Blog de Amazon Web Services (AWS)
Transformar los datos masivos del TR-069 en información con AWS IoT Core y los servicios de análisis en AWS
Intro
Los proveedores de servicios de comunicación (CSPs) generalmente administran millones de dispositivos de sus clientes (CPE) para proporcionar una variedad de servicios. Existen varios tipos de dispositivos en función de las tecnologías de comunicación utilizadas. Los módems de cable y xDSL, los decodificadores y los enrutadores inalámbricos son algunos ejemplos de los tipos de equipos que vemos en los entornos de los clientes.
Para administrar estos dispositivos, muchos CSPs utilizan el protocolo TR-069 del Broadband Forum (también conocido como CPE WAN Management Protocol o CWMP). Este protocolo permite una forma estandarizada de administrar diferentes tipos de CPEs, lo que permite a los CSP reutilizar la capa de administración en diferentes tipos de dispositivos mediante un software de administración denominado Auto Configuration Server (ACS). Hay varios proveedores de ACS que han implementado satisfactoriamente el protocolo y brindan servicios a los CSP para administrar sus flotas de dispositivos de manera eficaz.
Las primeras versiones del protocolo TR-069 no definían una forma específica de recopilar la información de telemetría del dispositivo. Inicialmente, las ACS utilizaban operaciones definidas por el protocolo, como getParameterValues, o información periódica, para recopilar algunos datos de telemetría de los dispositivos en intervalos específicos. Sin embargo, esta forma de recopilación de datos trajo problemas de escalabilidad, especialmente para flotas con millones de dispositivos. Al ver este problema, el Broadband Forum introdujo una nueva forma de recopilar información de telemetría de dispositivos, llamada “recopilación masiva de datos” y la incluyó en las últimas versiones del TR-069.
La función de recopilación masiva de datos crea un canal de recopilación de datos independiente con el fin de enviar información de telemetría a otro destino que no sea el ACS. Este enfoque crea una segregación que separa la gestión de la configuración de la gestión del rendimiento, lo que permite que estas funciones escalen de forma independiente.
El año pasado, AWS publicó un diagrama de arquitectura de referencia para el TR-069 en AWS, en el que se muestra cómo se pueden utilizar los servicios de AWS para recopilar datos de telemetría de dispositivos a fin de generar información.
En esta entrada de blog, explicaré los casos de uso que vemos en la industria para el uso de datos de telemetría de CPE y mostraré una implementación del TR-069 utilizando la arquitectura de referencia de AWS.
Enfoque
Hay algunos casos de uso comunes en los que los CSP pueden utilizar los datos de telemetría del CPE. En este blog, explicaré cinco de estos casos de uso y cómo se pueden tratar en AWS, procesando los datos obtenidos a través de los datos masivos del TR-069:
- Dashboards (Paneles en tiempo real)
- Heartbeat (detección de la salud de los servicios)
- Circuito cerrado (detección de anomalías y automatización de circuito cerrado)
- Mantenimiento predictivo
- Análisis e informes de datos históricos
En las siguientes secciones, describo estos casos de uso y presento una propuesta arquitectónica para abordarlos en AWS.
Dashboards en tiempo real
Los dashboards en tiempo real suelen ser el primer requisito para los proyectos de recopilación masiva de datos. Estos dashboards permiten mostrar los datos procesados o brutos (raw data) tan pronto como sea posible después de la ingestión. Los dashboards en tiempo real permiten al equipo de operaciones ver las métricas sin procesar en tiempo real, así como las métricas derivadas para respaldar las operaciones y la resolución de problemas.
Detección de heartbeats (salud de los servicios)
La detección de heartbeats permite a los CSP detectar dispositivos que están desconectados. Esta detección se puede implementar de diversas maneras. Con la recopilación de datos masivos a través de HTTPS, normalmente se utiliza una aplicación de análisis de transmisión dinámica para rastrear si un dispositivo en particular envió datos dentro de un período de tiempo definido. En algunas implementaciones, el software de panel de control en tiempo real también se puede usar para detectar el heartbeat de los dispositivos. Si MQTT implementa la recopilación masiva de datos, las desconexiones del dispositivo se pueden detectar inmediatamente porque hay una conexión persistente entre el dispositivo y el MQTT.
Detección y automatización de anomalías en circuito cerrado (closed-loop)
La detección de anomalías es otro caso de uso común para procesar datos de telemetría. Ciertas métricas, como la utilización de la CPU, la utilización de la memoria o la velocidad de transferencia, se pueden utilizar para crear líneas base y el sistema puede crear alertas para situaciones en las que las lecturas actuales se desvíen de esas líneas. Para detectar anomalías puntuales, que no requieren un enfoque basado en el aprendizaje automático (Machine Learning – ML), son eficaces las comprobaciones sencillas basadas en límites. La detección de una tasa de error creciente en una interfaz es un ejemplo de este tipo de anomalías.
Una vez detectada la anomalía, se deben tomar medidas para corregirla. Si la anomalía requiere una acción manual, normalmente se convierte en una alerta o una llamada de problema en los sistemas de soporte de operaciones (OSS) del CSP para su seguimiento y gestión. Si la anomalía se puede resolver mediante una acción automática (como reiniciar el dispositivo o cambiar el canal de Wi-Fi), se puede intentar corregirla en un circuito cerrado. En esta configuración, el sistema de recopilación de datos normalmente activa el ACS para iniciar una acción correctiva en el dispositivo problemático. Las automatizaciones de circuito cerrado funcionan casi en tiempo real.
Mantenimiento predictivo
El mantenimiento predictivo tiene como objetivo resolver los problemas antes de que ocurran. Por ejemplo, el monitoreo continuo de los niveles de voltaje de la batería de un dispositivo puede identificar los problemas de la batería antes de que causen falta de disponibilidad. El análisis de mantenimiento predictivo generalmente requiere datos históricos, no se realiza en tiempo real y se puede realizar en lotes. Evitar el envío innecesario de equipos de mantenimiento puede aportar importantes ahorros de costes a los CSPs y, al mismo tiempo, mejorar la experiencia del cliente.
Análisis e informes de datos históricos
Los informes históricos son otro caso de uso común. Los datos históricos del dispositivo se pueden utilizar para entrenar modelos de aprendizaje de máquina para los casos de uso basados en ML que mencioné anteriormente. Otro uso de esto es para resolver los problemas de los clientes. Por ejemplo, un cliente puede llamar al centro de llamadas y quejarse de un problema de rendimiento recurrente que ocurre en ciertos momentos de la semana. Es posible que no sea posible identificar la causa raíz del problema del cliente sin analizar los datos históricos. El análisis de datos históricos también se utiliza con fines de análisis de datos exploratorios. Los dispositivos generalmente emiten cientos de métricas. Es necesario explorar los datos brutos disponibles para identificar cuáles pueden usarse para resolver los casos de uso mencionados anteriormente o para crear nuevos casos de uso.
Solución
La siguiente arquitectura de solución se utilizará para recopilar datos de CPE y analizarlos para abordar los casos de uso anteriores. Como mencioné anteriormente, esta arquitectura es una implementación basada en la arquitectura de referencia. Según los casos de uso que desee abordar, la implementación puede ser más simple, más compleja o puede utilizar otros servicios de AWS.

Diagrama de arquitectura que muestra cómo se pueden enviar los metadatos de telemetría y CPE a AWS para generar información
En las siguientes secciones, dividiré la arquitectura propuesta en secciones y organizaré las secciones por casos de uso. A continuación, explicaré los pasos comunes de la configuración de dispositivos, la ingestión y el filtrado de datos, la normalización y el enriquecimiento de los datos.
Configuración del dispositivo
El primer paso en la recopilación masiva de datos basada en el TR-069 es configurar el perfil de datos masivos en un dispositivo. El perfil de datos masivos forma parte de los modelos de datos TR-098 o TR-181 y debe configurarse mediante ACS. El perfil de datos masivos incluye parámetros de conexión, como la URL del receptor de datos masivos, el protocolo, el puerto, la información de autenticación, etc. El perfil de datos masivos también incluye qué métricas del modelo de datos se recopilarán y enviarán a un receptor.
En este ejemplo, el mecanismo de envío de datos se basa en POST a través de HTTPS. En este escenario, la flota de CPEs está configurada para enviar métricas de datos masivos a un punto de enlace HTTPS de AWS IoT Core a intervalos específicos configurados en el perfil de datos masivos.
Ingestión de datos
Para la ingestión de datos, utilizamos AWS IoT Core. En AWS IoT Core, existe la opción de configurar una función de AWS Lambda como un autorizador personalizado para el punto de enlace HTTP. La función AWS Lambda, junto con una tabla de Amazon DynamoDB, se utilizan para recopilar y validar la información de nombre de usuario y contraseña de los encabezados HTTP.
Como la ingestión de datos se realiza únicamente a través de HTTP, también se utiliza la funcionalidad de ingesta básica de AWS IoT Core. Esta funcionalidad nos permite «evitar» el intermediario de mensajes (message broker) a lo largo de la ruta de ingestión, lo que permite un flujo de datos más económico.
Una regla de enrutamiento de datos del motor de reglas de IoT de AWS envía los mensajes entrantes a Amazon Kinesis Data Streams. Esta transmisión de datos brutos (canal de datos sin procesar) se utiliza para recopilar y retener estos mensajes.
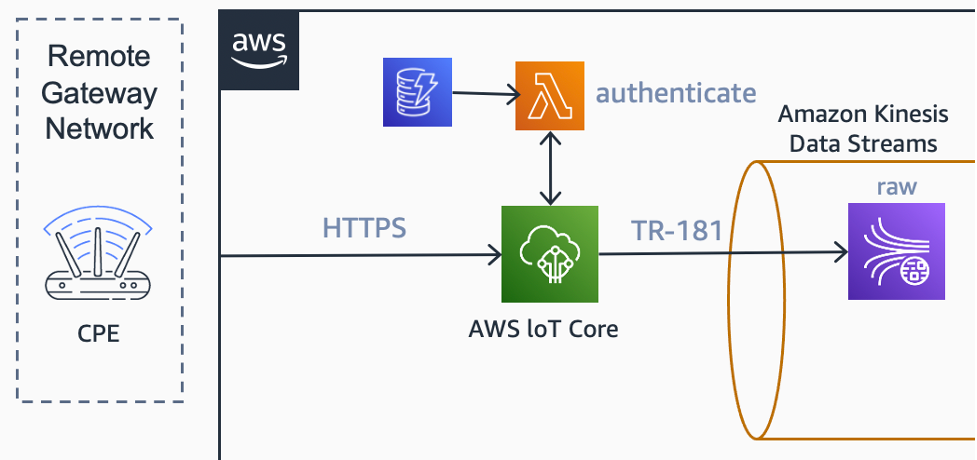 Diagrama de arquitectura que muestra cómo AWS IoT Core puede ingerir los datos de telemetría de CPE
Diagrama de arquitectura que muestra cómo AWS IoT Core puede ingerir los datos de telemetría de CPE
Filtrado, normalización y enriquecimiento de datos
Una aplicación de análisis de flujos, basada en Apache Flink y que se ejecuta en Amazon Kinesis Data Analytics, busca continuamente nuevos mensajes en la transmisión de datos brutos. Esta aplicación filtra, normaliza y convierte el documento JSON, recibido de los CPEs, en el modelo de datos interno, que se utilizará más adelante en el procesamiento de los casos de uso.
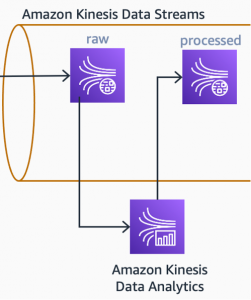 Diagrama arquitectónico que muestra cómo Amazon Kinesis Data Analytics procesa los datos brutos y cómo los graba en otra transmisión
Diagrama arquitectónico que muestra cómo Amazon Kinesis Data Analytics procesa los datos brutos y cómo los graba en otra transmisión
La aplicación que se ejecuta en Kinesis Data Analytics también enriquece los datos. A menudo, encontraremos métricas que son contadores dentro de los datos brutos. Las métricas como BytesSent y BytesReceived son contadores que aumentan continuamente en el dispositivo. Para utilizar este tipo de métricas en el análisis, necesitamos procesarlas y crear métricas derivadas. La velocidad de transferencia de entrada, por ejemplo, se puede calcular a partir de dos puntos de datos consecutivos de BytesReceived y el intervalo de tiempo entre ellos.
Una vez que los datos se enriquecen con métricas derivadas, se pueden escribir en otro flujo: flujo procesado. Este flujo será una entrada para el primer caso de uso posterior: paneles en tiempo real.
Caso de uso 1: paneles en tiempo real (dashboards)
El primer caso de uso que expliqué estaba relacionado con dashboards o paneles en tiempo real. En la arquitectura propuesta, utilizo Amazon Managed Grafana para crear los paneles. Además, también utilizo una función de AWS Lambda para leer los datos recibidos de la transmisión procesada y escribirlos en Amazon Timestream. Amazon Timestream contiene información sobre series temporales, que se puede ver en los paneles de control de Amazon Managed Grafana a través de su plug-in.
 Diagrama de arquitectura que muestra cómo se pueden mostrar los datos procesados en los paneles de control de Amazon Managed Service for Grafana.
Diagrama de arquitectura que muestra cómo se pueden mostrar los datos procesados en los paneles de control de Amazon Managed Service for Grafana.
Un panel de Amazon Managed Grafana puede mostrar muchos detalles según los requisitos del cliente. Las agregaciones como MIN, MAX y AVG se pueden realizar dentro del panel a intervalos de tiempo amplios. Los paneles de Amazon Managed Grafana también permitirán establecer límites en las métricas y mostrar alarmas cuando se superen esos límites.
Caso de uso 2: Detección de la salud de los servicios (heartbeat)
En la arquitectura propuesta, también se utiliza la misma aplicación que se ejecuta en Kinesis Data Analytics para detectar perdidas de heartbeats en el flujo de entrada, ya que no tendrá requisitos de escalabilidad independientes, y supuse que un solo equipo será responsable de Kinesis Data Analytics. Si este no es el caso, debe diseñarse como una lectura separada del flujo sin procesar o del flujo procesado. Esto también se aplica a los casos de uso futuros que se definirán en este blog.
Como Apache Flink es una plataforma de procesamiento de transmisiones controlada por estados, se puede usar para mantener el estado de un dispositivo específico. En este objeto que guarda estados, se pueden guardar la última fecha y hora en que el dispositivo envió la recopilación de datos masiva (bulk data collection) y se pueden usar temporizadores para detectar cuándo un dispositivo pierde un número configurable de intervalos de tiempo. Cuando se detecta una falta de transmisión de datos de los servicios (heartbeats), la aplicación genera un evento de alarma en el flujo de alarma de heartbeats.
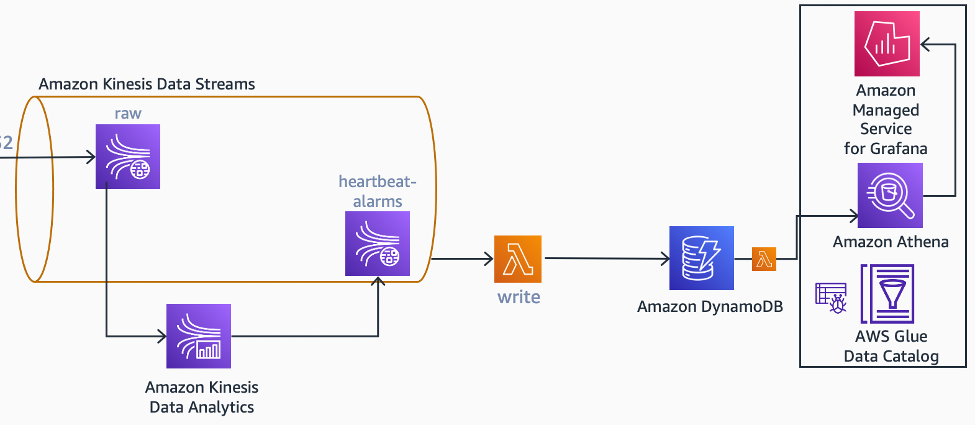 Diagrama arquitectónico que muestra cómo se pueden generar alarmas de heartbeats a partir de datos brutos.
Diagrama arquitectónico que muestra cómo se pueden generar alarmas de heartbeats a partir de datos brutos.
Cuando el dispositivo vuelve a estar en línea (vuelve a transmitir), la misma aplicación de Kinesis Data Analytics genera otro evento, esta vez eliminando la alarma, para la misma transmisión. Una función de AWS Lambda recopila y procesa los eventos de creación y eliminación de alarmas y mantiene una tabla con los dispositivos con alarma de heartbeats en Amazon DynamoDB.
Si es necesario, puede ver esta información en un panel de control. En la arquitectura propuesta, se crea un panel en Grafana gestionado por Amazon, que utiliza Amazon Athena para extraer información de la tabla de dispositivos con falta de transmisión (heartbeat-missing-devices).
Caso de uso 3: detección de anomalías y automatización de circuito cerrado
Como se mencionó anteriormente, hay varias formas de detectar anomalías con métricas. La detección de anomalías basada en límites se puede utilizar en elementos de datos individuales o agregados en función de intervalos de tiempo. Una aplicación de Kinesis Data Analytics también puede detectar anomalías en tiempo real mediante el aprendizaje de máquina (ML) usando un algoritmo RCF (Random Cut Forest) o llamando a un terminal de inferencia previamente entrenado de Amazon SageMaker.
Independientemente del mecanismo utilizado, las anomalías detectadas se pueden utilizar para activar automatizaciones de auto-reparación con o sin la aprobación humana.
En la arquitectura propuesta, una anomalía puntual, detectada mediante un simple límite en una métrica de error, activa un mecanismo de auto-reparación con la aprobación del usuario.
En esta subarquitectura, el flujo de eventos comienza cuando la aplicación Kinesis Data Analytics publica un evento de detección de anomalías en un tópico de Amazon SNS. Este evento incluye el ID del dispositivo asociado a la anomalía. Cuando Amazon SNS recibe el evento, invoca una función Lambda. La función Lambda consulta en una tabla de DynamoDB la información del dispositivo responsable mediante el ID del dispositivo. Una vez que se encuentra la información de la persona responsable, la función Lambda busca el número de teléfono y envía un SMS a la persona responsable mediante Amazon Pinpoint y le solicita su autorización para reiniciar el dispositivo.
 Diagrama arquitectónico que muestra cómo las alarmas de anomalías pueden activar una acción correctiva.
Diagrama arquitectónico que muestra cómo las alarmas de anomalías pueden activar una acción correctiva.
Amazon Pinpoint utiliza su funcionalidad de SMS bidireccionales para recopilar la respuesta del usuario y enviarla a un tema de Amazon SNS. En este tema se pasa la información a una cola FIFO de Amazon SQS, que es consultada por otra función de Lambda. La función Lambda escribe la respuesta del propietario en una tabla de DynamoDB y, si la respuesta es positiva, invoca otra función Lambda. A continuación, la función Lambda interactuará con la interfaz de dirección norte (NBI) del ACS para reiniciar el dispositivo.
Las diferentes anomalías requerirán diferentes mecanismos de autocuración (self-healing). Un análisis de los mecanismos actuales de resolución de problemas y sus factores desencadenantes ayudará a encontrar posibles candidatos para escenarios de autocuración.
Casos de uso 4 y 5: análisis de datos históricos, informes y mantenimiento predictivo
Los datos históricos de los dispositivos pueden desempeñar un papel importante en los casos de uso del análisis de datos históricos y la generación de informes. Estos datos también se pueden utilizar para entrenar algoritmos de aprendizaje automático para detectar anomalías e indicar actividades de mantenimiento predictivo.
La ingesta de datos de telemetría de millones de dispositivos cada minuto conlleva desafíos de escalabilidad, especialmente en lo que respecta al almacenamiento. Se eligió Amazon S3 para la arquitectura propuesta porque tiene una escalabilidad casi ilimitada y una excelente relación costo-beneficio y, por lo tanto, es adecuado para almacenar datos de telemetría.
Los datos procesados y brutos de Amazon Kinesis Data Streams se copian a los cubos procesados y sin procesar, respectivamente. La operación de copia se realiza con Amazon Kinesis Data Firehose. Kinesis Data Firehose organiza los datos en una estructura de carpetas AAAA/MM/DD/HH (año/mes/día/hora) y añade automáticamente prefijos a S3. Como los datos procesados se recuperarán directamente de Amazon Athena, Amazon Kinesis Data Firehose también convierte los datos al formato Parquet para optimizar los costes y la lectura. Las políticas de ciclo de vida de Amazon S3 se configuran en cubos procesados y sin procesar, para mover objetos de la clase de almacenamiento Amazon S3 Standard a clases de almacenamiento más frías tras un período de retención especificado.
Nuestros clientes y socios normalmente necesitan utilizar los datos existentes en el ACS junto con los datos de telemetría. Por lo general, los datos masivos del TR-069 no incluyen metadatos del dispositivo, información como la ubicación, los recursos del dispositivo y otra información de inventario.
Los datos del ACS también se pueden importar a Amazon S3 y se pueden correlacionar con los datos de telemetría de Amazon Athena mediante consultas SQL. Los datos del ACS también se pueden utilizar para enriquecer el flujo de datos en la aplicación Kinesis Data Analytics. En la arquitectura propuesta, utilicé el AWS Database Migration Service (AWS DMS) para capturar metadatos de las bases de datos de ACS. AWS DMS admite varios motores de bases de datos SQL y NoSQL, como Oracle, MS SQL Server y MongoDB. Gracias a sus funciones de migración continua y captura de datos de cambios (change data capture – CDC), puede capturar los cambios de la base de datos de ACS e introducirlos en Amazon S3 casi en tiempo real. Cuando los datos llegan a Amazon S3, un trabajo de AWS Glue los transforma aún más del formato de salida de Amazon DMS a un formato común, optimizado para su lectura.

Diagrama arquitectónico que muestra cómo se pueden extraer los metadatos de ACS de la base de datos de ACS mediante AWS DMS.
Conclusión
En este blog, definí algunos de los casos de uso comunes de los datos de telemetría del CPE. Mostré cómo la recopilación masiva de datos del TR-069 se puede utilizar junto con diferentes servicios de AWS para la ingestión y el análisis con una arquitectura de muestras de AWS.
El uso de los servicios sin servidor de AWS permite una escalabilidad transparente a medida que crece su flota de CPEs, además de reducir los costos de administración.
Puede explorar el TR-069 y la arquitectura de referencia de AWS e implementarlos para resolver sus desafíos de recopilación masiva de datos de CPE.
También puede visitar Telecommunications on AWS para conocer cómo los CSP están reinventando la comunicación con AWS.
Este artículo fue traducido del Blog da AWS em Inglés.
Acerca del autor
 Murat Balkan es Specialist Solutions Architect (OSS/BSS) en Toronto.
Murat Balkan es Specialist Solutions Architect (OSS/BSS) en Toronto.
Revisor
 Marlon Fuentes es arquitecto de soluciones que tiene más de 20 años de experiencia en TI, especialmente en la industria de Telecomunicaciones. Actualmente dedica su tiempo a ayudar a los Partners a identificar nuevas oportunidades de negocio, innovar y usar los servicios de nube de AWS para obtener los mayores beneficios. Su principal pasatiempo es correr, inicialmente fue una obligación ahora es una pasión junto con la cocina. También acostumbra leer sobre varios temas, especialmente sobre tecnología.
Marlon Fuentes es arquitecto de soluciones que tiene más de 20 años de experiencia en TI, especialmente en la industria de Telecomunicaciones. Actualmente dedica su tiempo a ayudar a los Partners a identificar nuevas oportunidades de negocio, innovar y usar los servicios de nube de AWS para obtener los mayores beneficios. Su principal pasatiempo es correr, inicialmente fue una obligación ahora es una pasión junto con la cocina. También acostumbra leer sobre varios temas, especialmente sobre tecnología.