亚马逊AWS官方博客
新 – 适用于您的 Lambda 函数的共享文件系统
我很高兴地宣布 AWS Lambda 函数现在可以挂载 Amazon Elastic File System (EFS),后者是可扩展的弹性 NFS 文件系统,可跨多个可用区 (AZ) 及在其内部存储数据,以实现高可用性和持久性。以后,您可以使用熟悉的文件系统接口来跨一个或多个 Lambda 函数的全部并发执行环境存储与共享数据。EFS 支持全文件系统访问语义,如强一致性和文件锁定。
要连接 EFS 文件系统和 Lambda 函数,您要使用 EFS 接入点,它是特定于应用程序的 EFS 文件系统入口点,该系统包括当访问文件系统和文件系统权限时要使用的操作系统用户和组,而且可以限制访问文件系统中的特定路径。 这有助于使文件系统配置从应用程序代码保持解耦。
您可以使用相同或不同的接入点从多个函数访问同一个 EFS 文件系统。例如,通过使用不同的 EFS 接入点,每个 Lambda 函数都可以访问文件系统中的不同路径,或使用不同的文件系统权限。
您可以与 Amazon Elastic Compute Cloud (EC2) 实例、使用 Amazon ECS 和 AWS Fargate 的容器化应用程序和本地服务器共享同一个 EFS 文件系统。按照此方法,您可以使用不同的计算架构(函数、容器、虚拟服务器)来处理相同的文件。例如,对事件做出响应的 Lambda 函数可以更新由在容器上运行的应用程序读取的配置文件。或者,您还可以使用 Lambda 函数来处理由在 EC2 上运行的 Web 应用程序上传的文件。
通过这种方式,使用 Lambda 函数更易于实现部分用例。例如:
- 处理或加载大于
/tmp中可用空间 (512MB) 的数据。 - 加载经常变动的文件的最新版本。
- 使用需要存储空间以加载模型及其他依赖项的数据科学程序包。
- 跨调用保存函数状态(使用唯一的文件名称或文件系统锁定)。
- 构建需要访问大量参考数据的应用程序。
- 将传统应用程序迁移到无服务器架构。
- 与专门为文件系统访问设计的数据密集型工作负载进行交互。
- 对文件进行部分更新(使用适用于并发访问的文件系统锁定)。
- 通过原子操作移动文件系统内的目录及其内容。
创建 EFS 文件系统
要挂载 EFS 文件系统,您的 Lambda 函数必须连接至可以访问 EFS 挂载目标的 Amazon Virtual Private Cloud。 为简单起见,我在这里使用每个 AWS 区域中自动创建的默认 VPC。
请注意,在将 Lambda 函数连接至 VPC 时,网络的运行方式会有所不同。如果您的 Lambda 函数使用 Amazon Simple Storage Service (S3) 或 Amazon DynamoDB,您应该为这些服务创建一个网关 VPC 终端节点。若 Lambda 函数需要访问公共 Internet(例如,调用外部 API),您则需要配置 NAT 网关。我通常不会更改默认 VPC 的配置。如果有特定的要求,我会通过 AWS Cloud Development Kit 新建一个具有公有或私有子网的 VPC,或者使用这些 AWS CloudFormation 示例模板的其中一个。这样一来,我就可以把网络当做代码进行管理。
在 EFS 控制台中,我会选择创建文件系统,并确保已选择默认 VPC 及其子网。针对所有子网,我会使用默认安全组,该安全组将提供对使用相同安全组的 VPC 中的其他资源进行网络访问的权限。

在下一个步骤中,我会为文件系统提供名称标签,并保留其他全部选项的默认值。

然后,我会选择添加接入点。我会使用 1001 作为用户和组的 ID,并且限制访问 /message 路径。在用于首次连接至接入点时自动创建文件夹的“拥有者”部分,我会使用与之前相同的用户和组 ID,然后对于权限使用 750。通过此项权限,拥有者可以读取、写入和执行文件。同一个组中的用户只能读取。其他用户则无访问权限。

继续操作以便完成文件系统的创建。
EFS 与 Lambda 函数结合使用
从简单的用例开始,我们先构建一个 Lambda 函数,以实现添加、读取或删除文本消息的 MessageWall API。消息会被存储于 EFS 上的文件中,因此,该 Lambda 函数的全部并发执行环境均可看到相同的内容。
在 Lambda 控制台中,我会创建新的 MessageWall 函数,并选择 Python 3.8 运行时。在权限部分,我会保留默认值。这样做将创建一个新的具有基本权限的 AWS Identity and Access Management (IAM) 角色。
当创建函数时,我会在权限选项卡中单击 IAM 角色名称,以便打开 IAM 控制台中的角色。在这里,我会选择附加策略,以添加 AWSLambdaVPCAccessExecutionRole 和AmazonElasticFileSystemClientReadWriteAccess AWS 托管策略。在生产环境中,您可以限制对特定 VPC 和 EFS 接入点的访问。
回到 Lambda 控制台,我会使用用于 EFS 挂载点的相同默认安全组编辑 VPC 配置,以便将 MessageWall 函数连接至默认 VPC 中的所有子网。
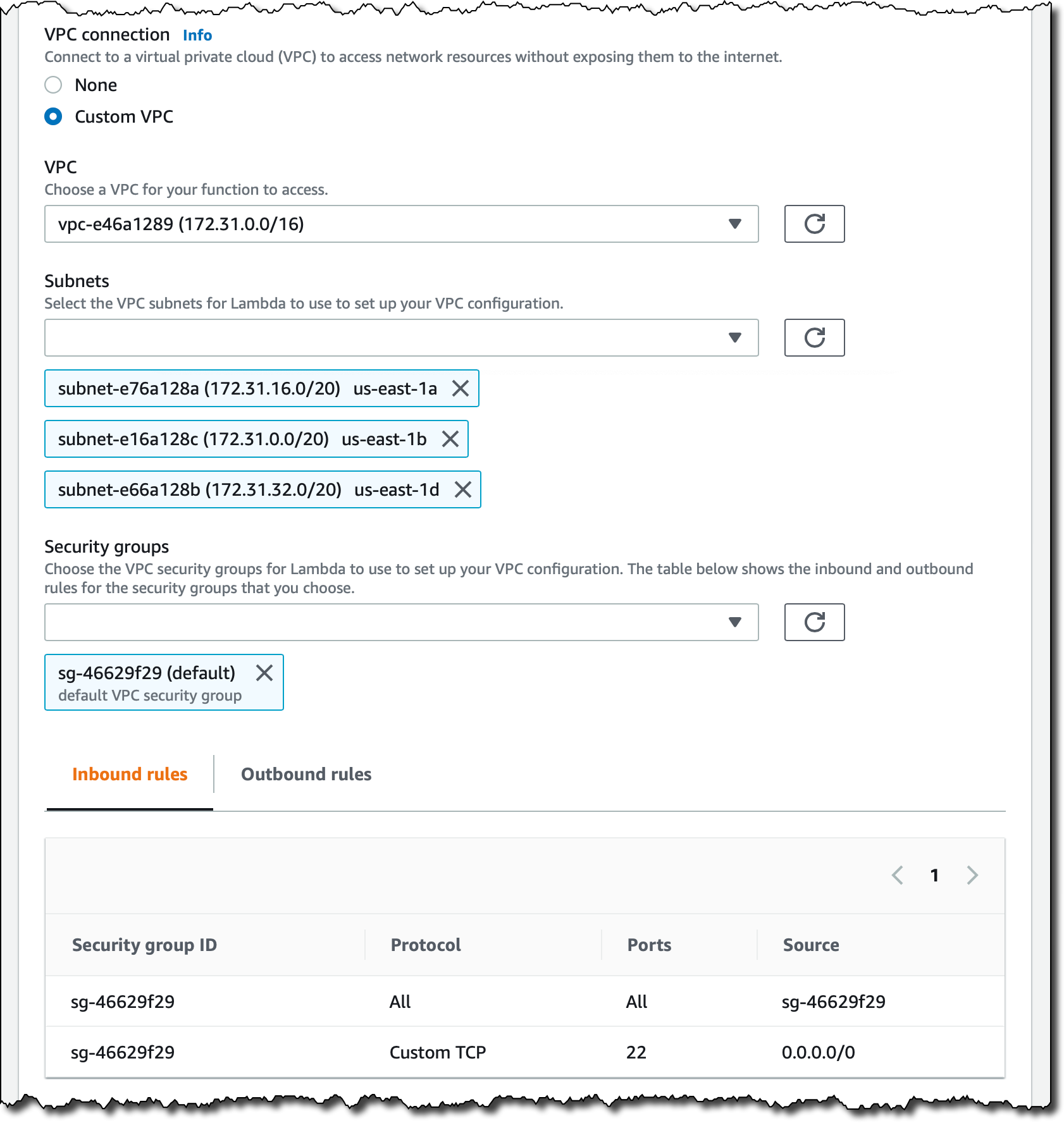
现在,在函数配置的新文件系统部分选择添加文件系统。在这里,我会选择我在之前创建的 EFS 文件系统和接入点。对于本地挂载点,我会使用 /mnt/msg 并保存。这是接入点将被挂载的路径,而且与我的 EFS 文件系统中的 /message 文件夹对应。

在 Lambda 控制台的函数代码编辑器中,粘贴以下代码并保存。
import os
import fcntl
MSG_FILE_PATH = '/mnt/msg/content'
def get_messages():
try:
with open(MSG_FILE_PATH, 'r') as msg_file:
fcntl.flock(msg_file, fcntl.LOCK_SH)
messages = msg_file.read()
fcntl.flock(msg_file, fcntl.LOCK_UN)
except:
messages = 'No message yet.'
return messages
def add_message(new_message):
with open(MSG_FILE_PATH, 'a') as msg_file:
fcntl.flock(msg_file, fcntl.LOCK_EX)
msg_file.write(new_message + "\n")
fcntl.flock(msg_file, fcntl.LOCK_UN)
def delete_messages():
try:
os.remove(MSG_FILE_PATH)
except:
pass
def lambda_handler(event, context):
method = event['requestContext']['http']['method']
if method == 'GET':
messages = get_messages()
elif method == 'POST':
new_message = event['body']
add_message(new_message)
messages = get_messages()
elif method == 'DELETE':
delete_messages()
messages = 'Messages deleted.'
else:
messages = 'Method unsupported.'
return messages
选择“添加”触发器,然后在配置中选择 Amazon API Gateway。我将创建一个新的 HTTP API。为简单起见,我会保持我的 API 终端节点处于开放状态。

在选择 API Gateway 触发器以后,我会复制刚刚创建的新的 API 的终端节点。
现在,我可以使用 curl 对 API 进行测试:
$ curl https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MessageWall
No message yet.
$ curl -X POST -H "Content-Type: text/plain" -d 'Hello from EFS!' https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MessageWall
Hello from EFS!
$ curl -X POST -H "Content-Type: text/plain" -d 'Hello again :)' https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MessageWall
Hello from EFS!
Hello again :)
$ curl https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MessageWall
Hello from EFS!
Hello again :)
$ curl -X DELETE https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MessageWall
Messages deleted.
$ curl https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MessageWall
No message yet.为不同用户添加唯一的文件名称(或特定子目录),并且将此简单的示例扩展到更加复杂的消息收发应用程序,这样的做法相对比较容易。作为一名开发人员,我非常重视在代码中使用熟悉的文件系统接口所能带来的简便性。不过,根据您的需求,必须将 EFS 吞吐量配置纳入考虑范围。见本文后半部分的理解 EFS 性能以了解更多信息。
现在,我们将使用 AWS Lambda 中新的 EFS 文件系统支持来构建一些更有趣的架构。例如,我们要使用 EFS 以更多可用空间构建一个机器学习推理 API 来处理图片。
构建无服务器机器学习推理 API
要创建执行机器学习推理的 Lambda 函数,我需要能够在我的代码中导入必要的库并加载机器学习模型。在这样做时,这些依赖项的整体大小经常会超出部署程序包大小中的当前 AWS Lambda 限制。解决此问题的方法之一是,准确地将函数代码随带的库最小化,然后从 S3 存储桶将模型直接下载到内存(最大达到 3 GB,包括处理模型所需的内存)或 /tmp(最大为 512 MB)。要执行此模型的自定义最小化与下载从来都不容易。现在,我便可以使用 EFS 文件系统了。
我此时所构建的 Lambda 函数需要访问公共 Internet,以下载预先训练的模型和图片,以便在其之上运行推理。因此,我要创建具有公有和私有子网的新 VPC,配置私有子网所使用的 NAT 网关和路由表,以便提供对公共 Internet 的访问权限。使用 AWS Cloud Development Kit,只需数行代码即可完成此操作。
我会在使用与之前类似配置的新 VPC 中创建新的 EFS 文件系统和接入点。这时候,我会为接入点路径使用 /ml。
然后创建权限设置与之前相同的新的 MLInference Lambda 函数,并且将该函数连接至新 VPC 的私有子网。机器学习推理是一项密集型工作负载,所以,我会为内存和超时分别选择 3 GB 和 5 分钟。在文件系统配置中,添加新的接入点,并将其挂载到 /mnt/inference 下方。
我为此函数所使用的机器学习框架是 PyTorch,而且我需要在 EFS 文件系统中放置运行推理所需的库。在新 VPC 的公有子网中启动 Amazon Linux EC2 实例。在实例详细信息中,选择一个有 EFS 挂载点的可用区,然后添加文件系统以自动挂载我为该函数所使用的相同 EFS 文件系统。对于 EC2 实例的安全组,我会选择默认安全组(能够挂载 EFS 文件系统)以及为 SSH 提供入站访问的安全组(能够连接至实例)。
我会使用 SSH 连接至实例,并且创建一个包含我需要的依赖项的 requirements.txt 文件:
torch
torchvision
numpy
EFS 文件系统将由 EC2 自动挂载到 /mnt/efs/fs1 下方。然后,创建 /ml 目录,并将路径的拥有者更改为我正在使用而且目前所连接的用户和组 (ec2-user)。
$ sudo mkdir /mnt/efs/fs1/ml
$ sudo chown ec2-user:ec2-user /mnt/efs/fs1/ml我会安装 Python 3,并在 /mnt/efs/fs1/ml/lib 路径中使用 pip 来安装依赖项:
$ sudo yum install python3
$ pip3 install -t /mnt/efs/fs1/ml/lib -r requirements.txt
最后,我会将整个 /ml 路径的所有权赋予在为 EFS 接入点所使用的用户和组:
$ sudo chown -R 1001:1001 /mnt/efs/fs1/ml
总得来说,我的 EFS 文件系统中的依赖项共使用大约 1.5 GB 的存储空间。
现在回头再讨论 MLInference Lambda 函数配置。根据所使用的运行时,您需要找到方法,当依赖项不包含在部署程序包或层中时,判断要在哪里查找它们。在 Python 例子中,我将 PYTHONPATH 环境变量设置为 /mnt/inference/lib。
接下来,我会使用 PyTorch Hub 来下载此预先训练的机器学习模型,以便识别图片中的鸟的种类。我为此示例使用的模型相对较小,约为 200 MB。要在 EFS 系统文件上缓存该模型,将 TORCH_HOME 环境变量设置为 /mnt/inference/model。

现在,在文件系统中,函数已挂载所有依赖项,而且我可以直接在函数代码编辑器中键入我的代码。粘贴以下代码以便获得一个机器学习推理 API:
import urllib
import json
import os
import torch
from PIL import Image
from torchvision import transforms
transform_test = transforms.Compose([
transforms.Resize((600, 600), Image.BILINEAR),
transforms.CenterCrop((448, 448)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
model = torch.hub.load('nicolalandro/ntsnet-cub200', 'ntsnet', pretrained=True,
**{'topN': 6, 'device': 'cpu', 'num_classes': 200})
model.eval()
def lambda_handler(event, context):
url = event['queryStringParameters']['url']
img = Image.open(urllib.request.urlopen(url))
scaled_img = transform_test(img)
torch_images = scaled_img.unsqueeze(0)
with torch.no_grad():
top_n_coordinates, concat_out, raw_logits, concat_logits, part_logits, top_n_index, top_n_prob = model(torch_images)
_, predict = torch.max(concat_logits, 1)
pred_id = predict.item()
bird_class = model.bird_classes[pred_id]
print('bird_class:', bird_class)
return json.dumps({
"bird_class": bird_class,
})添加 API Gateway 作为触发器,类似于之前为 MessageWall 函数所做的那样。 现在,我可以使用刚刚创建的无服务器 API 来分析鸟的图片。我并非此领域的专家,因此,我在 Wikipedia 上查了一些有趣的图片:


我会调用 API 对这两张图片进行预测:
$ curl https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MLInference?url=https://path/to/image/atlantic-puffin.jpg
{"bird_class": "106.Horned_Puffin"}
$ curl https://1a2b3c4d5e.execute-api.us-east-1.amazonaws.com/default/MLInference?url=https://path/to/image/western-grebe.jpg
{"bird_class": "053.Western_Grebe"}成功了! 在 Amazon CloudWatch Logs 中查找 Lambda 函数时,我发现首次调用,亦即函数在 CPU 上为推理加载和准备预先训练的模型所用的时间约为 30 秒。为避免响应过慢,或 API Gateway 超时,我会使用预置并发将函数准备就绪。后续调用大概花了 1.8 秒。
理解 EFS 性能
在结合使用 EFS 和您的 Lambda 函数时,理解 EFS 性能表现如何非常重要。对于吞吐量,每个文件系统都可以被配置为使用突发或预置模式。
当使用突发模式时,所有 EFS 文件系统,不论其大小,都可以突增至至少 100 MiB/秒吞吐量。这些在标准存储类别中超过 1 TiB 的系统则可以按照文件系统中存储的每 TiB 数据突增至 100 MiB/秒。 EFS 使用积分系统来确定文件系统何时突增。每个文件系统随着时间推移以基线速率获得积分,而该速率由存储于标准存储类别中的文件系统大小决定。文件系统会在读取或写入数据时使用积分。每 GiB 存储的基线速率为 50 KiB/秒。
您可以监控 CloudWatch 中积分的使用情况,每个 EFS 文件系统都有一项 BurstCreditBalance 指标。如果发现您正在使用全部积分,而且 BurstCreditBalance 指标降为零,您应该为文件系统启用预置吞吐量模式,从 1 设置为 1024 MiB/秒。根据您在基线速率的基础上增加多少吞吐量,使用预置吞吐量时会产生额外成本。
为避免积分用尽,您应该将该吞吐量视为平时所需的平均值。例如,如果有一个 10GB 文件系统,您的基线速率为 500 KiB/秒,那么每天您可以读取/写入 500 KiB/秒 * 3600 秒 * 24 小时 = 43.2 GiB。
如果在初始化期间您的函数需要加载的库和其他内容达到大约 2 GiB,而且您只在函数初始化时访问 EFS 文件系统,如上述的 MLInference Lambda 函数,这意味着每天对您的函数进行 20 次左右初始化(例如,要更新或对活动进行扩展)。次数不多,而且您很可能需要为 EFS 文件系统配置预置吞吐量。
如果您的预置吞吐量为 10 MiB/秒,那么每天的读取或写入为 10 MiB/秒 * 3600 秒 * 24 小时 = 864 GiB。如果您仅在函数初始化时使用 EFS 文件系统来读取大约 2 GB 依赖项,这意味着您可以在每天进行 400 次初始化。对于您的用例来说,这一数字可能足以应付。
在 Lambda 函数配置中,您还可以使用预留并发控制来限制函数所使用的执行环境的最大数量。
如果因为失误,BurstCreditBalance 降为零,而且文件系统相对较小(如几个 GiB),您的函数可能会被卡住,无法在超时前以足够快的速度执行。在这种情况下,您应该启用(或增加)EFS 文件系统的预置吞吐量,或者通过将预留并发设置为零以限制您的函数,从而避免所有调用直到 EFS 文件系统获得足够积分。
理解安全控制
在结合使用 EFS 文件系统和 AWS Lambda 时,您将拥有多个级别的安全控制。我在此做一个快速总结,因为在设计和实现您的无服务器应用程序期间,所有这些都应该被考虑在内。您可以在这篇文章中找到关于结合使用 IAM 授权与接入点,以及 EFS 的更多信息。
要将 Lambda 函数连接到 EFS 文件系统,您需要:
- 在 VPC 路由/对等连接及安全组方面的网络可见性。
- Lambda 函数访问 VPC 与挂载(只读或读取/写入)EFS 文件系统所需的 IAM 权限。
- 您可以在 IAM 策略条件中指定 Lambda 函数可以使用哪个 EFS 接入点。
- EFS 接入点可以限制对文件系统中特定路径的访问。
- 文件系统安全(用户 ID、组 ID、权限)则可以限制对 Lambda 函数所挂载的每个文件或目录的读取、写入或可执行访问。
Lambda 函数执行环境和 EFS 挂载点使用行业标准传输层安全性 (TLS) 1.2 来加密传输中的数据。 您可以预置 Amazon EFS 对静态数据进行加密。静态数据加密显然会在写入时加密,读取时解密,因此您无需修改您的应用程序。加密密钥由 AWS Key Management Service (KMS) 管理,从而消除了构建与维护安全密钥管理基础设施的必要性。
现已推出
此项新功能已在所有提供 AWS Lambda 和 Amazon EFS 的区域内推出,但中国除外,我们正在努力以便尽快在该区域集成这项功能。如需关于可用性的更多信息,请见 AWS 区域表。要了解更多信息,请见相关文档。
适用于 Lambda 的 EFS 可通过控制台、AWS 命令行界面 (CLI)、AWS 开发工具包,以及无服务器应用程序模型进行配置。 此项功能让您可以构建需要处理大文件的数据密集型应用程序。例如,您现在可以通过几行代码即可解压缩 1.5 GB 文件,或处理 10 GB JSON 文档。 您还可以加载大于 AWS Lambda 的 250 MB 程序包部署大小限制的库或程序包,实现新的机器学习、数据建模、金融分析和 ETL 作业场景。
AWS 合作伙伴网络解决方案在启动时支持适用于 Lambda 的 Amazon EFS,包括 Epsagon、Lumigo、Datadog、HashiCorp Terraform,以及 Pulumi。
从 Lambda 函数使用 EFS 不会产生额外费用。您要支付 AWS Lambda 和 Amazon EFS 的标准价格。Lambda 执行环境始终连接至可用区内正确的挂载目标,而不是跨可用区。您可以通过跨账户 VPC 连接至相同可用区内的 EFS,但可能会产生数据传输成本。我们不支持 EFS 和 Lambda 之间的跨区域或跨可用区连接。
– Danilo