- AWS Solutions Library›
- Guidance for Deploying High Performance Computing Clusters on AWS
Guidance for Deploying High Performance Computing Clusters on AWS
Conforming high performance computing (HPC) workloads with NIST SP 800-223
Overview
This Guidance demonstrates how to use infrastructure as code (IaC) templates to deploy secure and compliant high performance computing (HPC) workloads. The IaC templates automatically provision resources for a fully functional HPC environment that aligns with the security requirements of the National Institute of Standards and Technology (NIST) Special Publication (SP) 800-223. By offering a comprehensive suite of AWS services tailored for HPC, including high-performance processors, low-latency networking, and scalable storage options, this Guidance allows users to efficiently build and manage secure, compliant, and high performing compute environments.
How it works
Network, security and infrastructure deployment
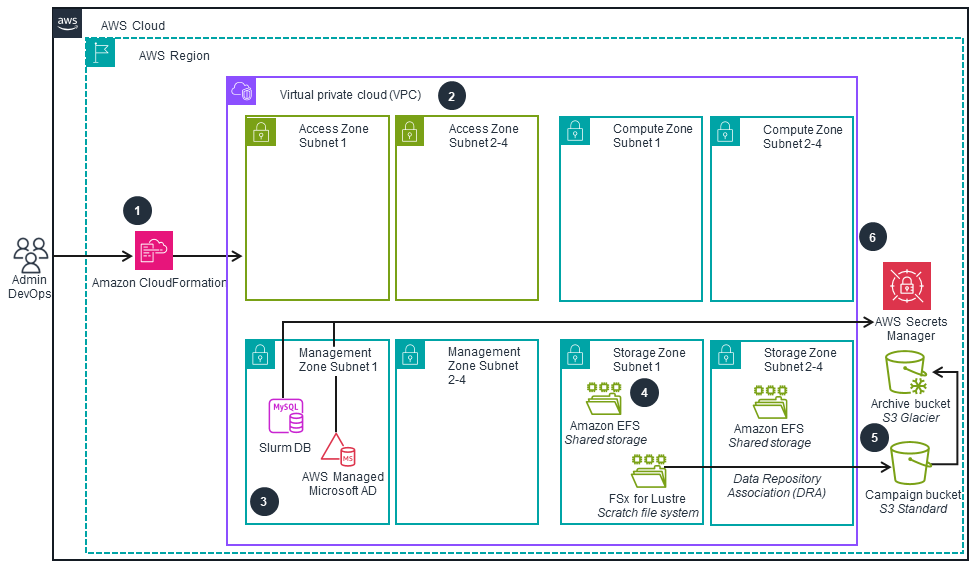
This architecture diagram shows how to deploy this Guidance using AWS CloudFormation templates that provision networking resources, security, and storage components. The next tab shows how HPC resources are deployed using the AWS ParallelCluster CloudFormation stack.
HPC cluster deployment
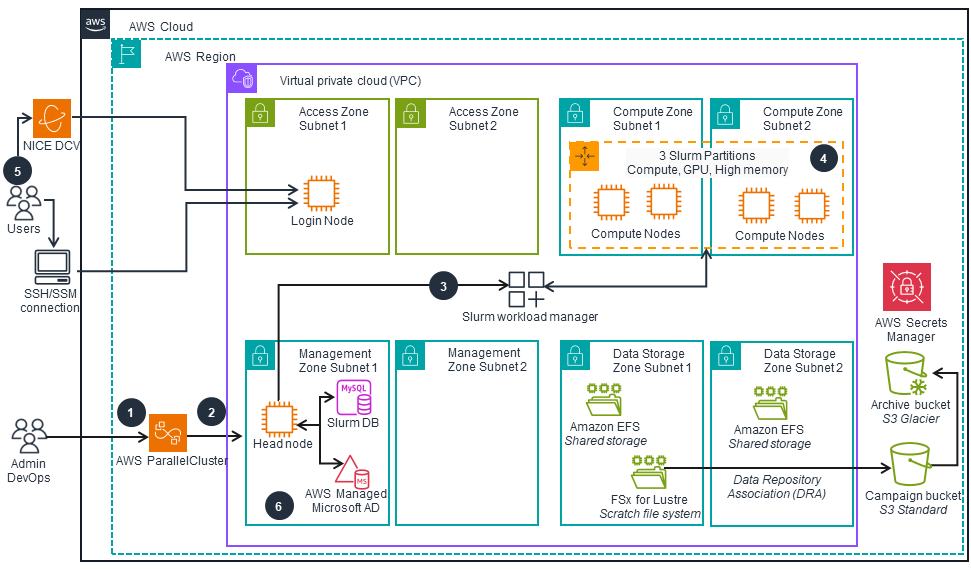
This architecture diagram shows how HPC resources are deployed using the AWS ParallelCluster CloudFormation stack. It references the network, storage, security, database, and user directory components from the previous tab.
Deploy with confidence
Ready to deploy? Review the sample code on GitHub for detailed deployment instructions to deploy as-is or customize to fit your needs.
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
CloudFormation and AWS ParallelCluster support IaC practices for consistent, repeatable HPC deployments. Amazon CloudWatch provides monitoring and observability to assess cluster performance and health. Collectively, these services automate HPC deployments, supporting compliance and security and facilitating secure infrastructure management. This approach aligns with NIST SP 800-223 recommendations so you can implement best practices when managing complex HPC workloads on AWS.
Amazon VPC enables network isolation and segmentation of HPC environments into distinct security zones (access, management, compute, and storage), aligning with NIST SP 800-223 recommendations. In addition, AWS services such as AWS Identity and Access Management (IAM), AWS Key Management Service (AWS KMS), and AWS CloudTrail directly address key security requirements. Specifically, IAM provides fine-grained access control implementing least privilege, AWS KMS offers data encryption at rest and in transit, and CloudTrail offers comprehensive API auditing. This multi-layered approach enables a zone-based security architecture with proper access controls, data protection, and comprehensive monitoring.
AWS ParallelCluster provides a framework for deploying and operating HPC clusters for consistent setup. Amazon EFS and FSx for Lustre offer optimized file systems for HPC workloads, while Amazon S3 stores campaign data and archives. Amazon Relational Database Service (Amazon RDS) manages the Slurm accounting database with automated backups, and AWS Auto Scaling adjusts capacity to maintain performance cost-effectively. These services address reliability concerns outlined in NIST SP 800-223 by providing robust data storage, supporting critical component availability, and enabling automatic scaling.
Amazon EC2 offers instance types optimized for various HPC workloads, including GPU-enabled instances for accelerated computing. FSx for Lustre provides a high performance file system designed for HPC, while AWS ParallelCluster automates HPC environment creation for efficient deployment and scaling. These services deliver the computational power, storage performance, and job scheduling capabilities essential for HPC workloads, allowing users to achieve optimal performance without managing complex infrastructure.
AWS ParallelCluster optimizes costs in HPC environments by automatically scaling compute resources based on workload demand and also by supporting Amazon EC2 Spot Instances for interruptible tasks. This dynamic adjustment can reduce costs by up to 90% compared to Amazon EC2 On-Demand Instances. Additionally, Amazon S3 Intelligent-Tiering automatically moves data to the most cost-effective access tier, optimizing storage costs for large HPC datasets. These services address the significant computational resource requirements of HPC systems by efficiently managing capacity and storage.
Amazon EC2 Auto Scaling and AWS ParallelCluster support sustainability in HPC environments by dynamically adjusting compute resources to match workload demands, minimizing idle resources. AWS Batch optimizes resource allocation for batch workloads, while Amazon S3 Intelligent-Tiering automatically moves data to appropriate storage tiers, reducing energy consumption for infrequently accessed data. Although NIST SP 800-223 does not explicitly focus on sustainability, these services align with its emphasis on efficient resource utilization. By using energy-efficient processors, matching resources to demand, and automating data management, these services minimize waste from overprovisioning—a common issue in traditional HPC environments. This approach not only reduces the environmental impact of HPC operations but also often leads to cost savings, demonstrating that sustainability and cost optimization can be complementary goals in cloud-based HPC.
Disclaimer
The sample code; software libraries; command line tools; proofs of concept; templates; or other related technology (including any of the foregoing that are provided by our personnel) is provided to you as AWS Content under the AWS Customer Agreement, or the relevant written agreement between you and AWS (whichever applies). You should not use this AWS Content in your production accounts, or on production or other critical data. You are responsible for testing, securing, and optimizing the AWS Content, such as sample code, as appropriate for production grade use based on your specific quality control practices and standards. Deploying AWS Content may incur AWS charges for creating or using AWS chargeable resources, such as running Amazon EC2 instances or using Amazon S3 storage.
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages