Amazon Web Services ブログ
【寄稿】株式会社D2CにおけるAWSを活用した機械学習ハッカソンの取り組み
この投稿は株式会社D2Cのデータサイエンティスト 阿部 将大 氏に、自社で開催された機械学習ハッカソンの取り組みについて寄稿頂いたものです。
※ 一部、ハッカソン開催を支援したAWSも執筆しています
1. はじめに
株式会社D2C ドコモ広告事業本部 データソリューション部の阿部と申します。D2Cは広告事業を展開しており、我々の部署はユーザーや広告主、メディアの分析を行い、広告配信システムのロジックやユーザーセグメントなどの開発をしています。
docomo Ad Network(ドコモアドネットワーク)
現在多くの企業でデータを使って何が出来るか、という部分を注力している状況かと思いますが、個人的に一番難しいと感じているのは実課題をデータサイエンスで解けるような設定に落とし込む箇所だと思っています。そのためにはデータサイエンスの知識・スキルだけではなく、そのビジネスへの深いドメイン知識が求められます。
ただ、その場合データ分析者が各業務のビジネス構造を現場の担当者と同等レベル(もしくはそれ以上)で理解するというのは、知識をキャッチアップする工数を考えると現実的ではないのかもしれないと感じ始めました。弊社もそうですが、データ分析者が一つの部署に集まった中央集権的な組織体制で動いている場合は、この辺りを課題に感じている方は多いのではないでしょうか。
理想的には、モデリングやデータエンジニアリングを含めた分析スキルを他部署のメンバーにも継承し、実課題に落とし込む段階も協力してプロジェクトを進めていけるのが良いと考えています。そこで、取り組みの第一弾としてビジネスサイドや普段、機械学習に馴染みのないエンジニアのメンバー向けに、機械学習の概要や実データを用いたモデリングに触れてもらい、参加者同士で予測精度を競うハッカソンを企画しましたので、本記事ではその詳細をご紹介致します。
2. 機械学習ハッカソンの概要
今回のハッカソンの課題で用いたデータは、実際の広告配信システムで用いられているデータになります。もともとは2020年夏に我々の部署が実施した短期インターンシップと同じ課題を用いました。具体的には過去の広告配信ログやユーザーの属性、あるサービスにおける行動ログを提供し、これらを組み合わせてユーザーと広告粒度でクリックする確率を予測するモデルを作成する流れになります。そして、この学習データよりも配信日が未来の配信ログをテストデータとして、その精度を競う形式になります。ただ、データが大規模で複数のデータを用意しているため探索的データ分析(EDA)を行うだけでもある程度のコーディングスキルが求められます。そのためインターンシップに応募頂いた学生の皆様にはコーディングテストを事前に課して参加者を決めさせて頂きました。
そこで今回のように機械学習に馴染みのないメンバーに、この課題に対してどのような方法で取り組んでもらおうか悩んでいたところ、なるべくコードレスでEDA→前処理→モデリングのフローを回せる構成をAWSさんにご提案頂きました。日頃からAWSの方々には既存システムの改善や新しいシステムを作る際の助言など多くのサポートを頂いていますが、今回のようなオーダーメイドのイベントまで一緒に考えて更に当日の講師まで協力頂けるとは思っていませんでした。
具体的なAWSサービスの説明は次節以降にしますが、簡単な流れを説明させていただきます。ハッカソンは全体で3日間(計8時間)行いました。1日目はGUI上で大規模データの集計・可視化・加工を行うことが出来るAWS Glue DataBrewのハンズオンを実施頂きました。2日目には機械学習の概論とAmazon SageMakerとAutoGluonを使ったモデリングのハンズオンを行い、最終日までの1週間で参加者各々が精度向上に取り組むという流れになります。これらのサービスを組み合わせることにより、エンジニア以外の参加者でも少ないコード量で予測モデルの構築は最低限出来る状況が可能となりました。
結果的に今回のハッカソンは各部署から40名近い参加者となりました。そのうち半分以上の参加者はAWS自体初めて使うという状況に加えて、オンライン実施という難しさもありましたが、各セクションでハンズオンを実施しながら進めて頂いたことにより、モデリングまで進めることが出来ました。

ハッカソンの課題

最終日は上位の方に取り組んだことを発表してもらいました
以降は各AWSサービスの詳細な説明となります。
3. 機械学習ハッカソンの構成
※このセクションはAWSの藤田が執筆しました
機械学習ハッカソンを実施した際のアーキテクチャは下図の通りです。
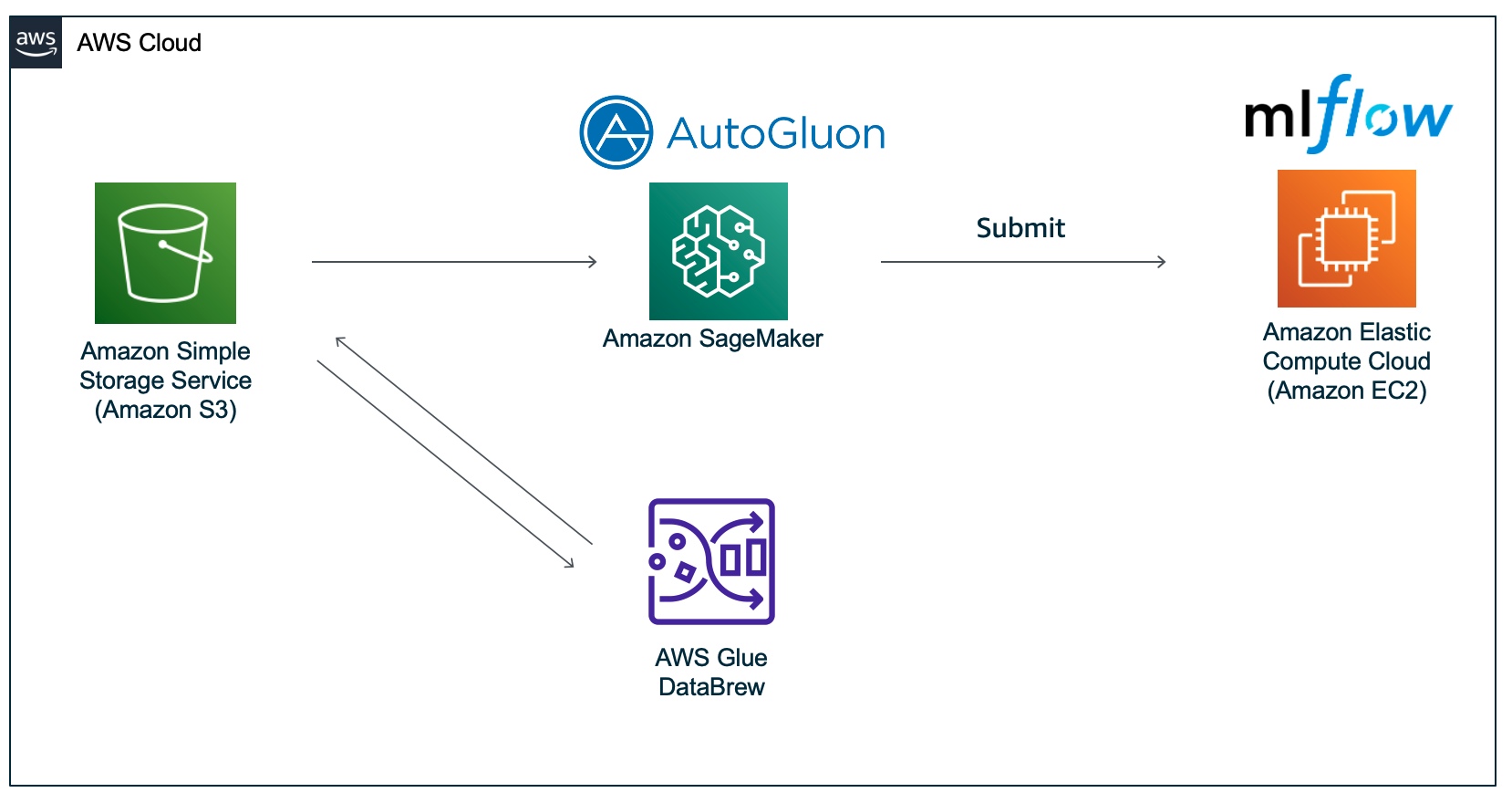
ハッカソンで使用したアーキテクチャ
今回のハッカソンではAmazon S3、AWS Glue DataBrew、Amazon SageMaker、Amazon EC2を使用しました。
大まかな流れとして、参加者はAWS Glue DataBrewでデータの可視化や集計などを行いながらデータに対する理解を深め、機械学習モデルの予測精度を向上させるべく特徴量を作成します。Amazon SageMakerでは、作成された特徴量を基に機械学習モデルを作成し、テストデータに対して予測を行います。
予測結果はAmazon EC2に構築しているmlflowサーバへ送信します。mlflowサーバでは、送信されてきた予測結果から精度を計算します。その結果、参加者はmlflowから自身の機械学習モデルの精度を確認することができます。
3-1. AWS Glue DataBrewを使ったデータ加工
※このセクションはAWSの津和崎が執筆しました
ハッカソン用に用意されたユーザーの属性などのデータの集計、可視化と後続の機械学習で活用しやすく変換する目的で、AWS Glue DataBrewを活用しました。

AWS Glue DataBrewはS3などのデータストアに簡単に接続し、コーディングなしに⽣データをサーチ、接続、クレンジングして加⼯することができる、視覚的でインタラクティブなデータ準備のサービスです。
典型的な分析や機械学習のワークフローでは、データの準備に最大80%が費やされると言われています。AWS Glue DataBrewを活用すると、コードを書かないデータアナリストもデータの準備や特徴量の生成などを視覚的なインターフェースから行うことができます。今回、ハッカソンを行うに当たり、AWS Glue DataBrewハンズオンを実際の機械学習でのユースケースに合わせ作成し、特徴量生成でよく行われる操作をご案内しました。
AWS Glue DataBrewそのものについて詳しく学びたい方は、 AWS Black Belt Online Seminar「AWS Glue DataBrew」にて動画が公開されておりますので、是非あわせて参照ください。
ハッカソンにてご紹介したAWS Glue DataBrewの操作手順をハンズオンの形式にまとめております。当ハンズオンを実施いただければ、ハッカソン同様の特徴量生成を体験することが可能です。
※D2C様向けのハンズオンでは、ハッカソン用にお客様提供のデータを活用しましたが、同様の手順が行えるサンプルデータを当Blog向けに用意いたしました。合わせてご活用ください。
3-2. Amazon SageMakerとAutoGluonを使った機械学習モデリング
※このセクションはAWSの藤田が執筆しました
ハッカソンの機械学習モデル作成では、Amazon SageMakerとAutoGluonを活用しました。

Amazon SageMakerは、機械学習に関する幅広い機能を提供するフルマネージドサービスです。データサイエンティストや開発者が機械学習モデルを迅速に準備、構築、学習、およびデプロイするのを支援するサービスです。

AutoGluonは、AWSが開発した画像、テキスト、テーブルデータに対してAutoMLを実行するOSSです。今回のハッカソンではテーブルデータに対してAutoMLを実行するAutoGluon Tabularを使用しました。
SageMakerとAutoGluonをハッカソンに利用するメリットは以下の通りです。
- SageMakerノートブックインスタンスを使用することで参加者に一律の独立した開発環境を提供できる
- AutoGluonを使用することで参加者は数行のコードで機械学習モデルを構築できる
この2つの組み合わせは日頃、機械学習に馴染みのない方でも環境構築〜機械学習モデリングを行える点で効率的です。
それでは具体的な流れを説明します。
- まずは参加者の方々にSageMakerのノートブックインスタンスを立ち上げてもらいます。


- Glue DataBrewで作成したデータセットはS3に保存されているため、立ち上げたノートブックインスタンスからJupyter notebookを開き、S3のデータをダウンロードします。このハッカソンではAWS Data Wranglerを使用しました。AWS Data Wranglerを使うとS3などから表形式のデータを簡単にダウンロードし、読み取ることができます。
import awswrangler as wr train = wr.s3.read_csv("s3://bucket_name/prefix/train.csv") - ハッカソンでは運営側より、シンプルなデータセットに対して機械学習モデルの学習と推論を行うサンプルコードを提供しました。AutoGluonを使うと複数の機械学習アルゴリズムをわずか数行のコードで実行できます。以下は二値分類を行う際のコードスニペットです。
from autogluon.tabular import TabularPredictor predictor = TabularPredictor(label=target, problem_type='binary', eval_metric='roc_auc') predictor.fit(train_data=train_df, tuning_data=val_df, time_limit=None) - 学習が終わったら、テストデータに対して予測を行い、予測結果をmlflowサーバへ送信します。


あとは参加者の方々に一週間、試行錯誤しながら改善を重ねてもらいます。
この試行錯誤とモデルの精度が良くなった・悪くなったことに対する原因の考察は、データからビジネスを理解することや実際のデータ分析実務においても役に立つ経験となることが期待できます。
以上が機械学習ハッカソンの流れとなります。
4. 最後に
最後までお読み頂きありがとうございます。
ハッカソンの改善点として、難易度の調整は難しく今後の課題となりました。
できるだけ多くの様々なバックグラウンドの方に参加してもらえるようにするには敷居は下げたい一方で、下げ過ぎるとある程度慣れている方には物足りない内容になってしまいます。
研修等を通じて日頃からデータ活用に慣れていただくための活動やハッカソン開催では難易度でトラックを分けるなどの工夫も今後取り入れていきたいと考えています。
今回の活動を通じて、自社でデータ活用の動きがさらに活発になっていくと嬉しいと思っています。
著者について
 株式会社D2C 阿部 将大 氏
株式会社D2C 阿部 将大 氏
株式会社D2Cで機械学習やそのための基盤構築を担当。マネージャーになって手を動かす仕事が減ることを危惧してETL系のタスクでも喜んで飛びつきます。趣味はゴールドジム巡り。

アマゾン ウェブ サービス ジャパン ソリューションアーキテクト 津和﨑 美希(Miki Tsuwazaki)
通信業界のお客様を担当するエンタープライズ ソリューション アーキテクト。好きなAWSサービスはAWS マネジメントコンソールです。コンピュートから機械学習まで、ありとあらゆるサービスを、経験問わず、だれでもすぐに開始できるところが好きです。

アマゾン ウェブ サービス ジャパン 機械学習 プロトタイプ ソリューションアーキテクト 藤田 充矩 (Atsunori Fujita)
機械学習 プロトタイプ ソリューション アーキテクトで、自然言語処理や時系列分析などを得意にしています。趣味はkaggleです。