Amazon Web Services 한국 블로그
AWS Lambda 함수 AWS Graviton2 프로세서 지원 출시 – Arm 기반 실행 시 34% 향상된 가격 대비 성능 제공
많은 AWS 고객들(예: Formula One, Honeycomb, Intuit, SmugMug 및 Snap Inc.)이 Arm 기반 AWS Graviton2 프로세서를 사용하여 작업을 처리하고, 높은 가성비 혜택을 누리고 있습니다. 오늘부터 여러분도 AWS Lambda 함수에 대해 동일한 혜택을 누릴 수 있습니다. 이제 x86 또는 Arm/Graviton2 프로세서에서 실행되도록 새로운 함수와 기존의 함수를 구성할 수 있습니다.
이 옵션을 이용하여 두 가지 방법으로 비용을 절감할 수 있습니다. 첫째, Graviton2 아키텍처로 인해 함수를 보다 효율적으로 실행할 수 있습니다. 둘째, 실행 시간에 대한 비용을 절감할 수 있습니다. 실제로 Graviton2에 의해 구동되는 Lambda 함수는 20% 더 적은 비용으로 최대 19% 더 높은 성능을 제공하도록 설계되었습니다.
Lambda를 사용하면 함수에 대한 요청 수와 밀리초 단위의 시간(코드를 실행하는 데 걸리는 시간)을 기준으로 요금이 청구됩니다. Arm/Graviton2 아키텍처를 사용하는 함수의 경우 시간 요금은 현재 x86 가격보다 20% 저렴합니다. 프로비저닝된 동시성을 사용하는 함수에 대한 기간 요금에도 동일한 20%의 인하가 적용됩니다.
가격 인하 외에도 Arm 아키텍처를 사용하는 함수는 Graviton2 프로세서에 내장된 성능과 보안의 혜택을 누릴 수 있습니다. 멀티스레딩 및 멀티프로세싱을 사용하거나 많은 I/O 작업을 수행하는 작업에 대해 실행 시간이 단축되고, 그 결과 비용은 더욱 절감됩니다. 이를 통해 최대 10GB의 메모리와 6개의 vCPU를 갖춘 Lambda 함수를 사용할 수 있으므로 특히 유용합니다. 예를 들어 웹 및 모바일 백엔드, 마이크로 서비스 및 데이터 처리 시스템의 성능을 향상시킬 수 있습니다.
함수가 종속성을 포함하여 아키텍처별 바이너리를 사용하지 않는 경우 한 아키텍처에서 다른 아키텍처로 전환할 수 있습니다. 이는 Node.js 및 Python과 같은 해석된 언어를 사용하는 함수나 Java 바이트 코드로 컴파일된 함수에서 자주 발생합니다.
사용자 지정 런타임을 포함하여 Amazon Linux 2 위에 구축된 모든 Lambda 런타임은 지원 종료에 도달한 Node.js 10을 제외하고 Arm에서 지원됩니다. 함수 패키지에 바이너리가 있는 경우, 사용하려는 아키텍처에 대한 함수 코드를 다시 빌드해야 합니다. 컨테이너 이미지로 패키지된 함수는 사용할 아키텍처(x86 또는 Arm)에 맞게 빌드해야 합니다.
아키텍처 간의 차이를 측정하기 위해 x86용과 Arm용으로 각각 하나씩, 두 가지 버전의 함수를 만들 수 있습니다. 그런 다음 가중치를 사용하여 별칭을 통해 함수에 트래픽을 전송하여 두 버전 간에 트래픽을 배포할 수 있습니다. Amazon CloudWatch에서 함수 버전 별로 성능 지표가 수집되며, 통계를 사용하여 주요 지표(예: 시간)를 확인할 수 있습니다. 그런 다음 두 아키텍처 간의 평균 및 p99 시간 등을 비교할 수 있습니다.
또한 함수 버전과 가중 별칭을 사용하여 프로덕션에서 롤아웃을 제어할 수 있습니다. 예를 들어 새 버전을 소량의 호출(예: 1%)에 대해 배포한 다음 전체 배포에 대해 100%까지 늘릴 수 있습니다. 롤아웃 중에 지표에 의심스러운 항목이 표시되는 경우(예: 오류 증가), 가중치를 낮추거나 0으로 설정할 수 있습니다.
몇 가지 예를 통해 이 새로운 기능이 실제로 어떻게 작동하는지 살펴보겠습니다.
바이너리 종속성이 없는 함수의 아키텍처 변경
바이너리 종속성이 없는 경우 Lambda 함수의 아키텍처를 변경하는 것은 스위치를 누르는 것과 같습니다. 예를 들어 저는 얼마 전에 Lambda 함수로 퀴즈 앱을 만들었습니다. 이 앱에서 사용자는 웹 API를 사용하여 질문과 답변을 할 수 있습니다. Amazon API Gateway HTTP API를 사용하여 함수를 트리거합니다. 다음은 첫 부분에 몇 가지 샘플 질문들이 포함된 Node.js 코드입니다.
const questions = [
{
질문:
“당신의 뇌 속에 있는 시냅스(신경 연결)과 우리 은하계에 있는 별들 중 어느 것이 더 많습니까?“,
answers: [
“은하계에 있는 별이 더 많습니다.“,
“뇌 속의 시냅스(신경 연결)가 더 많습니다.“,
“거의 같습니다.“,
],
correctAnswer: 1,
},
{
질문:
“클레오파트라의 생존 시기는 는 iPhone 출시 시점과 기자 피라미드 건설 시점 중 어느 쪽과 더 가깝습니까?“,
answers: [
“iPhone 출시 시점.“,
“기자 피라미드 건설 시점.“,
“클레오파트라의 생존 시기는 정확히 두 사건의 중간입니다.“,
],
correctAnswer: 0,
},
{
질문:
“피라미드가 건설되는 동안 맘모스는 지구 상에 존재하고 있었을까요?“,
answers: [
“아니요, 맘모스는 훨씬 전에 멸종되었습니다.“,
“맘모스의 멸종은 그 시점으로 추정됩니다.“,
“예, 그 당시에도 일부 맘모스가 여전히 존재하고 있었습니다.“,
],
correctAnswer: 2,
},
];
exports.handler = async (event) => {
console.log(event);
const method = event.requestContext.http.method;
const path = event.requestContext.http.path;
const splitPath = path.replace(/^\/+|\/+$/g, "").split("/");
console.log(method, path, splitPath);
var response = {
statusCode: 200,
body: "",
};
if (splitPath[0] == "questions") {
if (splitPath.length == 1) {
console.log(Object.keys(questions));
response.body = JSON.stringify(Object.keys(questions));
} else {
const questionId = splitPath[1];
const question = questions[questionId];
if (question === undefined) {
response = {
statusCode: 404,
body: JSON.stringify ({메시지: “질문을 찾을 수 없습니다”}),
};
} else {
if (splitPath.length == 2) {
const publicQuestion = {
question: question.question,
answers: question.answers.slice(),
};
response.body = JSON.stringify(publicQuestion);
} else {
const answerId = splitPath[2];
if (answerId == question.correctAnswer) {
response.body = JSON.stringify({ correct: true });
} else {
response.body = JSON.stringify({ correct: false });
}
}
}
}
}
return response;
};퀴즈를 시작하기 위해 질문 ID 목록을 요청합니다. 이를 위해서 /questions 엔드포인트에서 HTTP GET과 함께 curl을 사용합니다.
이 함수를 프로덕션에서 사용할 계획입니다. 많은 호출이 예상되며, 저는 비용을 최적화할 수 있는 옵션을 찾고 있습니다. Lambda 콘솔에서 이 함수가 x86_64 아키텍처를 사용하고 있음을 알 수 있습니다.

이 함수는 바이너리를 사용하지 않기 때문에 아키텍처를 arm64로 전환하고 더 낮은 가격의 혜택을 누립니다.

아키텍처의 변경으로 인해 함수가 호출되거나 답변이 전달되는 방식이 변경되지는 않습니다. 즉, API Gateway와의 통합은 물론 다른 애플리케이션 또는 도구와의 통합도 이러한 변경에 의해 영향을 받지 않으며, 이전과 같이 계속 작동합니다.
코드를 실행하는 데 사용된 아키텍처가 백엔드에서 변경되었다는 힌트 없이 퀴즈를 계속합니다. 질문 엔드포인트에 답변 수(0부터 시작)를 추가하여 이전 질문에 답합니다.
정답입니다! 클레오파트라의 생존 시기는 기자 피라미드 건설 시점보다 iPhone 출시 시점과 더 가깝습니다. 이 정보를 이해하는 동안 우리는 Arm으로 함수 마이그레이션을 완료하고 비용을 최적화했음을 알게 되었습니다.
컨테이너 이미지를 사용하여 패키징된 함수의 아키텍처 변경
우리가 컨테이너 이미지를 사용하여 Lambda 함수를 패키징하고 배포하는 기능을 도입했을 때, PDFKit 모듈로 PDF 파일을 생성하는 Node.js 함수로 데모를 수행했습니다. 이 함수를 Arm으로 마이그레이션하는 방법을 살펴보겠습니다.
이 함수는 호출될 때마다 faker.js 모듈에 의해 생성된 임의의 데이터를 포함하고 있는 새 메일을 생성합니다. 함수의 출력은 Amazon API Gateway의 구문을 이용하여 Base64 encoding를 사용하는 PDF 파일을 반환합니다. 편의상 여기에 함수의 코드(app.js)를 복제합니다.
const PDFDocument = require('pdfkit');
const faker = require('faker');
const getStream = require('get-stream');
exports.lambdaHandler = async (event) => {
const doc = new PDFDocument();
const randomName = faker.name.findName();
doc.text(randomName, { align: 'right' });
doc.text(faker.address.streetAddress(), { align: 'right' });
doc.text(faker.address.secondaryAddress(), { align: 'right' });
doc.text(faker.address.zipCode() + ' ' + faker.address.city(), { align: 'right' });
doc.moveDown();
doc.text('Dear ' + randomName + ',');
doc.moveDown();
for(let i = 0; i < 3; i++) {
doc.text(faker.lorem.paragraph());
doc.moveDown();
}
doc.text(faker.name.findName(), { align: 'right' });
doc.end();
pdfBuffer = await getStream.buffer(doc);
pdfBase64 = pdfBuffer.toString('base64');
const response = {
statusCode: 200,
headers: {
'Content-Length': Buffer.byteLength(pdfBase64),
'Content-Type': 'application/pdf',
'Content-disposition': 'attachment;filename=test.pdf'
},
isBase64Encoded: true,
body: pdfBase64
};
return response;
};이 코드를 실행하려면 pdfkit, faker 및 get-stream npm 모듈이 필요합니다. 이러한 패키지 및 그 버전들에 대해 package.json 및 package-lock.json 파일에 설명되어 있습니다.
Dockerfile에서 FROM 라인을 업데이트하여 Arm 아키텍처에 대한 Lambda 용 AWS 기본 이미지를 사용합니다. 기회가 되면 Node.js 14(당시에는 Node.js 12를 사용하고 있었음)를 사용할 수 있도록 이미지를 업데이트합니다. 이것이 아키텍처를 전환하는 데 필요한 유일한 변경입니다.
다음 단계로 앞서 언급했던 게시물을 따릅니다. 이번에는 컨테이너 이미지의 이름과 Lambda 함수의 이름으로 random-letter-arm을 사용합니다. 먼저 이미지를 만듭니다.
그런 다음 이미지를 검사하여 올바른 아키텍처를 사용하고 있는지 확인합니다.
함수가 새 아키텍처에서 작동하는지 확인하기 위해 컨테이너를 로컬에서 실행합니다.
컨테이너 이미지에 Lambda 런타임 인터페이스 에뮬레이터가 포함되어 있으므로, 로컬에서 함수를 테스트할 수 있습니다.
제대로 작동합니다! 응답은 API Gateway에 대한 base64로 인코딩된 응답을 포함하는 JSON 문서입니다.
제 Lambda 함수가 arm64 아키텍처에서 제대로 작동한다는 확신을 가지고 AWS Command Line Interface(CLI)를 사용하여 새로운 Amazon Elastic 컨테이너 레지스트리 저장소를 생성합니다.
이미지에 태그를 지정하고 저장소로 푸시합니다.
Lambda 콘솔에서 random-letter-arm 함수를 생성하고 컨테이너 이미지에서 함수를 생성하는 옵션을 선택합니다.

함수 이름을 입력하고, ECR 저장소를 찾아 random-letter-arm 컨테이너 이미지를 선택한 다음, arm64 아키텍처를 선택합니다.

이제 테이블 생성을 완료했습니다. 그런 다음, API Gateway를 트리거로 추가합니다. 간단하게 만들기 위해 API 인증은 선택하지 않습니다.

이제 API 엔드포인트를 몇 번 클릭하여 임의의 데이터로 생성된 일부 PDF 메일을 다운로드합니다.

이 Lambda 함수를 Arm으로 마이그레이션하는 작업이 완료되었습니다. 대상 아키텍처를 지원하지 않는 특정 종속성이 있는 경우 프로세스가 달라집니다. 컨테이너 이미지를 로컬에서 테스트하는 기능은 프로세스 초기에 문제를 찾아 해결하는 데 도움이 됩니다.
함수 버전 및 별칭을 사용한 서로 다른 아키텍처 간의 비교
함수가 CPU를 의미있게 사용하게 하기 위해 다음 Python 코드를 사용합니다. 이 코드는 매개 변수로 전달된 한도까지 모든 소수를 계산합니다. 여기에서 가능한 최고의 알고리즘, 즉, Sieve of Eratosthenes를 사용하지는 않지만, 이는 메모리를 효율적으로 사용하기 위한 좋은 절충안입니다. 가시성을 높이기 위해 함수가 사용하는 아키텍처를 함수의 응답에 추가합니다.
import json
import math
import platform
import timeit
def primes_up_to(n):
primes = []
for i in range(2, n+1):
is_prime = True
sqrt_i = math.isqrt(i)
for p in primes:
if p > sqrt_i:
break
if i % p == 0:
is_prime = False
break
if is_prime:
primes.append(i)
return primes
def lambda_handler(event, context):
start_time = timeit.default_timer()
N = int(event['queryStringParameters']['max'])
primes = primes_up_to(N)
stop_time = timeit.default_timer()
elapsed_time = stop_time - start_time
response = {
'machine': platform.machine(),
'elapsed': elapsed_time,
'message': '{}개의 소수가 있습니다 <= {}'.format(len(primes), N)
}
return {
'statusCode': 200,
'body': json.dumps(response)
}서로 다른 아키텍처를 사용하여 두 가지 함수 버전을 만듭니다.

호출을 균등하게 분산하기 위해 x86 버전에서는 50%의 가중치를 가진 가중 별칭을, Arm 버전에서는 50%의 가중치를 가진 가중 별칭을 사용합니다. 이 별칭을 통해 함수를 호출할 때 서로 다른 두 아키텍처에서 실행되는 두 버전이 동일한 확률로 실행됩니다.

함수 별칭에 대한 API Gateway 트리거를 만든 다음, 랩톱에서 몇 개의 터미널을 사용하여 약간의 부하를 생성합니다. 각 호출은 최대 백만 개의 소수를 계산합니다. 출력에서 두 개의 서로 다른 아키텍처가 어떻게 함수를 실행하는지 확인할 수 있습니다.
이러한 실행 중에 Lambda는 지표를 CloudWatch로 전송하고 함수 버전(실행 버전)은 차원 중 하나로 저장됩니다.
무슨 일이 일어나고 있는지 더 잘 이해하기 위해 CloudWatch 대시 보드를 만들어 두 아키텍처의 p99 시간을 모니터링합니다. 이러한 방식으로 이 함수에 대한 두 환경의 성능을 비교하고, 프로덕션 환경에서 사용할 아키텍처에 대해 정보에 입각한 결정을 내릴 수 있습니다.

이러한 특정 워크로드의 경우 Graviton2 프로세서에서 함수가 훨씬 빠르게 실행되므로 사용자 경험이 개선되고 비용이 크게 절감됩니다.
Lambda 파워 튜닝을 이용한 다양한 아키텍처 비교
제 친구 Alex Casalboni가 만든 AWS Lambda Power Tuning 오픈 소스 프로젝트는 다양한 설정을 사용하여 함수를 실행하고, 비용 최소화 및/또는 성능을 최대화를 위한 구성을 제시합니다. 프로젝트가 최근 업데이트되어 동일한 차트에서 두 결과를 비교할 수 있습니다. 이것은 동일한 함수의 두 가지 버전(x86 사용 버전과 Arm 사용 버전)을 비교하는 데 편리합니다.
예를 들어, 이 차트는 이전 게시물에서 사용한 소수를 계산하는 함수에 대해 x86의 결과와 Arm/Graviton2의 결과를 비교합니다.
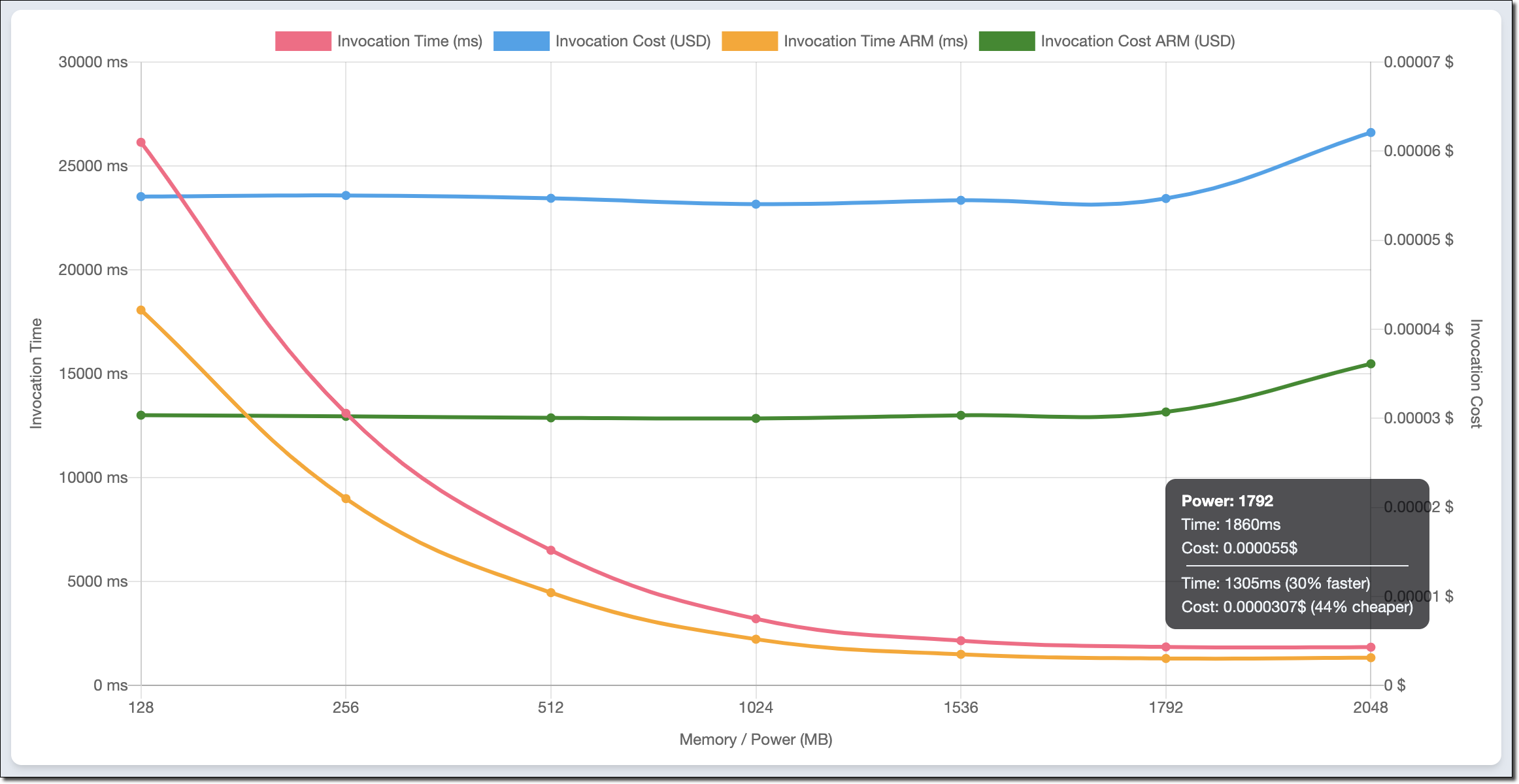
이 함수는 단일 스레드를 사용하고 있습니다. 실제로 메모리가 1.8GB로 구성된 경우, 두 아키텍처에 대해 가장 낮은 기간이 보고됩니다. Lambda 함수는 2개 이상의 vCPU에 액세스할 수 있지만, 이 경우 함수는 추가 권한을 사용할 수 없습니다. 같은 이유로 메모리 용량 1.8GB까지는 비용이 안정적입니다. 메모리가 커질 수록 이 워크로드에 추가적인 성능 혜택이 없으므로 비용이 증가합니다.
차트를 보고 1.8GB의 메모리와 Arm 아키텍처를 사용하도록 함수를 구성합니다. Graviton2 프로세서는 컴퓨팅 집약적 함수에 대해 명백히 더 좋은 성능과 낮은 비용을 제공합니다.
가용성 및 요금
현재 미국 동부(버지니아 북부), 미국 동부(오하이오), 미국 서부(오레곤), 유럽(프랑크푸르트), 유럽(아일랜드), EU(런던), 아시아 태평양(뭄바이), 아시아 태평양(싱가포르), 아시아 태평양(시드니), 아시아 태평양(도쿄)에서 Graviton2 프로세서 기반의 Lambda 함수를 사용할 수 있습니다.
Amazon Linux 2를 기반으로 실행되는 다음 런타임이 Arm에서 지원됩니다.
- Node.js 12 및 14
- Python 3.8 및 3.9
- Java 8(
java8.al2) 및 11 - .NET Core 3.1
- Ruby 2.7
- 사용자 지정 런타임(
.al2 제공)
AWS Serverless Application Model(SAM) 및 AWS Cloud Development Kit(AWS CDK)를 사용하여 Graviton2 프로세서 기반의 Lambda 함수를 관리할 수 있습니다. 또한 AntStack, Check Point, Cloudwiry, Contino, Coralogix, Datadog, Lumigo, Pulumi, Slalom, Sumo Logic, Thundra, Xerris와 같은 많은 AWS Lambda 파트너들을 통해서도 지원을 받을 수 있습니다.
Arm/Graviton2 아키텍처를 사용하는 Lambda 함수는 최대 34%의 가격 대비 성능 향상을 제공합니다. 시간 비용의 20% 절감은 프로비저닝된 동시성 사용 시에도 적용됩니다. Compute Savings Plans을 사용하면 비용을 최대 17%까지 추가로 절감할 수 있습니다. Graviton2를 기반으로 하는 Lambda 함수는 기존 한도까지 AWS 프리 티어에 포함됩니다. 자세한 내용은 AWS Lambda 요금 페이지를 참조하세요.
AWS Graviton2 프로세서에 대해 워크로드를 최적화하기 위한 도움말은 AWS Graviton 시작하기 저장소에서 확인할 수 있습니다.
지금 Arm에서 Lambda 함수를 실행하세요.
— Danilo