AWS Compute Blog
Introducing global endpoints for Amazon EventBridge
This post is written by Stephen Liedig, Principal Serverless Specialist SA.
Last year, AWS announced two new features for Amazon EventBridge that allow you to route events from any commercial AWS Region, and across your AWS accounts. This supported a wide range of use cases, allowing you to implement easily global event delivery and replication scenarios.
From today, EventBridge extends this capability with global endpoints. Global endpoints provide a simpler and more reliable way for you to improve the availability and reliability of event-driven applications. The feature allows you to fail over event ingestion automatically to a secondary Region during service disruptions. Global endpoints also provide optional managed event replication, simplifying your event bus configuration and reducing the risk of event loss during any service disruption.
This blog post explains how to configure global endpoints in your AWS account, update your applications to publish events to the endpoint, and how to test endpoint failover.
How global endpoints work
Customers building multi-Region architectures today are building more resilience by using self-managed replication via EventBridge’s cross-Region capabilities. With this architecture, events are sent directly to an event bus in a primary Region and replicated to another event bus in a secondary Region.
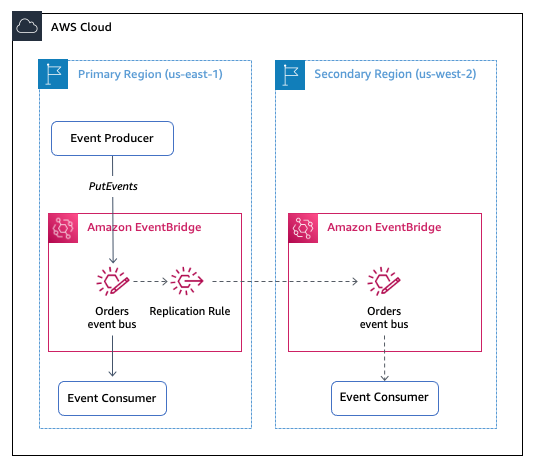
This event flow can be interrupted if there is a service disruption. In this scenario, event producers in the primary Region cannot PutEvents to their event bus, and event replication to the secondary Region is impacted.
To put more resiliency around multi-Region architectures, you can now use global endpoints. Global endpoints solve these issues by introducing two core service capabilities:
- A global endpoint is a managed Amazon Route 53 DNS endpoint. It routes events to the event buses in either Region, depending on the health of the service in the primary Region.
- There is a new EventBridge metric called
IngestionToInvocationStartLatency. This exposes the time to process events from the point at which they are ingested by EventBridge to the point the first invocation of a target in your rules is made. This is a service-level metric measured across all of your rules and provides an indication of the health of the EventBridge service. Any extended periods of high latency over 30 seconds may indicate a service disruption.
These two features provide you with the ability to failover event ingestion automatically to the event bus in the secondary Region. The failover is triggered via a Route 53 health check that monitors a CloudWatch alarm that observes the IngestionToInvocationStartLatency in the primary Region.
If the metric exceeds the configured threshold of 30 seconds consecutively for 5 minutes, the alarm state changes to “ALARM”. This causes the Route 53 health check state to become unhealthy, and updates the routing of the global endpoint. All events from that point on are delivered to the event bus in the secondary Region.
The diagram below illustrates how global endpoints reroutes events being delivered from the event bus in the primary Region to the event bus in the secondary Region when CloudWatch alarms trigger the failover of the Route 53 health check.

Once events are routed to the secondary Region, you have a couple of options:
- Continue processing events by deploying the same solution that processes events in the primary Region to the secondary Region.
- Create an EventBridge archive to persist all events coming through the secondary event bus. EventBridge archives provide you with a type of “Active/Archive” architecture allowing you to replay events to the event bus once the primary Region is healthy again.
When the global endpoint alarm returns to a healthy state, the health check updates the endpoint configuration, and begins routing events back to the primary Region.
Global endpoints can be optionally configured to replicate events across Regions. When enabled, managed rules are created on your primary and secondary event buses that define the event bus in the other Region as the rule target.
Under normal operating conditions, events being sent to the primary event bus are also sent to the secondary in near-real-time to keep both Regions synchronized. When a failover occurs, consumers in the secondary Region have an up-to-date state of processed events, or the ability to replay messages delivered to the secondary Region, before the failover happens.
When the secondary Region is active, the replication rule attempts to send events back to the event bus in the primary Region. If the event bus in the primary Region is not available, EventBridge attempts to redeliver the events for up to 24 hours, per its default event retry policy. As this is a managed rule, you cannot change this. To manage for a longer period, you can archive events being ingested by the secondary event bus.
How do you identify if the event has been replicated from another Region? Events routed via global endpoints have identical resource fields, which contain the Amazon Resource Name (ARN) of the global endpoint that routed the event to the event bus. The region field shows the origin of the event. In the following example, the event is sent to the event bus in the primary Region and replicated to the event bus in the secondary Region. The event in the secondary Region is us-east-1, showing the source of the event was the event bus in the primary Region.
If there is a failover, events are routed to the secondary Region and replicated to the primary Region. Inspecting these events, you would expect to see us-west-2 as the source Region.

The two preceding events are identical except for the id. Event IDs can change across API calls so correlating events across Regions requires you to have an immutable, unique identifier. Consumers should also be designed with idempotency in mind. If you are replicating events, or replaying them from archives, this ensures that there are no side effects from duplicate processing.
Setting up a global endpoint
To configure a Global endpoint, define two event buses — one in the “primary” Region (this is the same Region you configure the endpoint in) and one in a “secondary” Region. To ensure that events are routed correctly, the event bus in the secondary Region must have the same name, in the same account, as the primary event bus.
- Create two event buses in different Regions with the same name. This is quickly set up using the AWS Command Line Interface (AWS CLI):
Primary event bus:
aws events create-event-bus --name orders-bus --region us-east-1Secondary event bus:
aws events create-event-bus --name orders-bus --region us-west-2 - Open the Amazon EventBridge console in the Region where you want to create the global endpoint. This aligns with your primary Region. Navigate to the new global endpoints page and create a new endpoint.

- In the Endpoint details panel, specify a name for your global endpoint (for example, OrdersGlobalEndpoint) and enter a description.
- Select the event bus in the primary Region,
orders-bus. - Select the Region used when creating the secondary event bus previously. the secondary event bus by choosing the Region it was created in from the dropdown.

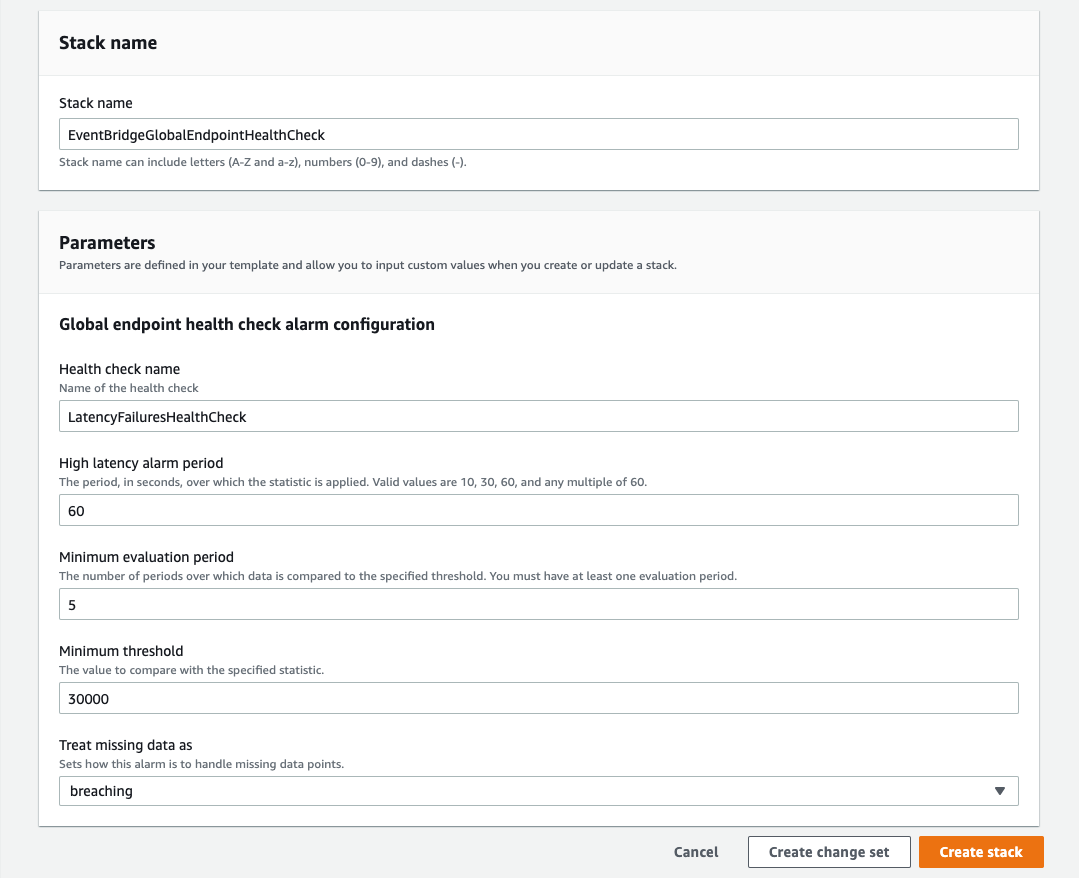
- Select the Route 53 health check for triggering failover and recovery. If you have not created one before, choose New health check. This opens an AWS CloudFormation console to create the “LatencyFailuresHealthCheck” health check and CloudWatch alarm in your account. EventBridge provides a template with recommended defaults for a CloudWatch alarm that is triggered when the average latency exceeds 30 seconds for 5 minutes.

- Once the CloudFormation stack is deployed, return to the EventBridge console and refresh the dropdown list of health checks. Select the physical ID of the health check you created.

- Ensure that event replication is enabled, and create the endpoint.

- Once the endpoint is created, it appears in the console. The global endpoint URL contains the
EndpointId, which you must specify in PutEvents API calls to publish events to the endpoint.




Testing failover
Once you have created an endpoint, you can test the configuration by creating “catch all” rules on the primary and secondary event buses. The simplest way to see events being processed is to create rules with CloudWatch log group target.
Testing global endpoint failure over is accomplished by inverting the Route 53 health check. This can be accomplished using any of the Route 53 APIs. Using the console, open the Route 53 health checks landing page and edit the “LatencyFailuresHealthCheck” associated with your global endpoint. Check “Invert health check status” and save to update the health check.
Within a few minutes, the health check changes state from “Healthy” to “Unhealthy” and you see events flowing to the event bus in the secondary.

Using the PutEvents API with global endpoints
To use global endpoints in your applications, you must update your current PutEvents API call. All AWS SDKs have been updated to include an optional EndpointId parameter that you must set when publishing events to a global endpoint. Even though you are no longer putting events directly on the event bus, the EventBusName must be defined to validate the endpoint configuration.
PutEvents SDK support for global endpoints requires the AWS Common Runtime (CRT) library, which is available for multiple programming languages, including Python, Node.js, and Java:
https://github.com/awslabs/aws-crt-python
https://github.com/awslabs/aws-crt-nodejs
https://github.com/awslabs/aws-crt-java
To install the awscrt module for Python using pip, run:
python3 -m pip install boto3 awscrt
This example shows how to send an event to a global endpoint using the Python SDK:
import json
import boto3
from datetime import datetime
import uuid
import random
client = session.client('events', config=my_config)
detail = {
"order_date": datetime.now().isoformat(),
"customer_id": str(uuid.uuid4()),
"order_id": str(uuid.uuid4()),
"order_total": round(random.uniform(1.0, 1000.0), 2)
}
put_response = client.put_events(
EndpointId=" y6gho8g4kc.veo",
Entries=[
{
'Source': 'com.aws.Orders',
'DetailType': 'OrderCreated',
'Detail': json.dumps(detail),
'EventBusName': 'orders-bus'
}
]
)
Event producers can suffer data loss if the PutEvents API call fails, even if you are using global endpoints. Global endpoints allow you to automate the re-routing of events to another event-bus in another Region, but the health checks triggering the failover won’t be invoked for at least 5 minutes. It’s possible that your applications experience increased error rates for PutEvents operations before the failover occurs and events are routed to a healthy Region. To safeguard against message loss during this time, it’s best practice to use exponential retry and back-off patterns and durable store-and-forward capability at the producer level.
Conclusion
This blog shows how to create an EventBridge global endpoint to improve the availability and reliability of event ingestion of event-driven applications. This example shows how to use the PutEvents in the Python AWS SDK to publish events to a global endpoint.
To create a global endpoint using the API, see CreateEndpoint in the Amazon EventBridge API Reference. You can also create a global endpoint by using AWS CloudFormation using an AWS::Events:: Endpoints resource.
To learn more about EventBridge global endpoints, see the EventBridge Developer Guide. For more serverless learning resources, visit Serverless Land.