Amazon Web Services ブログ
株式会社ディー・エヌ・エー様におけるEC2スポットインスタンスの大規模活用のための工夫とコンテナ技術を用いた設計例の紹介
EC2スポットインスタンススペシャリスト ソリューションアーキテクトの滝口です。この記事では、スポットインスタンスを最大限に活用した事例として、多くの技術的な工夫をこらしてAmazon Elastic Compute Cloud (Amazon EC2)インスタンスの費用の最適化に成功した、株式会社ディー・エヌ・エー様をご紹介します。またその考え方をコンテナ技術を用いて設計するとしたらどのようになるかを検討し、設計例を構築手順とともにご紹介します。
はじめに
アプリケーションの実行環境にEC2インスタンスを選択する環境では、全体のAWS費用の中でEC2インスタンスの費用が大きな割合を占めるケースが多くあり、AWS費用全体の7割以上がEC2インスタンスの費用という場合もあります。そのため、EC2インスタンスの費用を可能な限り最適化し、節約できた分を次の投資に繋げる、という考え方が非常に重要になります。
EC2インスタンスの費用の最適化はどのように考えたら良いでしょうか。例えば年間を通じて定常的に稼働するワークロードがあり、365日起動し続ける必要のあるEC2インスタンスがある場合、Savings Plansやリザーブドインスタンスを活用して費用を節約できます。また後述するような、中断に強いワークロードがある、もしくはアプリケーションを中断に強い形に改良できるという場合、EC2スポットインスタンスを活用し、オンデマンド価格の最大9割引でEC2インスタンスをお使いいただくことができます。スポットインスタンスは、AWSクラウド内の使用されていないEC2キャパシティーを活用して、オンデマンドインスタンス料金に比べて最大 90% の割引料金でご利用いただける仕組みです。
なお、この記事の内容はAWS Summit Tokyo 2019での講演である「【初級】DeNA の QCT マネジメント IaaS 利用のベストプラクティス」(動画)を踏まえたものです。こちらのご講演内容も合わせてご活用ください。
スポットインスタンス適用率100%を実現した株式会社ディー・エヌ・エー様の取り組みの紹介
株式会社ディー・エヌ・エー様(以下DeNA様)では、2018年よりAWSで構築された大規模ゲームインフラ環境に対するQCTマネジメントを推進してきました。品質(Quality), 費用(Cost), 納期(Time)の3つの要素をバランスさせながら、最終的に全体のインフラコストを60%削減することに成功しています。
この施策の中で、管理対象の大きなものの一つに全体費用の90%をも占めるEC2インスタンスの費用がありました。そこで、自動スケールとスポットインスタンスの活用に着目し、この費用を最適化しました。その結果、適用対象としたステートレスなサーバー群のすべてをスポットインスタンスで構成することができ、適用前と比較して60%の削減に成功しています。同時に、オンデマンドインスタンスを使用していた頃と遜色ない品質でサービス提供を継続しています。この取り組みの詳細は、こちらのDeNAエンジニアブログの記事を参照してください。
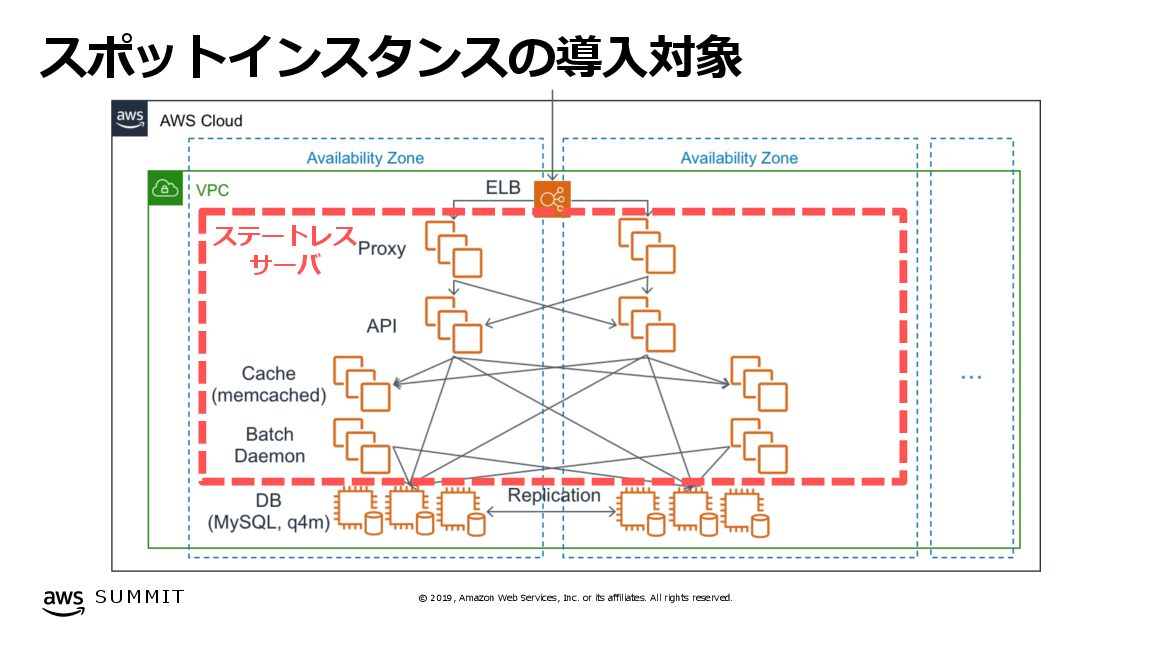
図. スポットインスタンスの適用対象 (「DeNAのQCTマネジメント IaaS利用のベストプラクティス」より)
オンデマンドインスタンス価格の最大9割引で提供されるスポットインスタンスは、需要の増加に伴ってEC2サービスから削除されることがあります。これをスポットインスタンスの中断と呼びます。
スポットインスタンスが活用するのは、「スポットプール」と呼ばれる、EC2サービスの空きキャパシティ、すなわち使われていない部分です。図の赤枠で示した箇所は、それぞれ独立した6つのスポットプールです。
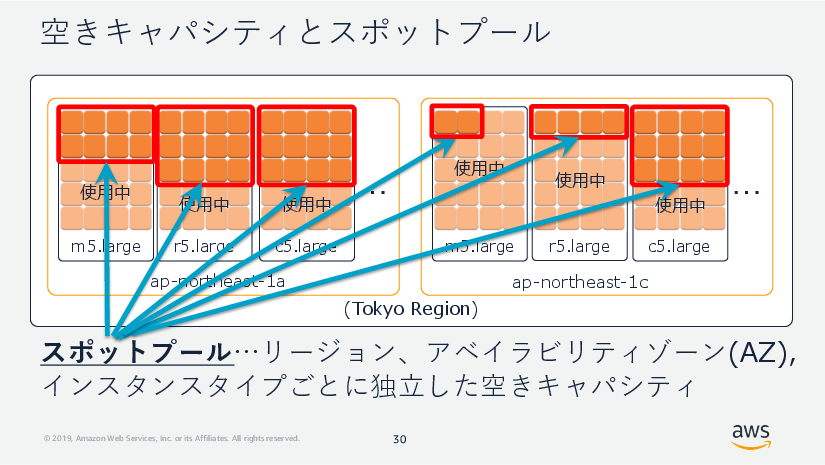
図. 空きキャパシティとスポットプール – スポットプールの定義
あるスポットプールに空きがあるとき、そのアベイラビリティゾーンで指定したインスタンスタイプでスポットインスタンスを起動できます。

図. 空きキャパシティとスポットプール – 空きキャパシティがあるとき
あるスポットプールに空きがないとき、そのアベイラビリティゾーンで指定したインスタンスタイプでスポットインスタンスを起動することはできません。また稼働中のすべてのスポットインスタンスは中断対象となり、高まった需要に対応するため、スポットインスタンスとして使用されていたキャパシティはEC2サービスに戻されることになります。
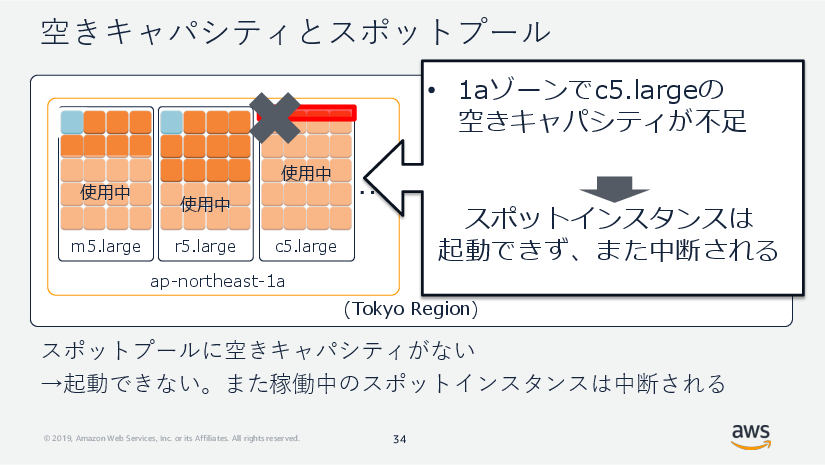
図. 空きキャパシティとスポットプール – 空きキャパシティがないとき
スポットインスタンスを活用するには、中断というリスクに備えたアーキテクチャであることが必要です。中断に強いアーキテクチャを設計するための秘訣として、可能な限りすべてのアベイラビリティゾーンを指定し、幅広いインスタンスタイプを選択し、なるべく多くのスポットプールを増やしていくことが極めて重要です。
次の図では、6台のスポットインスタンスを起動するシナリオでスポットプールを増やすことの重要性を説明しています。6種類の定義可能なスポットプールに対して、6つすべてを選択した場合と、インスタンスタイプをm5.largeに絞って2つのみを選択した場合、それぞれを比較します。仮にap-northeast-1cゾーンのm5.largeの空きキャパシティが不足したとすると、2つのスポットプールを選択したパターンでは半数の3台が中断されるのに対し、6つのスポットプールを選択したパターンでは5台が残ることになります。

図. スポットプール拡充の重要性
ステートレスなサーバー群をすべてスポットインスタンスで構成するために、DeNA様では最終的に使用するスポットプールを20プールまで引き上げました。これは例えばある時点で、北バージニアリージョンの5つのアベイラビリティゾーンに対して、c5.2xlarge, c5.4xlarge, c5d.4xlarge, c5.9xlargeの4種類のインスタンスタイプを定義している状態を指し、このときのプール数は 5 x 4 = 20プールと計算されます。
次の図の横軸は時間、縦軸は起動したインスタンス台数を示し、それぞれのインスタンスがどのスポットプールから起動されたかが色分けされて示されています。20個ものスポットプールを拡充しておくことで、一部のスポットプールのキャパシティが十分にスポットインスタンスを供給できなかった場合にも、他のスポットプールで起動されたスポットインスタンスにより、サービス提供を継続できるようになっています。
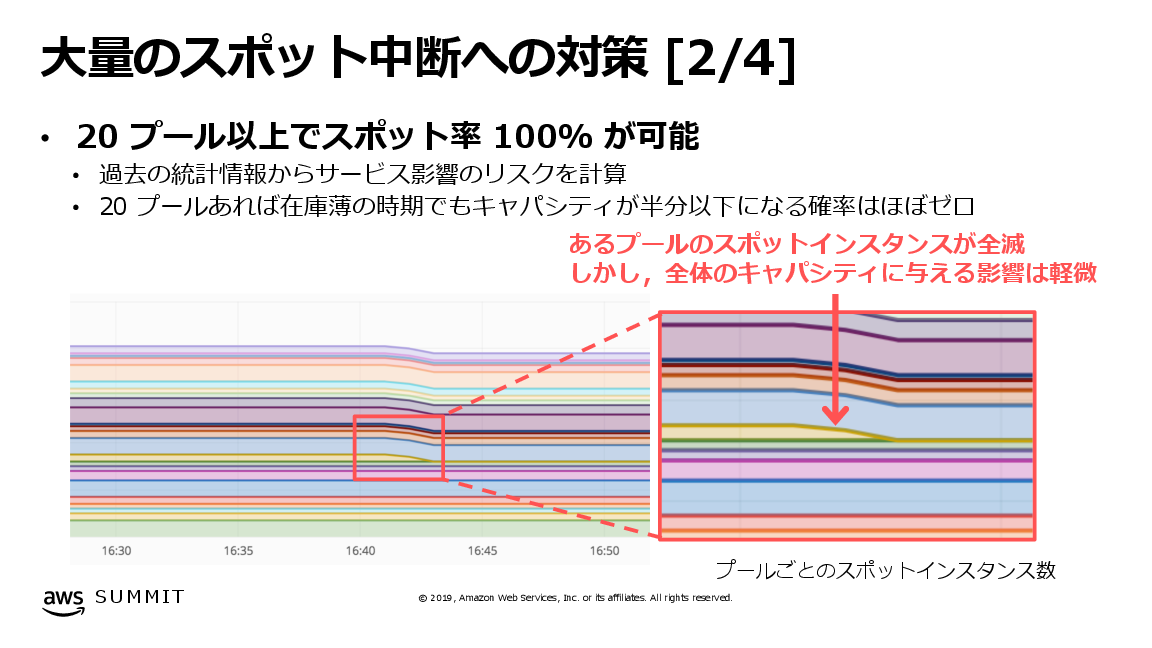
図. 大量のスポット中断への対策 (「DeNAのQCTマネジメント IaaS利用のベストプラクティス」より)
インスタンスタイプ追加のための工夫
上記のブログ記事やAWS Summit Tokyo 2019での登壇資料である「DeNAのQCTマネジメント IaaS利用のベストプラクティス」で触れられているように、インスタンスタイプを追加するための取り組みは、単純に設定変更をして終わり、というものではありませんでした。サービス全体の処理性能の処理性能を均質にしようとしたとき、インスタンスタイプによって性能が異なるため、そのままではリクエストごとの応答時間にばらつきが生じます。
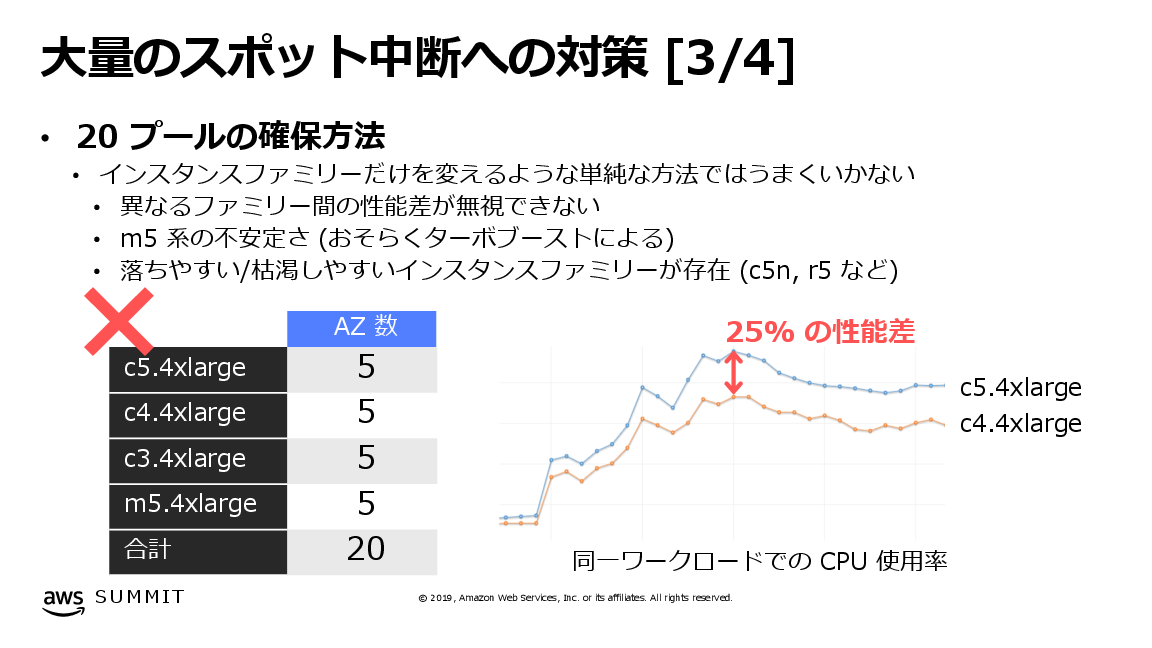
図. 大量のスポット中断への対策 (「DeNAのQCTマネジメント IaaS利用のベストプラクティス」より)
この応答時間のばらつきを解決するため、まずインスタンスタイプごとに計測した性能差に応じて複数のセカンダリIPアドレスを付与しました。そしてインスタンスごとではなく、IPアドレスに対してDNSラウンドロビンで負荷分散することで、応答時間を均質化することに成功しました。
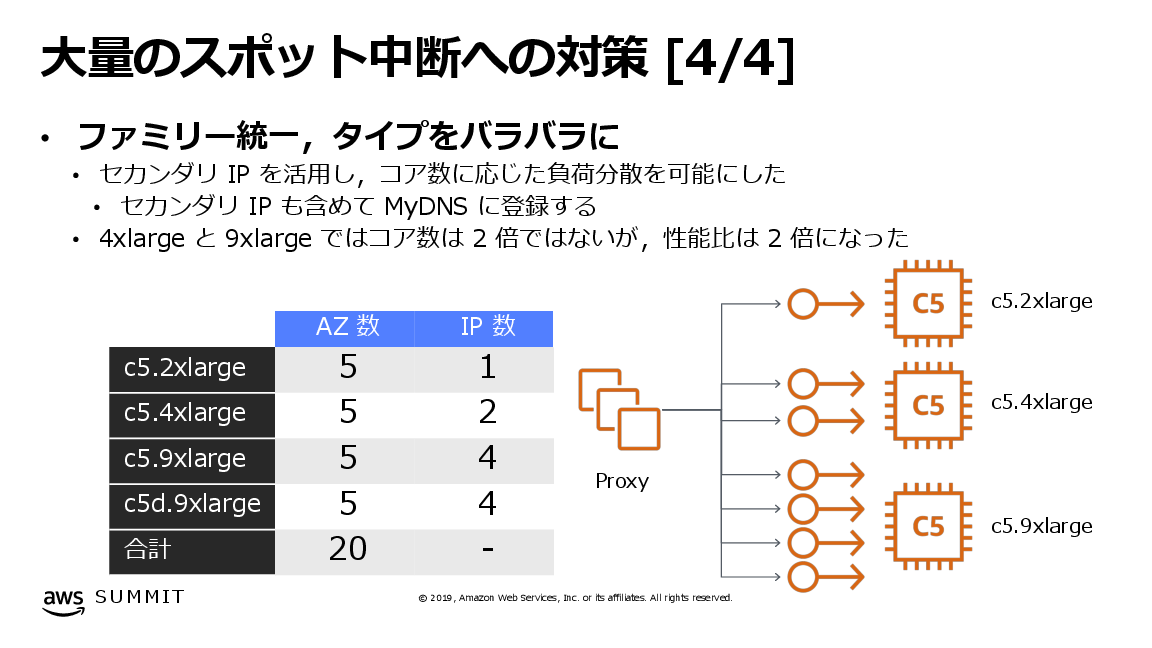
図. 大量のスポット中断への対策 (「DeNAのQCTマネジメント IaaS利用のベストプラクティス」より。本稿ではIPアドレス数を正確な情報に更新した版の画像を掲載)
このようにセカンダリIPアドレスを付与する方法は、今回のようにアプリケーションをEC2インスタンスで直接ホストするタイプのワークロードにおいて、異なるインスタンスタイプにまたがってアプリケーションを稼働させるための実践的な工夫のひとつです。この工夫を踏まえ、もしコンテナ技術を活用できるという条件があったとしたらどのように実現できるか、この記事の後半では構築手順とともに設計例を紹介します。
コンテナ技術によるインスタンスタイプ間の処理性能の均質化を実現するアーキテクチャの検討
次の図は、今回検討するシステムの全体概要を示したものです。

図. 検討するシステムの全体概要
最初に、今回検討するアプリケーションの要件を、なるべくシンプルになるように決めておきます。まず、HTTPリクエストを受け付けるコンテナアプリケーションを考えます。エンドユーザーからのリクエストの大半は速やかに、例えば1秒以内に応答されているものとします。またアプリケーションはステートレスな設計になっているものとします。これにより、コンテナの稼働するインスタンス(コンテナインスタンス)が一時的に動作できない状況下であっても、既存のリクエストへの影響を可能な限り小さくし、スポットインスタンスの中断や予期せぬインスタンス障害などに備えることができます。
今回、全てのコンテナインスタンスはスポットインスタンスとして稼働させます。また、スポットインスタンスの中断に強いアーキテクチャにするため、複数のインスタンスタイプを活用します。そしてコンテナオーケストレーターとしてAmazon Elastic Container Service(Amazon ECS)を選択し、それぞれのコンテナが独立してサービスを提供するようにします。
具体的な内容を次の通り決めていきます。まず仮に、コンテナアプリケーションが要求するvCPU数を2 vCPUと決めます。またインスタンスタイプはm5.large, m5.xlargeの2種類を用います。それぞれvCPU数はm5.largeが2vCPU, m5.xlargeが4vCPUです。このときAmazon ECSの仕組みにより、起動できるコンテナの数はコンテナインスタンスのvCPUに基づいて決まります。したがって、m5.largeには1つのコンテナ、m5.xlargeには2つのコンテナが起動される設定となります。この設定は、DeNA様がセカンダリIPアドレスを用いて実現した、インスタンスタイプ間の性能差を吸収し、サービス側の処理性能を均質化する、という目的を達成できることになります。
では実際にアプリケーションおよび実行環境を構築し、動作を確認していきたいと思います。
構築手順の紹介
前準備
この記事では、AWSコマンドラインインターフェイス(CLI), Dockerコマンド、そしていくつかの基本的なUNIXコマンドを使用します。必要に応じて、お手元の環境に準備してください。AWS Cloud9を用いることもできます。
Dockerイメージの作成
HTTPリクエストを受け付けるステートレスアプリケーションを模したものとして、接続先サーバーのIPアドレスを返すだけの小さなコンテナアプリケーションを作成します。ロードバランサー経由でこのアプリケーションにアクセスしたとき、どのコンテナがリクエストを受け付けたのかを知ることができます。
今回はDocker Hubの公式phpイメージをベースに、ドキュメントルート直下のipaddr.phpにアクセスするとhttpサーバー自身のIPアドレスを返すスクリプトを追加します。
以下の内容をDockerfileに記述します。これ以降、記載される構成ファイルやコマンドの例については、横方向にスクロールして参照してください。内容は折り返されていません。またコピーの際は、内容の全体が含まれることを確認してください。
このDockerfileをビルドします。
デフォルトリージョンの設定
この記事では、東京リージョンにシステムを構築することとします。次のように、AWS CLIのデフォルトリージョンを設定します。Cloud9をお使いの場合は設定不要ですのでスキップしてください。
ECRリポジトリの作成
続いて、これから作成するECSクラスターからこのDockerイメージを取得(プル)できるよう、お使いのアカウントのAmazon Elastic Container Registry (Amazon ECR)サービス内にリポジトリを作成します。次のコマンドを実行します。
ECRリポジトリ作成の詳細についてはECRドキュメントの「Creating a Repository – Amazon ECR」を参照してください。
ECRリポジトリへのDocerイメージのプッシュ
続いて、ECRリポジトリにイメージをプッシュします。まずECRリポジトリにdocker pushできるよう、docker loginコマンドにECRレジストリの認証トークンを渡します。アカウントIDはお使いのものに置き換えてください。
次にDockerイメージにタグを打っておきます。
そしてこのタグ名を指定し、DockerイメージをECRリポジトリにプッシュします。
VPCの準備: awsvpcモードの指定
次に検証のためのVPCと関連リソースを作成します。今回、ECSのネットワークモードにawsvpcを採用し、ECSタスク、つまりコンテナがそれぞれ個別のENIとプライベートIPアドレスを持つようにします。このため、パブリックサブネットとプライベートサブネット、またプライベートサブネットからインターネットへの通信を提供するためのNATゲートウェイと必要な経路を定義したルートテーブル、そしてこの検証で共通して用いるセキュリティグループを作成します。作成するリソースの一覧は次の通りです。
- 検証用VPCの作成
- パブリックサブネットとプライベートサブネットの作成、ルートテーブルの作成
- NATゲートウェイの作成、ルートテーブルの作成
- セキュリティグループの作成
お使いのアカウントに既に同様のVPC環境がある場合、この節をスキップできます。なお、プライベートサブネットに起動したEC2インスタンスがインターネットに向けた通信を開始できることを確認してください。
なおこの構成は、VPCドキュメントの「パブリックサブネットとプライベートサブネットを持つ VPC (NAT)」に解説されています。理解を深める際に参照してください。
まず新規にVPCを作成し、出力からVPC IDを控えておきます。
続いてこのVPCにサブネットを2つ作成します。それぞれ、192.168.0.0/24がパブリックサブネット、192.168.1.0/24がプライベートサブネットの役割を担います。出力からそれぞれのサブネットIDを控えておきます。
続いてサブネットの1つ、192.168.0.0/24をパブリックサブネットとして構成します。まずインターネットゲートウェイを作成し、出力からインターネットゲートウェイIDを控えておきます。
このインターネットゲートウェイをVPCにアタッチします。
このVPCにカスタムルートテーブルを作成し、出力からルートテーブルIDを控えておきます。
このルートテーブルに、自VPC宛て以外の全てのトラフィック(0.0.0.0/0)がインターネットゲートウェイを向く経路を追加します。
このルートテーブルを192.168.0.0/24のサブネットに関連付け、サブネットをパブリックサブネットにします。
続いて、NATゲートウェイを作成します。まずNATゲートウェイの動作に必要なElastic IPアドレスをお使いのアカウントに割り当てます。アロケーションIDを控えておきます。
次にこのアロケーションIDを指定し、パブリックサブネット(192.168.0.0/24)にNATゲートウェイを作成します。NATゲートウェイIDを控えておきます。
このVPCにカスタムルートテーブルを作成し、出力からルートテーブルIDを控えておきます。
このルートテーブルに、自VPC宛て以外の全てのトラフィック(0.0.0.0/0)がNATゲートウェイを向く経路を追加します。
このルートテーブルを192.168.1.0/24のプライベートサブネットに関連付け、プライベートサブネットからインターネットに向けた通信を開始できるようにします。
最後にこの検証シナリオで共通して用いるセキュリティグループを作成します。セキュリティグループIDを控えておきます。
そしてこのセキュリティグループに、インターネットからTCP 80番ポートへのアクセスを許可するルールを追加します。コンテナインスタンスにSSHアクセスできるよう、必要に応じて22番ポートへの許可ルールも追加することができます。
今回は検証用に1つのセキュリティグループのみを準備しますが、実際に運用するシステムではコンポーネントごとのアクセス許可を適切に分離し、セキュリティグループを分割することを検討してください。
ECS環境の準備とコンテナの配備
下準備が整ったところで、ECSクラスターとECSタスクを作成していきます。
ECSタスク定義
先ほど準備したDockerイメージを指定して、ECSタスクを作成します。まず次の内容をecs-taskdef.jsonという名前で準備します。アカウントIDをお使いのものに置き換え、ご自身のECRリポジトリが参照されるようにしてください。
このタスク定義では、事前に作成したECRリポジトリにプッシュしたイメージを指定しています。コンテナインスタンスからECRリポジトリにあるイメージをpullするには、適切な権限のIAMロールを持つインスタンスプロファイルがコンテナインスタンスに設定されている必要があります。このインスタンスプロファイルの作成と指定については後続のステップで取り扱います。
また、タスクごとに固有のENIを持たせる要件に対応するため、networkModeにawsvpcを指定しています。なお、このとき提供されるENIにはパブリックIPアドレスは付与されず、プライベートIPアドレスのみとなります。またawsvpcネットワークモードを使用するタスクには、ECSサービスにリンクされたIAMロールが必要となります。このロールは、次のステップで実行する、クラスターの作成により自動的に作成されます。awsvpcネットワークモードの詳細については、ECSドキュメントの「タスクネットワーキングと awsvpc ネットワークモード」を参照してください。
また、コンテナのログをCloudWatch Logsで確認できるようにawslogsログドライバーを有効にしました。さらに必要なリソースとして、2vCPUと2GBのメモリを要求しています。
このecs-taskdef.jsonを指定してECSタスク定義を作成します。
ECSクラスターの作成
続いて、ECSクラスターを作成します。
スポットインスタンスの起動準備
ここではまずコンテナアプリケーションの稼働するスポットインスタンスを起動するために起動テンプレートを定義します。続いて、ここまでに作成したECSタスク定義、ECSクラスターを指定して、ECSサービスを作成します。
起動テンプレートの作成
オンデマンドインスタンスを用いる場合の設定項目に加えて、コンテナインスタンスとしてスポットインスタンスを用いる際には次の内容を起動テンプレートに記述します。
- ECS最適化AMIの指定
- ECSコンテナインスタンスIAMロール(
ecsInstanceRole)の指定 - ECSクラスター名の指定(ユーザーデータ経由)
- スポットインスタンス中断ハンドリング機能の有効化(ユーザーデータ経由)
特に最後の項目、スポットインスタンスの中断ハンドリング機能は、ECS環境でスポットインスタンスを活用する際に強くお勧めする機能です。中断の2分前に送付されるスポットインスタンスの中断通知をコンテナインスタンスが受け取ったとき、ECSはそのコンテナインスタンスのステータスを自動的にDRAININGに更新します。これにより、中断対象のインスタンスで新規のコンテナタスクが起動されないようになります。
ECSコンテナインスタンスに関連する各項目の詳細は、ECSドキュメントの「Amazon ECS コンテナインスタンスの起動」 および「スポットインスタンス のドレイン」 を参照してください。スポットインスタンスの中断通知についてはAmazon EC2ドキュメントの「スポットインスタンス 中断の通知」を参照してください。
まずユーザーデータ用のテキストをuser-data.txtという名前で準備します。ECSクラスター名、中断ハンドリング用の設定を定義します。
そしてこの内容をbase64エンコードします。
続いて、最新版のECS最適化AMIのIDを取得します。
また、タスク定義の設定で触れたとおり、コンテナインスタンスが必要とするIAMロールである、ecsInstanceRoleを準備します。これは、Amazon ECSマネジメントコンソールに初回アクセスしたときに自動的に作成され、これが最も簡単な作成方法です。もし未作成であればここで作成してください。その他の手動での作成方法、存在の確認方法などの詳細については「Amazon ECS コンテナインスタンス IAM ロール」を参照してください。
そして、起動テンプレートに含める内容をlt.jsonという名前で準備します。ここでは上で準備した項目に加え、共通で用いるセキュリティグループ、またアカウントに設定されたキーペア名を指定しています。
そして、このjsonを用いて起動テンプレートを作成します。起動テンプレート名を控えておいてください。
スポットインスタンス単体の準備
続いて、コンテナアプリケーションを稼働させるためのスポットインスタンスを起動します。スポットインスタンスを起動するにはEC2 Auto Scalingを含めたいくつかの方法がありますが、今回は2種類のインスタンスタイプとして、m5.large, m5.xlargeを1台ずつ起動できるよう、最もシンプルな手順であるRunInstancesを用います。
先ほど作成した起動テンプレート名を指定し、プライベートサブネットにm5.large, m5.xlargeをそれぞれ1台ずつ起動するよう指示します。
この実行結果について補足します。EC2 APIであるRunInstancesは、AWS CLIからはaws ec2 run-instancesというコマンドで呼び出されます。これを実行すると、正常終了し、レスポンスのjsonデータが戻されました。このjsonの中に、起動されたインスタンスIDが含まれることが分かります。もし何らかの理由で異常終了した場合、エラーメッセージが戻されます。
EC2インスタンスを起動するAPIの中で、RunInstancesは同期リクエストに分類されます。同期リクエストでは、正常終了を受け取ったとき、EC2インスタンスの起動指示の受付が成功したことを意味します。これに対して、例えばAuto Scalingグループを作成するCreateAutoScalingGroupは、EC2インスタンスを起動するという観点では非同期リクエストに分類されます。CreateAutoScalingGroupの場合、正常終了の応答は単にAuto Scalingグループの作成受付完了までを示すものであり、実際に希望容量が充足されたかどうか、つまりEC2インスタンスが起動されたかどうかの情報は含まれません。実際に容量が充足されたかどうかを確認するにはDescribeAutoScalingGroupsなどから確認する必要があります。このように、リソースを作成するAPIを発行する際には、そのAPIが同期リクエストか非同期リクエストかを意識すると、より厳密に処理を記述できる場合があります。
起動後、2台のインスタンスがコンテナインスタンスとしてECSクラスターに登録されたことを確認します。ユーザーデータに設定したECS_CLUSTERの値に従って、インスタンス内で動作するECSエージェントが自身をECSクラスターに登録する仕組みです。
ロードバランサーとECSサービスの作成
ロードバランサーの作成
構築の最後のステップとして、起動したコンテナへの外部からのアクセスをロードバランサーで振り分け、リクエストが負荷分散されることを確認します。今回は構成を単純化するために、サブネットを配置するアベイラビリティゾーンを1つのみ選択しています。Elastic Load Balancing (ELB)では3種類のロードバランサーを提供しますが、今回は1つのアベイラビリティゾーンに対して負荷分散できるロードバランサーとして、Network Load Balancer (NLB)を選択します。複数のアベイラビリティーゾーンを定義している場合は、Application Load Balancer (ALB)も選択できます。ELBの提供するロードバランサーの比較については「Elastic Load Balancing の特徴」を参照してください。
まずNLBのリソースを作成します。create-load-balancerにはサブネットの指定が必要です。出力からNLBのARNとDNS名を控えておきます。
続いてターゲットグループを作成します。create-target-groupはVPCの指定が必要です。また、登録対象のターゲットタイプにはinstanceではなく、ipを指定します。検証の待ち時間を短縮するため、ヘルスチェック間隔を10秒に指定しています。この出力からターゲットグループのARNを控えておきます。
最後にリスナーを作成し、NLBとターゲットグループを関連づけます。ロードバランサーのARNとターゲットグループのARNを指定します。
ECSサービスの作成
続いて、ECSサービスを作成します。まず、次のコマンドを発行し、先に作成したタスク定義とリビジョン番号を確認しておきます。
この結果を用いて、次の内容をecs-service.jsonという名前で準備します。上で確認したタスク定義とリビジョン番号はtaskDefinitionに指定します。作成したターゲトグループをこのサービスに関連づけます。コンテナ名とポートはタスク定義に指定した値を指定します。今回の要件では1台のスポットインスタンスに複数のコンテナアプリケーションが稼働する場合があるため、schedulingStrategyにREPLICAを指定します。タスクが配置されるサブネットにはプライベートサブネットを指定し、共通で用いるセキュリティグループを指定します。
そしてこのjsonを用いてECSサービスを作成します。
動作確認
改めて、2台のインスタンスがコンテナインスタンスとしてECSクラスターに登録されていることを確認します。スポットインスタンスの中断等の理由で2台を下回る場合には、上述のaws ec2 run-instancesコマンドを発行し、新たなスポットインスタンスを起動してください。コンテナインスタンスARNの末尾に与えられる、コンテナインスタンスIDを控えておいてください。
続いてサービスから自動的に起動されたタスクを確認します。タスク定義では1コンテナあたり2vCPUを要求しました。またサービス定義ではこのコンテナを3つ要求しました。m5.large, m5.xlargeそれぞれのvCPU数は2と4ですので、それぞれ1つ、および2つのタスクが起動することになります。list-tasksにそれぞれのコンテナインスタンスIDを渡し、コンテナインスタンスごとの起動されたタスク数を確認しましょう。
おめでとうございます! ここまでの手順で、インスタンスサイズに応じてコンテナを配置することができました。本検証の目的であった、インスタンスタイプ間の性能差を吸収してサービス側の処理性能を均質化する、というゴールを達成できたことになります。
それぞれのタスクのプライベートIPアドレスを確認しておきます。先ほどlist-taskコマンドで確認したタスクIDの一覧を与え、describe-tasksコマンドから次のようにプライベートIPアドレスのリストを抽出します。
NLBへのアクセス確認
最後に構築したシステムに対してNLB経由でアクセスし、そのリクエストがコンテナタスクごとに負荷分散される様子を確認します。冒頭でコンテナアプリケーションのDockerイメージを作成したとき、ドキュメントルート直下のipaddr.phpにアクセスするとそのHTTPサーバーのIPアドレスを返すように設定したのを思い出してください。
手元のコマンドラインコンソールからcurlコマンドで、NLBのDNS名とパスから構成されるURLに何度かアクセスします。
NLBのリクエストルーティングアルゴリズムは、ALBとは異なりラウンドロビンではありません。したがって、アクセスのたびに接続先ターゲットコンテナが変化するという動作にはなりにくいですが、何度かアクセスすると接続先が変化することを確認できます。ルーティングアルゴリズムの違いについてはELBドキュメントの「Elastic Load Balancing の仕組み – ルーティングアルゴリズム」を参照してください。
終わりに
スポットインスタンスを活用するとき、システムを中断の発生に強くするために、可能な限りすべてのアベイラビリティゾーンを指定し、幅広いインスタンスタイプを選択してスポットプールを拡充していくことが極めて重要です。
今回の記事では、DeNA様が掲げた、可能な限り多くのスポットプールを定義するためにインスタンスタイプ間の性能差を吸収し、サービス側の処理性能を均質化する、という目標に対して、Amazon ECSで実現する一例を見てきました。
今回の構成を実際のワークロードに適用するには、DeNA様が最優先で力を入れていたように、自動スケールの仕組みを導入することが求められることでしょう。今回の構成を自動スケールさせるためには、RunInstancesで起動した手順をAuto Scalingグループに置き換えるのが最初のステップになります。またさらに発展的に、Auto Scalingと統合したECSの機能の一部であるキャパシティプロバイダーおよびCluster Auto Scalingを用いることも、大変有力なアイデアです。
今後さらに、インスタンスタイプ間の性能差を吸収するというテーマをベースに、もしAmazon Elastic Kubernetes Service (Amazon EKS)およびKubernetesを用いたらどのようになるのか、またDeNA様のようにEC2インスタンス単体で実現するとしたらどのようにできるか、といった実現例をご紹介する機会を持てればと考えています。
今回の記事が、みなさまのスポットインスタンス活用の一助になることを願っています。