AWS Big Data Blog
Introducing AWS Glue Flex jobs: Cost savings on ETL workloads
AWS Glue is a serverless data integration service that makes it simple to discover, prepare, and combine data for analytics, machine learning (ML), and application development. You can use AWS Glue to create, run, and monitor data integration and ETL (extract, transform, and load) pipelines and catalog your assets across multiple data stores. Typically, these data integration jobs can have varying degrees of priority and time sensitivity. For example, non-urgent workloads such as testing and one-time data loads often don’t require fast job startup times or consistent runtimes via dedicated resources.
Today, we are pleased to announce the general availability of a new AWS Glue job run class called Flex. Flex allows you to optimize your costs on your non-urgent or non-time sensitive data integration workloads such as testing, and one-time data loads. With Flex, AWS Glue jobs run on spare compute capacity instead of dedicated hardware. The start and runtimes of jobs using Flex can vary because spare compute resources aren’t readily available and can be reclaimed during the run of a job
Regardless of the run option used, AWS Glue jobs have the same capabilities, including access to custom connectors, visual authoring interface, job scheduling, and Glue Auto Scaling. With the Flex execution option, customers can optimize the costs of their data integration workloads by configuring the execution option based on the workloads’ requirements, using standard execution option for time-sensitive workloads, and Flex for non-urgent workloads. The Flex execution class is available for AWS Glue 3.0 Spark jobs.
The Flex execution class is available for AWS Glue 3.0 Spark jobs.
In this post, we provide more details about AWS Glue Flex jobs and how to enable Flex capacity.
How do you use Flexible capacity?
The AWS Glue jobs API now supports an additional parameter called execution-class, which lets you choose STANDARD or FLEX when running the job. To use Flex, you simply set the parameter to FLEX.
To enable Flex via the AWS Glue Studio console, complete the following steps:
- On the AWS Glue Studio console, while authoring a job, navigate to the Job details tab
- Select Flex Execution.
- Set an appropriate value for the Job Timeout parameter (defaults to 120 minutes for Flex jobs).
- Save the job.
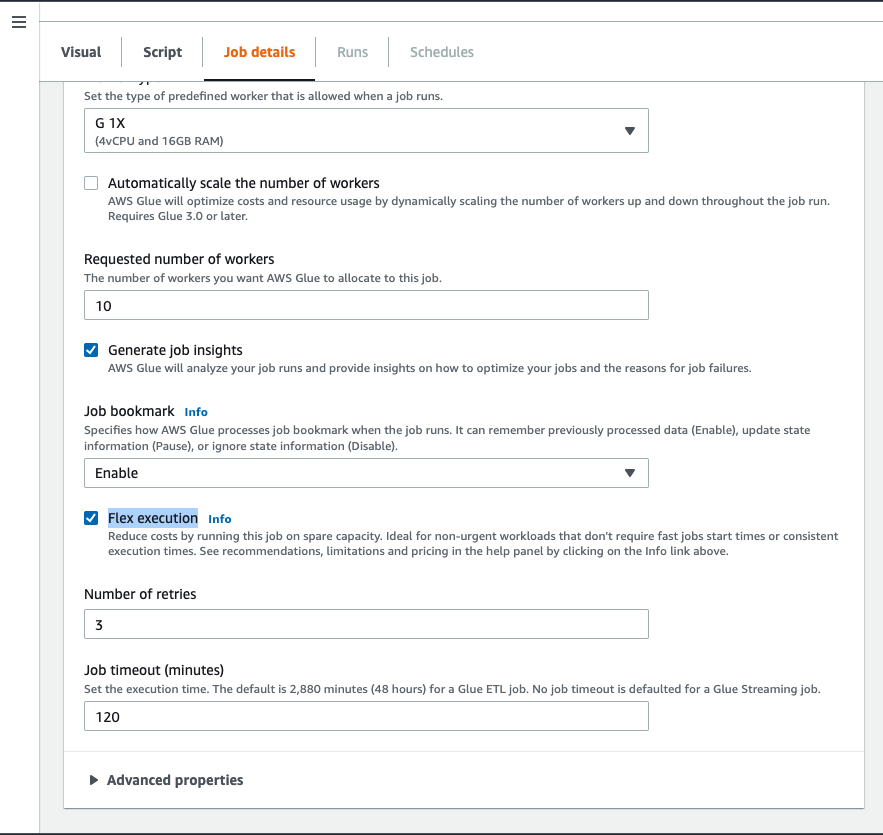
- After finalizing all other details, choose Run to run the job with Flex capacity.
On the Runs tab, you should be able to see FLEX listed under Execution class.
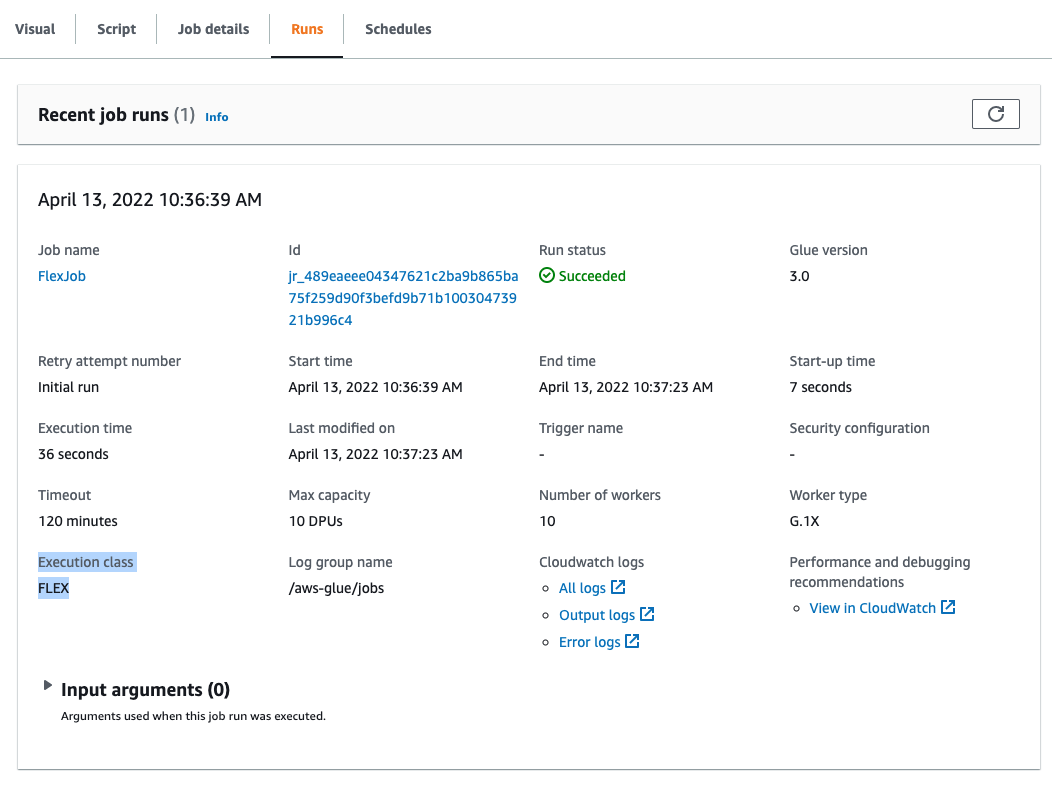
You can also enable Flex via the AWS Command Line Interface (AWS CLI).
You can set the --execution-class setting in the start-job-run API, which lets you run a particular AWS Glue job’s run with Flex capacity:
You can also set the --execution-class during the create-job API. This sets the default run class of all the runs of this job to FLEX:
The following are additional details about the relevant parameters:
- –execution-class – The enum string that specifies if a job should be run as FLEX or STANDARD capacity. The default is STANDARD.
- –timeout – Specifies the time (in minutes) the job will run before it’s moved into a TIMEOUT state.
When should you use Flexible capacity?
The Flex execution class is ideal for reducing the costs of time-insensitive workloads. For example:
- Nightly ETL jobs, or jobs that run over weekends for processing workloads
- One-time bulk data ingestion jobs
- Jobs running in test environments or pre-production workloads
- Time-insensitive workloads where it’s acceptable to have variable start and end times
In comparison, the standard execution class is ideal for time-sensitive workloads that require fast job startup and dedicated resources. In addition, jobs that have downstream dependencies are better served by the standard execution class.
What is the typical life-cycle of a Flexible capacity Job?
When a start-job-run API call is issued, with the execution-class set to FLEX, AWS Glue will begin to request compute resources. If no resources are available immediately upon issuing the API call, the job will move into a WAITING state. No billing occurs at this point.
As soon as the job is able to acquire compute resources, the job moves to a RUNNING state. At this point, even if all the computes requested aren’t available, the job begins running on whatever hardware is present. As more Flex capacity becomes available, AWS Glue adds it to the job, up to a maximum value specified by Number of workers.
At this point, billing begins. You’re charged only for the compute resources that are running at any given time, and only for the duration that they ran for.
While the job is running, if Flex capacity is reclaimed, AWS Glue continues running the job on the existing compute resources while it tries to meet the shortfall by requesting more resources. If capacity is reclaimed, billing for that capacity is halted as well. Billing for new capacity will start when it is provisioned again. If the job completes successfully, the job’s state moves to SUCCEEDED. If the job fails due to various user or system errors, the job’s state transitions to FAILED. If the job is unable to complete before the time specified by the --timeout parameter, whether due to a lack of compute capacity or due to issues with the AWS Glue job script, the job goes into a TIMEOUT state.
Flexible job runs rely on the availability of non-dedicated compute capacity in AWS, which in turn depends on several factors, such as the Region and Availability Zone, time of day, day of the week, and the number of DPUs required by a job.
A parameter of particular importance for Flex Jobs is the --timeout value. It’s possible for Flex jobs to take longer to run than standard jobs, especially if capacity is reclaimed while the job is running. As a result, selecting the right timeout value that’s appropriate for your workload is critical. Choose a timeout value such that the total cost of the Flex job run doesn’t exceed a standard job run. If the value is set too high, the job can wait for too long, trying to acquire capacity that isn’t available. If the value is set too low, the job times out, even if capacity is available and the job execution is proceeding correctly.
How are Flex capacity jobs billed?
Flex jobs are billed per worker at the Flex DPU-hour rates. This means that you’re billed only for the capacity that actually ran during the execution of the job, for the duration that it ran.
For example, if you ran an AWS Glue Flex job for 10 workers, and AWS Glue was only able to acquire 5 workers, you’re only billed for five workers, and only for the duration that those workers ran. If, during the job run, two out of those five workers are reclaimed, then billing for those two workers is stopped, while billing for the remaining three workers continues. If provisioning for the two reclaimed workers is successful during the job run, billing for those two will start again.
For more information on Flex pricing, refer to AWS Glue pricing.
Conclusion
This post discusses the new AWS Glue Flex job execution class, which allows you to optimize costs for non-time-sensitive ETL workloads and test environments.
You can start using Flex capacity for your existing and new workloads today. However, note that the Flex class is not supported for Python Shell jobs, AWS Glue streaming jobs, or AWS Glue ML jobs.
For more information on AWS Glue Flex jobs, refer to their latest documentation.
Special thanks to everyone who contributed to the launch: Parag Shah, Sampath Shreekantha, Yinzhi Xi and Jessica Cheng,
About the authors
 Aniket Jiddigoudar is a Big Data Architect on the AWS Glue team.
Aniket Jiddigoudar is a Big Data Architect on the AWS Glue team.
 Vaibhav Porwal is a Senior Software Development Engineer on the AWS Glue team.
Vaibhav Porwal is a Senior Software Development Engineer on the AWS Glue team.
 Sriram Ramarathnam is a Software Development Manager on the AWS Glue team.
Sriram Ramarathnam is a Software Development Manager on the AWS Glue team.