Amazon Web Services ブログ
Amazon MSK が Apache Kafka からデータレイクへのマネージドデータ配信を導入
9月28日、Amazon Managed Streaming for Apache Kafka (Amazon MSK) の新機能を発表しました。この機能を使用することで、Apache Kafka クラスターから Amazon Simple Storage Service (Amazon S3) にデータを継続的にロードできるようになります。抽出、変換、ロード (ETL) サービスである Amazon Kinesis Data Firehose を利用して、Kafka トピックからデータを読み取り、レコードを変換し、Amazon S3 の送信先に書き込みます。Kinesis Data Firehose はフルマネージドであり、コンソールで数回クリックするだけで設定できます。コードやインフラストラクチャは必要ありません。
Kafka は、システムまたはアプリケーション間で大量のデータを確実に移動するリアルタイムデータパイプラインを構築するために一般的に使用されています。これは、スケーラビリティと耐障害性に優れたパブリッシュ/サブスクライブメッセージングシステムを提供します。AWS の多くのお客様は、クリックストリームイベント、トランザクション、IoT イベント、アプリケーションやマシンのログなどのストリーミングデータをキャプチャするために Kafka を採用しており、リアルタイム分析と継続的な変換を実行して、このデータをデータレイクおよびデータベースにリアルタイムで配布するアプリケーションを持っています。
ただし、Kafka クラスターのデプロイに課題がないわけではありません。
1 つ目の課題は、Kafka クラスター自体をデプロイ、設定、メンテナンスすることです。この点に鑑みて、弊社は 2019 年 5 月に Amazon MSK をリリースしました。MSK は、本番環境での Apache Kafka の設定、スケール、管理に必要な作業を減らします。インフラストラクチャは当社が管理するため、お客様はデータとアプリケーションに注力できます。2 つ目の課題は、Kafka からのデータを使用するアプリケーションコードを記述、デプロイ、管理することです。通常、Kafka Connect フレームワークを使用してコネクタをコーディングし、そのコネクタを実行するためのスケーラブルなインフラストラクチャをデプロイ、管理、メンテナンスする必要があります。インフラストラクチャに加えて、データ変換および圧縮ロジックをコーディングし、最終的なエラーを管理して、Kafka からの転送 (OUT) 中にデータが失われないように再試行ロジックをコーディングする必要もあります。
本日、Amazon Kinesis Data Firehose を利用して Amazon MSK から Amazon S3 にデータを配信するためのフルマネージドソリューションが利用可能になったことを発表します。このソリューションはサーバーレスであるため、管理するサーバーインフラストラクチャは存在せず、コードも必要ありません。データ変換とエラー処理ロジックは、コンソールで数回クリックするだけで設定できます。
ソリューションのアーキテクチャを次の図に示します。

Amazon MSK はデータソース、Amazon S3 はデータの送信先であり、Amazon Kinesis Data Firehose はデータ転送ロジックを管理します。
この新しい機能を使用すると、Amazon MSK からデータを読み取り、変換し、結果として得られたレコードを Amazon S3 に書き込むためのコードを開発する必要がなくなります。Kinesis Data Firehose は、読み取り、変換と圧縮、Amazon S3 に対する書き込みオペレーションを管理します。また、問題が発生した場合のエラーと再試行ロジックも処理します。システムは、処理できないレコードを、手動検査のために選択した S3 バケットに配信します。このシステムは、データストリームの処理に必要なインフラストラクチャも管理します。転送するデータ量に合わせて自動的にスケールアウトおよびスケールインします。お客様側でプロビジョニングやメンテナンスの操作を行う必要はありません。
Kinesis Data Firehose 配信ストリームは、パブリックとプライベートの両方の Amazon MSK プロビジョンドクラスターまたはサーバーレスクラスターをサポートします。また、MSK クラスターから読み取り、異なる AWS アカウントの S3 バケットに書き込むためのクロスアカウント接続もサポートしています。Data Firehose 配信ストリームは、MSK クラスターからデータを読み取り、設定可能なしきい値のサイズと時間でデータをバッファリングし、バッファリングされたデータを単一のファイルとして Amazon S3 に書き込みます。MSK と Data Firehose は同じ AWS リージョンに存在する必要がありますが、Data Firehose は他のリージョンの Amazon S3 バケットにデータを配信できます。
Kinesis Data Firehose 配信ストリームはデータ型も変換できます。JSON から Apache Parquet および Apache ORC 形式への変換をサポートする組み込み変換機能を備えています。これらは、スペースを節約し、Amazon S3 に対するクエリの高速化を可能にする列指向のデータ形式です。JSON 以外のデータの場合は、データを Apache Parquet/ORC に変換する前に、AWS Lambda を利用して CSV、XML、構造化テキストなどの入力形式を JSON に変換できます。さらに、データを Amazon S3 に配信する前に、Data Firehose からデータ圧縮形式 (GZIP、ZIP、SNAPPY など) を指定したり、データを raw 形式で Amazon S3 に配信したりできます。
仕組みを見てみましょう
使用を開始するために、Amazon MSK クラスターが既に設定されており、いくつかのアプリケーションがそのクラスターにデータをストリーミングしている AWS アカウントを使用します。使用を開始し、最初の Amazon MSK クラスターを作成するには、チュートリアルをお読みいただくことをお勧めします。
このデモでは、コンソールを使用してデータ配信ストリームを作成および設定します。これに代えて、AWS コマンドラインインターフェイス (AWS CLI)、AWS SDK、AWS CloudFormation、または Terraform を使用することもできます。
AWS マネジメントコンソールの Amazon Kinesis Data Firehose ページに移動し、[配信ストリームを作成] を選択します。
データ [ソース] として Amazon MSK を選択し、配信の [送信先] として Amazon S3 を選択します。このデモでは、プライベートクラスターに接続したいので、[Amazon MSK クラスター接続] で [プライベートブートストラップブローカー] を選択します。
クラスターの完全な ARN を入力する必要があります。ほとんどのユーザーと同じように、私も ARN を思い出せないため、[参照] を選択し、リストからクラスターを選択します。
最後に、この配信ストリームの読み取り元となるクラスターの [トピック] 名を入力します。

ソースを設定したら、ページを下方向にスクロールして、データ変換セクションを設定します。
[レコードを変換および転換] セクションで、独自の Lambda 関数を提供して JSON にないレコードを変換するか、またはソース JSON レコードを 2 つの使用可能な事前構築済みの送信先データ形式 (Apache Parquet または Apache ORC) のいずれかに変換するかを選択できます。
Amazon S3 からデータをクエリする場合、Apache Parquet および ORC 形式は JSON 形式よりも効率的です。ソースレコードが JSON 形式の場合、これらの送信先データ形式を選択できます。AWS Glue のテーブルからデータスキーマを提供する必要もあります。
これらの組み込み変換機能により、Amazon S3 のコストが最適化され、ダウンストリーム分析クエリが Amazon Athena、Amazon Redshift Spectrum、または他のシステムで実行される際にインサイトを取得するまでの時間が短縮されます。

最後に、送信先の Amazon S3 バケットの名前を入力します。繰り返しになりますが、思い出せない場合は、[参照] ボタンを使用して、コンソールのガイドに従ってバケットのリストを確認します。必要に応じて、ファイル名として [S3 バケットプレフィックス] を入力します。このデモでは、aws-news-blog と入力します。プレフィックス名を入力しない場合、Kinesis Data Firehose は、日付と時刻 (UTC) をデフォルト値として使用します。
[バッファのヒント、圧縮、暗号化] セクションで、バッファリングのデフォルト値を変更したり、データ圧縮を有効にしたりできるほか、KMS キーを選択して、Amazon S3 の保管中のデータを暗号化することもできます。
準備ができたら、[配信ストリームを作成] を選択します。しばらくすると、ストリームのステータスが ✅ (使用可能) に変わります。

ソースとして選択したクラスターにデータをストリーミングするアプリケーションがあると仮定した場合、S3 バケットに移動して、Kinesis Data Firehose がストリーミングする際に、選択した送信先の形式でデータが表示されることを確認できるようになりました。
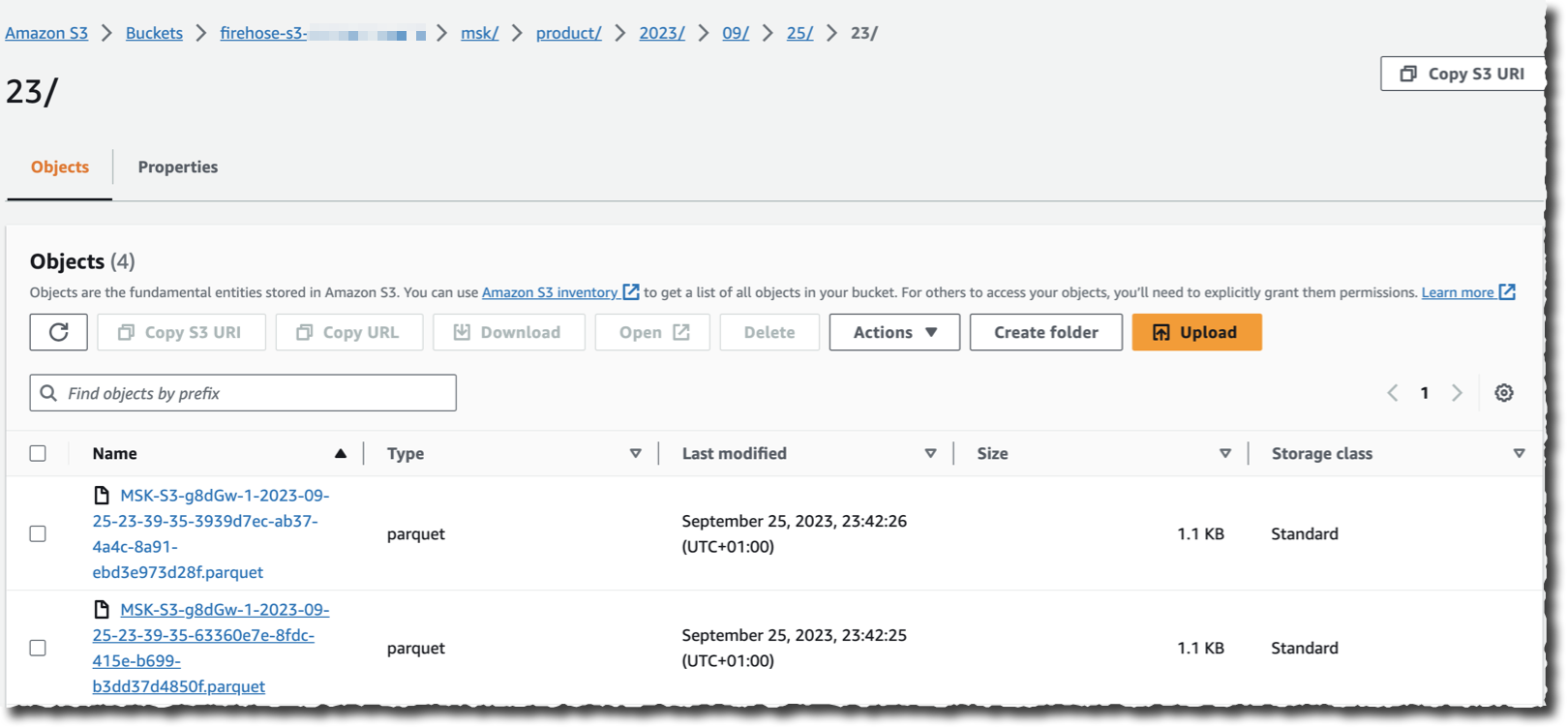
ご覧のとおり、Kafka クラスターからのレコードの読み取り、変換、書き込みにコードは必要ありません。また、ストリーミングと変換ロジックを実行するための基盤となるインフラストラクチャを管理する必要もありません。
料金と利用可能なリージョン。
この新しい機能は現在、Amazon MSK と Kinesis Data Firehose が利用可能なすべての AWS リージョンでご利用いただけます。
Amazon MSK から送信されるデータ量 (GB/月で測定) についての料金をお支払いいただきます。請求システムでは、正確なレコードサイズが考慮されます。丸めはありません。いつものように、料金ページですべての詳細をご確認いただけます。
この新しい機能を採用した後に、どの程度の量のインフラストラクチャやコードが廃止されるのかをお聞きするのが待ちきれません。今すぐ、Amazon MSK と Amazon S3 の間の最初のデータストリームを設定しましょう。
原文はこちらです。