Amazon Web Services ブログ
Amazon Athena と AWS CloudTrail を使用したAWS Config Rules 利用料の見積もり
AWS Config は、AWSリソースがあるべき設定状態に準拠しているかを監査するサービスです。記録された設定項目の数と 1 か月あたりのリソースごとに行われる AWS Config Rules の評価件数に基づいて課金されます。
この記事では、Amazon Athena を使用して AWS CloudTrail ログをクエリし、AWS Config Rules 評価の詳細な請求内訳を確認する方法をご紹介します。請求の内訳を把握することで月額コストに最も寄与しているルールを特定することができれば、特定のルールの実行頻度を減らしてコストを抑えるといったコスト最適化施策を講じることができます。なお、この記事ではAWS Configの設定項目の確認については触れていません。詳細については、ブログ記事「Identifying resources with the most configuration changes using AWS Config」を参照してください。
ステップ 1: CloudTrail ログをクエリするために Athena テーブルを作成する
Athena テーブルを作成し、CloudTrail ログのS3上のパスとスキーマを設定します。CloudTrail コンソールで利用可能な自動生成されたステートメントを使用することで簡単に設定できます。左側のナビゲーションペインからイベント履歴を選択し、Athena テーブルを作成を選択します。

図 1: CloudTrail コンソールのイベント履歴ページ
Amazon Athena でテーブルを作成 ページで、CloudTrail ログを選択します。ストレージの場所 で、CloudTrail ログファイルが含まれている S3 バケットを選択します。S3バケットを選択すると、クエリ中の [TABLE_NAME], [S3_BUCKET_NAME], [S3_BUCKET_URL] が自動的に置き換わります。
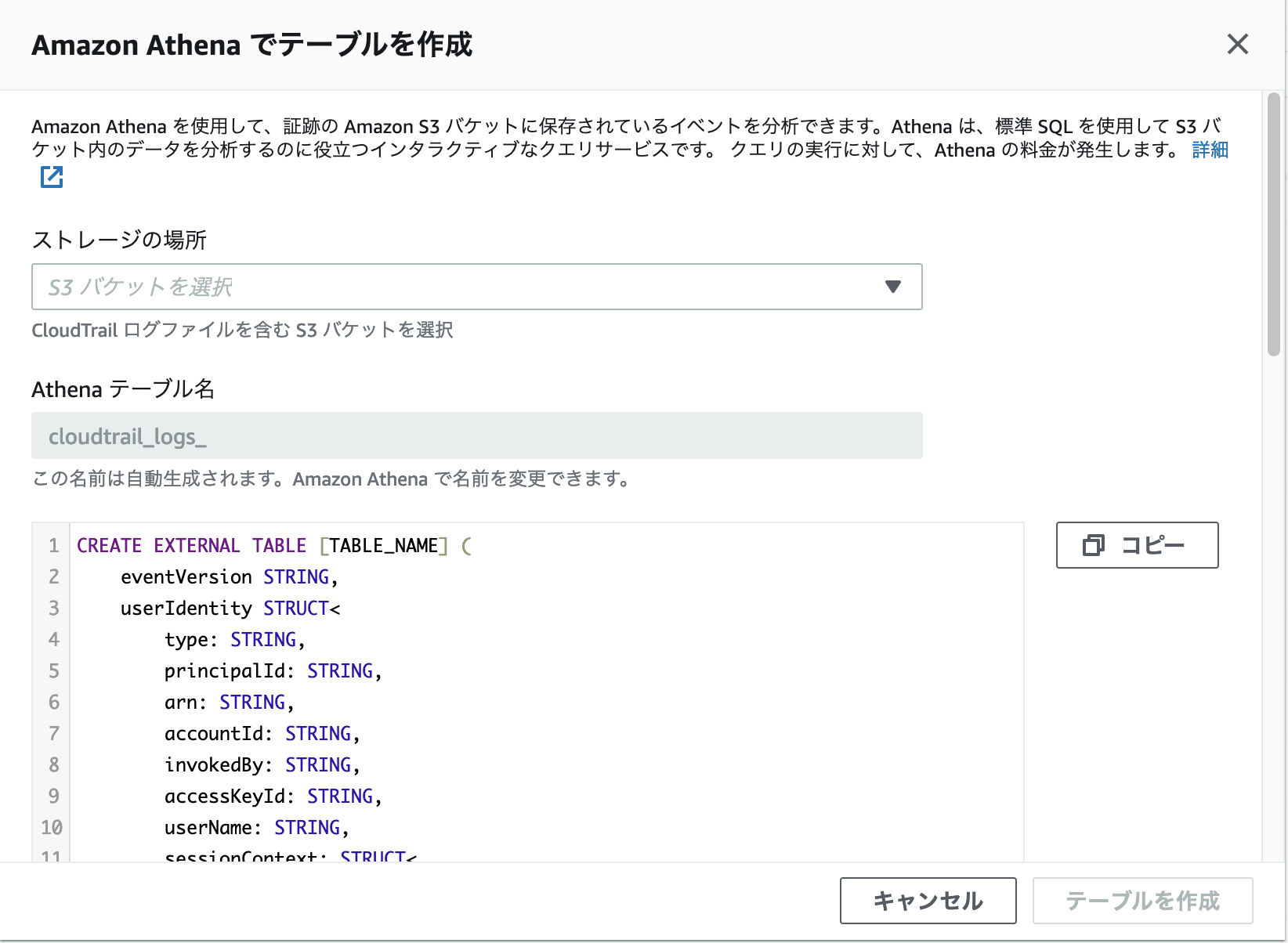
図 2: Amazon Athena でテーブルを作成する
[テーブルを作成]を選択してテーブルを作成します。クエリを編集する必要がある場合は、このステートメントをコピーして Athena コンソールで編集したクエリを実行してください。CREATE TABLE ステートメント中の [TABLE_NAME] (1行目) , [S3_BUCKET_NAME](46行目), [S3_BUCKET_URL] (50行目)が置き換えられ、次のようになります。
ステップ 2: 簡単なクエリを実行してみる
次のクエリを使用して、Athena テーブルが正しく作成されたことを確認します。[your_cloudtrail_table] (2行目) を、前のステップで設定された Athena テーブル名に置き換えます。上の例では、テーブル名は cloudtrail_management_logs となっています。
テーブルが正しく作成されていれば、10 行の結果が表示されるはずです。このクエリは後で実行するクエリのベースとなるものです。クエリを見てみると、config.amazonaws.com (AWS Config で発生したイベント) と PutEvaluations (リソースのコンプライアンス状態を記録しているイベント) の 2 つの属性値でフィルタリングされていることがわかります。
このクエリから取得された 2 つの列 requestparameters と additionaleventdata に注目してください。次の手順で、これらの JSON オブジェクトからデータを抽出します。これらのオブジェクトの詳細な説明については、PutEvaluations API と ConfigRule API のドキュメントをそれぞれ参照してください。
ステップ 3: ルール名ごとに AWS Config Rules 評価件数をクエリする
次のクエリを使用して、AWS Config Rules 評価件数を、ルール名でグループ化して、評価件数の多い順から少ない順にソートして取得します。[your_cloudtrail_table] (6行目) を Athena テーブルの名前に置き換えます。
正常に実行されると、次のような結果が表示されます。
クエリの中身を見てみましょう。
3 行目:JSONPath 式 ('$.configRuleName') で、additionaleventdataから configRuleNameを抽出するために json_extract 関数を使用しています。
4 行目:3 行目と同様に、json_extract でrequestparametersからevaluationsを抽出します。さらに、ARRAY<MAP>型にキャストします。
16行目: UNNEST演算子を使用して、4 行目で抽出されたevaluations配列を個々の要素に展開します。
18 行目:課金対象とならないNOT_APPLICABLEは除外します。
22 行目:各ルールの評価件数をカウントします。
クエリには LIMIT 句 (9行目) も含まれまています。デフォルトでは、Athena は指定された S3 バケット内のすべての CloudTrail ログファイルをクエリするためです。バケットの大きさによっては、このクエリの実行に時間がかかる場合があります。LIMIT 句を削除して、クエリ実行時間が許容できるかどうか試してみてください。(クエリの実行には 1 分以上かかる場合があります)。
試しに使う分にはS3 バケット内のすべてのファイルをスキャンするクエリを Athena で実行しても問題はありません。ただし、継続的に使用する場合は、データをパーティション分割するほうがパフォーマンスとコスト効率が高くなります。Amazon Athena を使用する場合、スキャンしたデータ量によって課金されます。詳細については、Amazon Athena の料金ページ を参照してください。
ステップ 4 ~ 6 では、パーティションの作成とパーティションへのクエリについて説明します。パーティショニングが不要であれば、ステップ 7 に進んでください。
ステップ 4: パーティションキーを使用して新しいテーブルを作成する
Athena テーブルのパーティショニングとは、各クエリでスキャンされるデータ量を制限する論理グループを作成することを意味します。一般的なベストプラクティスは、日付または時刻で分割することです。この記事のステップ 1 の CREATE TABLE ステートメントを見ると、LOCATION 句は次のようになっています。
図 3 を見てください。S3 バケットの中は AWS リージョン、年、月、日といった階層構造になっています。これらは物理的にパーティショニングされています。しかし、Athenaはこの物理パーティションを認識していないため、デフォルトではすべてのクエリがすべてのフォルダにアクセスします。

図 3: CloudTrail S3 バケットリージョンフォルダ
テーブルをパーティショニングするには、まず CREATE TABLEステートメントでパーティションキーを定義する必要があります。ステップ 1 と同じ CREATE TABLE ステートメントを使用しますが、以下の例 (47行目) に示すように PARTITIONED BY 句を追加します。パーティショニングされていないテーブルと区別するために、テーブル名に _partitioned サフィックスを追加しているのがわかります。 (1行目)
47行目: region, year, monthの3つのパーティションキーが指定されています。ユースケースに応じて、さらにパーティションキー (アカウント ID や日など) を追加することもできます。
注: PARTITIONED BY 句が (COMMENTの後に) 入力された場合、句の順序が正しくないと、構文エラーが発生する可能性があります。
パーティションキーを定義したら、Athena コンソールでこのステートメントを実行してパーティショニングされたテーブルを作成します。
ステップ 5: パーティションの場所を登録する
パーティショニングされた Athena テーブルを作成した後、ALTER TABLE ステートメントを使用して、各パーティションに対応する S3 バケットのパスを登録します。次のステートメントを実行します。
このステートメントでは、物理的な S3 ロケーションに ‘ap-northeast-1’、’2021’、’08’ を論理的に割り当てました。このステートメントをテンプレートとして使用すると、必要な数のパーティションを登録できます。
ステップ 6: パーティションを使用したクエリ
これで、手順 3 でクエリを変更し、WHERE 句を更新して、検索を特定のパーティションに制限できます。クエリは次の例のようになります。テーブル名 (6行目) とパーティション (9 〜 11行目) は適切な値に置き換えてください。
実行してみると、このクエリははるかに高速になり、かつスキャンされるデータが全体として少なくなることがわかります。
ステップ 7: コストの見積もり
クエリが AWS Config ルールごとのルール評価件数を正常に返せるようになれば、SELECT ステートメントに cost 列を追加することができます。
count(compliance_type)* 0.001 as cost
0.001(1評価あたり 0.001 ドル)は、現在の AWS Config の料金における「最初の 100,000 件のルール評価」の料金テーブルに基づいています。総評価件数によって、異なる料金体系が適用される可能性があります。この値は適用される料金体系に応じた値にする必要があります。SELECT ステートメント全体 (cost 列を含む) は次のようになります。
注: 1評価あたりの AWS Config の料金はその月の総評価件数により決定されるため、上記クエリにより算定されるのは推定コストとなります。また、カスタムルールはアカウントで AWS Lambda 関数として実行され、標準の Lambda 実行コストも適用されます。上記のクエリでは、これらの追加コストは考慮されません。
機能拡張と次のステップ
ここでは、実装すると便利な機能を3つ紹介します。
Amazon Quicksight を使用してクエリの結果を可視化する同じクエリを使用して、Amazon QuickSight ダッシュボードを作成して、このデータを時系列に可視化できます。 この例では、月ごとのルール評価件数の推移、過去 3 か月間の推定コスト、および前月の 1 日あたりの評価件数を可視化しました
|
図 4: QuickSight ダッシュボードのグラフ |

記録された設定項目を確認するクエリを作成する同じようにクエリを作成して、記録された設定項目の数と推定コストを確認することができます。設定項目は別の S3 バケットに格納されます。詳細については、ブログ記事 Identifying resources with the most configuration changes using AWS Config を参照してください。 この例では、前月に記録された設定項目の数をリソースタイプ別にグループ化して可視化しています。
|
図 5: QuickSight ダッシュボードの円グラフ |

パーティション作成を自動化する
この記事では、パーティションを手動で登録しました(ステップ 5)。カスタム Lambda 関数を作成し、毎月 ALTER TABLE ステートメントを実行するようにスケジュールすることで、パーティションの登録を自動化できます。
まとめ
このブログ記事では、Amazon Athena を使用して AWS CloudTrail ログをクエリし、AWS Config ルールごとの 評価件数を確認する方法を説明しました。この手順をぜひお試しください!Athena はデータを変換することなく、データに関するあらゆる種類のインサイトを収集するのに役立つ強力なツールとなります。
著者について
翻訳はソリューションアーキテクトの 小森谷が担当しました。原文はこちら。