Amazon Web Services ブログ
AWS Database Migration Service を使用して Amazon Aurora から Amazon S3 にデータをレプリケート
このブログ記事でご紹介するのは、AWS CloudFormation テンプレートを使って Amazon Aurora のようなリレーショナルデータベースから Amazon Simple Storage Service (Amazon S3) にデータをレプリケートできるよう、設定を自動化する方法です。CloudFormation テンプレートのサンプルを使って説明していくので、ニーズに合わせて応用してください。
AWS Database Migration Service (AWS DMS) を使えば、データをあるデータソースから別のデータソースに移行できます。たとえば、Oracle から Aurora、NoSQL から SQL、オンプレミスからクラウドへの移行などがあります。顧客が DMS を利用するのは 1 回限りのデータ移行の場合だけではありません。ETL プロセスの一部として継続的な異種データレプリケーションを行う場合にもよく利用します。それこそがこのブログ記事のテーマです。
ソリューションの概要
アーキテクチャを図で示します。
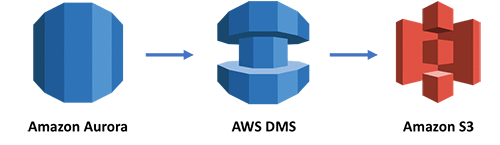
この CloudFormation テンプレートのサンプルは、この例に必須のすべてのリソースを記述しプロビジョニングします。コードは GitHub で探すことができ、テンプレートをスタックとしてデプロイするには [Launch Stack] ボタンをクリックします。注意: us-east-1 リージョンでは、このテンプレートは RDS DB クラスタースナップショットを使用します。スタックを別のリージョンにデプロイしたい場合は、希望するリージョンにスナップショットをコピーして、CloudFormation テンプレート内の SnapshotIdentifier の値を置き換えます。
![]()
このプロセスの開始からスタックが作成されるまでには、約 50 分ほどかかります。このテンプレートは下記の処理を行います。
- AWS DMS Sample Database のスナップショットから Aurora MySQL データベースを作成する。
- Aurora MySQL データベースで DMS に必須の設定を行う。詳細は、MySQL 互換データベースの AWS DMS のソースとしての使用をご覧ください。
- S3 バケットを作成する。
- DMS レプリケーションインスタンスを作成する。
- 必須の IAM アクセス許可と IAM ロールがまだ存在しない場合にその設定を行う。詳細については、AWS DMS を使用するのに必要な IAM アクセス許可をご覧ください。
- DMS ソースエンドポイントとして Aurora データベースを設定する。
- 作成した S3 バケットを DMS ターゲットエンドポイントとして設定する。
- DMS 移行タスクを作成し、既存のデータをロードして継続的な変更をソースエンドポイントからターゲットエンドポイントにレプリケートする。
スタックが作成された後、Aurora から S3 へのレプリケーションをテストできます。以下では、MySQL データベースと DMS を合わせて使用する場合について取り上げます。
MySQL との互換性があるデータベースを DMS のソースとして使用する
このCloudFormation テンプレートは、DMS のソースエンドポイントのサンプルとして機能する Aurora MySQL データベースを作成します。ほかのお好きな MySQL との互換性があるデータベース (MySQL、MariaDB) からデータをレプリケートするようにテンプレートを設定することも可能です。どの MySQL との互換性があるエンジンを選ぶかにかかわらず、DMS のソースとしてデータベースを使用するには、まず一定の前提条件を設定してください。詳細については、MySQL 互換データベースの AWS DMS のソースとしての使用をご覧ください。
DMS は複数の移行メソッドをサポートしています。既存のデータのみを移行するか、既存のデータを移行するとともに継続的な変更をレプリケートするか、あるいは、ソースからターゲットデータベースヘのデータ変更のみをレプリケートすることができます。この例では、既存のデータを移行するとともに継続的な変更をレプリケートする (変更データキャプチャ/CDC) メソッドをとり、既存の、かつ継続的なすべてのデータを Aurora から S3 にレプリケートします。継続的な変更をレプリケートしたいときは、MySQL データベースでバイナリログ記録を有効化する必要もあります。テンプレートがこれを処理します。詳細は、How do I enable binary logging for my Amazon RDS instance running Amazon Aurora MySQL? をご覧ください。
Aurora MySQL で継続的なレプリケーションを有効化する場合、パフォーマンスとクラッシュからの復旧について考慮すべき事項があります。詳細については、AWS Database Migration Service のベストプラクティスおよび “Amazon Aurora の信頼性” の “クラッシュ回復” のセクション をご覧ください。
AWS DMS の IAM アクセス許可を設定する
AWS DMS を使用するには、いくつかの IAM アクセス許可と IAM ロールが必須です。アクセス許可とロールが作成済みでない場合、テンプレートは dms-vpc-role という IAM ロールを設定し、それにより DMS は EC2 インスタンスを作成してレプリケーションインスタンスにネットワークを設定します。また、dms-cloudwatch-logs-role というロールも作成され、レプリケーションインスタンスメトリクスとログを表示させることができます。詳細については、AWS DMS を使用するのに必要な IAM アクセス許可をご覧ください。
Amazon S3 を DMS のターゲットに使用する際にも IAM アクセス許可が追加で必要となりますが、テンプレートは dms-s3-target-role というロールを作成して、ターゲットとなる S3 バケットへの一定のアクセス許可を取得します。詳細については、AWS Database Migration Service のターゲットとしての Amazon S3 の使用をご覧ください。
例をテストする
スタックが作成されたら、CloudFormation コンソールの [Outputs] タブから S3 バケット名および Aurora エンドポイント情報を確認します。下のコンソールの例を参照してください。この情報は後で使用します。

次に、DMS コンソールから以下のステップを実行して DMS タスクを開始します。
- 左のナビゲーションペインで [Tasks] を選択します。
- 作成したタスクを選択します。
- [Start/Resume] を選択します。
タスクの開始後、DMS がソースエンドポイントからターゲットへのデータのロードを開始します。S3 コンソールで自身の S3 バケット名を選択します。
このバケットには dms_sample という名前のフォルダがありますが、ほかにも複数あるフォルダそれぞれがソースデータベースのテーブルに対応しています。各フォルダの中身はサンプルデータの CSV です。初期データロードの完了には最大 10 分かかることがあります。下のコンソールの例を参照してください。

DMS コンソールでタスクの進行状況をモニタリングすることもできます。下にコンソールの例があります。タスクの状況が [Load complete] と表示されたら、ソースデータベースに対してクエリを実行して変更データキャプチャをテストできます。

お好きな MySQL クライアントを使用して Aurora データベースに接続できます。この例では Linux 用 MySQL クライアントを使用してコマンドを紹介します。
ターミナル/シェルからデータベースに接続します。
パスワードを求められたら password と入力します。接続したら、dms_sample データベースを使用します。
このデータベースのサンプルは、トランザクションを生成するよう設計されたプロシージャを含んでいます。トランザクションを生成するには、以下の SQL ステートメントを実行します。
このステートメントは 50 枚のチケットを 0.01 秒ごとの連続購入に対して “販売” します。チケットは 1 ~ 6 のランダムなグループでランダムな人々にランダムな価格で販売されます。各トランザクションの記録は ticket_purchase_hist テーブルに登録されます。データが Aurora データベースから S3 バケットに移行するまで、ほんの少し待たなければならないときがあります。レプリケーションが始まったら、新たな ticket_purchase_hist フォルダが dms_sample フォルダ内に作成されていることを確認できます。中には変更を含んだ CSV ファイルが入っていることが確認できます。下のスクリーンショットを参照してください。
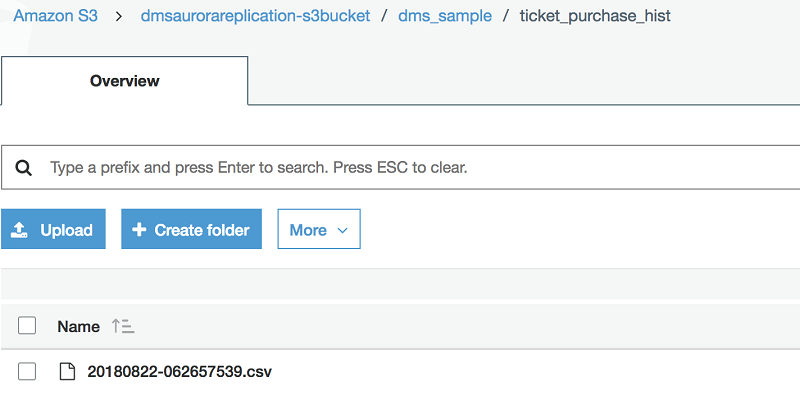
テストに使用できるプロシージャをほかにも探すには、GitHub の SampleDB のページをご覧ください。
最後に
DMS を使用した継続的レプリケーションに CloudFormation テンプレートを活用できることがお分かりいただけたなら幸いです、ぜひ応用してビジネスのニーズをサポートするのにお役立てください。
Amazon S3 にデータを置いているのであれば、 S3 に統合されたほかの AWS サービスを使って新たなワークロードを稼働させるのもよいでしょう。たとえば、別の分析システムにデータを移動させることなく、S3 内のデータでビッグデータ分析を実行することができます。Amazon は以下のような一連のツールを提供しています。
- Amazon Athena –サーバーレスのインタラクティブなクエリサービスにより、SQL を知っている人なら誰でも大量の非構造化データへのオンデマンドのクエリアクセスが可能です。Athena の実際については、Amazon Athena – Amazon S3上のデータに対話的にSQLクエリををご覧ください。
- Amazon Redshift Spectrum – Amazon Redshift に含まれている機能である Spectrum を使えば、データウェアハウスと S3 の両方にまたがる SQL クエリを実行できます。Redshift Spectrum の実際については、Amazon Redshift Spectrum – S3のデータを直接クエリし、エクサバイトまでスケール可能をご覧ください。
- Amazon EMR –マネージド型 Hadoop フレームワークが提供され、大量のデータを、簡単、高速、高コスト効率な方法で処理できます。EMR の詳細については、Amazon EMR によるビッグデータ分析入門をご覧ください。
このブログ記事に関するコメントやご質問は、以下のコメントセクションからお送りください。
今回のブログ投稿者について
 Chris Chang は、アマゾン ウェブ サービスのソリューションアーキテクトです。米国内の新興企業や中小企業と連携し、AWS を使用したスケーラブルで安全なソリューションを構築できるよう、クラウドテクノロジーの導入を支援しています。趣味は、サーフィン、バイク、火を通しすぎないようにディナーを作る方法を模索することです。
Chris Chang は、アマゾン ウェブ サービスのソリューションアーキテクトです。米国内の新興企業や中小企業と連携し、AWS を使用したスケーラブルで安全なソリューションを構築できるよう、クラウドテクノロジーの導入を支援しています。趣味は、サーフィン、バイク、火を通しすぎないようにディナーを作る方法を模索することです。