Amazon Web Services ブログ
AWS Glue for Apache Spark のコストのモニタリングと最適化
AWS Glue は、分析、機械学習 (ML)、アプリケーション開発のためのデータを発見、準備、組み合わせることを簡単にする、サーバーレスなデータインテグレーションサービスです。AWS Glue を使用すると、データインテグレーションと ETL (Extract, Transform, Load) のパイプラインを作成、実行、モニタリングし、複数のデータストアにわたるアセットをカタログ化することができます。
AWS Glue for Spark についてお客様から最もよくいただくご質問のひとつに、ワークロードのコストを効果的にモニタリングし、最適化する方法があります。AWS Glue では、コストに関係するオプションが多数提供されているため、データワークロードのコストを効果的に管理しながら、ビジネスニーズに応じたパフォーマンスとキャパシティを維持できます。AWS Glue ワークロードのコストを最適化するには、ジョブ実行をモニタリングして、実際にかかったコストと使用状況を分析し、節約できるポイントを見つけ、コードや構成の改善に向けたアクションを取ります。
この投稿では、AWS Glue ワークロードの上にモニタリングと最適化技術を用いることで、コストを管理および削減するためのアプローチを紹介します。
AWS Glue for Apache Spark の全体的なコストのモニタリング
AWS Glue for Apache Spark は、データ処理単位 (DPU) の数に基づいて最低 1 秒から 1 分単位の課金となります。 詳細は AWS Glue の料金をご覧ください。このセクションでは、AWS Glue for Apache Spark の全体的なコストをモニタリングする方法について説明します。
AWS Cost Explorer
AWS Cost Explorer で、DPU 時間の全体的な傾向を確認できます。次のステップを実行してください:
- Cost Explorer コンソールで、新しいコストと使用状況のレポートを作成します。
- サービスとして、Glue を選択します。
- 使用タイプとして、次のオプションを選択します。
- 標準ジョブの場合は <Region>-ETL-DPU-Hour (DPU-Hour) を選択します。
- Flex ジョブの場合は <Region>-ETL-Flex-DPU-Hour (DPU-Hour) を選択します。
- インタラクティブセッションの場合は <Region>-GlueInteractiveSession-DPU-Hour (DPU-Hour) を選択します。
- 適用を選択します。
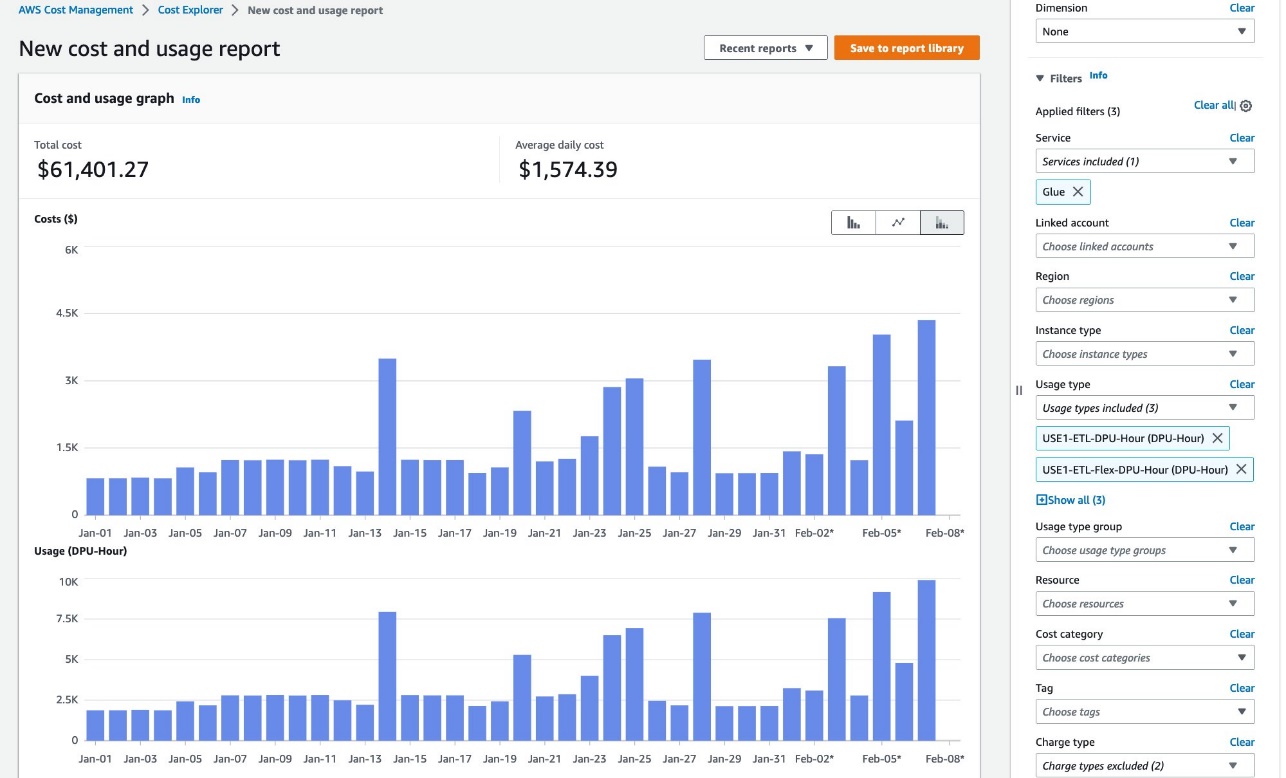
詳しくは AWS Cost Explorerを用いてコストを分析するをご確認ください。
個々のジョブ実行コストのモニタリング
このセクションでは、AWS Glue 上の Apache Spark ジョブの個々のジョブ実行コストをモニタリングする方法について説明します。これを実現するには 2 つのオプションがあります。
AWS Glue Studio の Monitoring ページ
AWS Glue Studio の Monitoring ページで、特定のジョブ実行に費やした DPU 時間をモニタリングできます。 次のスクリーンショットは、同じデータセットを処理した 3 つのジョブ実行を示しています。1 回目のジョブ実行では 0.66 DPU 時間、2 回目のジョブ実行では 0.44 DPU 時間を費やしました。Flex を使用した 3 回目は、わずか 0.32 DPU 時間で済みました。

GetJobRun および GetJobRuns API
ジョブ実行ごとの DPU 時間の値は、AWS API を通じて取得できます。
Auto Scaling ジョブと Flex ジョブの場合、DPUSeconds フィールドは GetJobRun API と GetJobRuns API のレスポンスで利用できます:
DPUSeconds フィールドは 1137.0 を返します。これは 1137.0/(60*60)=0.32 で計算できる 0.32 DPU 時間を意味します。
Auto Scaling のない他の標準ジョブの場合、DPUSeconds フィールドは利用できません:
これらのジョブの場合、DPU 時間は ExecutionTime*MaxCapacity/(60*60) で計算できます。そうすると 157*10/(60*60)=0.44 で 0.44 DPU 時間が得られます。AWS Glue バージョン 2.0 以降は 1 分が課金の最小単位であることに注意してください。
AWS CloudFormation テンプレート
DPU 時間は GetJobRun API や GetJobRuns API で取得できるため、これを Amazon CloudWatch などの他のサービスと統合して、消費された DPU 時間の傾向を経時的にモニタリングできます。 たとえば、AWS Glue ジョブの実行が完了するたびに AWS Lambda 関数を呼び出して CloudWatch メトリクスを公開する Amazon EventBridge ルールを設定できます。
これを素早く設定するために、AWS CloudFormation テンプレートを提供しています。このテンプレートは、ニーズに合わせて見直しやカスタマイズできます。このスタックがデプロイするリソースの一部は、使用時にコストが発生します。
CloudFormation テンプレートは、次のリソースを生成します:
- AWS Identity and Access Management (IAM) ロール
- Lambda 関数
- EventBridge ルール
リソースを作成するには、次のステップを完了してください:
- AWS CloudFormation コンソールにサインインします。
- Launch Stack を選択します。

- 次へ を選択します。
- 次へ を選択します。
- 次のページで、次へ を選択します。
- 最終ページの詳細を確認し、AWS CloudFormation によって IAM リソースがカスタム名で作成される場合があることを承認します を選択します。
- スタックの作成 を選択します。
スタックの作成には最大 3 分かかります。
スタックの作成が完了した後、AWS Glue ジョブが完了すると、次の DPUHours メトリクスが CloudWatch の Glue 名前空間に発行されます:
- 集計メトリクス – ディメンション=[JobType、GlueVersion、ExecutionClass]
- ジョブごとのメトリクス – ディメンション=[JobName、JobRunId=ALL]
- ジョブ実行ごとのメトリクス – ディメンション=[JobName、JobRunId]
集計メトリクスとジョブごとのメトリクスは、次のスクリーンショットのように表示されます。
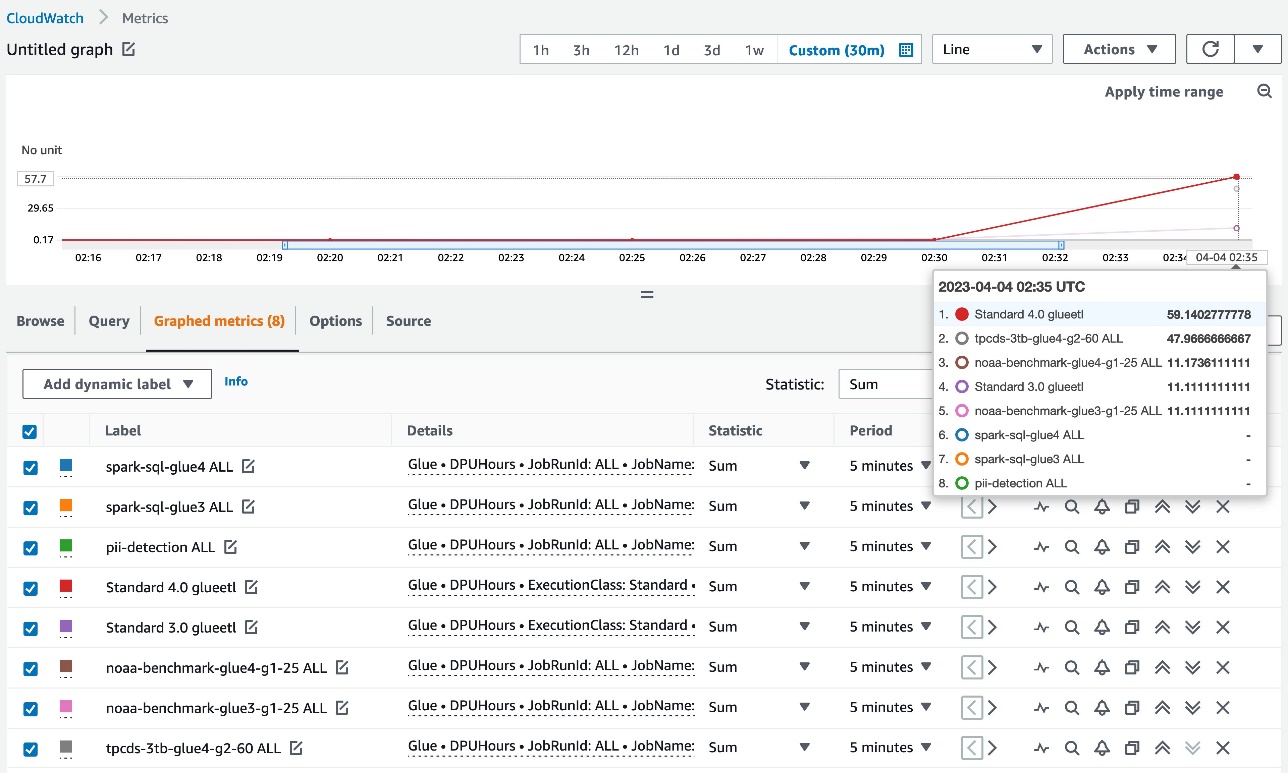
各データポイントは個々のジョブ実行ごとの DPU 時間数を表しているため、CloudWatch メトリクスの有効な統計は SUM です。CloudWatch メトリクスを使用することで、DPU 時間数を詳細に確認することができます。
コスト最適化のオプション
このセクションでは、Apache Spark 上の AWS Glue でコストを最適化するための主要なオプションについて説明します。
- 最新バージョンへのアップグレード
- Auto Scaling
- Flex
- ジョブのタイムアウト期間の適切な設定
- インタラクティブセッション
- ストリーミングジョブ用の小さいワーカータイプ
個々のオプションについて詳しく見ていきます。
最新バージョンへのアップグレード
AWS Glue ジョブを最新バージョンで実行することで、Apache Spark などのサポートされているエンジンのアップグレードバージョンで提供される最新の機能と改善を利用できます。 たとえば、AWS Glue 4.0 には、最適化された新しい Apache Spark 3.3.0 ランタイムが含まれており、ビルトインの pandas API のサポートに加え、Apache Hudi、Apache Iceberg、Delta Lake フォーマットへのネイティブサポートなど、データの分析と保存のためのより多くのオプションが使用できます。 また、TPC-DS ベンチマークで 10 倍高速な Amazon Redshift コネクタも含まれています。
Auto Scaling
コスト削減のための最も一般的な課題の 1 つは、ジョブを実行するのに適切なリソース量を特定することです。 ユーザーはリソース関連の問題を回避するためにワーカーを必要以上に確保する傾向がありますが、それらの DPU の一部は使用されず、不必要にコストが増加します。 バージョン 3.0 以降の AWS Glue では、Auto Scaling により、バッチジョブとストリーミングジョブの両方でワークロードに基づいてリソースを動的に増減することができます。 Auto Scaling は、ジョブにリソースを過剰にプロビジョニングしたり、アイドル状態のワーカーに料金を支払ったりしないようワーカー数を最適化する必要性を軽減します。
AWS Glue Studio で Auto Scaling を有効にするには、AWS Glue ジョブの Job Details タブに移動し、Automatically scale number of workers を選択します。

Flex
迅速なジョブ開始が必要ない場合や、ジョブの失敗時に再実行をする余裕のある緊急性の低いデータインテグレーションのワークロード場合は、Flex が良い選択肢となります。 Flex を使用するジョブの開始時間とランタイムは、すぐに利用できる余剰コンピューティングリソースが常にあるわけではなく、ジョブの実行中に回収される可能性があるため異なります。 Flex ベースのジョブは、カスタムコネクタへのアクセス、ビジュアルジョブ作成エクスペリエンス、ジョブスケジューリングシステムなど、同じ機能を提供します。 Flex オプションを使用することで、ワークロードのコストを最大 34% 削減できます。
AWS Glue Studio で Flex を有効にするには、ジョブの Job Details タブに移動し、Flex execution を選択します。

詳細は、Introducing AWS Glue Flex jobs: Cost savings on ETL workloads をご覧ください。
インタラクティブセッション
AWS Glue ジョブのスクリプトを開発する際には、コードに変更を加えるたびにジョブを繰り返し実行するのが一般的です。しかし、ジョブに割り当てられたワーカーの数と実行回数によってはコスト効率が良くない場合があります。また、このアプローチではジョブの実行完了を待つ必要があるため、開発に時間がかかってしまう可能性があります。この問題に対処するために、2022年に AWS Glue インタラクティブセッション をリリースしました。この機能により、開発者は Jupyter ベースのノートブックや IDE を使用してインタラクティブにデータを処理できます。セッションは数秒で開始でき、ビルトインのコスト管理機能があります。AWS Glue ジョブと同様に、使用したリソースに対してのみ課金されます。インタラクティブセッションを使用すると、コード全体を実行することなく、コードの変更をテストするためにコードを 1 行ずつテストできます。
ジョブのタイムアウト期間の適切な設定
設定の問題、スクリプトのコーディングエラー、データの異常などのため、AWS Glue ジョブが異常に長い時間がかかったり、データの処理に苦労することがあります。これによって予期しない課金が発生する可能性があります。AWS Glue では、任意のジョブに対してタイムアウト値を設定できます。デフォルトでは、AWS Glue ジョブは 48 時間のタイムアウト値で設定されていますが、任意のタイムアウトを指定できます。ジョブの平均実行時間を特定し、それに基づいて適切なタイムアウト期間を設定することをおすすめします。こうすることで、ジョブ実行ごとのコストを制御し、予期しない課金を防ぐことができます。また、ジョブに関連する問題をより早期に検出できます。
AWS Glue Studio のタイムアウト値を変更するには、ジョブの Job Details タブに移動し、Job timeout に値を入力します。

インタラクティブセッションでは、セッションのアイドルタイムアウト値を設定することもできます。Spark ETL セッションのデフォルトのアイドルタイムアウト値は 2880 分 (48 時間) です。タイムアウト値を変更するには、%idle_timeout magic を使用できます。
ストリーミングジョブ用の小さいワーカータイプ
リアルタイムデータ処理はお客様にとって一般的なユースケースですが、これらのストリームには断続的でデータ量の少ないものもあります。特にストリーミングジョブを 24 時間 365 日実行する必要がある場合、G.1X や G.2X のワーカータイプがワークロードに対して大きすぎる可能性があります。コスト削減を支援するために、2022 年にストリーミング ETL ジョブのための 1/4 DPU ワーカータイプである G.025X をリリースしました。この新しいワーカータイプを使用することで、データ量の少ないストリームを 1/4 のコストで処理できます。
AWS Glue Studio で G.025X ワーカータイプを選択するには、ジョブの Job Details タブに移動します。Type で Spark Streaming を選択した後、Worker type で G 0.25X を選択します。

詳細は、Best practices to optimize cost and performance for AWS Glue streaming ETL jobs をご覧ください。
コスト最適化のためのパフォーマンス調整
パフォーマンスチューニングはコスト削減において重要な役割を果たします。 パフォーマンスチューニングの第一歩は、ボトルネックを特定することです。 パフォーマンスを測定せず、ボトルネックを特定せずにコスト効果的な最適化を行うことは現実的ではありません。 CloudWatch メトリクスは簡単なビューを提供し、迅速な分析を可能にします。また、Spark UI はパフォーマンスチューニングのためのより深いビューを提供します。 ジョブで Spark UI を有効にし、UI を表示してボトルネックを特定することを強くおすすめします。
コストを最適化するための戦略の概要は以下のとおりです。
- クラスターキャパシティのスケール
- スキャンするデータ量の削減
- タスクの並列化
- シャッフルの最適化
- データの偏りを克服
- クエリプランニングの高速化
この投稿では、スキャンするデータ量を減らし、タスクを並列化する技術について説明します。
スキャンデータ量の削減: ジョブブックマークの有効化
AWS Glue ジョブのブックマークは、ジョブを定期的な間隔で複数回実行する場合に、データを増分的に処理する機能です。ユースケースが増分データロードの場合、すべてのジョブ実行のフルスキャンを避け、最後のジョブ実行からの差分のみを処理するために、ジョブのブックマークを有効にできます。これにより、スキャンするデータ量が削減され、個々のジョブ実行が加速されます。
データスキャン量の削減: パーティションのプルーニング
入力データがあらかじめパーティション分割されている場合は、パーティションの切り捨てによってスキャンするデータ量を減らすことができます。
AWS Glue DynamicFrame の場合、次のコード例のように push_down_predicate (と catalogPartitionPredicate) を設定します。詳細は、AWS Glue での ETL 出力のパーティションの管理をご覧ください。
Spark DataFrame (または Spark SQL) の場合、where 句や filter 句を設定してパーティションを剪定します。
タスクの並列化: JDBC読み込みの並列化
JDBC ソースからの同時読み取り数は、構成によって決定されます。 デフォルトでは、単一の JDBC 接続が SELECT クエリを介してソースからすべてのデータを読み取ることに注意してください。
AWS Glue DynamicFrame と Spark DataFrame の両方が、データセットを分割することにより、複数のタスクにわたるデータスキャンを並列化してサポートしています。
AWS Glue DynamicFrame の場合、hashfield または hashexpression と hashpartition を設定します。 詳細は、JDBC テーブルからの並列読み取りをご覧ください。
Spark DataFrame の場合、numPartitions、partitionColumn、lowerBound、upperBound を設定します。 詳細は、JDBC To Other Databases をご覧ください。
まとめ
この投稿では、AWS Glue for Apache Spark のコストをモニタリングおよび最適化する方法論について説明しました。これらの手法により、AWS Glue for Spark のコストを効果的にモニタリングし、最適化できます。
付録: Amazon CloudWatch の料金
AWS Glue ジョブで Amazon CloudWatch を使用する場合、CloudWatch メトリクスと CloudWatch ログに対して標準料金が請求されます。 詳細は Amazon CloudWatch の料金をご確認ください。
- ジョブのメトリクス: ジョブメトリクスを有効にすると追加料金が発生し、CloudWatch カスタムメトリクスが作成されます。
- アプリケーションログ: CloudWatch ロググループ
/aws-glue/jobs/outputと/aws-glue/jobs/errorの集計アプリケーションログについて追加料金が発生します。 - 連続ログ記録: 連続ログ記録を有効にすると追加料金が発生し、CloudWatch ログイベントが CloudWatch ロググループ
/aws-glue/jobs/logs-v2に出力されます。
Glue ジョブに関連する CloudWatch の料金を最適化したい場合、まずは AWS Cost Explorer で内訳を確認する必要があります。
CloudWatch メトリクスのコスト最適化
メトリクスの料金を削減するために、ジョブメトリクスを無効にすることができます。 この投稿で提供されている CloudFormation テンプレートはカスタムメトリクスを作成するため、さらに追加の料金が発生することに注意してください。
CloudWatch ログのコスト最適化
CloudWatch Logs の料金設定は、主に取り込みとアーカイブストレージで定義されます。
ログ取り込みの料金を削減するために、次のことができます:
- ジョブスクリプト内の不要なログ出力を減らしてください。
print()、df.show()、カスタムロガー呼び出しなどです - no filter ではなく、standard log filter を設定してください
- 本番ジョブのログレベルを
DEBUGに設定しないでください
ログアーカイブストレージの料金を削減するために、ロググループの保持期間を設定することができます。 詳細は、CloudWatch Logs でログデータ保管期間を変更するをご覧ください。
本記事は、Leonardo Gómez、関山宜孝による “Monitor and optimize cost on AWS Glue for Apache Spark” を翻訳したものです。 翻訳はソリューションアーキテクトの高橋が担当しました。