Amazon Web Services ブログ
複数の Amazon Redshift クラスターにわたってシステムテーブルのデータを保持する方法、およびクラスター間診断クエリを実行する方法
Amazon Redshift は、システムの履歴を STL ログテーブルに記録するデータウェアハウスサービスです。STL ログテーブルは、ログ使用状況とディスクの空き容量に応じて、2 〜 5 日間だけログ履歴を保持し、ディスクスペースを管理します。
Amazon Redshift は、監査データ用に一部の STL テーブルを Amazon S3 に自動ロギングする機能を備えています。含まれるログは、主にデータベースセキュリティとクエリの実行に関係するものです。これらの監査ログの使用については、前回の記事 「Analyze Database Audit Logs for Security and Compliance Using Amazon Redshift Spectrum」 で説明しました。
監査ログに含まれていない STL テーブルのデータからシステムデータを保持する場合は、通常、すべてのシステムテーブルに対してレプリカテーブルを作成する必要があります。次に、各レプリカテーブルに対し、システムテーブルからのデータを定期的にレプリカにロードします。STL テーブルのレプリカテーブルを管理することで、STL テーブルの履歴データに対して診断クエリを実行できます。その後、クエリの実行時間、クエリプラン、およびディスクスピルのパターンから詳細な情報を導き出し、より良いクラスターサイズを決定します。ただし、定期的な間隔で STL テーブルのライブデータでレプリカテーブルを更新するには、Cron や AWS Data Pipeline などのスケジューラが必要です。また、これらのテーブルは 1 つのクラスターに固有であり、クラスターが終了した後はアクセスできません。これは、アドホッククエリ実行が決められた期間だけ続く一時的な Amazon Redshift クラスターに、特に当てはまります。
このブログ記事では、複数の Amazon Redshift クラスターのシステムテーブルを Amazon S3 バケットにエクスポートするソリューションを紹介します。このソリューションはサーバーレスで、5 分ごとの間隔でスケジュールを設定できます。ここで使用する AWS CloudFormation デプロイメントテンプレートは、ご自分の環境でソリューションの設定を自動化できます。Amazon S3 バケット内のシステムテーブルのデータは、クラスター名とクエリ実行日によってパーティション化され、クラスター間診断クエリで効率的な結合が可能になります。
この記事の後半に、別の CloudFormation テンプレートも用意しています。この 2 つ目のテンプレートは、Amazon S3 に格納されているシステムテーブルデータ用の AWS Glue データカタログで、テーブルの作成を自動化するのにお役に立てるでしょう。システムテーブルを Amazon S3 にエクスポートしたら、システムテーブルのデータに対してクラスター間診断クエリを実行します。これで、各 Amazon Redshift クラスターのクエリ実行に関する詳細な情報を得ることができます。これは、Amazon QuickSight、Amazon Athena、Amazon EMR、またはAmazon Redshift Spectrum を使用して行うことができます。
CloudFormation テンプレート、AWS Glue 抽出、変換、ロード (ETL) スクリプト、こちらの GitHub リポジトリで発生する可能性がある一般的なエラーの解決手順など、この記事ではあらゆるコード例が載せています。
ソリューションの概要
この記事のソリューションは、AWS Glue を使用して、Amazon Redshift クラスターから Amazon S3 にシステムテーブルのログデータをエクスポートすることです。AWS Glue ETL ジョブは、AWS Lambda がスケジュールした間隔で起動します。AWS Systems Manager には、構成データ管理とシークレット管理のための安全な階層ストレージが用意されており、ソリューションが有効になっている Amazon Redshift クラスターの詳細を維持します。クラスターテーブルのそれぞれの組み合わせの最後に取得したタイムスタンプ値は、Amazon DynamoDB テーブルに保持されます。
次の図は、このソリューションに関連する重要な手順を示しています。
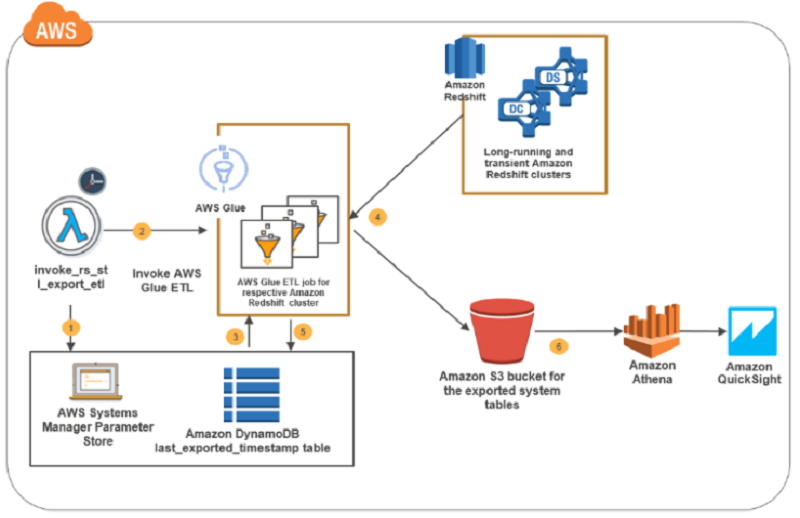
前のフローチャートに示したソリューションは、次のようになります。
- Lambda 関数 invoke_rs_stl_export_etl は、Amazon CloudWatch で制御されて、定期的にトリガーされます。この関数は、AWS Systems Manager パラメータストアを参照して、システムテーブルエクスポートが有効になっている Amazon Redshift クラスターの詳細を取得するようにトリガーします。
- 手順 1 で取得した Amazon Redshift クラスターの詳細に基づいた同じ Lambda 関数は、Amazon Redshift クラスター用に指定した AWS Glue ETL ジョブを呼び出します。クラスターの ETL ジョブが見つからない場合、Lambda 関数は ETL ジョブを作成します。
- Amazon Redshift クラスターに対して呼び出された ETL ジョブは、パラメータストアからクラスター認証情報を取得します。DynamoDB テーブルから、各システムテーブルがそれぞれの Amazon Redshift クラスターからエクスポートされた時の最後にエクスポートされたタイムスタンプを取得します。
- ETL ジョブは、Amazon Redshift クラスターのシステムテーブルデータを Amazon S3 バケットにアンロードします。
- ETL ジョブは、Amazon Redshift クラスターからエクスポートされた各システムテーブルの最後にエクスポートされたタイムスタンプ値で、DynamoDB テーブルを更新します。
- Amazon Redshift のクラスターシステムテーブルのデータは Amazon S3 で使用でき、クラスター間診断クエリを実行するためのクラスター名と日付でパーティション化されています。
構成データを理解する
このソリューションでは、AWS Systems Manager パラメータストアを使用し、Amazon Redshift クラスター認証情報を安全に保存します。パラメータストアは、AWS Glue ETL ジョブがシステムテーブルのデータを抽出し Amazon S3 に格納するために必要な他の構成情報も安全に格納します。Systems Manager には、Amazon Redshift クラスター認証情報のパスワードコンポーネントを暗号化するのに使用するデフォルトの AWS Key Management Service (AWS KMS) キーが付属しています。
次のテーブルは、このソリューションで必要なグローバルパラメータとクラスター固有のパラメータについて説明しています。グローバルパラメータは一度定義されると、ソリューション全体のレベルで適用されます。クラスター固有のパラメータは、Amazon Redshift クラスターに特有のもので、この記事にあるソリューションを有効にするクラスターごとに繰り返します。この記事の後半で説明する CloudFormation テンプレートは、これらのパラメータをデプロイメントプロセスの一部として作成します。
| パラメータ名 | タイプ | 説明 |
| Global parameters—defined once and applied to all jobs | ||
| redshift_query_logs.global.s3_prefix | 文字列 | クエリログがエクスポートされる Amazon S3 パス。このパスの下で、エクスポートされた各テーブルはクラスター名と日付によってパーティション化されます。 |
| redshift_query_logs.global.tempdir | 文字列 | AWS Glue ETL ジョブが一時的にデータをステージングするために使用する Amazon S3 パス。 |
| redshift_query_logs.global.role> | 文字列 | AWS Glue ETLジョブ が引き受けるロール名。ロール名だけで結構です。完全な Amazon Resource Name (ARN) は必要ありません。 |
| redshift_query_logs.global.enabled_cluster_list | StringList | システムテーブルのデータエクスポートが有効になっているク、カンマ区切りのクラスター名リスト。これにより、ユーザーが特定のクラスターを除外する柔軟性が得られます。 |
| Cluster-specific parameters—for each cluster specified in the enabled_cluster_list parameter | ||
| redshift_query_logs.<<cluster_name>>.connection | 文字列 | Amazon Redshift クラスターへの AWS Glue データカタログの接続名。例えば、クラスター名が product_warehouse の場合、エントリは redshift_query_logs.product_warehouse.connection となります。 |
| redshift_query_logs.<<cluster_name>>.user | 文字列 | AWS Glue が Amazon Redshift クラスターに接続するために使用するユーザー名。 |
| redshift_query_logs.<<cluster_name>>.password | 安全な文字列 | AWS KMS で管理する Amazon Redshift クラスターの encrypted-by キーに AWS Glue が接続するために使用するパスワード。 |
例えば、この記事で解説されているソリューションが有効になっている 2 つの Amazon Redshift クラスター、product-warehouse および category-management があるとします。この場合、次のスクリーンショットに示すように、パラメータは AWS Systems Manager パラメータストアのソリューションデプロイメントである CloudFormation テンプレートが作成します。

ソリューションのデプロイメント
開発を簡単に開始できるように、ソリューションを自動的に構成およびデプロイする CloudFormation テンプレートを作成しました。デプロイ後に行う手順は、たった 1 つしかありません。
前提条件
ソリューションをデプロイするには、プライベートサブネットに 1つ以上の Amazon Redshift クラスターが必要です。このサブネットには、ネットワークアドレス変換 (NAT) ゲートウェイ、または NAT インスタンスが設定されている必要があります。また、すべての TCP ポートに対して自己参照の受信ルールを持つセキュリティグループも必要です。前述の AWS Glue ETL に必要な設定が必要な理由の詳細については、AWS Glue のドキュメントの「VPC の JDBC データストアに接続する」を参照してください。
デプロイメントを開始するには、CloudFormation テンプレートを起動します。
![]()
CloudFormation スタックパラメータ
次のテーブルは、複数の Amazon Redshift クラスターからクエリログをエクスポートするソリューションをデプロイするためのパラメータを一覧にし、解説しています。
| プロパティ | デフォルト | 説明 |
| S3Bucket | mybucket | このソリューションは、エクスポートされたクエリログの格納、コードアーティファクトの生成、Amazon Redshift からアンロード実行するために使用するバケットです。例えば、mybucket/extract_rs_logs/data バケットは、クラスターがパーティション化した各システムテーブルのエクスポートされたすべてのクエリログを格納するために使用します。mybucket/extract_rs_logs/temp/bucket は、Amazon Redshift からアンロードされたデータを一時的にステージングするために使用します。mybucket/extract_rs_logs/code バケットは、Lambda および AWS Glue ETL ジョブに必要なすべてのコードアーティファクトを格納するために使用します。 |
| ExportEnabledRedshiftClusters | 必要な入力 | システムテーブルログをエクスポートする必要があるクラスター名のカンマ区切りのリスト。 |
| DataStoreSecurityGroups | 必要な入力 | ExportEnabledClusters パラメータが提供する Amazon Redshift クラスターへの受信ルールを持つセキュリティグループのリスト。これらのセキュリティグループは、「VPC の JDBC データストアに接続する」で説明されているように、すべての TCP ポートで自己参照受信ルールを持つ必要もあります。 |
テンプレートを起動してスタックを作成すると、以下のリソースが作成されていることが分かります。
- CloudFormation スタックパラメータ ExportEnabledRedshiftClusters にある Amazon Redshift クラスターごとの AWS Glue 接続。
- このソリューションに必要なパラメータはすべて、パラメータストアで作成されます。
- 設定された各 Amazon Redshift クラスターの AWS Glue ETL ジョブを 5 分間隔で起動する Lambda 機能。
- エクスポートされた各クラスターテーブルの組み合わせの最後にエクスポートされたタイムスタンプを取得する DynamoDB テーブル。
- AWS Glue ETL ジョブは、CloudFormation スタックパラメータ ExportEnabledRedshiftClusters が提供する各 Amazon Redshift クラスターから、クエリログをエクスポートします。
- Lambda 機能と AWS Glue ETL ジョブに必要な IAM ロールとポリシー。
デプロイ後
各 Amazon Redshift クラスターが CloudFormation スタックパラメータ ExportEnabledRedshiftClusters を介してソリューションを有効にした場合、自動デプロイには、デプロイ後に更新する必要がある一時的な認証情報を含んでいます。
- パラメータストアに移動します。
- このソリューションを有効にした 各 Amazon Redshift クラスターに対応する、パラメータ <<cluster_name>>.user 、および redshift_query_logs.<<cluster_name>>.password を書き留めます。これらのパラメータを編集して、プレースホルダーの値を正しい認証情報で置き換えます。
例えば、product-warehouse がシステムテーブルエクスポートを有効にしたクラスターの 1 つである場合は、適切なユーザー名とパスワードでこれら 2 つのパラメータを編集し、[Save parameter] を選択します。


エクスポートされたシステムテーブルのクエリを実行する
ソリューションデプロイメントの実行後数分以内に、Amazon Redshift クエリログが Amazon S3 の場所 <<S3Bucket_you_provided>>/extract_redshift_query_logs/data/ にエクスポートされていることが分かります。そのバケットには、8 つのシステムテーブルが顧客名と日付で区切られて表示されています。stl_alert_event_log, stl_dlltext, stl_explain, stl_query, stl_querytext, stl_scan, stl_utilitytext, and stl_wlm_query.

エクスポートされたシステムテーブルに対してクラスター間診断クエリを実行するには、AWS Glue データカタログで外部テーブルを作成します。これを簡単に行うため、Amazon S3 に格納されているエクスポートされたシステムテーブルをクロールし、AWS Glue データカタログに外部テーブルを構築する AWS Glue クローラを作成するための CloudFormation テンプレートを用意しています。
![]()
この CloudFormation テンプレートを起動して、Amazon Redshift システムテーブルに対応する外部テーブルを作成します。S3Bucket は、このスタックデプロイメントに必要な唯一の入力パラメータです。システムテーブルのデータをエクスポートする場所と同じ Amazon S3 バケット名を指定します。スタックを正常に作成すると、次のスクリーンショットに示すように、データベース内の 8 つのテーブル redshift_query_logs_db が表示されます。

次に、Athena コンソールに移動して、クラスター間診断クエリを実行します。次のスクリーンショットは、複数の Amazon Redshift クラスターに記録されたクエリアラートを取得する Athena で実行される診断クエリを示しています。

さらに、既存のクラスターのいずれかで Redshift Spectrum から同じ AWS Glue データカタログ外部テーブルをクエリすることもできます。
Athena でクラスター間診断クエリを実行し、複数の Amazon Redshift クラスター間の時間クエリ数と主要クエリアラートイベントを識別します。これで次にある Amazon QuickSight ダッシュボードの例を構築できます。

ソリューションの拡張方法
この投稿のソリューションは、次の 2 つの方法で拡張が可能です。
- ソリューションをデプロイした後に、スピンアップした新しい Amazon Redshift クラスターを追加します。
- 他のシステムテーブルまたはカスタムクエリ結果を、Amazon Redshift クラスターからのエクスポートリストに追加します。
ソリューションを他の Amazon Redshift クラスターに拡張する
ソリューションをもっと多くの Amazon Redshift クラスターに拡張するには、この記事の前半にあるガイドラインに従って、AWS Systems Manager パラメータストアに 3 つのクラスター固有パラメータを追加します。新しいクラスターをカンマ区切り文字列に加えるには、redshift_query_logs.global.enabled_cluster_list パラメータを変更します。
他のテーブルやカスタムクエリを Amazon Redshift クラスターに追加するためのソリューションを拡張する
現在のソリューションには、次の Amazon Redshift システムテーブルのエクスポート機能が付属しています。
- stl_alert_event_log
- stl_dlltext
- stl_explain
- stl_query
- stl_querytext
- stl_scan
- stl_utilitytext
- stl_wlm_query
AWS Glue ETL ジョブに数行のコード <<cluster-name>_extract_rs_query_logs を追加することで、別のシステムテーブルまたはカスタムクエリを簡単に追加することができます。例えば、product-warehouse Amazon Redshift クラスターから 2000 USD 以上の注文をエクスポートしたいとします。それには、次の 5 行のコードを AWS Glue ETL ジョブ product-warehouse_extract_rs_query_logs に追加します。ここで product-warehouse はクラスター名です。
- 最後に処理されたタイムスタンプ値を取得します。この関数は、まだ存在しない場合に値を作成します。
salesLastProcessTSValue = functions.getLastProcessedTSValue(trackingEntry=”mydb.sales_2000",job_configs=job_configs)
- タイムスタンプの付いたカスタムクエリを実行します。
returnDF=functions.runQuery(query="select * from sales s join order o where o.order_amnt > 2000 and sale_timestamp > '{}'".format (salesLastProcessTSValue) ,tableName="mydb.sales_2000",job_configs=job_configs)
- 結果を Amazon S3 に保存します。
functions.saveToS3(dataframe=returnDF,s3Prefix=s3Prefix,tableName="mydb.sales_2000",partitionColumns=["sale_date"],job_configs=job_configs)
- 手順 2 で返されたデータフレームから、最新のタイムスタンプ値を取得します。
latestTimestampVal=functions.getMaxValue(returnDF,"sale_timestamp",job_configs)
- DynamoDB テーブルの最後に処理されたタイムスタンプ値を更新します。
functions.updateLastProcessedTSValue(“mydb.sales_2000",latestTimestampVal[0],job_configs)
結論
この記事では、複数の Amazon Redshift クラスター全体で、システムテーブルのログデータを保持するサーバーレスソリューションを紹介しました。このソリューションで、データをシステムテーブルから Amazon S3 へ徐々にエクスポートできます。このエクスポートを実行すると、クラスター間診断クエリと監査ダッシュボードを構築し、Athena などのサービスを使用して容量計画についての詳細な情報を導き出すことができます。また、数行のコードを追加して、このソリューションを他のアドホッククエリのユースケースやシステムテーブル以外のテーブルに拡張する方法を解説しました。
その他の参考資料
この記事がお役にたった場合は、「本番環境で Amazon Redshift Spectrum、Amazon Athena、および AWS Glue を Node.js で使用する」、「Amazon Redshift – 2017 Recap」をぜひ参照してください。

著者について
 Karthik Sonti は、アマゾン ウェブ サービスのシニアビッグデータアーキテクトです。 AWS のお客様がビッグデータと分析ソリューションを構築するサポートを行い、アーキテクチャとベストプラクティスについて指導を行っています。
Karthik Sonti は、アマゾン ウェブ サービスのシニアビッグデータアーキテクトです。 AWS のお客様がビッグデータと分析ソリューションを構築するサポートを行い、アーキテクチャとベストプラクティスについて指導を行っています。