Amazon Web Services ブログ
Amazon SageMakerとAmazon QuickSightを使用した有害事象のリアルタイム検出システムの構築
この記事は “Build a system for catching adverse events in real-time using Amazon SageMaker and Amazon QuickSight” を翻訳したものです。
ソーシャルメディアプラットフォームは、消費者が服用している医薬品を含むさまざまな製品について話すためのコミュニケーションチャネルを提供します。製薬会社にとって、製品の作用を監視して効果的に追跡することで、製品に関する顧客からのフィードバックが得られます。これは、患者の安全の維持と向上に不可欠です。しかし、医薬品投与による予期せぬ医療事象が発生した場合は、有害事象(AE)に分類されます。これには、投薬過誤、薬物有害反応、アレルギー反応、過剰摂取が含まれます。AEは、病院、介護施設、外来患者の環境など、どこでも発生する可能性があります。
この投稿の目的は、Amazon SageMakerと事前トレーニング済みのトランスフォーマーモデルを使用して、ソーシャルメディアで言及されているAEを検出する方法を紹介する例を提供することです。このモデルは、テキスト分類タスクを実行するために、ドメイン固有のデータに基づいてファインチューニングされます。また、Amazon QuickSightを使用してモニタリングダッシュボードを作成しています。重要なのは、この投稿でツイートを取得するにはTwitter開発者アカウントが必要であることです。このデモでは、公開されているツイートのみを使用します。この投稿ではプライバシーとデータガバナンスについて明確に説明していませんが、ユーザーはこれらのプロセスを考慮する必要があります。役立つリソースは、AWS Marketplaceや、データガバナンス向けのAWSパートナーソリューションを通じて見つけることができます。このデモの後、使用したデータをすべて削除しました。
この記事は、世界中のライフサイエンスおよび製薬業界のお客様を対象とした包括的なファーマコビジランス活動をサポートすることを目的としていますが、リファレンス・アーキテクチャはどのお客様にも実装できます。このモデルは、有害事象を特定するため学習済みで、バイオテクノロジー、ヘルスケア、ライフサイエンスの分野に適用できます。
ソリューション概要
次のアーキテクチャ図は、ソリューションのワークフローを示しています

ワークフローには以下のステップが含まれます。
- SageMakerトレーニングを使用して分類モデルを学習し、SageMakerリアルタイム推論を使用して学習済みモデルをエンドポイントにデプロイします。
- AWS Cloud9ストリームリスナーを作成します。
- ライブツイートをAmazon DynamoDBに保存します。
- DynamoDB Streamsを使用してAWS LambdaがAE分類用のSageMakerエンドポイントを呼び出し、Amazon Comprehend Medicalで症状を検出し、ICD-10の説明を提供するようにトリガーします。
- Amazon Simple Storage Service(Amazon S3)にAE分類と症状を含むツイートを保存し、AWS Glue Data Catalogを使用してテーブルビューを作成します。
- Amazon Athenaを使用してAmazon S3からのデータを分析します。
- QuickSightダッシュボードを作成して、ツイートとそのAEステータスを監視します。
環境の構築とソリューションの実装
クラウドアプリケーションリソースを定義するオープンソースのソフトウェア開発フレームワークであるAWS Cloud Development Kit (AWS CDK)を使用して、有害事象検出アプリのテンプレートを作成しました。ソリューションをエンドツーエンドで実行するには、次の手順を実行します。
- GitHubリポジトリを、AWSアカウントで設定され、AWS Command Line Interface (AWS CLI)がインストールされているローカルマシン、またはAWSアカウント内のAWS Cloud9環境にあるローカルマシンにクローンします。
コードリポジトリのクローンを作成したら、デプロイプロセスを開始できます。
- プロジェクトディレクトリに移動し、
.venvディレクトリの下に格納される仮想環境をこのプロジェクト内に作成します。macOSまたはLinuxで仮想環境を手動で作成するには、次のコードを使用します。 - 仮想環境が作成されたら、仮想環境をアクティブ化します。
- 仮想環境がアクティブ化されたら、必要な依存関係をインストールします。
- この時点で、AWS CloudFormationテンプレートを作成できるようになりました。
cdk synth はCloudFormationテンプレートをJSON形式で生成し、リソースを起動するために必要なその他のアセットファイルを生成します。これらのファイルはcdk.outディレクトリに保存されます。その後、cdk deployコマンドはスタックをAWSアカウントにデプロイします。2つのスタックをデプロイします。1つはS3バケットスタックで、もう1つは主要な有害事象アプリケーションスタックです。コアアプリケーションスタックは、Amazon S3スタックが正常にデプロイされた後にデプロイする必要があります。デプロイプロセス中に問題が発生した場合は、「AWS CDK の一般的な問題のトラブルシューティング」を参照してください。
AWS CDKが正常にデプロイされたら、モデルをトレーニングしてデプロイする必要があります。SageMakerコンソールの[ノートブック]ページに AdverseEventDetectionModelingという名前のノートブックインスタンスがあるはずです。ノートブック全体 (AE_Model_train_Deploy.ipynb) を実行すると、SageMakerトレーニングジョブが起動され、モデルがSageMakerエンドポイントにデプロイされます。このチュートリアルのモデルトレーニングデータは、Hugging FaceのAdverse Drug Reactionデータセットに基づいていますが、他のデータセットに置き換えることができます。
有害事象分類のためのトランスフォーマーモデルの学習とデプロイ
有害事象 (AE) 分類のために、Hugging Faceライブラリ内でトランスフォーマーモデルをファインチューニングします。トレーニングジョブはSageMaker PyTorch estimatorを使用して構築されます。モデルのデプロイにはPyTorch Model Serverを使用します。このセクションでは、モデルトレーニングとデプロイメントの主な手順を説明します。
データ準備
Hugging Faceデータセット内のAdverse Drug Reactionデータ (ade_corpus_v2) をトレーニングおよび検証データとして使用します。モデルのトレーニングと推論に必要なデータ構造には、次の2つの列があります。
- モデル入力データとしてのテキストコンテンツの1列。
- ラベルクラスの別の列。テキストには、
Not_AEクラスとAdverse_Eventクラスの2つのクラスがあります。
生のデータセットをダウンロードし、トレーニング (80%) データセットと検証 (20%) データセットに分割し、入力列とターゲット列の名前をそれぞれテキストとラベルに変更してAmazon S3にアップロードします。
このモデルはマルチクラス分類も可能なため、モデルトレーニング用に独自のデータセットを持ち込むことができます。
モデルトレーニング
SageMakerのビルトインPyTorch estimatorを使用して、トランスフォーマーモデルをファインチューニングします。エントリポイントスクリプト./src/hf_train_deploy.pyには、モデルトレーニング用の train() 関数があります。
スクリプトソースフォルダ./src内に必須パッケージの一覧であるrequirements.txtファイルを追加しました。SageMakerトレーニングジョブを起動すると、SageMaker PyTorchコンテナはスクリプトソースフォルダ内のrequirements.txtファイルを自動的に検索し、pip installを使用してそのファイルにリストされているパッケージをインストールします。
バッチサイズ、シーケンス長、学習率に加えて、model_nameを指定して、Hugging Face automodelForSequenceClassification の事前トレーニング済みモデルリスト内でサポートされるトランスフォーマーモデルを選択することもできます。text_columnパラメーターとlabel_columnパラメーターで指定するには、textとlabelの列名も必要です。
次のコードは、モデルトレーニングのハイパーパラメーターを設定する例です。
その後、トレーニングジョブを開始します。
モデルのデプロイ
次の前提条件関数がエントリポイントスクリプト hf_train_deploy.py 内に提供されていれば、SageMakerリアルタイム推論を使用してPyTorchトレーニング済みモデルをエンドポイントに直接デプロイできます。
model_fn(model_dir)モデルオブジェクトのロードinput_fn(request_body, request_content_type)入力テキストをロードしてトークン化predict_fn(input_data, model)各クラスの確率値を返すモデル予測
次のコードを使用して、リアルタイム推論のためにSageMakerエンドポイントにモデルをデプロイします。
モデルサービス
SageMakerエンドポイントが作成されたら、Lambdaのようなサービスを通じてリアルタイムモデル推論のためにエンドポイントを呼び出すことができます。
リアルタイムデータストリーミング用Twitter APIストリームリスナーを設定
最初のcdk deployプロセス中に、AWS CDKはアカウント内のAWS Cloud9環境をセットアップし、コードリポジトリを環境にクローンします。AWS Cloud9 を使用して、ライブデータストリーミング用のTwitter APIストリームリスナーをホストしています。
Twitter APIストリームリスナーは、次の要素で構成されます。
- stream_config.py – Twitter APIを認証するパラメーターと、検索する医薬品名の事前定義済みリスト
- stream.py – 主にストリームをアクティブに保つために使用されますが、ユーザーの共有属性の処理や、医薬品のメンションが
stream_config.pyで提供されているものと一致するかどうかの評価など、他の機能にも対応します。
次のステップはTwitter APIストリームリスナーを設定することです。Twitter開発者ポータルからコンシューマーキーと認証トークンを取得したら、stream_config.py の下のAWS Cloud9にアクセスし、次の情報を入力します。
- Twitter API 認証情報を入力します。
- 関連するツイートを取得するために、薬剤名と関心のあるルールを追加します。コードに薬剤名の例を挙げました。
aws_access_key_idとaws_secret_access_keyをそれぞれ入力します。

- AWS Cloud9ターミナルに戻り、次のコマンドを実行して必要なパッケージをインストールし、
en_core_web_smをダウンロードします。 - APIストリームリスナーをアクティブ化するには、次のコマンドを実行します (
ae-blog-cdkフォルダーにいることを確認してください)。
推論の実行とモデル予測結果のクロール
ストリームリスナーがアクティブになると、受信したツイートデータはDynamoDBテーブルae_tweets_ddbに保存されます。

Lambda関数はAmazon DynamoDB Streamsによってトリガーされ、SageMakerステップからデプロイされたモデルエンドポイントを呼び出します。この関数は、SageMakerがデプロイしたエンドポイントHF-BERT-AE-modelを通じて推論を提供し、受信したツイートを有害事象として分類します。
有害事象に分類されるすべてのツイートについて、Amazon Comprehend Medical APIを使用して、ICD-10コードと説明のリストとともに、病状の兆候、症状、診断を検出するエンティティを取得します。わかりやすくするために、最大スコアに基づいてエンティティを抽出します。ICD-10コードと説明により、より正規化された概念で症状を分類できます (詳細については、ICD-10-CM-LinkING を参照)。次のコードを参照してください。
Lambda関数はツイートを処理し、予測、関連エンティティ、ICD-10コードをS3バケットフォルダーlambda_predictionsに出力します。
AWS Glueクローラs3_tweets_crawlerは、Amazon S3で予測をクロールし、データベースs3_tweets_dbとテーブルlambda_predictionsが作成されるデータカタログにデータを入力するために作成されます。

Amazon Athenaによる表形式の処理済みデータ表示
関係者にツイートの全体像を提供するために、Athenaを使用してAmazon S3 (AWS Glue Data Catalog でリンク) の結果をクエリし、QuickSightを使用してカスタムダッシュボードを拡張して作成できます。
- Athenaを初めて使用する場合は、Amazon S3ロケーションにクエリを保存するロケーションを設定します。
- クエリエディタで、Databaseに
s3_tweets_dbを設定します。 lambda_predictionsテーブルを選択し、[テーブルをプレビュー] を選択して、処理済みのツイートの一部を生成します。

次のスクリーンショットは、特定のコンセプトに関連するツイートをプレビューするカスタムSQLコマンドです。

Amazon QuickSightでのダッシュボードの作成
QuickSightダッシュボードを構築すると、モデルから分析と推論を公開するエンドツーエンドのパイプラインを完全に完成させることができます。QuickSightの概要では、Athenaを使用してデータをインポートし、S3バケットにリンクされているAthenaデータベースとテーブルを見つけます。QuickSightを使用するときは、ユーザーのアカウントにAthenaとAmazon S3にアクセスするためのAWS Identity and Access Management (IAM)のアクセス許可があることを確認してください。
- QuickSightコンソールで、ナビゲーションペインの [データセット] を選択します。
- [新しいデータセット] を選択します。
- データソースとしてAthenaを選択します。
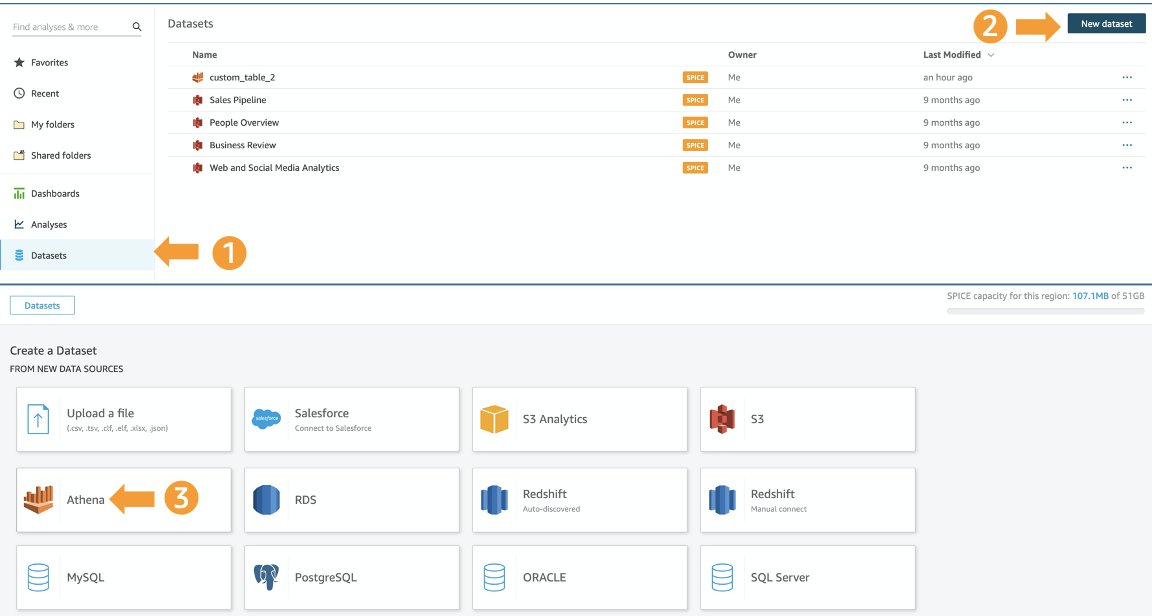
- [データソース名] に名前を入力します。
- プロンプトが表示されたら、Lambda関数で処理されたツイートを含むデータベースとテーブルを選択します。
- [カスタムSQLを使用] を選択します。

- [新しいカスタムSQL名] を
TweetsData(または任意の名前) に変更します。 - 次のSQLクエリを入力します。
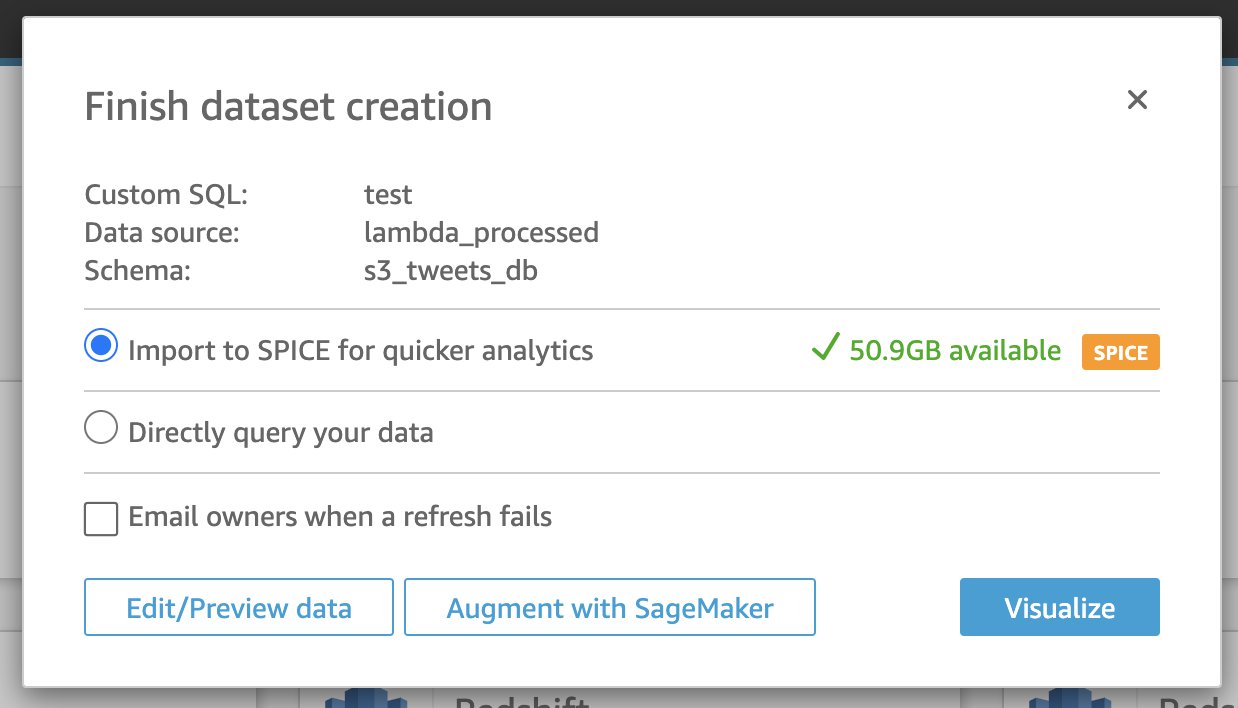
- [データの編集/プレビュー] を選択します。
- [すばやい分析のためSPICEをインポート] を選択します。
SPICE(超高速で並列のインメモリ計算エンジン) を使用してデータをインポートすることをお勧めします。インポート時に、データを編集して視覚化したり、データ列タイプを編集したり、ビジュアルに合わせて列の名前を変更したりできます。さらに、SPICEデータセットはスケジュールどおりに更新でき、データ更新による課金が発生しないように十分なSPICE容量があることを確認します。
- [視覚化] を選択します。
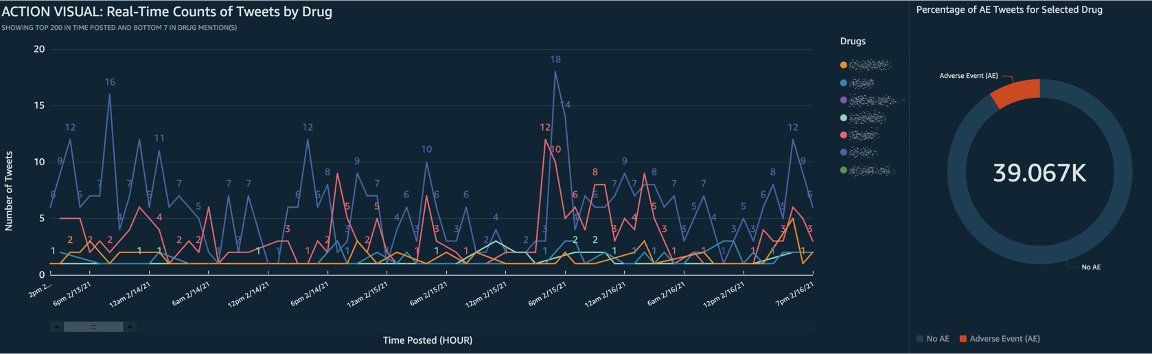
データをインポートした後は、パネルをよりインタラクティブにするために、フィルタリングやナビゲーションのためのカスタムアクションとともに、ビジュアルの形式で分析の開発を開始できます。最後に、開発したダッシュボードを公開して共有できます。次のスクリーンショットは、カスタムビジュアライゼーションの例を示しています。
クリーンアップ
AWS CDKスタックに戻って、cdk destroy —all コマンドを実行して、このチュートリアルで使用したすべてのリソースをクリーンアップできます。何らかの理由でコマンドが正常に実行されなかった場合は、AWS CloudFormationコンソールに移動して、スタックを手動で削除できます。また、この投稿のデータを使用してダッシュボードを作成した場合は、QuickSight内のデータソースと関連するダッシュボードを手動で削除します。
まとめ
新しい医薬品の開発が拡大するにつれ、関連する有害事象の数が増加しています。有害事象は、責任を持って効率的に監視および報告する必要があります。この投稿では、SageMakerを使用して分類モデルを構築およびデプロイし、Amazon Comprehend Medicalを使用してツイートを推測し、QuickSightを使用して医薬品から発生する可能性のある有害事象を検出するエンドツーエンドのソリューションについて詳しく説明しました。このソリューションは、手間のかかる手作業によるレビューを自動化された機械学習プロセスに置き換えるのに役立ちます。Amazon SageMakerの詳細については、ウェブページをご覧ください。
著者について
Prithiviraj Jothikumar, PhDは、AWS プロフェッショナルサービスのデータサイエンティストで、お客様が機械学習を使用してソリューションを構築するのを支援しています。彼は映画やスポーツを見たり、瞑想に時間を費やすことを楽しんでいます。
Jason Zhuは、AWS プロフェッショナルサービスのシニアデータサイエンティストで、顧客向けのエンタープライズレベルの機械学習アプリケーションの構築を主導しています。余暇には、屋外にいて、料理人としての能力を伸ばすことを楽しんでいます。
Rosa Sunは、アマゾンウェブサービスのプロフェッショナルサービスコンサルタントです。仕事以外では、雨の中を歩いたり、ポートレートを描いたり、犬を抱き締めることを楽しんでいます。
Sai Sharanya Nalla は AWS プロフェッショナルサービスのデータサイエンティストです。彼女はお客様と協力して、AWSでAIおよびMLソリューションを開発し、実装しています。余暇には、ポッドキャストやオーディオブックを聴いたり、長い散歩をしたり、アウトリーチ活動に従事したりしています。
Shuai Caoは、アマゾンウェブサービスのプロフェッショナルサービスチームのデータサイエンティストです。彼の専門知識は、ヘルスケアおよびライフサイエンスのお客様向けに大規模な機械学習アプリケーションを構築することです。仕事以外では、世界中を旅して何十種類もの楽器を演奏するのが大好きです。
翻訳はIndustry Solutions Architectの松永が担当しました。原文はこちらです。