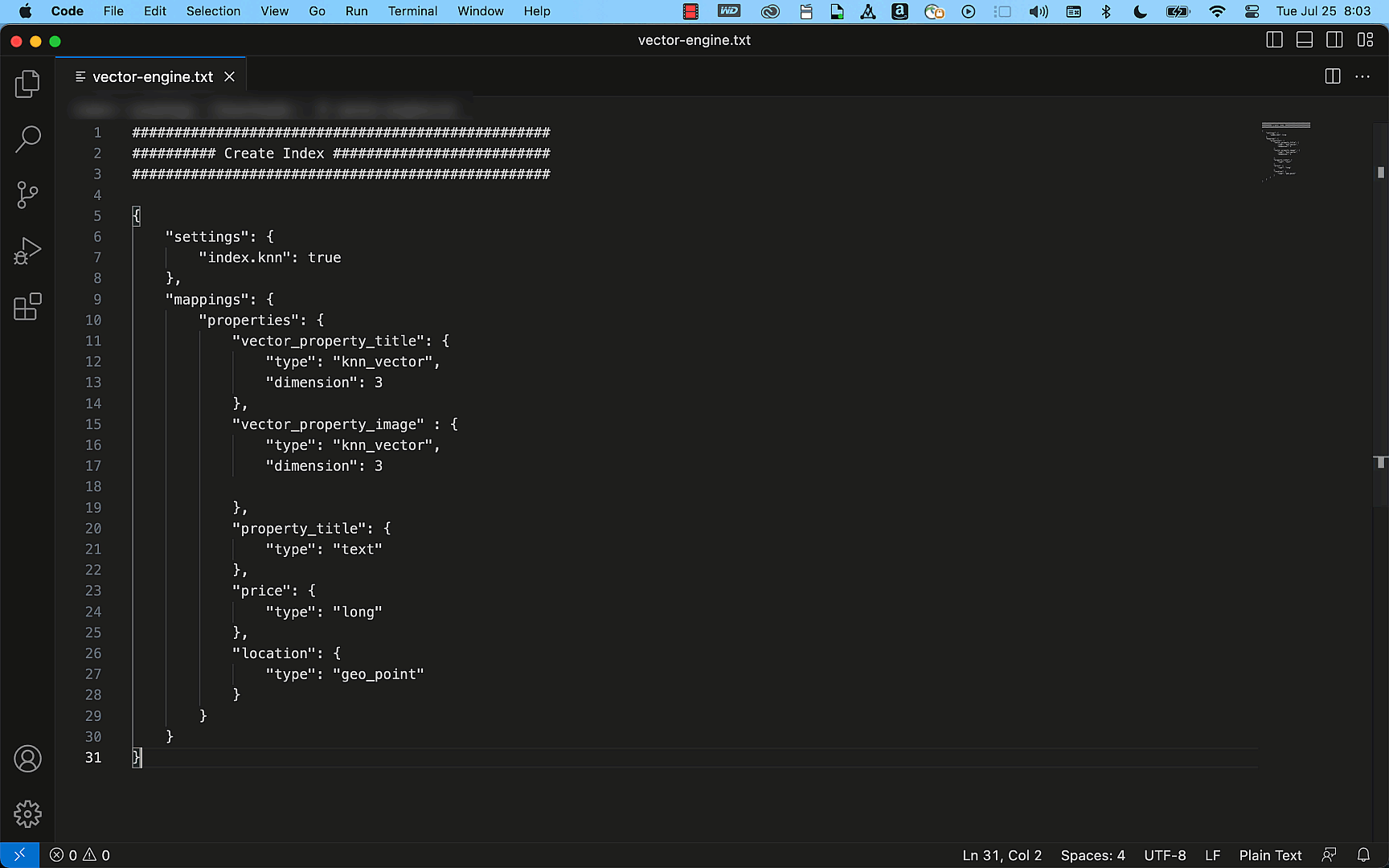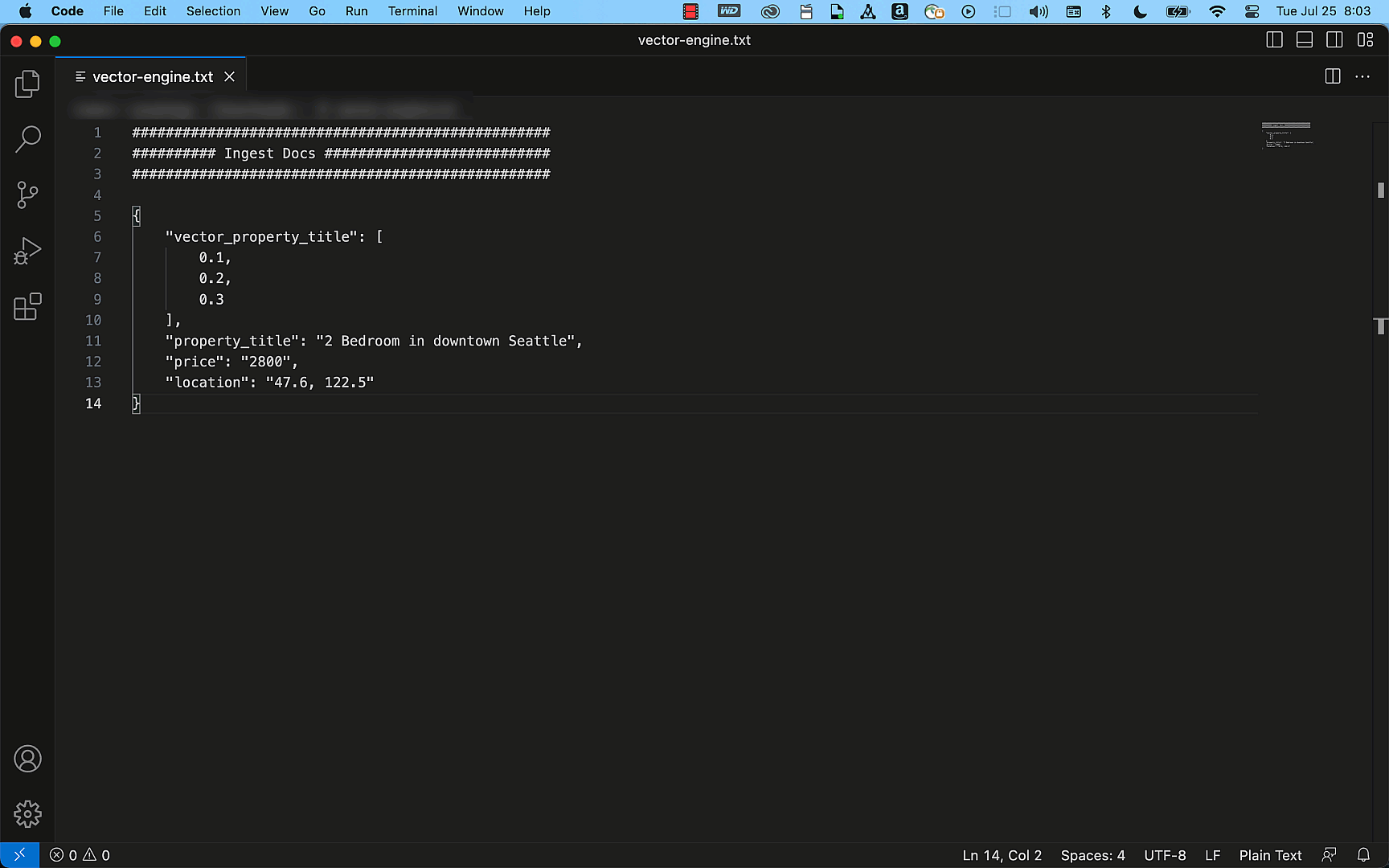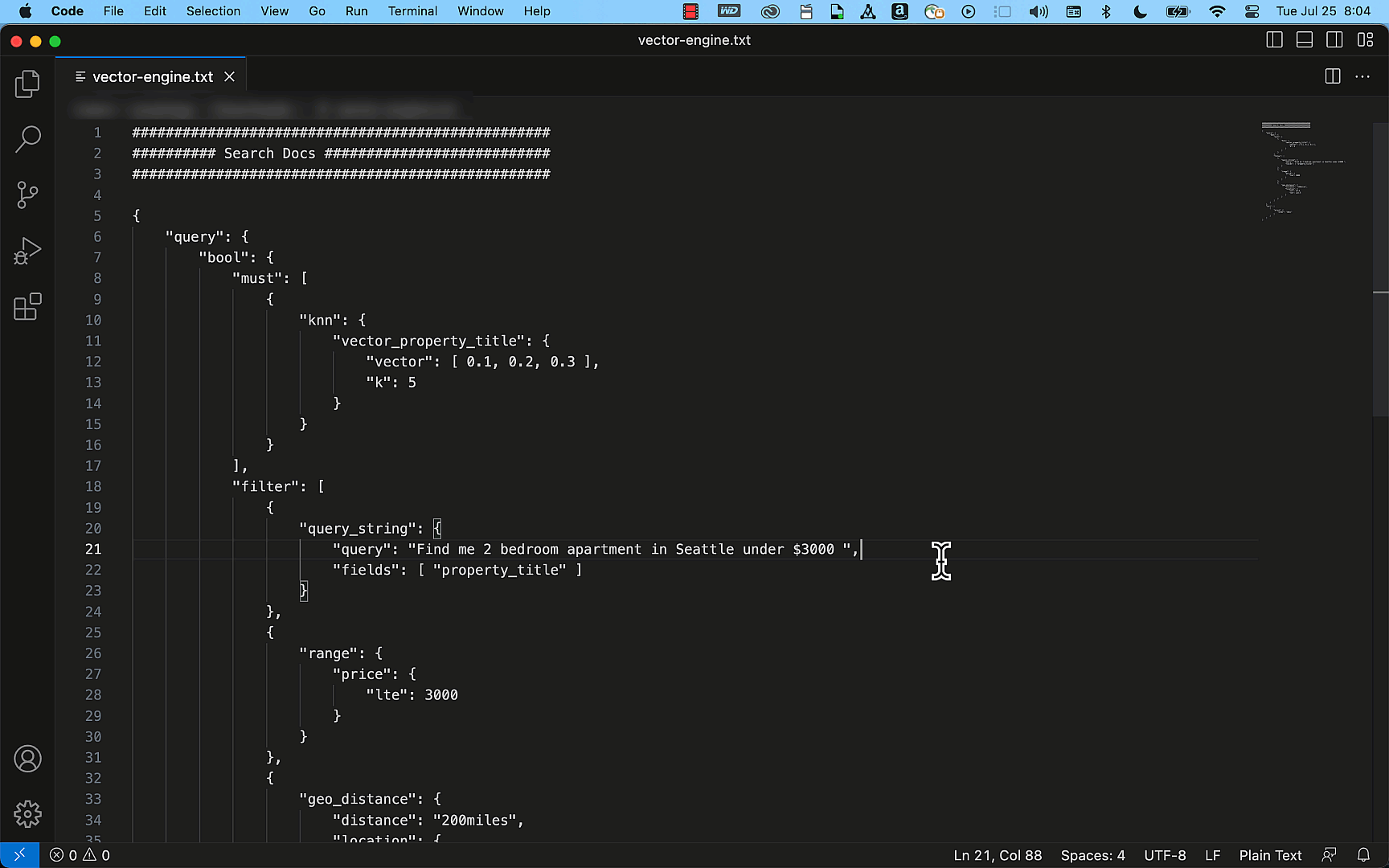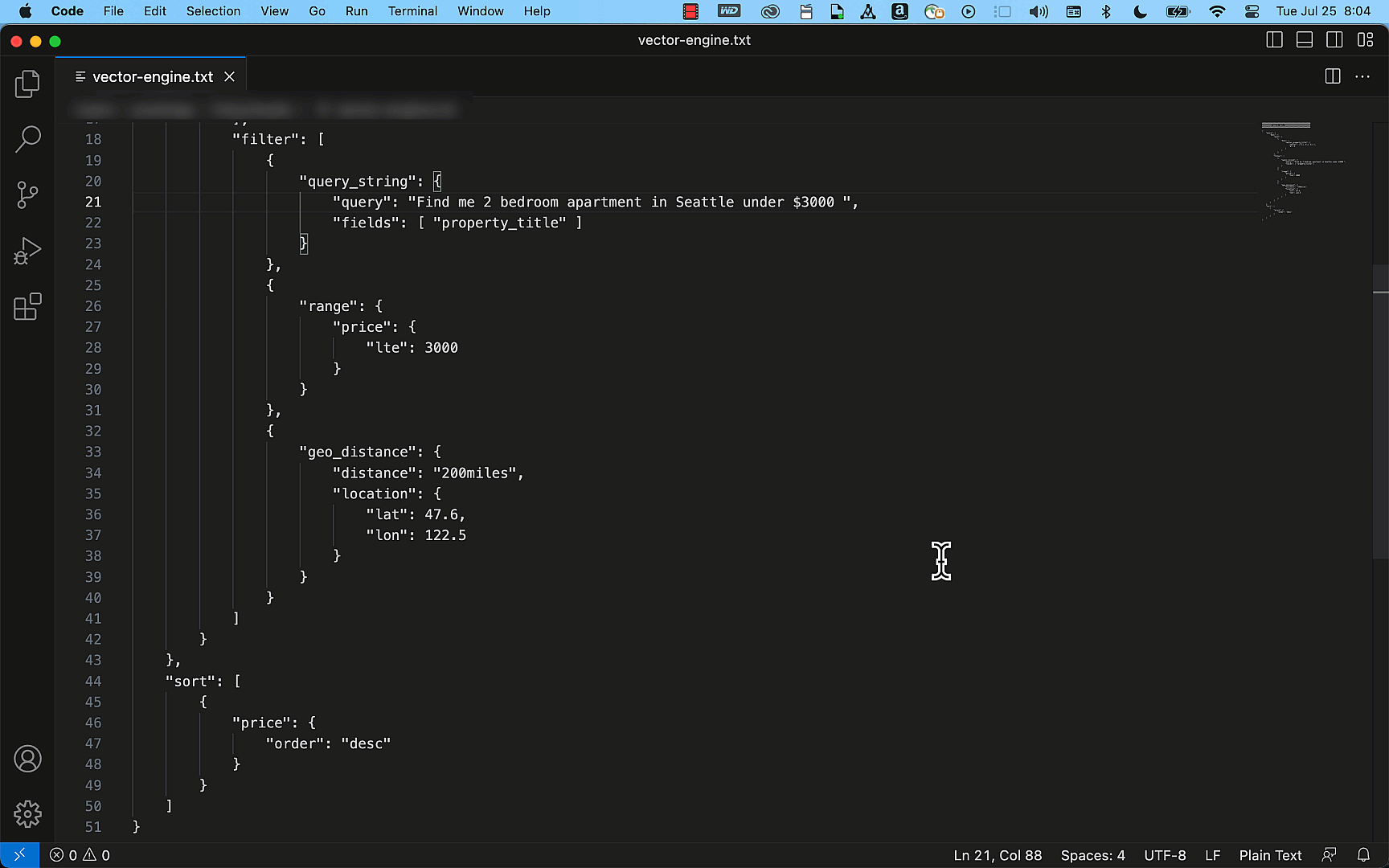
プレビューから GA、それ以降について
本日、ベクトルエンジンのプレビューを発表し、すぐにテストを開始できるようになりました。前述のように、OpenSearch Serverless はインデックスと検索用の独立したコンピューティングリソースと組み込みの冗長性を備えた、エンタープライズ アプリケーションを強化する高可用性サービスを提供するように設計されています。
私たちは、皆様の多くが実験段階にあり、開発とテストのためのより経済的なオプションを望んでいることを認識しています。GA の前に、最初のコレクションのコストを削減できる 2 つの機能を提供する予定です。1 つ目は、アクティブなスタンバイまたはレプリカを使用せずにコレクションを起動できる新しい開発/テストオプションで、エントリーコストを 50% 削減します。ベクトルエンジンはすべてのデータを Amazon S3 に保持するため、耐久性が保証されます。2 つ目は、初期ワークロードが数万から数十万ベクトル前半の場合、最初に 0.5 OCU フットプリント(ワークロードをサポートするために必要に応じてスケールアップされます)を次元数に応じてプロビジョニングしてコストをさらに削減するオプションです。これら 2 つのオプションで、最初のコレクションを導入するために必要な最小 OCU を 1 時間あたり 4 OCU から 1 OCU に削減します。
また、今後数か月以内に提供できるようにワークロードの一時停止と再開を実現できる機能の開発にも取り組んでいます。これらのユースケースの多くはデータの継続的なインデックス作成を必要としないため、これはベクトルエンジンにとって特に役立ちます。
最後に、私たちはキャッシュやマージなどの改善を含め、ベクトルグラフのパフォーマンスとメモリ使用量の最適化に熱心に取り組んでいます。
これらのコスト削減に取り組んでいる間、開発テストオプションが利用可能になるまで、ベクトルコレクションで月あたり最初の 1400 OCU 時間を無料で提供する予定です。これにより、ワークロードに応じて毎月最大 2 週間ベクトルエンジンのプレビューを無料でテストできるようになります。
まとめ
OpenSearch Serverless のベクトルエンジンには、シンプルでスケーラブルかつ高性能なベクトルストレージおよび検索機能が導入されており、さまざまな ML モデルから生成された数十億のベクトルエ埋め込みをミリ秒単位の応答で簡単かつ迅速に保存およびクエリできるようになります。
OpenSearch Serverless 用のベクトルエンジンのプレビューリリースは、米国東部 (オハイオ)、米国東部 (バージニア北部)、米国西部 (オレゴン)、アジアパシフィック (シンガポール)、アジアパシフィック (シドニー)、アジア太平洋 (東京)、ヨーロッパ (フランクフルト)、ヨーロッパ (アイルランド)の 8 つのリージョンで利用可能になりました。
私たちは今後の展望に興奮しており、皆様のフィードバックはこの製品の進歩を導く上で重要な役割を果たします。OpenSearch Serverless のベクトルエンジンを試して、使用例、質問、フィードバックをコメントセクションで共有することをお願いしています。
今後数週間で、ベクトルエンジンを LangChain、Amazon Bedrock、SageMaker と統合する方法に関する詳細なガイダンスを提供する一連の投稿を公開する予定です。ベクトルエンジンの機能の詳細については、our Getting Started with Amazon OpenSearch Serverless documentation をご参照ください。
About the authors
 Pavani Baddepudi は、 AWS の検索サービスのプリンシパルプロダクトマネージャーであり、OpenSearch サーバーレスのリード PM です。彼女の興味には、分散システム、ネットワーキング、セキュリティが含まれます。仕事以外のときは、ハイキングや新しい料理の探索を楽しんでいます。
Pavani Baddepudi は、 AWS の検索サービスのプリンシパルプロダクトマネージャーであり、OpenSearch サーバーレスのリード PM です。彼女の興味には、分散システム、ネットワーキング、セキュリティが含まれます。仕事以外のときは、ハイキングや新しい料理の探索を楽しんでいます。
 Carl Meadows は AWS の製品管理ディレクターであり、Amazon Elasticsearch Service、OpenSearch、Open Distro for Elasticsearch、および Amazon CloudSearch を担当しています。Carl は、Amazon Elasticsearch Service が 2015 年に開始される前から働いています。彼は、エンタープライズ ソフトウェアおよびクラウド サービスの分野で長年働いてきました。仕事以外の時間は、音楽を作ったり録音したりすることを楽しんでいます。
Carl Meadows は AWS の製品管理ディレクターであり、Amazon Elasticsearch Service、OpenSearch、Open Distro for Elasticsearch、および Amazon CloudSearch を担当しています。Carl は、Amazon Elasticsearch Service が 2015 年に開始される前から働いています。彼は、エンタープライズ ソフトウェアおよびクラウド サービスの分野で長年働いてきました。仕事以外の時間は、音楽を作ったり録音したりすることを楽しんでいます。
このブログは Introducing the vector engine for Amazon OpenSearch Serverless, now in preview を翻訳したものになります。