Amazon Web Services 한국 블로그
Amazon DynamoDB 테이블 S3 내보내기 기능 출시 – 코드 없는 데이터 레이크 분석 제공
2012년 출시 이래 수십만의 AWS 고객이 미션 크리티컬 워크로드를 지원할 솔루션으로 Amazon DynamoDB를 선택했습니다. DynamoDB는 비관계형 관리형 데이터베이스로, 사실상 무한한 양의 데이터를 저장하며 규모에 관계없이 1밀리초 단위로 데이터를 검색할 수 있습니다.
이 데이터를 최대한 활용하려면 고객은 AWS Data Pipeline, Amazon EMR 또는 DynamoDB 스트림 기반의 기타 솔루션을 사용해야 했습니다. 이러한 솔루션은 일반적으로 읽기 처리량이 높은 맞춤형 애플리케이션을 구축해야 하므로 유지 관리 및 운영 비용이 많이 듭니다.
오늘 AWS는 코드를 작성하지 않고도 DynamoDB 테이블 데이터를 Amazon Simple Storage Service(S3)로 내보낼 수 있는 새로운 기능을 출시합니다.
이 기능은 DynamoDB의 새로운 네이티브 기능이므로 서버 또는 클러스터를 관리할 필요가 없고 규모에 관계없이 작동하며, 여러 AWS 리전 및 계정에 걸쳐 데이터를 초 단위로 지난 35일 동안 원하는 시점으로 내보낼 수 있습니다. 또한 프로덕션 테이블의 읽기 용량이나 가용성에는 영향을 주지 않습니다.
DynamoDB JSON 또는 Amazon Ion 형식으로 S3에 데이터를 내보내면 Amazon Athena, Amazon SageMaker, AWS Lake Formation 등 즐겨 사용하는 도구로 데이터를 쿼리하거나 재구성할 수 있습니다.
이 문서에서는 DynamoDB 테이블을 S3로 내보내고 표준 SQL을 사용하여 Amazon Athena를 통해 쿼리하는 방법을 설명합니다.
DynamoDB 테이블을 S3 버킷으로 내보내기
내보내기 프로세스는 DynamoDB의 기능을 사용하여 데이터를 지속적으로 백업합니다. 이 기능을 연속 백업이라고 합니다. 이 기능은 PITR(지정 시간 복구)을 지원하며 지난 35일 동안의 임의의 시점으로 테이블을 복원할 수 있습니다.
스트리밍 및 내보내기(Streams and exports) 탭에서 [S3로 내보내기(Export to S3)]를 클릭하여 시작할 수 있습니다.

연속 백업을 이미 활성화하지 않은 경우 다음 페이지에서 [PITR 활성화(Enable PITR)]를 클릭하여 활성화해야 합니다.
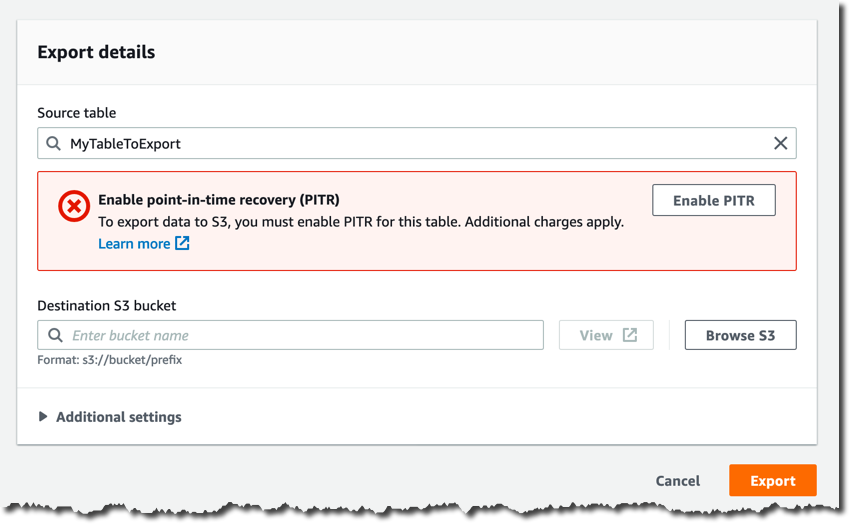
[대상 S3 버킷(Destination S3 bucket)]에 버킷 이름을 입력합니다(예: s3://my-dynamodb-export-bucket). 버킷이 다른 계정이나 다른 리전에도 있을 수 있습니다.
원하는 경우 [추가 설정(Additional settings)]에서 특정 시점, 출력 형식 및 암호화 키를 구성할 수 있습니다. 여기서는 기본 설정을 사용하겠습니다.

이제 [내보내기(Export)]를 클릭하여 내보내기 요청 의사를 확인할 수 있습니다.
내보내기 프로세스가 시작되며, [스트리밍 및 내보내기(Streams and exports)] 탭에서 해당 상태를 모니터링할 수 있습니다.

내보내기 프로세스가 완료되면 S3 버킷에 새 [AWSDynamoDB] 폴더와 내보내기 ID에 해당하는 하위 폴더가 표시됩니다.
해당 하위 폴더의 콘텐츠는 다음과 같습니다.

무결성을 확인하고 [데이터(data)] 하위 폴더에서 S3 객체의 위치를 검색할 수 있는 2개의 매니페스트 파일이 있습니다. 이 파일은 자동으로 압축되고 암호화됩니다.
AWS CLI를 통해 내보내기 프로세스를 자동화하는 방법
매주 또는 매월 새 내보내기를 생성하는 등의 경우에 내보내기 프로세스를 자동화하려면 ExportTableToPointInTime API를 호출하여 AWS 명령줄 인터페이스(CLI) 또는 AWS SDK를 통해 새 내보내기 요청을 생성하면 됩니다.
다음은 CLI를 사용한 예제입니다.
aws dynamodb export-table-to-point-in-time \
--table-arn TABLE_ARN \
--s3-bucket BUCKET_NAME \
--export-time 1596232100 \
--s3-prefix demo_prefix \
-export-format DYNAMODB_JSON
{
"ExportDescription": {
"ExportArn": "arn:aws:dynamodb:REGUIB:ACCOUNT_ID:table/TABLE_NAME/export/EXPORT_ID",
"ExportStatus": "IN_PROGRESS",
"StartTime": 1596232631.799,
"TableArn": "arn:aws:dynamodb:REGUIB:ACCOUNT_ID:table/TABLE_NAME",
"ExportTime": 1596232100.0,
"S3Bucket": "BUCKET_NAME",
"S3Prefix": "demo_prefix",
"ExportFormat": "DYNAMODB_JSON"
}
}내보내기를 요청한 후 ExportStatus가 “COMPLETED”로 바뀔 때까지 기다려야합니다.
aws dynamodb list-exports
{
"ExportSummaries": [
{
"ExportArn": "arn:aws:dynamodb:REGION:ACCOUNT_ID:table/TABLE_NAME/export/EXPORT_ID",
"ExportStatus": "COMPLETED"
}
]
}Amazon Athena를 사용하여 내보낸 데이터 분석
데이터가 S3 버킷에 안전하게 저장되면 Amazon Athena를 사용하여 분석을 시작할 수 있습니다.
S3 버킷에는 여러 개의 gz 압축 객체가 있으며 각 객체에는 한 줄에 하나씩 여러 개의 JSON 객체가 포함된 텍스트 파일이 들어 있습니다. 이러한 JSON 객체는 Item 필드로 래핑된 DynamoDB 항목에 해당하며, 선택한 내보내기 형식에 따라 구조가 다릅니다.
위의 내보내기 프로세스에서는 DynamoDB JSON을 선택했으며 샘플 테이블의 항목은 간단한 게임의 사용자를 나타내므로 일반적인 객체는 다음과 같습니다.
{
"Item": {
"id": {
"S": "my-unique-id"
},
"name": {
"S": "Alex"
},
"coins": {
"N": "100"
}
}
}이 예에서 name은 문자열이고 coins는 숫자입니다.
AWS Glue 크롤러를 사용하여 데이터의 스키마를 자동 검색하고 AWS Glua 카탈로그에 가상 테이블을 생성하는 것이 좋습니다.
그러나 CREATE EXTERNAL TABLE 문을 사용하여 가상 테이블을 수동으로 정의할 수도 있습니다.
CREATE EXTERNAL TABLE IF NOT EXISTS ddb_exported_table (
Item struct <id:struct<S:string>,
name:struct<S:string>,
coins:struct<N:string>
)
ROW FORMAT SERDE 'org.openx.data.jsonserde.JsonSerDe'
LOCATION 's3://my-dynamodb-export-bucket/AWSDynamoDB/{EXPORT_ID}/data/'
TBLPROPERTIES ( 'has_encrypted_data'='true');이제 일반 SQL로 쿼리하거나 Create Table as Select(CTAS) 쿼리를 사용하여 새 가상 테이블을 정의할 수도 있습니다.
DynamoDB JSON 형식을 사용하면 쿼리가 다음과 같이 표시됩니다.
SELECT
Item.id.S as id,
Item.name.S as name,
Item.coins.N as coins
FROM ddb_exported_table
ORDER BY cast(coins as integer) DESC;그리고 결과 집합을 출력으로 얻을 수 있습니다.

성능 및 비용 고려 사항
내보내기 프로세스는 서버리스 방식이며, 자동으로 확장되고 맞춤형 테이블 스캔 솔루션보다 훨씬 빠릅니다.
완료 시간은 테이블의 크기와 테이블에 데이터가 얼마나 균일하게 분산되어 있는지에 따라 다릅니다. 내보내기는 대부분 30분 이내에 완료됩니다. 최대 10GiB의 작은 테이블의 경우 몇 분 밖에 걸리지 않습니다. 테라바이트 단위의 매우 큰 테이블의 경우 몇 시간이 걸릴 수 있습니다. 데이터 레이크 내보내기를 실시간 분석에 사용할 일은 없기 때문에 이는 문제가 되지 않습니다. 일반적으로 데이터 레이크는 대규모로 데이터를 집계하고 일별, 주별 또는 월별 보고서를 생성하는 데 사용됩니다. 따라서 대부분의 경우 분석 파이프라인을 진행하기 전에 내보내기 프로세스가 완료될 때까지 몇 분 또는 몇 시간 정도 기다릴 수 있습니다.
이 새로운 기능의 서버리스 특성 덕분에 시간당 요금은 발생하지 않습니다. Amazon S3로 내보낸 데이터의 용량(기가바이트 기준)에 대해서만 요금을 지불하면 됩니다. 예를 들어 미국 동부 리전에서는 GiB당 0.10 USD입니다.
데이터가 자체 S3 버킷으로 내보내지고 연속 백업이 내보내기 프로세스의 필수 조건이므로 DynamoDB PITR 백업 및 S3 데이터 스토리지와 관련한 추가 요금이 발생한다는 점을 유의하십시오. 관련된 모든 비용 구성 요소는 내보내는 데이터의 양에 따라 달라집니다. 따라서 전체 비용을 쉽게 예측할 수 있으며, 읽기 처리량이 높고 유지 관리 비용이 많이 드는 맞춤형 솔루션을 구축하는 데 소요되는 총 소유 비용보다 훨씬 저렴합니다.
정식 출시
이 새로운 기능은 현재 연속 백업을 사용할 수 있는 모든 AWS 리전에서 제공됩니다.
AWS Management Console, AWS 명령줄 인터페이스(CLI) 및 AWS SDK를 사용하여 내보내기를 요청할 수 있습니다. 이 기능을 사용하면 개발자, 데이터 엔지니어 및 데이터 사이언티스트가 비용이 많이 드는 맞춤형 ETL(추출, 변환, 로드) 애플리케이션을 설계하고 구축하지 않고도 DynamoDB 테이블에서 데이터를 손쉽게 추출 및 분석할 수 있습니다.
이제 자체 분석 도구를 DynamoDB 데이터에 연결하여 임시 분석을 위한 Amazon Athena, 데이터 탐색 및 시각화를 위한 Amazon QuickSight, 예측 분석을 위한 Amazon Redshift 및 Amazon SageMaker 등 다양한 서비스를 활용할 수 있습니다.
— Alex