Amazon Web Services ブログ
Amazon SageMaker オブジェクト検出モデルのトレーニングと AWS IoT Greengrass での実行 – パート 3/3: エッジへのデプロイ
全体として構築しているアーキテクチャを思い出してください。:
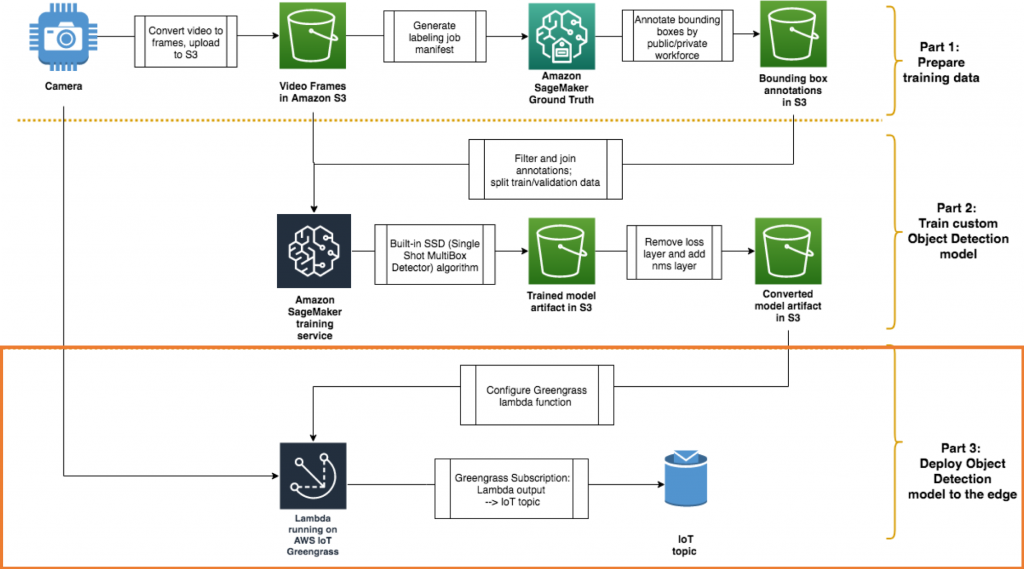
AWS アカウントの手順に従う
ご自身の AWS アカウントとエッジデバイスで、次の手順に従ってください。パート 1 とパート 2 は、このセクションに従うための前提条件ではありません。トレーニング済みのカスタムモデルまたは提供されているサンプルモデルのいずれかを使用できます(CDLA Permissive ライセンス条件下において)。
エッジデバイスに環境と AWS IoT Greengrass Core を設定する
エッジデバイスに AWS IoT Greengrass Core をインストールする前に、ハードウェアと OS の要件を確認してください。この投稿では、Ubuntu 18.04 AMI で Amazon EC2 インスタンスを使用しました。実際のエッジデバイスではなく、EC2 インスタンスを AWS IoT ユースケースのテストおよび開発環境として使用すると役立つことがよくあります。
デバイスをセットアップする
GPU 対応デバイスの場合は、CUDA などの GPU ドライバがインストールされていることを確認してください。デバイスに CPU しかない場合でも、推論を実行できますが、パフォーマンスは低下します。
また、モデル推論コードを実行するために必要な MXNet と OpenCV をエッジデバイスにインストールしてください。ガイダンスについては、こちらのドキュメントを参照してください。
次に、デバイスを設定し、環境のセットアップと AWS IoT Greengrass ソフトウェアのインストールの手順に従って AWS IoT Greengrass Core ソフトウェアをインストールします。
または、この AWS CloudFormation スタックを起動して、前のセットアップが完了したテスト EC2 インスタンスを起動します。:
![]()
AWS IoT Greengrass グループを作成する
これで、AWS クラウドに AWS IoT Greengrass グループを作成する準備が整いました。これを行う方法と、モデルをエッジで実行するように AWS Lambda 関数を構成する方法はいくつかあります。:
- 構成ファイルで AWS IoT Greengrass リソースを定義し、コマンドラインからデプロイを管理するためのオープンソース プロジェクトである Greengo を使用する: これは、この投稿で詳しく説明されているオプションです。
- AWS IoT Greengrass コンソールを使用する: 手順については、「Configure AWS IoT Greengrass on AWS IoT」を参照してください。
- AWS CloudFormationの使用: セットアップの例については、「Automating AWS IoT Greengrass Setup With AWS CloudFormation」を参照してください。
この投稿では、Greengo を使用してこのオブジェクト検出モデルを設定する手順を説明します。私たちのチームは、特にラピッドプロトタイピングや開発環境で使用する場合は、AWS IoT Greengrass のデプロイを管理するために Greengo プロジェクトを推奨しています。プロダクション環境の管理には AWS CloudFormation を使用することをお勧めします。
macOS または Linux コンピュータで、提供されたサンプルコードをまだダウンロードしていない場合は、git clone を使用してダウンロードします。ここに示すコマンドは、Windows ではテストされていません。
greengrass/ フォルダには、AWS IoT Greengrass グループの構成と Lambda 関数を定義する greengo.yaml ファイルがあります。ファイルの上部では、AWS IoT Greengrass グループと AWS IoT Greengrass Core の名前が定義されています。:
Group:
name: GG_Object_Detection
Cores:
- name: GG_Object_Detection_Core
key_path: ./certs
config_path: ./config
SyncShadow: TrueAWS IoT の AWS IoT Greengrass グループリソースの初期設定には、greengo.yaml のあるフォルダで次のコマンドを実行します。
pip install greengo
greengo createこれにより、すべての AWS IoT Greengrass グループのアーティファクトが AWS に作成され、AWS IoT Greengrass Core の証明書とconfig.json が ./certs/ と ./config/ に配置されます
また、デプロイ中にすべての適切なリソースを参照する状態ファイルを .gg/gg_state.json に生成します。:
scp を使用して certs および config フォルダをエッジ デバイス(またはテスト EC2 インスタンス)にコピーし、デバイスの /greengrass/certs/ および /greengrass/config/ ディレクトリにコピーします。
sudo cp certs/* /greengrass/certs/
sudo cp config/* /greengrass/config/デバイスで、Greengo が生成した証明書と互換性のあるルート CA 証明書も /greengrass/certs/ フォルダにダウンロードします。:
cd /greengrass/certs/
sudo wget -O root.ca.pem https://www.symantec.com/content/en/us/enterprise/verisign/roots/VeriSign-Class%203-Public-Primary-Certification-Authority-G5.pemAWS IoT Greengrass Core を開始する
これで、エッジデバイスで AWS IoT Greengrass Core デーモンを開始する準備が整いました。
$ sudo /greengrass/ggc/core/greengrassd start
Setting up greengrass daemon
Validating hardlink/softlink protection
Waiting for up to 1m10s for Daemon to start
...
Greengrass successfully started with PID: 4722最初の AWS IoT Greengrass グループのデプロイ
AWS IoT Greengrass デーモンが起動して実行されたら、ラップトップまたはワークステーションで GitHub からコード リポジトリをダウンロードした場所に戻ります。次に、greengrass/ フォルダー (greengo.yaml がある場所) に移動し、次のコマンドを実行します。:
greengo deployこれにより、greengo.yaml で定義した設定がエッジデバイスの AWS IoT Greengrass Core にデプロイされます。これまでのところ、Greengo 設定で Lambda 関数をまだ定義していないため、このデプロイは AWS IoT Greengrass Core を初期化するだけです。次のステップで簡単な動作テストを行った後、AWS IoT Greengrass セットアップに Lambda 関数を追加します。
MXNet 推論コード
前回の投稿の最後に、Jupyter ノートブックで次の推論コードを使用しました。 run_model/ フォルダーで、これを model_loader.py内の 1 つの Python クラス MLModel にまとめる方法を確認してください。:
class MLModel(object):
"""
Loads the pre-trained model, which can be found in /ml/od when running on greengrass core or
from a different path for testing locally.
"""
def __init__(self, param_path, label_names=[], input_shapes=[('data', (1, 3, DEFAULT_INPUT_SHAPE, DEFAULT_INPUT_SHAPE))]):
# use the first GPU device available for inference. If GPU not available, CPU is used
context = get_ctx()[0]
# Load the network parameters from default epoch 0
logging.info('Load network parameters from default epoch 0 with prefix: {}'.format(param_path))
sym, arg_params, aux_params = mx.model.load_checkpoint(param_path, 0)
# Load the network into an MXNet module and bind the corresponding parameters
logging.info('Loading network into mxnet module and binding corresponding parameters: {}'.format(arg_params))
self.mod = mx.mod.Module(symbol=sym, label_names=label_names, context=context)
self.mod.bind(for_training=False, data_shapes=input_shapes)
self.mod.set_params(arg_params, aux_params)
"""
Takes in an image, reshapes it, and runs it through the loaded MXNet graph for inference returning the top label from the softmax
"""
def predict_from_file(self, filepath, reshape=(DEFAULT_INPUT_SHAPE, DEFAULT_INPUT_SHAPE)):
# Switch RGB to BGR format (which ImageNet networks take)
img = cv2.cvtColor(cv2.imread(filepath), cv2.COLOR_BGR2RGB)
if img is None:
return []
# Resize image to fit network input
img = cv2.resize(img, reshape)
img = np.swapaxes(img, 0, 2)
img = np.swapaxes(img, 1, 2)
img = img[np.newaxis, :]
self.mod.forward(Batch([mx.nd.array(img)]))
prob = self.mod.get_outputs()[0].asnumpy()
prob = np.squeeze(prob)
# Grab top result, convert to python list of lists and return
results = [prob[0].tolist()]
return resultsデバイスの推定コードを直接 (オプション)
オプションですが、エッジデバイスで簡単なテストを実行して、他の依存関係 (MXNet など) が適切に設定されていることを確認することは常に役に立ちます。
前述の MLModel クラスをテストする単体テスト test_model_loader.py を作成しました。この GitHub リポジトリのコードを確認してください。
ユニットテストを実行するには、コードと機械学習 (ML) モデルのアーティファクトをエッジデバイスにダウンロードし、ユニットテストを開始します。:
git clone https://github.com/aws-samples/amazon-sagemaker-aws-greengrass-custom-object-detection-model.git
cd amazon-sagemaker-aws-greengrass-custom-object-detection-model/greengrass/run_model/resources/ml/od
wget https://greengrass-object-detection-blog.s3.amazonaws.com/deployable-model/deploy_model_algo_1-0000.params
cd ../../..
python -m unittest test.test_model_loader.TestModelLoader単体テストにパスしたら、AWS IoT Greengrass Lambda 関数内でこのコードを使用する方法を確認できます。
AWS IoT Greengrass Core で推論パイプラインを作成する
AWS IoT Greengrass を開始し、エッジデバイスで推論コードをテストしたので、すべてをまとめる準備ができました。AWS IoT Greengrass Core 内で推論コードを実行する AWS IoT Greengrass Lambda 関数を作成します。
AWS IoT Greengrass Lambda 関数の推論をテストするには、次のパイプラインを作成します。:

- オブジェクト検出推論コードを含む Lambda 関数は、AWS IoT Greengrass Core の BlogInferで実行されています。
- The AWS IoT トピック blog/infer/input 推論を行うエッジデバイス上の画像ファイルの場所について、BlogInfer Lambda 関数への入力を提供します。
- The IoT トピック blog/infer/output は BlogInfer Lambda 関数の予測出力をクラウドの AWS IoT メッセージ ブローカーに発行します。
AWS IoT Greengrass Lambda 関数のライフサイクル設定を選択する
AWS IoT Greengrass Lambda 関数には、on-demand と long-lived の 2 種類があります。 ML 推論を行うには、ML モデルをメモリに読み込むのに 300 ミリ秒以上かかることが多いため、モデルを long-lived 関数で実行する必要があります。
long-lived の AWS IoT Greengrass Lambda 関数で ML 推論コードを実行すると、初期化レイテンシーが 1 回だけ発生する可能性があります。AWS IoT Greengrass Core が起動すると、長時間実行される Lambda 関数用のコンテナが 1 つ作成され、実行され続けます。Lambda 関数を呼び出すたびに、同じコンテナが再利用され、すでにメモリに読み込まれている同じ ML モデルが使用されます。
Lambda 関数コードを作成する
前述の推論コードを Lambda 関数に変換するために、Lambda 関数のエントリポイントとして main.py を作成しました。これは long-lived 関数なので、MLModel オブジェクトは lambda_handler の外部で初期化してください。lambda_handler 関数内のコードは、関数が処理できる新しい入力があるたびに呼び出されます。
import greengrasssdk
from model_loader import MLModel
import logging
import os
import time
import json
ML_MODEL_BASE_PATH = '/ml/od/'
ML_MODEL_PREFIX = 'deploy_model_algo_1'
# Creating a Greengrass Core sdk client
client = greengrasssdk.client('iot-data')
model = None
# Load the model at startup
def initialize(param_path=os.path.join(ML_MODEL_BASE_PATH, ML_MODEL_PREFIX)):
global model
model = MLModel(param_path)
def lambda_handler(event, context):
"""
Gets called each time the function gets invoked.
"""
if 'filepath' not in event:
logging.info('filepath is not in input event. nothing to do. returning.')
return None
filepath = event['filepath']
logging.info('predicting on image at filepath: {}'.format(filepath))
start = int(round(time.time() * 1000))
prediction = model.predict_from_file(filepath)
end = int(round(time.time() * 1000))
logging.info('Prediction: {} for file: {} in: {}'.format(prediction, filepath, end - start))
response = {
'prediction': prediction,
'timestamp': time.time(),
'filepath': filepath
}
client.publish(topic='blog/infer/output', payload=json.dumps(response))
return response
# If this path exists, then this code is running on the greengrass core and has the ML resources to initialize.
if os.path.exists(ML_MODEL_BASE_PATH):
initialize()
else:
logging.info('{} does not exist and you cannot initialize this Lambda function.'.format(ML_MODEL_BASE_PATH))
Greengo を使用して AWS IoT Greengrass で ML リソースを構成する
エッジデバイスで単体テストを実行する手順を進めた場合は、ML モデルのパラメーターファイルを手動でエッジデバイスにコピーする必要がありました。これは、ML モデルアーティファクトのデプロイを管理するスケーラブルな方法ではありません。
ML モデルを定期的に再トレーニングし、新しいバージョンの ML モデルを引き続きデプロイするする場合はどうすれば良いでしょうか。複数のエッジデバイスがあり、すべてに新しい ML モデルを適用する必要がある場合はどうでしょうか。新しい ML モデルアーティファクトをエッジにデプロイするプロセスを簡素化するために、AWS IoT Greengrass は機械学習リソースの管理をサポートしています。
AWS IoT Greengrass で ML リソースを定義すると、そのリソースを AWS IoT Greengrass グループに追加します。グループ内の Lambda 関数がどのようにアクセスできるかを定義します。AWS IoT Greengrass グループのデプロイの一環として、AWS IoT Greengrass は Amazon S3 から ML アーティファクトをダウンロードし、それらを Lambda ランタイム名前空間内のディレクトリに抽出します。
そうすれば、AWS IoT Greengrass Lambda 関数はローカルにデプロイされたモデルを使用して推論を実行できます。ML モデルアーティファクトの新しいバージョンをデプロイする場合、AWS IoT Greengrass グループを再デプロイする必要があります。AWS IoT Greengrass サービスは、ソースファイルが変更されたかどうかを自動的に確認し、更新がある場合にのみ新しいバージョンをダウンロードします。
AWS IoT Greengrass グループで機械学習リソースを定義するには、greengo.yaml ファイルでこのセクションのコメントを外します。 (独自のモデルを使用するには、 S3Uri を独自の値に置き換えてください。)
Resources:
- Name: MyObjectDetectionModel
Id: MyObjectDetectionModel
S3MachineLearningModelResourceData:
DestinationPath: /ml/od/
S3Uri: s3://greengrass-object-detection-blog/deployable-model/deploy_model.tar.gz次のコマンドを使用して、構成の変更をデプロイします。:
greengo update && greengo deployAWS IoT Greengrass コンソールに、作成された ML リソースが表示されるはずです。次のスクリーンショットは、モデルのステータスが Unaffiliated であることを示しています。まだ Lambda 関数にアタッチしていないため、これは予期されることです。

ML リソースのデプロイのトラブルシューティングを行うには、AWS IoT Greengrass にはコンテナ化されたアーキテクチャがあることを覚えておくと役立ちます。 ML モデルアーティファクトなどのリソースをデプロイするときに、ファイルシステムのオーバーレイを使用します。
前述の例では、ML モデルのアーティファクトを /ml/od/ に抽出するように設定しても、AWS IoT Greengrass は実際に /greengrass/ggc/deployment/mlmodel/<uuid>/ のような場所にダウンロードします。このアーティファクトの使用を宣言した AWS IoT Greengrass のローカル Lambda 関数には、ファイルシステムのオーバーレイにより、抽出されたファイルが /ml/od/ に保存されているように見えます。
Greengo で Lambda 関数を設定する
Lambda 関数を設定して、以前に定義した機械学習リソースにアクセスできるようにするには、 greengo.yaml ファイルのコメントを外します。:
Lambdas:
- name: BlogInfer
handler: main.lambda_handler
package: ./run_model/src
alias: dev
greengrassConfig:
MemorySize: 900000 # Kb
Timeout: 10 # seconds
Pinned: True # True for long-lived functions
Environment:
AccessSysfs: True
ResourceAccessPolicies:
- ResourceId: MyObjectDetectionModel
Permission: 'rw'Lambda 関数の言語ランタイムを指定していません。これは、現在、Greengo プロジェクトが python2.7 を実行する Lambda 関数のみをサポートしているためです。
また、エッジデバイスに greengrasssdk がまだインストールされていない場合は、greengrasssdk を ./run_model/src/ ディレクトリにインストールして、Lambda デプロイパッケージに含めることができます。:
cd run_model/src/
pip install greengrasssdk -t .GPU 対応デバイスの使用
CPU のみのデバイスを使用している場合は、次のセクションにスキップできます。
GPU を備えたエッジデバイスまたはインスタンスを使用している場合は、AWS IoT Greengrass のローカルリソース機能を使用して、Lambda 関数が GPU デバイスにアクセスできるようにする必要があります。
greengo.yaml でデバイス リソースを定義するには、Resources の下のセクションのコメントを外します。:
- Name: Nvidia0
Id: Nvidia0
LocalDeviceResourceData:
SourcePath: /dev/nvidia0
GroupOwnerSetting:
AutoAddGroupOwner: True
- Name: Nvidiactl
Id: Nvidiactl
LocalDeviceResourceData:
SourcePath: /dev/nvidiactl
GroupOwnerSetting:
AutoAddGroupOwner: True
- Name: NvidiaUVM
Id: NvidiaUVM
LocalDeviceResourceData:
SourcePath: /dev/nvidia-uvm
GroupOwnerSetting:
AutoAddGroupOwner: True
- Name: NvidiaUVMTools
Id: NvidiaUVMTools
LocalDeviceResourceData:
SourcePath: /dev/nvidia-uvm-tools
GroupOwnerSetting:
AutoAddGroupOwner: True推論 Lambda 関数がデバイスリソースにアクセスできるようにするには、Lambda 関数の ResourceAccessPolicies 内の次のセクションのコメントを外します。
- ResourceId: Nvidia0
Permission: 'rw'
- ResourceId: Nvidiactl
Permission: 'rw'
- ResourceId: NvidiaUVM
Permission: 'rw'
- ResourceId: NvidiaUVMTools
Permission: 'rw'Greengo でトピックサブスクリプションを設定する
最後に、推論 Lambda 関数の呼び出しとその出力の受信をテストするために、推論 Lambda 関数の入力と出力のサブスクリプションを作成します。 greengo.yaml ファイルのこのセクションのコメントを外します。:
Subscriptions:
# Test Subscriptions from the cloud
- Source: cloud
Subject: blog/infer/input
Target: Lambda::BlogInfer
- Source: Lambda::BlogInfer
Subject: blog/infer/output
Target: cloudこれらの設定を AWS IoT Greengrass にデプロイするには、次のコマンドを実行します。
greengo update && greengo deployデプロイが完了したら、AWS IoT Greengrass コンソールでサブスクリプションの構成を確認することもできます。:

デプロイされた Lambda 関数を確認すると、ML リソースが関連付けられていることがわかります。:

AWS IoT Greengrass Lambda 関数をテストする
これで、Lambda 関数の呼び出しをテストできます。画像( 例 をエッジデバイスにダウンロードして、それを使用して推論をテストできるようにしてください。
{kind=link}
AWS IoT Greengrass コンソールで、Test を選択し、blog/infer/output トピックにサブスクライブします。次に、エッジデバイスで推論を行うための画像のパスを指定するメッセージを blog/infer/input に発行します。:

バウンディングボックスの予測結果が返されているはずです
リアルタイムのビデオ推論に利用する
これまでのところ、実装により、エッジデバイス上の画像ファイルで推論できる Lambda 関数が作成されます。ビデオソースでリアルタイムの推論を実行するために、アーキテクチャを拡張できます。カメラからビデオをキャプチャし、ビデオからフレームを抽出し (パート 1 で行ったことと同様)、画像の参照を ML 推論関数に渡す、別の long-lived Lambda 関数を追加します。:

リソースのクリーンアップ
AWS で実行されているリソースには料金が発生することに注意してください。したがって、次の手順に従っている場合は、忘れずにリソースをクリーンアップしてください。:
greengo removeを実行して、AWS IoT Greengrass グループを削除します。- Amazon SageMaker ノートブックインスタンスをシャットダウンします。
- テスト用 EC2 インスタンスを使用して AWS IoT Greengrass を実行した場合は、AWS CloudFormation スタックを削除します。
- 使用された S3 バケットをクリーンアップします。
まとめ
この投稿シリーズでは、オブジェクト検出モデルのトレーニングとエッジへのデプロイのプロセスを最初から最後まで説明しました。トレーニングデータを収集することから始め、トレーニングデータを選択して高品質のラベルを作成する際のベストプラクティスを共有しました。次に、Amazon SageMaker の組み込みオブジェクト検出モデルを使用してカスタムモデルをトレーニングし、出力をデプロイ可能な形式に変換するためのヒントについて説明しました。最後に、エッジデバイスをセットアップし、AWS IoT Greengrass を使用して、エッジへのコードデプロイと予測出力をクラウドに送信する手順を説明しました。
物体検出モデルをエッジで実行して、製造、サプライチェーン、小売のプロセスを改善する可能性は非常に高いと考えています。この ML と IoT の強力な組み合わせで構築されたものを見るのを楽しみにしています。
この GitHub リポジトリで、取り上げたすべてのコードを見つけることができます。
この 3 部構成のシリーズの他の投稿:
このブログは、ソリューションアーキテクトの戸塚智哉が翻訳しました。