Amazon Web Services ブログ
新機能 – Amazon DynamoDB テーブルデータを Amazon S3 のデータレイクにエクスポート。コードの記述は不要
2012 年のリリース以来、数十万の AWS のお客様がミッションクリティカルなワークロードに Amazon DynamoDB を選択しています。DynamoDB は、非リレーショナルマネージドデータベースで、事実上無限のデータを格納し、1 桁ミリ秒のパフォーマンスで任意のスケールで取得できます。
このデータから最大限の価値を引き出すには、お客様は AWS Data Pipeline、Amazon EMR、または DynamoDB ストリームに基づくその他のソリューションを利用する必要がありました。このようなソリューションでは通常、読み取りスループットの高いカスタムアプリケーションを構築する必要があるため、メンテナンスと運用のコストが高くなります。
本日、DynamoDB テーブルデータを Amazon Simple Storage Service (S3) にエクスポートできる新機能をリリースします – コードの記述は不要です。
これは DynamoDB の新しいネイティブ機能であるため、サーバーやクラスターを管理しなくてもあらゆる規模で機能します。これにより、過去 35 日間、AWS リージョンおよびアカウント間でデータを 1 秒あたりの粒度で任意のポイントインタイムにエクスポートできます。さらに、読み取りキャパシティーや本番テーブルの可用性には影響しません。
データが S3 にエクスポートされると (DynamoDB JSON 形式または Amazon Ion 形式で)、Amazon Athena、Amazon SageMaker、および AWS Lake Formation などのお気に入りのツールを使用してデータをクエリまたは再形成できます。
この記事では、DynamoDB テーブルを S3 にエクスポートし、標準 SQL を使用して Amazon Athena を介してクエリする方法を説明します。
DynamoDB テーブルを S3 バケットにエクスポートする
エクスポートプロセスは、内部でデータを継続的にバックアップする DynamoDB の機能を利用しています。この機能は、継続的バックアップと呼ばれています。これにより、ポイントインタイムリカバリ (PITR) が可能になり、過去 35 日間の任意の時点にテーブルを復元できます。
[ストリームとエクスポート] タブで [S3 にエクスポート] をクリックすることから始めることができます。
![[DynamoDB ストリームとエクスポート] タブ](https://d2908q01vomqb2.cloudfront.net/da4b9237bacccdf19c0760cab7aec4a8359010b0/2020/10/29/DynamoDB-exports-tab.png)
継続的バックアップを既に有効にしていない限り、次のページで [PITR を有効にする] をクリックして有効にする必要があります。
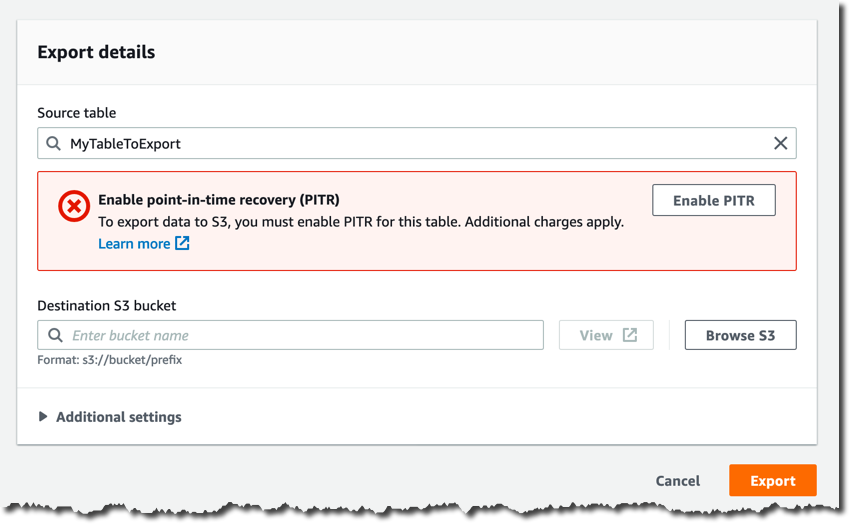
バケット名は、宛先 S3 バケットで指定します (例: s3:// my-dynamodb-export-bucket)。バケットが別のアカウントまたは別のリージョンにある可能性があることに注意してください。
[詳細設定] を自由にご覧ください。ここでは、特定の時点、出力形式、および暗号化キーを設定できます。この記事では、デフォルト設定を使用します。

これで、[エクスポート] をクリックして、エクスポートリクエストを確認できます。
エクスポートプロセスが開始され、[ストリームとエクスポート] タブでそのステータスを監視できます。

エクスポートプロセスが完了すると、S3 バケットに新しい AWS DynamoDB フォルダと、エクスポート ID に対応するサブフォルダが見つかります。
ここに、そのサブフォルダのコンテンツがどのように見えるかを示します。

整合性を検証し、データサブフォルダ内の S3 オブジェクトの場所を検出できる 2 つのマニフェストファイルがあります。これらのファイルは、自動的に圧縮および暗号化されています。
AWS CLI を介してエクスポートプロセスを自動化する方法
毎週または毎月新しいエクスポートを作成するなど、エクスポートプロセスを自動化する場合は、ExportTableToPointInTime API を呼び出すことで、AWS コマンドラインインターフェイス (CLI) または AWS SDK を介して新しいエクスポートリクエストを作成できます。
以下は、CLI の例です。
aws dynamodb export-table-to-point-in-time \
--table-arn TABLE_ARN \
--s3-bucket BUCKET_NAME \
--export-time 1596232100 \
--s3-prefix demo_prefix \
-export-format DYNAMODB_JSON
{
"ExportDescription": {
"ExportArn": "arn:aws:dynamodb:REGUIB:ACCOUNT_ID:table/TABLE_NAME/export/EXPORT_ID",
"ExportStatus": "IN_PROGRESS",
"StartTime": 1596232631.799,
"TableArn": "arn:aws:dynamodb:REGUIB:ACCOUNT_ID:table/TABLE_NAME",
"ExportTime": 1596232100.0,
"S3Bucket": "BUCKET_NAME",
"S3Prefix": "demo_prefix",
"ExportFormat": "DYNAMODB_JSON"
}
}エクスポートをリクエストした後、ExportStatus が「COMPLETED」 になるまで待つ必要があります。
aws dynamodb list-exports
{
"ExportSummaries": [
{
"ExportArn": "arn:aws:dynamodb:REGION:ACCOUNT_ID:table/TABLE_NAME/export/EXPORT_ID",
"ExportStatus": "COMPLETED"
}
]
}Amazon Athena を使用してエクスポートされたデータを分析する
データが S3 バケットに安全に保存されたら、Amazon Athena を使用してデータの分析を開始できます。
S3 バケットには多数の gz 圧縮オブジェクトがあり、各オブジェクトには、1 行に 1 つずつ、複数の JSON オブジェクトを含むテキストファイルが含まれています。これらの JSON オブジェクトは、Item フィールドにラップされた DynamoDB アイテムに対応し、選択したエクスポート形式に基づいて異なる構造になっています。
上記のエクスポートプロセスでは、DynamoDB JSON を選択しました。サンプルテーブルのアイテムは単純なゲームのユーザーを表しているため、一般的なオブジェクトは次のようになります。
{
"Item": {
"id": {
"S": "my-unique-id"
},
"name": {
"S": "Alex"
},
"coins": {
"N": "100"
}
}
}この例では、name は文字列で、coins は数値です。
AWS Glue クローラを使用して、データのスキーマを自動検出し、AWS Glue カタログに仮想テーブルを作成することをお勧めします。
ただし、CREATE EXTERNAL TABLE 文を使用して仮想テーブルを手動で定義することもできます。
CREATE EXTERNAL TABLE IF NOT EXISTS ddb_exported_table (
Item struct <id:struct<S:string>,
name:struct<S:string>,
coins:struct<N:string>
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION 's3://my-dynamodb-export-bucket/AWSDynamoDB/{EXPORT_ID}/data/'
TBLPROPERTIES ( 'has_encrypted_data'='true');これで、通常の SQL を使用してクエリを実行したり、Create Table as Select (CTAS) クエリを使用して新しい仮想テーブルを定義したりすることもできます。
DynamoDB JSON 形式では、クエリは次のようになります。
SELECT
Item.id.S as id,
Item.name.S as name,
Item.coins.N as coins
FROM ddb_exported_table
ORDER BY cast(coins as integer) DESC;そして、出力として結果セットを取得します。

パフォーマンスとコストに関する考慮事項
エクスポートプロセスはサーバーレスで、自動的にスケーリングされ、カスタムテーブルスキャンソリューションよりもはるかに高速です。
完了時間は、テーブルのサイズと、テーブル内でデータがどのように均一に分散されているかに左右されます。エクスポートの大部分は 30 分以内に完了します。10 GiB までの小さなテーブルの場合、数分で完了します。テラバイトのオーダーの非常に大きなテーブルの場合、数時間かかる場合があります。リアルタイム分析にデータレイクエクスポートを使用しないため、これは問題にはなりません。通常、データレイクは、大規模なデータを集約し、日次、週次、または月次のレポートを生成するために使用されます。したがって、ほとんどの場合、分析パイプラインを続行する前に、エクスポートプロセスが完了するまで数分または数時間待つ余裕があります。
この新機能のサーバーレスの性質のおかげで、時間単位のコストはかかりません。Amazon S3 にエクスポートされたギガバイトのデータに対してのみ支払います。例えば、米国東部リージョンでは GiB あたり 0.10 USD です。
データは独自の S3 バケットにエクスポートされ、継続的バックアップはエクスポートプロセスの前提条件であるため、DynamoDB PITR バックアップおよび S3 データストレージに関連する追加コストが発生することに注意してください。関連するすべてのコスト要素は、エクスポートするデータの量にのみ依存します。そのため、全体的なコストは簡単に見積もることができ、読み取りスループットが高く、メンテナンスに費用がかかるカスタムソリューションを構築するための総所有コストよりもはるかに低くなります。
今すぐご利用いただけます
この新機能は、継続的バックアップが提供されているすべての AWS リージョンで現在ご利用いただけます。
エクスポートリクエストは、AWS マネジメントコンソール、AWS コマンドラインインターフェイス(CLI)、および AWS SDK を使用して行うことができます。この機能により、デベロッパー、データエンジニア、データサイエンティストは、ETL (抽出、変換、読み込み) 用のカスタムで高価なアプリケーションを設計および構築することなく、DynamoDB テーブルからデータを簡単に抽出して分析できます。
社内の分析ツールを DynamoDB データに接続して、アドホック分析に Amazon Athena を、データの探索と視覚化に Amazon QuickSight を、予測分析に Amazon Redshift と Amazon SageMaker などのサービスを活用できるようになりました。
ー Alex