Amazon Web Services ブログ
S3 Select と Glacier Select – オブジェクトのサブセットを取得
Amazon Simple Storage Service (S3) は、各業界のマーケットリーダーが使用する数百万のアプリケーションのデータを保存しています。セキュアで耐久性のある非常に低コストのアーカイブストレージとして、これらの多くのお客様は Amazon Glacier も使用しています。S3 では、望むだけの数のオブジェクトを格納することができますし、個々のオブジェクトは最大5テラバイトとすることができます。オブジェクトストレージのデータは、通常1エンティティ全体としてアクセスされます。そのことは、例えば 5GB のオブジェクトに対してなんらかの要求をすれば、5GB 全てのデータ取得を行うことを意味します。これはオブジェクトストレージとしては自然なことです。
2017年11月29日、このパラダイムに挑戦すべく、S3とGlacierに2つの新機能を発表します。シンプルなSQL文を利用して、それらのオブジェクトから必要なバイトだけを引き出すことを可能としました。この機能により、S3やGlacierのオブジェクトにアクセスするすべてのアプリケーションが強化されます。
S3 Select
プレビューとして発表された S3 Select により、アプリケーションはシンプルなSQL文を用いて、オブジェクトからデータの一部分のみを取り出すことができます。アプリケーションが必要とするデータのみを取得するので、大幅なパフォーマンス向上が達成でき、400%ほどの改善が見込めることもあります。
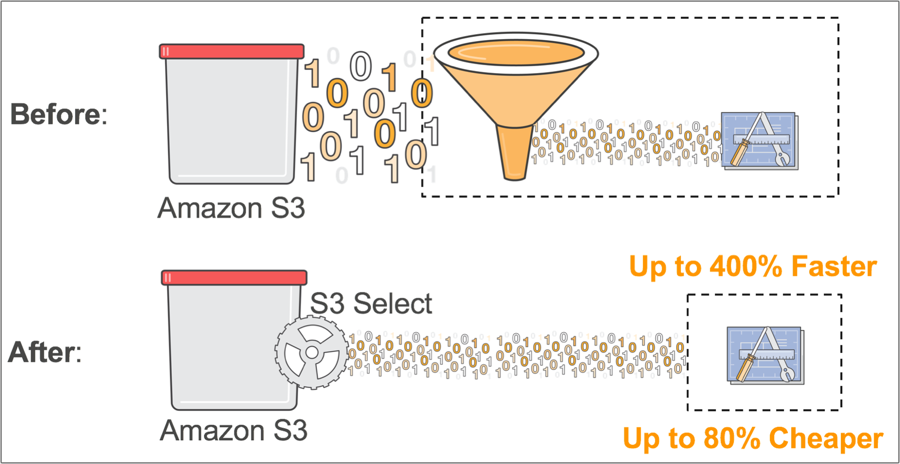
一つの例として、あなたはある大規模な小売業者の開発者の一人で、ある一店舗からの週別売上データを分析する必要があると想像してみてください。しかし、200店舗のデータが日別にGZIPで圧縮されたCSVファイルとして保存されています。S3 Select がない場合、必要なデータを取得するためには、全CSVファイルをダウンロード、解凍、処理する必要があるでしょう。S3 Select があれば、オブジェクト全体を取得するのではなく、関心のあるデータのみを戻すシンプルなSQL式を使うことができます。つまり、データ量が劇的に少なくて済むようになるため、アプリケーションの性能が向上することを意味します。
簡単な Python の例を見てみましょう。
import boto3
from s3select import ResponseHandler
class PrintingResponseHandler(ResponseHandler):
def handle_records(self, record_data):
print(record_data.decode('utf-8'))
handler = PrintingResponseHandler()
s3 = boto3.client('s3')
response = s3.select_object_content(
Bucket="super-secret-reinvent-stuff",
Key="stuff.csv",
SelectRequest={
'ExpressionType': 'SQL',
'Expression': 'SELECT s._1 FROM S3Object AS s'',
'InputSerialization': {
'CompressionType': 'NONE',
'CSV': {
'FileHeaderInfo': 'IGNORE',
'RecordDelimiter': '\n',
'FieldDelimiter': ',',
}
},
'OutputSerialization': {
'RecordOrder': 'STRICT',
'CSV': {
'RecordDelimiter': '\n',
'FieldDelimiter': ',',
}
}
}
)
handler.handle_response(response['Body'])クールですね! この動作を有効にすると、S3 Select はバイナリワイヤプロトコルでオブジェクトを返します。現在のところ、デシリアライゼーションのために小さなライブラリを追加する必要があります。
あらゆる種類のアプリケーションを高速化するために、お客様が S3 Select を使用すると期待しています。たとえば、この部分的なデータ取得機能は AWS Lambda で構築されたサーバーレスアプリケーションで特に役立ちます。Serverless MapReduce のリファレンスアーキテクチャを S3 Select を使用して必要なデータのみを取得するように変更してみたところ、パフォーマンスが2倍向上し、コストが80%削減できました。
また、S3 SelectチームはPrestoコネクタを作成しました。これは、あなたのクエリを変更することなく、Amazon EMR のパフォーマンスを向上させることができます。我々は試しに、ある複雑なクエリを走らせるテストにこのコネクタを使用してみたところ、99%のデータをフィルタリングすることができました。S3 Select をが無効な場合は、PrestoはS3のオブジェクト全体をスキャンしてフィルタリングする必要がありましたが、S3 Select を有効にすると、Prestoクエリに必要なデータのみを取得するために S3 Select を活用します。
[hadoop@ip-172-31-19-123 ~]$ time presto-cli --catalog hive --schema default --session hive.s3_optimized_select_enabled=false -f query.sql
"31.965496","127178","5976","70.89902","130147","6996","37.17715","138092","8678","135.49536","103926","11446","82.35177","116816","8484","67.308304","135811","10104"
real 0m35.910s
user 0m2.320s
sys 0m0.124s
[hadoop@ip-172-31-19-123 ~]$ time presto-cli --catalog hive --schema default --session hive.s3_optimized_select_enabled=true -f query.sql
"31.965496","127178","5976","70.89902","130147","6996","37.17715","138092","8678","135.49536","103926","11446","82.35177","116816","8484","67.308304","135811","10104"
real 0m6.566s
user 0m2.136s
sys 0m0.088sこのクエリはS3 Selectなしで35.9秒かかるものを、S3 Selectを使うと、6.5秒しかかかりませんでした。5倍も速いのです!
補足情報
- プレビュー中の S3 Select では、GZIP 圧縮の有無にかかわらず CSV ファイルまたは JSON ファイルをサポートします。なお、プレビューでは暗号化(at rest)されたオブジェクトはサポートされません。
- プレビュー中は S3 Select の料金はかかりません。
- Amazon Athena、Amazon Redshift、Amazon EMRや、Cloudera、DataBricks、Hortonworksといったパートナが S3 Selectをサポートする予定です。
Glacier Select
金融サービス、ヘルスケア業界の一部の企業は、SEC Rule 17a-4 またはHIPAAのようなコンプライアンスニーズを満たすために Amazon Glacier に直接データを書き込みます。多くのS3ユーザーはライフサイクルポリシーを用いて、定常的にアクセスする必要のなくなったデータをGlacierに移動することによって、ストレージのコストを削減します。オンプレミスのテープライブラリのようなレガシーなアーカイブソリューションは、データを取得するスループットが非常に制限されているため、迅速な分析や処理には適していません。それらのテープの1つに保存されたデータを使用したいとなると、有益な結果を得るのに数週間待たなければならないかもしれません 。一方で、Glacierに保存されたコールドデータは数分以内に簡単に参照できます。
この機能により、アーカイブされたデータに新しいビジネス価値をもたらします。Glacier Select は、標準のSQL文を使用して単一のGlacierオブジェクトに対して直接フィルタリングができます。
Glacier Select はほかの取得ジョブ (retrieval job) と同じように動作しますが、SelectParametersパラメータを追加します。
ここでは簡単な例を示します:
import boto3
glacier = boto3.client("glacier")
jobParameters = {
"Type": "select", "ArchiveId": "ID",
"Tier": "Expedited",
"SelectParameters": {
"InputSerialization": {"csv": {}},
"ExpressionType": "SQL",
"Expression": "SELECT * FROM archive WHERE _5='498960'",
"OutputSerialization": {
"csv": {}
}
},
"OutputLocation": {
"S3": {"BucketName": "glacier-select-output", "Prefix": "1"}
}
}
glacier.initiate_job(vaultName="reInventSecrets", jobParameters=jobParameters)
補足情報
Glacier Select は、Glacier のある全てのリージョンでご利用になれます。
Glacierは以下の3つの要素で価格設定されています。
- データがスキャンされたGB容量
- データが返ってきたGB容量
- Select のリクエスト数
これらの各要素の価格は、Glacierのアーカイブの取り出しオプションによって決まります:迅速(expedited, 1〜5分)、標準(Standard, 3〜5時間)、バルク(Bulk, 5〜12時間)
2018年の近いうちに、Athenaが Glacier Select を利用してGlacierと連携する予定です。
これらの機能を使用して、みなさんのアプリケーションが強化されたり、新しいアプリケーションを構築していただければ幸いです。