Amazon Web Services ブログ
新機能 — Amazon SageMaker Pipelines が機械学習プロジェクトに DevOps 機能を提供
本日、 Amazon SageMaker Pipelines を発表することができまして、大変うれしく思います。これは Amazon SageMaker の新機能で、データサイエンティストやエンジニアが、エンドツーエンドの機械学習パイプラインを簡単に構築、自動化、スケールできるようになります。
機械学習 (ML) はもともと試験段階にあり、本質的に予測することはできません。数日から数週間かけてさまざまな方法でデータを分析および処理します。これは、ジオード (晶洞石) を壊して、貴重な宝石を見つけようとする作業のようです。次に、さまざまなアルゴリズムとパラメータを試しながら、最高の精度を求めて多くのモデルをトレーニングおよび最適化します。この作業は通常、アルゴリズムとパラメータの間に依存関係がある多くの異なる手順を伴い、手作業で管理するため、とても複雑になる可能性があります。特に、モデル系列の追跡は簡単ではなく、監査性やガバナンスを妨げます。最後に、上位モデルをデプロイし、参照テストセットに対するモデルの評価を行います。最後に、 と言いましたが、実際には何度も反復して、新しいアイデアを試し、新しいデータでモデルを定期的に再トレーニングします。
ML がどんなにエキサイティングであっても、残念ながら多くの繰り返し作業を伴います。小規模なプロジェクトでも、本番環境に移る前には何百もの手順が必要になります。こうした作業のせいで、時間の経過とともにプロジェクトの楽しさや興奮が失われていくだけでなく、監視する必要性やヒューマンエラーの可能性が大きくなります。
手作業を軽減し、トレーサビリティを向上させるために、多くの ML チームでは DevOps の理念を採用し、継続的インテグレーションと継続的配信 (CI/CD) 用のツールとプロセスを実装しています。確かにこれは正しい手順といえますが、独自のツールを作成することで、当初の予想よりも多くのソフトウェアエンジニアリングとインフラストラクチャ作業が必要な複雑なプロジェクトとなる場合が多いです。貴重な時間とリソースが実際の ML プロジェクトから奪われ、革新のペースがスローダウンします。残念ながら一部のチームでは、手作業でのモデルの管理、承認、デプロイに戻ることにしました。
Amazon SageMaker Pipelines のご紹介
簡単に言うと、Amazon SageMaker Pipelines で、ML プロジェクトの DevOps がトップレベルになります。この新機能により、データサイエンティストや ML デベロッパーは、自動化された、信頼性の高いエンドツーエンドの ML パイプラインを簡単に作成できるようになります。SageMaker は通常どおり、すべてのインフラストラクチャを完全に管理するため、お客様が作業を行う必要はありません。
Care.com は、高品質の介護サービスを見つけて管理するための世界をリードするプラットフォームです。Care.com のデータサイエンスマネージャーの Clemens Tummeltshammer 氏は次のように言います「 需要と供給が均衡な、力のある介護業界は、個々の家庭から国の GDP にいたる経済成長にとって不可欠です。私たちは Amazon SageMaker Feature Store と Amazon SageMaker Pipelines に期待を寄せています。これらのパイプラインは、データ準備からデプロイにいたるスケーラブルなエンドツーエンドの機械学習 (ML) モデルパイプラインを構築するために利用できる、厳選された一貫性のあるデータのセットを活用することで、データサイエンスチームや開発チーム全体でより優れた拡張が可能になると確信しています。新たに発表された、この Amazon SageMaker の機能により、さまざまなアプリケーション用の ML モデルの開発とデプロイを迅速化できるでしょう。お客様には、以前よりすばやくリアルタイムの推奨事項を提供できるので、情報に基づいた意思決定を行っていただけるようになります。」
Amazon SageMaker Pipelines の主要コンポーネント (パイプライン、モデルレジストリ、MLOps テンプレート) について詳しく説明しましょう。
パイプライン – モデル構築パイプラインは、シンプルな Python SDK で定義されます。これには、Amazon SageMaker で利用可能なすべての操作、つまり Amazon SageMaker Processing または Amazon SageMaker Data Wrangler によるデータ準備、モデルトレーニング、リアルタイムエンドポイントへのモデルのデプロイ、あるいはバッチ変換などが含まれます。トレーニング前またはモデルのデプロイ後にバイアスを検出するため、 Amazon SageMaker Clarify をパイプラインに追加することもできます。同様に、Amazon SageMaker Model Monitor を追加して、データや予測品質の問題を検出することも可能です。
モデル構築パイプラインを起動すると、CI/CD パイプラインとして実行されます。すべての手順が記録され、詳細なログ情報をトレーサビリティとデバッグの目的で利用できます。もちろん、Amazon SageMaker Studio でパイプラインを視覚化し、さまざまな実行をリアルタイムで追跡することもできます。
モデルレジストリ – モデルを追跡およびカタログ化できます。SageMaker Studio では、モデル履歴の表示、バージョンの一覧表示と比較、モデル評価メトリクスなどのメタデータの追跡を簡単に実行できます。また、本番環境にデプロイできるバージョンと、できないバージョンを定義することもできます。承認されると、モデルのデプロイを自動的にトリガーするパイプラインを構築することもできます。モデルレジストリは、モデル系列のトレース、モデルガバナンスの向上、コンプライアンス体制の強化に役立ちます。
MLOps テンプレート – SageMaker Pipelines には、一般的なパイプライン (構築/トレーニング/デプロイ、デプロイのみ、など) 用の組み込みの CI/CD テンプレートが数多く含まれています。独自のテンプレートを追加して公開することもできます。そのため、チームは簡単にテンプレートを検出してデプロイできます。テンプレートで多くの時間を節約できるだけではありません。インフラストラクチャを管理する必要なく、標準的な作業で、実験からデプロイまで ML チーム間で簡単に共同作業ができるようになります。さらに、Ops チームは必要に応じて手順をカスタマイズしたり、トラブルシューティングを完全に視認したりも可能になります。
では、簡単なデモを行いましょう。
Amazon SageMaker Pipelines を使用したエンドツーエンドのパイプラインの構築
SageMaker Studio を開き、[コンポーネント] タブから [プロジェクト] ビューを選択します。組み込みのプロジェクトテンプレートの一覧が表示されます。モデルの構築、トレーニング、デプロイのどれか 1 つを選択します。

次に、プロジェクトに名前を付けて、作成するだけです。
数秒後には、プロジェクトの準備は完了しています。AWS CodeCommit でホストされている 2 つの Git リポジトリが含まれていることがわかります。1 つはモデルトレーニング用、もう 1 つはモデルのデプロイ用です。

最初のリポジトリは、データ処理、モデルトレーニング、モデル評価、精度に基づく条件付きモデル登録などの、マルチステップのモデル構築パイプラインを作成するためのスキャフォールディングコードを提供します。pipeline.py ファイルでわかるように、このパイプラインはよく知られている Abalone データセットの XGBoost アルゴリズムを使って線形回帰モデルをトレーニングします。このリポジトリには、パイプラインを自動的に実行するために、AWS CodePipeline と AWS CodeBuild が使用するビルド指定ファイルも含まれています。
同様に、2 つ目のリポジトリには、モデルデプロイ用のコードファイルと設定ファイル、品質のゲートを通過するために必要なテストスクリプトが含まれています。また、このオペレーションは AWS CodePipeline と AWS CodeBuild に基づいています。これらは、AWS CloudFormation テンプレートを実行して、ステージングと本番用のモデルエンドポイントを作成するものです。
2 つの青いリンクをクリックすると、リポジトリをローカルに複製します。これにより、パイプラインの最初の実行がトリガーされます。
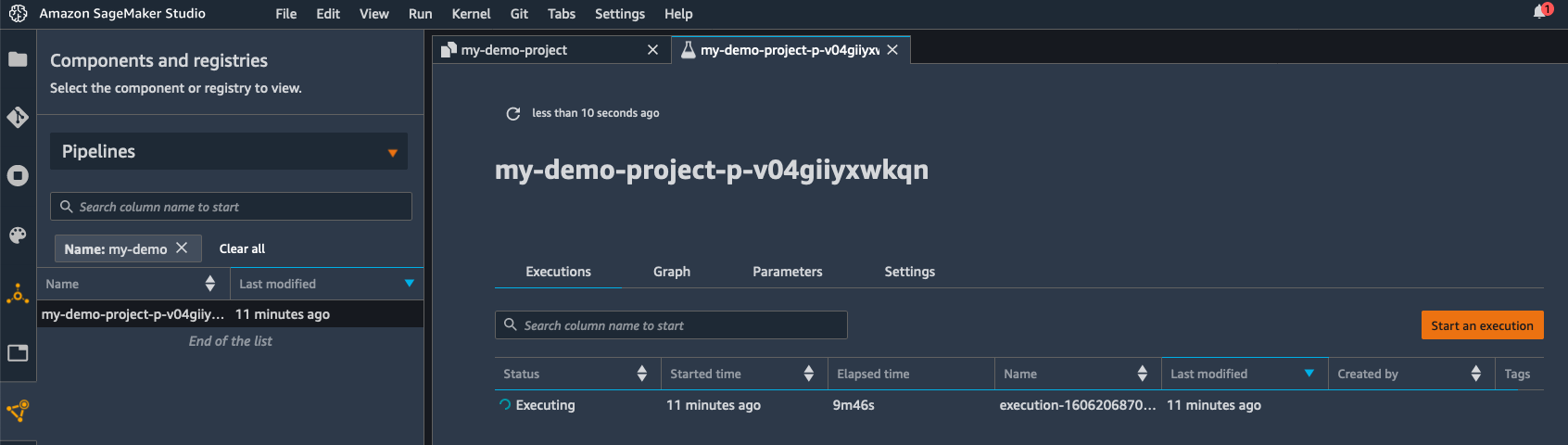
数分後、パイプラインは正常に実行されました。[パイプライン] ビューに切り替えると、その手順を視覚化できます。

トレーニングの手順上でクリックすると、モデルの二乗平均平方根誤差 (RMSE) メトリクスを確認できます。
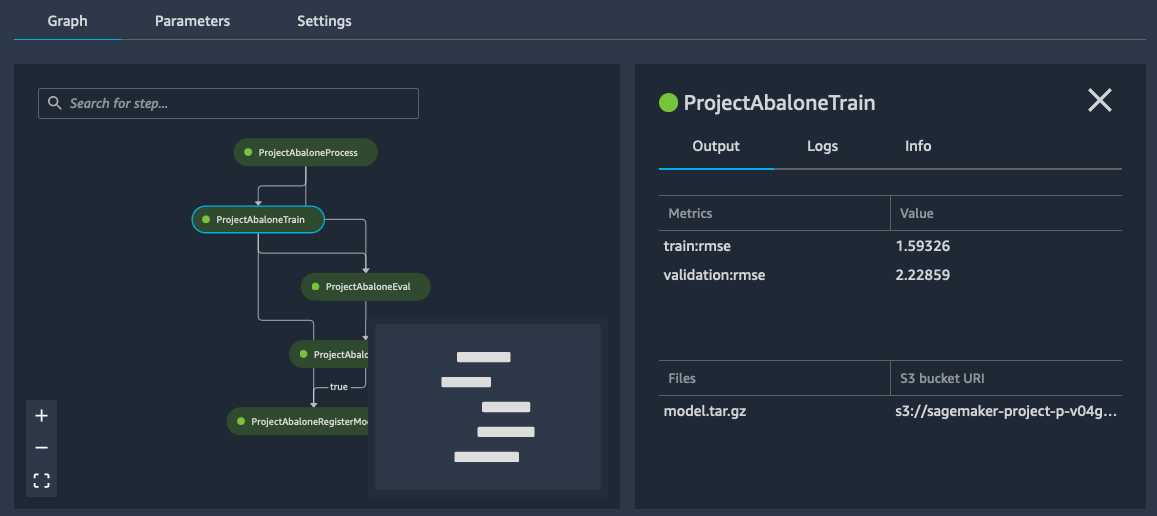
RMSE が条件付き手順で定義されているしきい値よりも低いため、下に示すように、モデルがモデルレジストリに追加されます。
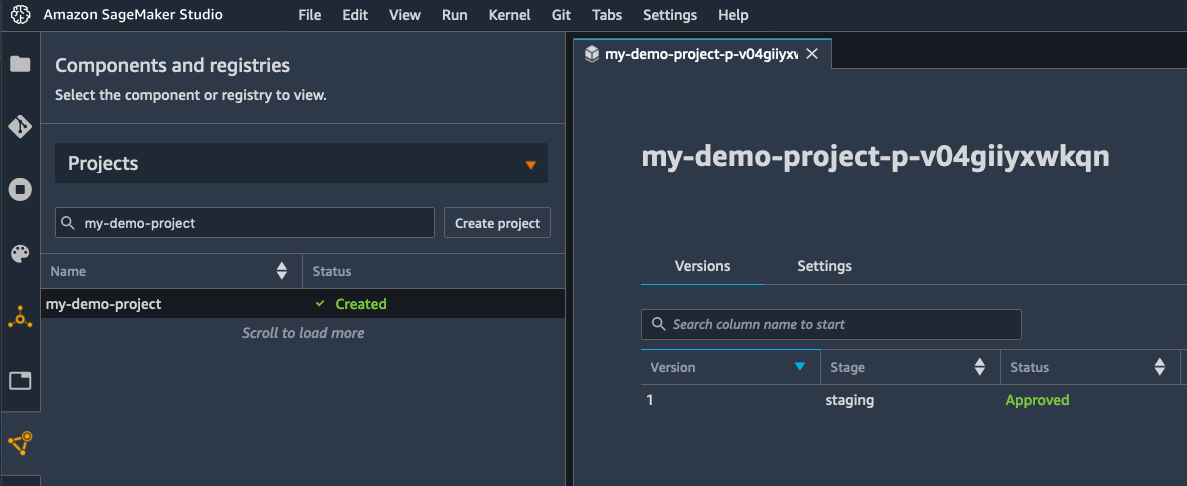
簡素化するために、登録手順ではモデルのステータスが「承認済み」に設定され、同じアカウントのリアルタイムエンドポイントへのデプロイが自動的にトリガーされます。数秒以内に、モデルがデプロイされていることがわかります。

または、モデルを「手動承認待ち」ステータスで登録することもできます。これにより、モデルは手動でレビューされ、承認されるまでデプロイされなくなります。モデルレジストリはクロスアカウントでのデプロイをサポートしているため、アカウント間で何もコピーしなくても、別のアカウントに簡単にデプロイできます。
数分後、エンドポイントが起動し、それを使用してモデルをテストできます。

このモデルが期待どおりに動作することを確認したら、MLOps チームに ping して、モデルを本番環境にデプロイするように依頼することができます。
MLOps の帽子マークをオンにして、AWS CodePipeline コンソールを開くと、デプロイが承認を待っていることがわかります。

次に、デプロイ用モデルを承認します。これで、パイプラインの最終段階がトリガーされます。
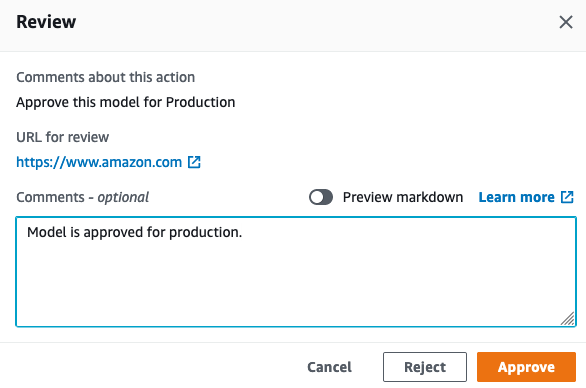
データサイエンティストのマークに戻すと、SageMaker Studio でモデルがデプロイされていることがわかります。これで完了です。

開始方法
ご覧のとおり、Amazon SageMaker Pipelines を使って、データサイエンスチームと MLOps チームは使い慣れたツールで簡単に共同作業を行うことができます。堅牢で自動化された ML パイプラインを作成および実行することで、高品質なモデルを従来よりも迅速に構築できます。
SageMaker を利用できるすべての商用リージョンで、SageMaker Pipelines を開始できます。CodePipeline が利用可能なリージョンでは、MLOps 機能も使用できます。
サンプルノートブックを利用して、開始できます。ぜひお試しいただいて、ご意見をお聞かせください。当社では、常にお客様からのフィードバックをお待ちしております。フィードバックは、通常の AWS サポート連絡先、または、SageMaker の AWS フォーラムを通じてお送りください。
早期段階のテストで協力してくれた、同僚の Urvashi Chowdhary に感謝します。