Điểm khác biệt giữa máy học và học sâu là gì?
Điểm khác biệt giữa máy học và học sâu là gì?
Máy học (ML) là môn khoa học đào tạo một hệ thống hoặc chương trình máy tính để thực hiện các tác vụ mà không cần hướng dẫn cụ thể. Các hệ thống máy tính sử dụng thuật toán ML để xử lý khối lượng lớn dữ liệu, xác định các khuôn mẫu dữ liệu và dự đoán kết quả chính xác cho các tình huống mới hoặc không xác định. Học sâu là một tập con của ML sử dụng các cấu trúc thuật toán cụ thể, gọi là mạng nơ-ron, được lập mô hình theo bộ não con người. Các phương pháp học sâu cố gắng tự động hóa các tác vụ phức tạp hơn và thường đòi hỏi trí tuệ của con người. Ví dụ như, bạn có thể sử dụng học sâu để mô tả hình ảnh, dịch tài liệu hoặc chép lại tệp âm thanh thành văn bản.
Điểm tương đồng giữa máy học và học sâu là gì?
Bạn có thể sử dụng cả máy học (ML) và học sâu để xác định các mẫu hình trong dữ liệu. Cả hai đều dựa vào tập dữ liệu để đào tạo các thuật toán dựa trên các mô hình toán học phức tạp. Trong quá trình đào tạo, các thuật toán phát hiện ra mối tương quan giữa đầu ra và đầu vào đã xác định. Sau đó các mô hình có thể tự động tạo ra hoặc dự đoán đầu ra dựa trên đầu vào không xác định. Không giống như lập trình truyền thống, quá trình học cũng tự động với sự can thiệp của con người ở mức tối thiểu.
Dưới đây là những điểm tương đồng khác giữa ML và học sâu.
Kỹ thuật trí tuệ nhân tạo
Cả ML và học sâu đều là tập con của khoa học dữ liệu và trí tuệ nhân tạo (AI). Cả hai đều có thể hoàn thành các tác vụ tính toán phức tạp mà đòi hỏi nhiều thời gian và nguồn lực để đạt được kết quả thông qua các kỹ thuật lập trình truyền thống.
Cơ sở thống kê
Cả học sâu và ML đều sử dụng các phương pháp thống kê để đào tạo các thuật toán của chúng bằng các tập dữ liệu. Những kỹ thuật này bao gồm phân tích hồi quy, cây quyết định, đại số tuyến tính và giải tích. Các chuyên gia ML và chuyên gia học sâu đều hiểu rõ số liệu thống kê.
Tập dữ liệu lớn
Cả ML và học sâu đều yêu cầu các tập dữ liệu đào tạo chất lượng lớn để đưa ra dự đoán chính xác hơn. Ví dụ, mô hình ML yêu cầu khoảng 50–100 điểm dữ liệu cho mỗi tính năng, trong khi mô hình học sâu bắt đầu từ hàng nghìn điểm dữ liệu cho mỗi tính năng.
Các ứng dụng đa dạng và khác nhau
Các giải pháp học sâu và ML giải quyết các vấn đề phức tạp trên tất cả các ngành công nghiệp và ứng dụng. Sẽ mất nhiều thời gian hơn đáng kể để tối ưu hóa hoặc giải quyết các loại vấn đề này nếu bạn sử dụng các phương pháp lập trình truyền thống và thống kê.
Yêu cầu về năng lực tính toán
Để đào tạo và chạy các thuật toán ML đòi hỏi năng lực tính toán đáng kể và các yêu cầu tính toán thậm chí còn cao hơn đối với học sâu do mức độ phức tạp của nó tăng lên. Tình trạng khả dụng của cả hai loại giải pháp phục vụ mục đích sử dụng cá nhân bây giờ có thể nhờ những tiến bộ gần đây về nâng cao năng lực tính toán và nguồn lực đám mây.
Cải thiện dần
Khi các giải pháp ML và học sâu tiếp nhận nhiều dữ liệu hơn, chúng trở nên chính xác hơn khi nhận dạng mẫu hình. Khi dữ liệu nhập liệu được thêm vào hệ thống, hệ thống sẽ cải thiện bằng cách sử dụng làm điểm dữ liệu để đào tạo.
Những hạn chế nào của máy học dẫn đến sự phát triển của học sâu?
Máy học truyền thống (ML) đòi hỏi sự tương tác đáng kể của con người thông qua thiết kế tính năng để tạo ra kết quả. Ví dụ, nếu bạn đang đào tạo một mô hình ML để phân loại hình ảnh của mèo và chó, bạn phải định cấu hình nó theo cách thủ công để nhận ra các tính năng như hình dạng mắt, hình dạng đuôi, hình dạng tai, đường viền mũi, v.v.
Vì mục tiêu của ML là giảm mức độ can thiệp của con người nên các kỹ thuật học sâu loại bỏ nhu cầu cần con người dán nhãn dữ liệu ở từng bước.
Mặc dù kỹ thuật học sâu đã tồn tại nhiều thập kỷ qua nhưng phải đến đầu thập niên 2000, các nhà khoa học như Yann LeCun, Yoshua Bengio và Geoffrey Hinton mới khám phá lĩnh vực này chi tiết hơn. Mặc dù các nhà khoa học đã nâng cao kỹ thuật học sâu nhưng các tập dữ liệu lớn và phức tạp bị hạn chế trong giai đoạn này và khả năng xử lý cần thiết để đào tạo các mô hình rất tốn kém. Trong 20 năm qua, những điều kiện này đã được cải thiện và kỹ thuật học sâu hiện nay khả thi về mặt thương mại.
Những điểm khác biệt chính giữa máy học và học sâu
Học sâu là một lĩnh vực “con” của máy học (ML). Bạn có thể nghĩ về nó như một kỹ thuật ML tiên tiến. Mỗi loại đều có nhiều ứng dụng khác nhau. Tuy nhiên, các giải pháp học sâu đòi hỏi nhiều tài nguyên hơn—tập dữ liệu lớn hơn, yêu cầu cơ sở hạ tầng và chi phí sau này.
Dưới đây là những điểm khác biệt khác giữa ML và học sâu.
Các trường hợp sử dụng dự định
Quyết định sử dụng ML hoặc học sâu phụ thuộc vào loại dữ liệu mà bạn cần xử lý. ML xác định các mẫu từ dữ liệu có cấu trúc, chẳng hạn như hệ thống phân loại và đề xuất. Ví dụ, một công ty có thể sử dụng ML để dự đoán khi nào khách hàng sẽ hủy đăng ký dựa trên dữ liệu của khách hàng trước đó.
Mặt khác, các giải pháp học sâu phù hợp hơn đối với dữ liệu không có cấu trúc, trong đó cần có mức độ trừu tượng cao để trích xuất các tính năng. Các tác vụ cho học sâu bao gồm phân loại hình ảnh và xử lý ngôn ngữ tự nhiên, trong đó cần xác định các mối quan hệ phức tạp giữa các đối tượng dữ liệu. Ví dụ, giải pháp học sâu có thể phân tích các nội dung được đề cập trên mạng xã hội để xác định cảm xúc của người dùng.
Cách tiếp cận giải quyết sự cố
ML truyền thống thường đòi hỏi thiết kế tính năng, trong đó con người tự chọn và trích xuất các tính năng từ dữ liệu thô và gán trọng số cho chúng. Ngược lại, các giải pháp học sâu thực hiện thiết kế tính năng với sự can thiệp tối thiểu của con người.
Kiến trúc mạng nơ-ron của học sâu phức tạp hơn theo thiết kế. Cách thức mà các giải pháp học sâu học được mô phỏng theo cách thức hoạt động của não người, với các tế bào nơ-ron được biểu diễn bởi các nút. Mạng nơ-ron học sâu bao gồm ba hoặc nhiều lớp nút, bao gồm các nút lớp đầu vào và đầu ra.

Trong học sâu, mỗi nút trong mạng nơ-ron tự động gán trọng số cho mỗi tính năng. Thông tin truyền qua mạng theo hướng chuyển tiếp từ đầu vào đến đầu ra. Sự khác biệt giữa đầu ra dự đoán và đầu ra thực tế sau đó được tính toán. Và lỗi này được truyền ngược qua mạng để điều chỉnh trọng số của các nơ-ron.
Vì quá trình gán trọng số tự động, độ sâu của các cấp độ kiến trúc và các kỹ thuật được sử dụng, một mô hình được yêu cầu để giải quyết nhiều hoạt động hơn trong học sâu so với trong ML.
Phương pháp đào tạo
ML có bốn phương pháp đào tạo chính: học có giám sát, học không có giám sát, học bán giám sát và học tăng cường. Các phương pháp đào tạo khác bao gồm học chuyển đổi và học tự giám sát.
Ngược lại, các thuật toán học sâu sử dụng một số loại phương pháp đào tạo phức tạp hơn. Chúng bao gồm các mạng nơ-ron phức tạp, mạng nơ-ron hồi quy, mạng đối nghịch sinh và bộ mã hóa tự động.
Đọc về Generative Adversarial Networks (GAN)”
Hiệu năng
Cả ML và học sâu đều có các trường hợp sử dụng cụ thể mà chúng phát huy khả năng tốt hơn so với các trường hợp khác.
Đối với các tác vụ đơn giản hơn như xác định thư rác đến mới, ML phù hợp và thường sẽ vượt trội hơn các giải pháp học sâu. Đối với các tác vụ phức tạp hơn như nhận dạng hình ảnh chẩn đoán y tế, các giải pháp học sâu phát huy hiệu quả hơn so với các giải pháp ML vì chúng có thể xác định những bất thường không nhìn thấy được bằng mắt người.
Sự tham gia của con người
Cả hai giải pháp ML và học sâu đều cần con người tham gia đáng kể vào quá trình thao tác. Một người phải tìm ra vấn đề, chuẩn bị dữ liệu, chọn và đào tạo mô hình, sau đó đánh giá, tối ưu hóa và triển khai giải pháp.
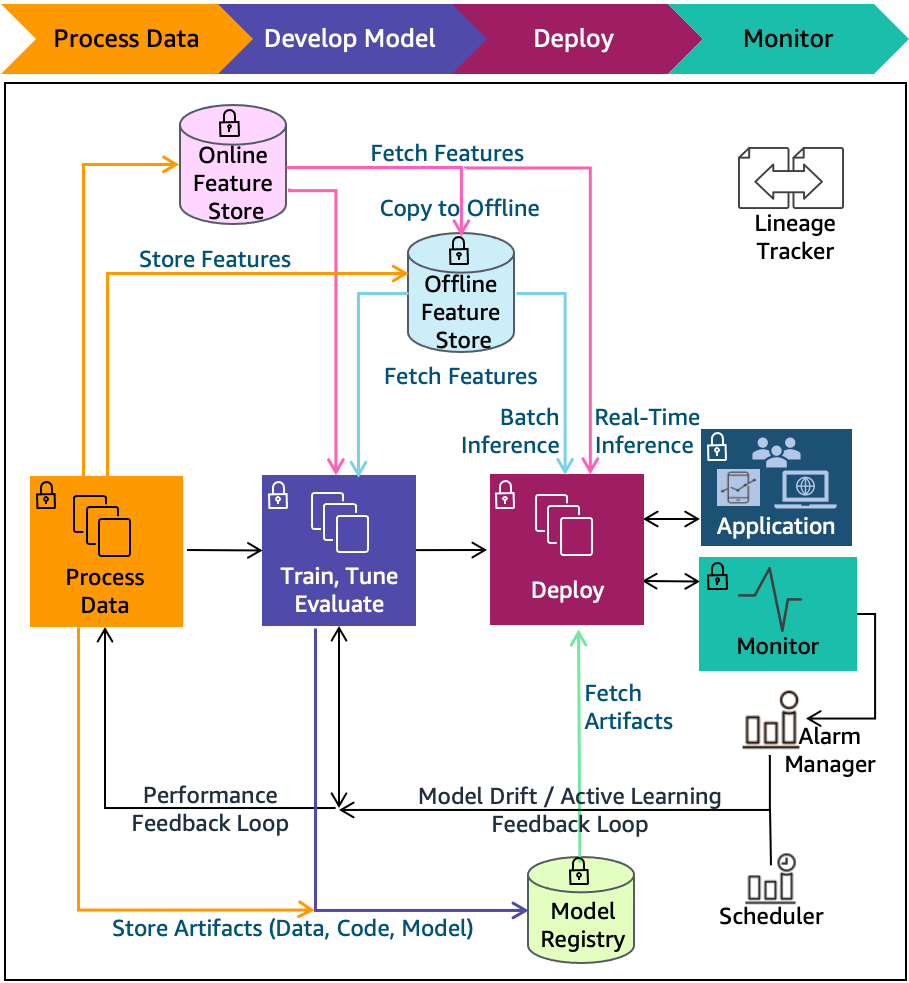
Mô hình ML có thể dễ dàng hơn để mọi người có thể diễn giải, vì chúng bắt nguồn từ các mô hình toán học đơn giản hơn, chẳng hạn như cây quyết định.
Ngược lại, các mô hình học sâu mất một khoảng thời gian đáng kể để có người phân tích chi tiết, vì các mô hình phức tạp về mặt toán học. Điều đó có nghĩa là cách học của các mạng nơ-ron sẽ không cần có người gắn nhãn dữ liệu. Bạn có thể giảm thêm mức độ tham gia của con người bằng cách chọn các mô hình và nền tảng được đào tạo trước.
Yêu cầu về cơ sở hạ tầng
Vì có độ phức tạp cao hơn và yêu cầu các tập dữ liệu lớn hơn nên các mô hình học sâu đòi hỏi lưu trữ nhiều hơn và khả năng tính toán cao hơn so với các mô hình ML. Mặc dù dữ liệu ML và mô hình có thể chạy trên một phiên bản đơn hoặc cụm máy chủ nhưng mô hình học sâu thường đòi hỏi các cụm hiệu suất cao và cơ sở hạ tầng đáng kể khác.
Các yêu cầu về cơ sở hạ tầng cho các giải pháp học sâu có thể dẫn đến chi phí cao hơn đáng kể so với ML. Cơ sở hạ tầng tại chỗ có thể không thực tế hoặc không tiết kiệm chi phí khi chạy các giải pháp học sâu. Bạn có thể sử dụng cơ sở hạ tầng mở rộng và các dịch vụ học sâu được quản trị đầy đủ để kiểm soát chi phí.
Tóm tắt điểm khác nhau: Máy học so với Học sâu
|
Máy học |
Học sâu |
|
|
Đó là gì? |
ML là một phương pháp trí tuệ nhân tạo (AI). Không phải tất cả ML đều là học sâu. |
Học sâu là phương pháp ML tiên tiến. Tất cả học sâu là ML. |
|
Trường hợp sử dụng phù hợp nhất |
ML là tùy chọn tốt nhất cho các tác vụ được xác định rõ ràng với dữ liệu có cấu trúc và được dán nhãn. |
Học sâu là tùy chọn tốt nhất để thực hiện các tác vụ phức tạp đòi hỏi máy móc phải hiểu được dữ liệu không có cấu trúc. |
|
Cách tiếp cận giải quyết sự cố |
ML giải quyết các sự cố thông qua thống kê và toán học. |
Học sâu kết hợp thống kê và toán học với kiến trúc mạng nơ-ron. |
|
Đào tạo |
Bạn phải tự chọn và trích xuất các đối tượng từ dữ liệu thô và gán trọng số để huấn luyện một mô hình ML. |
Các mô hình học sâu có thể tự học bằng cách sử dụng phản hồi từ các lỗi đã xác định. |
|
Tài nguyên cần thiết |
ML ít phức tạp hơn và có khối lượng dữ liệu thấp hơn. |
Học sâu phức tạp hơn với khối lượng dữ liệu rất cao. |
AWS có thể hỗ trợ các yêu cầu về máy học và học sâu như thế nào?
Có nhiều giải pháp học máy (ML) và học sâu (DL) trên Amazon Web Services (AWS). Các giải pháp này cho phép bạn tích hợp trí tuệ nhân tạo (AI) trong tất cả các ứng dụng của bạn và trường hợp sử dụng.
Đối với ML truyền thống, Amazon SageMaker là một nền tảng hoàn chỉnh để xây dựng, đào tạo và triển khai các thuật toán trên cơ sở hạ tầng đám mây mạnh mẽ, có thể mở rộng.
Đối với yêu cầu học sâu của bạn, bạn có thể sử dụng các dịch vụ được quản trị hoàn toàn như:
- Amazon Comprede h giúp bạn khám phá những hiểu biết có giá trị từ bất kỳ văn bản nào bằng cách sử dụng xử lý ngôn ngữ tự nhiên hoặc Amazon Compredeh Medical cho các văn bản y học phức tạp hơn.
- Amazon Fraud Detector giúp bạn phát hiện các hoạt động gian lận dựa trên hồ sơ lịch sử.
- Amazon Lex giúp bạn xây dựng chatbot thông minh và giao diện đàm thoại.
- Amazon Personalize giúp bạn nhanh chóng phân khúc khách hàng và xây dựng các hệ thống đề xuất được sắp xếp.
- Amazon Polly giúp bạn tạo ra các từ nói có âm thanh tự nhiên từ văn bản đầu vào bằng hàng chục ngôn ngữ.
- Amazon Rekognition giúp bạn nhận dạng hình ảnh được xây dựng sẵn và phân tích video.
- Amazon Textract giúp bạn trích xuất văn bản từ bất kỳ tài liệu viết tay hoặc do máy tính tạo.
Bắt đầu với machine learning và deep learning bằng cách tạo tài khoản AWS miễn phí ngay hôm nay.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages