Amazon Web Services ブログ
Amazon Redshift Serverless が新機能を備えて一般公開開始
昨年の re:Invent で、Amazon Redshift Serverless のプレビュー版を紹介しました。これは、データウェアハウスのインフラを管理しなくても、自由にデータを分析できるAmazon Redshift のサーバーレスオプションです。データを読み込んでクエリを実行するだけで利用でき、料金は使用した分だけです。これにより、利用頻度が少ない分析処理や夜間のみ実行されるワークロードなど、データウェアハウスを常時利用しないユースケースの場合に、より多くの企業がモダンデータ戦略を構築することができます。また、データ利用ユーザーが拡大している新しい部門において、データウェアハウスインフラストラクチャを所有せずに分析を実行したいというニーズにも適用できます。
本日、Amazon Redshift Serverless が一般提供開始となり、多くの新機能が追加されたことをお知らせします。また、プレビュー版と比較して、Amazon Redshift Serverless のコンピューティングのコストを削減しています。
名前空間とワークグループを使用して、AWS アカウントとリージョンごとに複数のサーバーレスエンドポイントを作成できるようになりました。
- 名前空間は、データベースオブジェクトとユーザーのコレクションです。 データベース名とパスワード、権限、暗号化設定などが含まれます。ここでデータが管理され、使用されているストレージの量を確認できます。
- ワークグループは、ネットワークとセキュリティの設定を含むコンピューティングリソースの集合です。各ワークグループには、アプリケーションを接続できるサーバーレスエンドポイントがあります。 ワークグループを設定するときに、プライベートまたはパブリックにアクセス可能なエンドポイントを設定できます。
各名前空間に関連付けることができるワークグループは 1 つのみです。逆に、各ワークグループに関連付けることができる名前空間も 1 つのみです。名前空間は、関連付けられたワークグループなしで存在することができます。たとえば、同じまたは別の AWS アカウントまたはリージョンの他の名前空間とデータを共有するためにのみ使用します。
ワークグループ構成で、クエリモニタリングルールを使用してコストが管理できるようになりました。
また、要求の厳しい予測不可能なワークロードに対して高速なパフォーマンスを提供するため、Amazon Redshift Serverless がデータウェアハウスの処理能力を自動スケーリングする方法が、よりインテリジェントになりました。
これがどのように機能するかを簡単なデモで見てみましょう。そして名前空間とワークグループで何ができるかを見てみます。
Amazon Redshift Serverless の使用
Amazon Redshift コンソールのナビゲーションペインで Redshift serverless を選択します。開始するには Use
default settings を選択します。デフォルト設定では最も一般的なオプションを使用して名前空間とワークグループを構成します。たとえば、デフォルト VPC とデフォルトセキュリティグループを使用して接続できるようになります。

デフォルト設定での唯一のオプションは 権限 です。ここでは、Amazon Redshift が S3、Amazon CloudWatch Logs、Amazon SageMaker、AWS Glue などの他のサービスとどのようにやり取りできるかを指定できます。後でデータをロードするために、AmazonRedshift に対し S3 バケットへのアクセスを許可します。Manage IAM roles、Create IAM role の順に選択します。
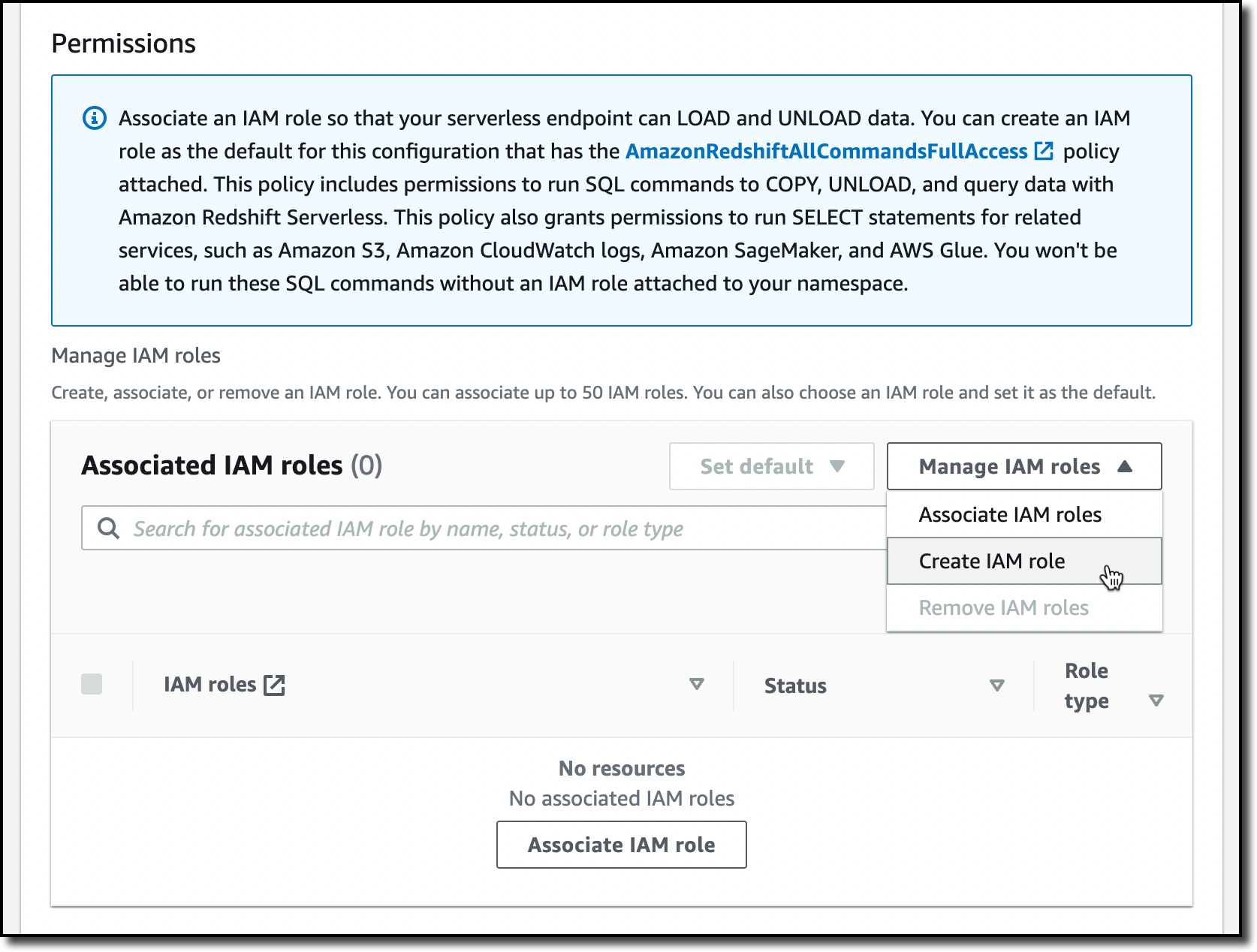
IAM ロールを作成するときに、特定の S3 バケットへのアクセスを許可する specific S3 buckets を選択し、同じ AWS リージョン内の S3 バケットを選択します。 次に、Create IAM role as default を選択して、ロールの作成を完了し、名前空間のデフォルトロールとして自動的に使用します。

Save configuration を選択すると、数分後にデータベースを使用できるようになります。Serverless dashboard で、Query data を選択して Redshift query editor v2 を開きます。そこで、Amazon Redshift データベース開発者ガイドに従って、サンプルデータベースをロードします。簡単なテストを行いたい場合は、いくつかのサンプルデータベース(ここで使用しているものを含む)が sample_data_dev データベースにて既に利用可能です。また、クエリを実行するために AmazonRedshift にデータをロードする必要はないことにも注意してください。外部スキーマと外部テーブルを作成することで、S3 データレイクからのデータをクエリで使用できます。
サンプルデータベースは7つのテーブルで構成され、ユーザーがスポーツイベント、ショー、コンサートのチケットを売買する架空の「TICKIT」Web サイトの販売活動を追跡します。
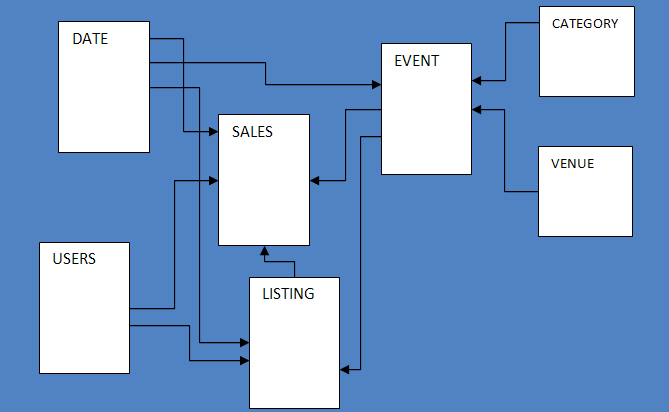
データベーススキーマを構成するために、いくつかの SQL コマンドを実行して、users , venue , category ,
date , event , listing , sales の表を作成します。

次に、データベース表のサンプルデータを含む tickitdb.zip ファイルをダウンロードします。そして IAM ロールを設定するときに使用した時と同じ S3 バケット内の tickit フォルダーにファイルを zip 解凍してロードします。
これで、COPYコマンドを使用して、S3 バケットからデータベースにデータをロードできます。 たとえば、users 表にデータをロードするには、次のようにします。
copy users from 's3://MYBUCKET/tickit/allusers_pipe.txt' iam_role default;sales 表のデータを含むファイルは、タブで区切られた値を使用しています。
copy sales from 's3://MYBUCKET/tickit/sales_tab.txt' iam_role default delimiter '\t' timeformat 'MM/DD/YYYY HH:MI:SS';すべての表にデータを読み込んだ後、いくつかのクエリの実行を開始します。たとえば、次のクエリは5つのテーブルを結合して、カリフォルニアを拠点とするイベントの上位5つの seller を見つけます(サンプルデータは2008年のものであることに注意してください)。
select sellerid, username, (firstname ||' '|| lastname) as sellername, venuestate, sum(qtysold)
from sales, date, users, event, venue
where sales.sellerid = users.userid
and sales.dateid = date.dateid
and sales.eventid = event.eventid
and event.venueid = venue.venueid
and year = 2008
and venuestate = 'CA'
group by sellerid, username, sellername, venuestate
order by 5 desc
limit 5;
データベースの準備ができたので、Amazon Redshift Serverless の名前空間とワークグループを構成して何ができるかを見てみましょう。
名前空間の使用と設定
名前空間は、データベースデータとそのセキュリティ構成の集合です。Amazon Redshift コンソールのナビゲーションペインで、Namespace configuration を選択します。リストでは、作成した default の名前空間を選択します。
Data backup タブでは、スナップショットを作成または復元したり、30分ごとに自動的に作成され24時間保持されるリカバリポイントの1つからデータを復元したりできます。これは、誤って書き込みまたは削除した場合にデータを回復するのに役立ちます。

Security and encryption タブで、リソースの暗号化と復号化に使用されるAWS Key Management Service (KMS) キーを含む、アクセス許可と暗号化設定を更新できます。このタブでは、監査ログを有効にして、ユーザー、接続、ユーザーアクティビティのログを CloudWatch Logs にエクスポートすることもできます。

Datashares タブで、データ共有を作成して、同じリージョンまたは異なるリージョンにある他の名前空間や AWS アカウントとデータを共有できます。このタブでは、他の名前空間または AWS アカウントから受け取ったデータ共有からデータベースを作成することもできます。また、AWS Data Exchange によって管理されているデータ共有のサブスクリプションを確認できます。

データ共有を作成するときに、含めるオブジェクトを選択できます。たとえば、ここでは機密データが含まれていないため、date 表と event 表のみを共有します。

ワークグループの使用と構成
ワークグループは、コンピューティングリソースとそのネットワークおよびセキュリティ設定の集合です。そしてこれらは、構成されている名前空間のサーバーレスエンドポイントを提供します。Amazon Redshift コンソールのナビゲーションペインで、Workgroup configuration を選択します。リストでは、作成した default の名前空間を選択します。
Data access タブで、ネットワークとセキュリティの設定を更新したり(たとえば、VPC、サブネット、セキュリティグループなどを変更したり)、エンドポイントをパブリックアクセス可能にすることができます。このタブでは、Enhanced VPC routing を有効にして、サーバーレスデータベースと使用するデータリポジトリ(たとえば、データのロードまたはアンロードに使用される S3 バケット)間でインターネットの代わりに VPC を介してネットワークトラフィックをルーティングすることもできます 。別の VPC またはサブネットにあるサーバーレスエンドポイントにアクセスするために、Amazon Redshift によって管理される VPC エンドポイントを作成できます。

Limits タブで、クエリの処理に使用される基本処理能力(Redshift Processing Unit (RPU) で表される)を設定できます。Amazon Redshift Serverless は、より多くのユーザーからの処理を実行するために処理能力を拡張します。ここでは、クエリを高速化するために基本処理能力を増やすか、コストを削減するためにそれを減らすオプションもあります。
このタブでは、Usage limits を設定して、コストを予測可能に保つために、日次、週次、および月次のしきい値を設定することもできます。たとえばこの例では、コンピューティングリソースに対して、1日あたり200 RPU 時間の制限、および1か月あたり2,000 RPU の時間制限を設定しました。クロスリージョンデータ共有のデータ転送コストを管理するために、1日あたり3 TB の制限、1週間あたり10 TB の制限を設定しました。そして各クエリで使用されるリソースを制限するために、Query limits を使用して、60秒を超えて実行されているクエリをタイムアウトさせるよう設定しました。

利用可能なリージョンと料金
Amazon Redshift Serverless は、米国東部(バージニア北部)、米国東部(オハイオ)、米国西部(オレゴン)、欧州(フランクフルト)、欧州(アイルランド)、欧州(ロンドン)、欧州(ストックホルム)、アジアパシフィック(ソウル)、アジアパシフィック(シンガポール)、アジアパシフィック(シドニー)、アジアパシフィック(東京)の各 AWS リージョンで一般利用可能です。
JDBC / ODBCを介して任意のクライアントツールを使用するか、AmazonRedshift コンソールで利用可能な Web ベースの SQL クライアントアプリケーションである Amazon Redshift query editor v2 を使用して、ワークグループエンドポイントに接続できます。Web サービスベースのアプリケーション(AWS Lambda 関数や Amazon SageMaker ノートブックなど)を使用する場合、組み込みの Amazon Redshift Data API を使用してデータベースにアクセスし、クエリを実行できます。
Amazon Redshift Serverless では、データベースがアクティブなときに消費するコンピューティング容量に対してのみ料金を支払います。コンピューティング容量は、ワークロードに基づいて自動的にスケールアップまたはスケールダウンし、非アクティブな期間中にはシャットダウンして、時間とコストを節約します。データはマネージドストレージに保存され、GB/月の料金を支払います。
Amazon Redshift Serverless をさらに幅広いユースケースに対応できるようにするために、価格性能を見直しました。米国東部(バージニア北部)リージョンのRPU-時間あたりの価格を0.5ドルから0.375ドルに引き下げました。 同様に、他のリージョンの価格もプレビュー価格から平均25%引き下げています。詳細については、AmazonRedshift の料金ページをご覧ください。
すぐにAmazon Redshift Serverless をお試し頂けるよう90日以内に利用可能な300ドルの AWS クレジットを提供しています。これらのクレジットは、Amazon Redshift Serverless のコンピューティング、ストレージ、スナップショットの使用にかかる費用のみをカバーするために適用されます。
Amazon Redshift Serverlessを使用して、データから数秒でインサイトを得ることができます。
— Danilo
翻訳はソリューションアーキテクトの野間と平間が担当しました。原文はこちらです。
Amazon Redshift Serverless を使って、データ分析をかんたんにお試しいただくことのできるセルフハンズオンを、こちらのページにご用意しております。興味のある方はぜひお試しください。