Amazon Web Services ブログ
Amazon Redshift Serverless のご紹介 – データウェアハウスインフラストラクチャを管理することなく、あらゆる規模で分析を実行
例えば、従来のデータウェアハウスを管理する専門知識や時間がないデベロッパーやビジネスアナリストなど、組織内の新しいオーディエンスの間でデータ分析の利用が拡大しています。また、ワークロードが変動し、予測不可能な急上昇が発生し、キャパシティーを継続的に管理することが非常に困難なお客様もいます。
Amazon Redshift では、SQL を使用して、データウェアハウス、運用データベース、データレイクにわたって構造化データと半構造化データを分析できます。2021 年 11 月 30 日(米国時間)、Amazon Redshift Serverless のパブリックプレビューを発表しました。 これは、あらゆる規模で高いパフォーマンスでクラウドで分析を非常に簡単に実行できる新機能です。データを読み込んでクエリを開始するだけです。クラスターのセットアップや管理は不要です。データのクエリやロード中など、データウェアハウスの使用中は秒単位で課金されます。データウェアハウスがアイドル状態の場合は課金されません。
Amazon Redshift Serverless は、開始時に適切なコンピューティングリソースを自動的にプロビジョニングします。同時ユーザー数が増え、新しいワークロードが増えるにつれ、データウェアハウスはシームレスかつ自動的に拡張し、変化に適応します。オプションで、基本データウェアハウスのサイズを指定して、コストとアプリケーション固有の SLA をさらに細かく制御できます。
新しいサーバーレスオプションを使用すると、Amazon Simple Storage Service (Amazon S3) データレイク、Amazon Aurora および Amazon Relational Database Service (RDS) データベースなど、他の AWS データストアのデータを引き続きクエリできます。
Amazon Redshift Serverless は、変動するワークロード、アイドル時間のある定期的なワークロード、急上昇のある定常状態のワークロードなど、コンピューティングのニーズを予測するのが難しい場合に最適です。このアプローチは、迅速に開始する必要があるアドホック分析のニーズや、テスト環境と開発環境にも適しています。
ここからは、実際にどのように機能するのかを見ていきましょう。
Amazon Redshift Serverless を使用する
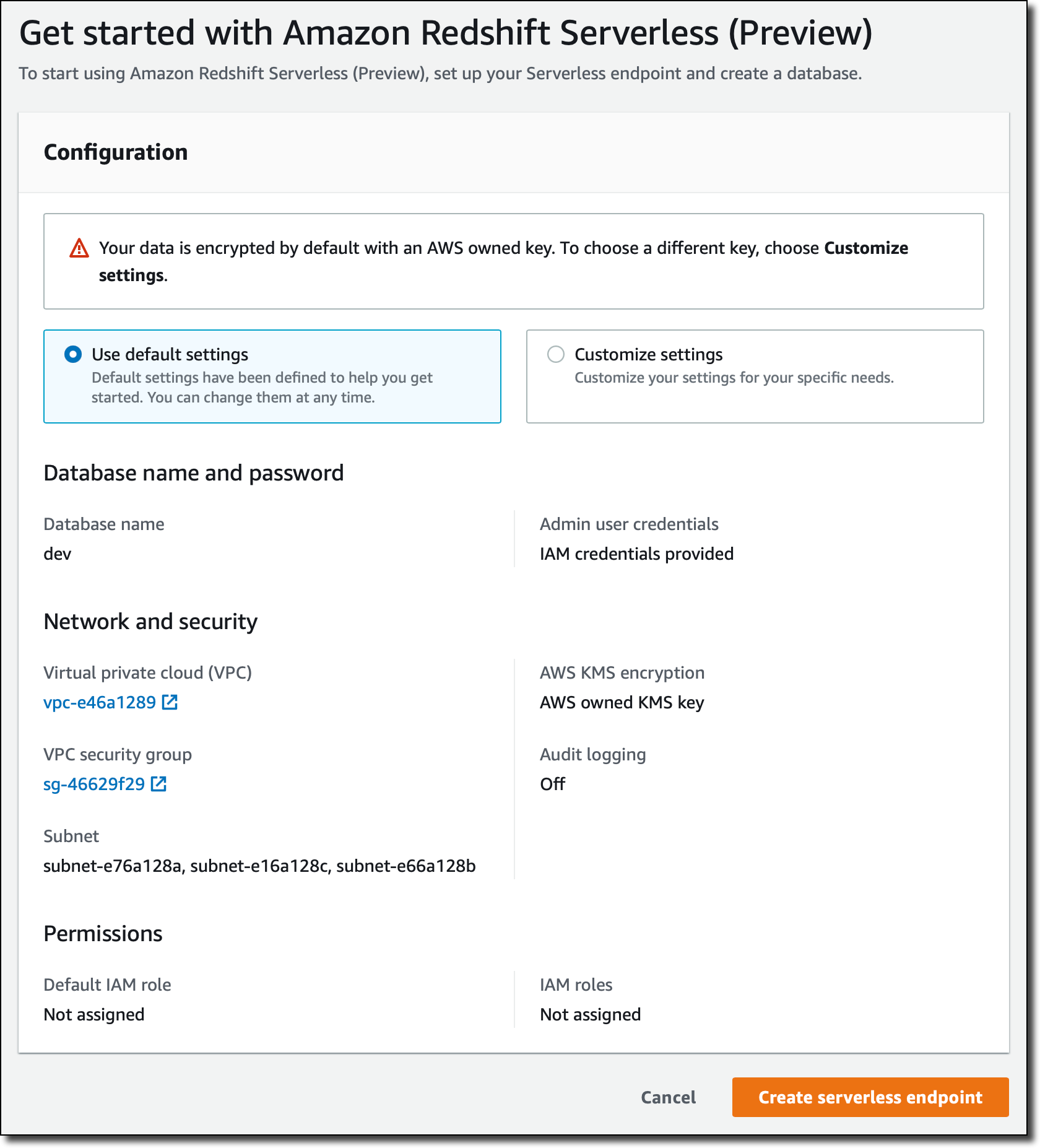
Amazon Redshift コンソールに移動して、新しいサーバーレスオプションを選択します。初めてサーバーレスエンドポイントをセットアップし、ネットワークとセキュリティを設定しました。
デフォルトの Amazon Virtual Private Cloud (VPC) とそのデフォルトのセキュリティグループのすべてのサブネットを使用するデフォルト設定を確認します。データは常に暗号化されており、AWS が所有するデフォルトのキーを使用します。オプションで、すべての設定をカスタマイズできます。今後、AWS Identity and Access Management (IAM) ロールを関連付けて、S3 バケットからデータをロードできるようにするなど、他の AWS リソースにアクセスする許可を付与できます。サーバーレスエンドポイントの設定は、同じ AWS アカウントとリージョン内のすべてのサーバーレスデータウェアハウスで共有されます。
データをクエリするには、Amazon Redshift Query Editor V2 を使用します。これは、数か月前に利用可能になった新しい無料のウェブベースのツールです。クエリエディタを使用すると、いくつかのサンプルデータセットにすばやくアクセスでき、Amazon Redshift の SQL 機能を簡単に学習できます。これには、TPC-H、TPC-DS、イベント用のチケット販売に関する情報を含むデータセットである tickit があります。
簡単なテストのために、tickit サンプルデータセットを使用するので、データを読み込む必要はありません。日付ごとに販売されたチケットのリストを取得するクエリを用意し、最初に売り上げが多い日付を表示するように並べ替えます。
SELECT caldate, sum(qtysold) as sumsold
FROM tickit.sales, tickit.date
WHERE sales.dateid = date.dateid
GROUP BY caldate
ORDER BY sumsold DESC;ウェブベースのクエリエディタを使用すると、サーバーレスエンドポイントに到達するために SQL クライアントを設定したり、ネットワークアクセス許可を設定したりする必要がなくなります。代わりに、SQLクエリを記述して実行するだけです。

私は視覚的に見えるようにするのが好みです。結果テーブルの右側にある [チャート] オプションを有効にして、棒グラフを選択します。

チャートの明快さに満足できたので、イメージファイルとしてエクスポートしました。こうすることで、すぐに共有したり、レポートに含めたりすることができます。

Amazon Redshift Serverless は、半構造化データのサポートなど、Amazon Redshift の豊富な SQL 機能をすべてサポートしています。JDBC/ODBC 準拠のツールまたは Amazon Redshift Data API を使用して、データをクエリできます。データを移行するには、Amazon Redshift でプロビジョニングされたクラスターのスナップショットを作成し、サーバーレスとして復元します。次に、新しいサーバーレスエンドポイントを使用するように SQL アプリケーションを更新する必要があります。
利用可能なリージョンと料金
Amazon Redshift Serverless は、米国東部 (バージニア北部)、米国西部 (北カリフォルニア、オレゴン)、欧州 (フランクフルト、アイルランド)、アジアパシフィック (東京) の各 AWS リージョンでパブリックプレビューでご利用いただけます。
Amazon Redshift Serverless では、使用するコンピューティングとストレージに対して別途料金を支払います。コンピューティング性能は Redshift Processing Units (RPU) で測定され、ワークロードの料金は RPU 時間で 1 秒単位で請求されます。ストレージについては、Amazon Redshift が管理するストレージに保存されたデータと、スナップショットに使用したストレージに対して課金されます。これは、RA3 インスタンスを使用してプロビジョニングされたクラスターで支払うのと同じです。
コストを管理するために、使用制限を指定し、制限に達した場合に Amazon Redshift が自動的に実行するアクションを定めることができます。使用制限は RPU 時間単位で指定でき、毎日、毎週、または毎月の期間に関連付けられます。使用制限を高く設定すると、システムの全体的なスループットが向上します。特に、常に高いパフォーマンスを維持しながら高い同時実行性を処理する必要があるワークロードでそれが言えます。
コンピューティングリソースは、アクティビティがない場合はバックグラウンドで自動的にシャットダウンし、データをロードしているときやクエリを受信すると再開します。新しいサーバーレスエンドポイントを介して S3 データレイクにアクセスする場合、Amazon Redshift Spectrum の料金を個別に支払う必要はありません。統一されたサーバーレスエクスペリエンスがあり、データレイククエリの料金も RPU 秒で済みます。詳細については、Amazon Redshift の料金ページを参照してください。
サーバーレスエンドポイントは AWS アカウントレベルで設定されます。複数のチームまたはプロジェクトがあり、コストを個別に管理する場合は、別々の AWS アカウントを使用できます。プロビジョニングされたクラスターとサーバーレスエンドポイント間、およびアカウント全体のサーバーレスエンドポイント間でデータを共有できます。
練習に役立つように、Amazon Redshift Serverless パブリックプレビューを試すのに使える 500 USD の AWS クレジットを用意させていただきました。 クレジットは、Amazon Redshift Serverless で初めてデータベースを作成したときに取得します。クレジットの用途は、Amazon Redshift Serverless のコンピューティング、ストレージ、およびスナップショットの使用にかかる費用を賄うことに限定されます。
Amazon Redshift Serverless を今すぐ使い始めて、データウェアハウスクラスターのプロビジョニングや管理を行うことなく、分析の実行とスケーリングを行いましょう。
– Danilo
原文はこちらです。