Amazon Web Services ブログ
Amazon CloudFront ログを使用したリアルタイムダッシュボードの作成
Amazon CloudFront は AWS グローバルネットワークを使用して、静的および動的なウェブコンテンツを低レイテンシかつ高速で安全に配信するコンテンツ配信ネットワーク (CDN) です。
この度 CloudFront でリアルタイムに利用可能な、デリバリーログを配信する機能が発表されました。このリアルタイムログには、CloudFront が受け取った全てのリクエストに関する詳細情報が含まれます。詳細な情報をリアルタイムで確認することで、運用イベントに迅速に対応できるようになります。
リアルタイムログでは、収集する情報とその配信先をカスタマイズできます。リアルタイムログは Amazon Kinesis Data Streams と統合されており、Amazon Kinesis Data Firehose を使用して一般的な HTTP エンドポイントにログを配信できます。
Amazon Kinesis Data Firehose では Amazon S3、Amazon Redshift、Amazon Elasticsearch Service (Amazon ES)、および Datadog、New Relic、Splunk などのサービスプロバイダにログを配信できます。このログを使用して、リアルタイムダッシュボードの作成、アラートの設定、異常の調査や運用イベントへの迅速な対応を行うことができます。追跡できる一般的なデータポイントとしては、異なる地理的リージョンからのビューアーリクエスト数や、レイテンシが高いユニークビューアー数などがあります。
本ブログでは CloudFront リアルタイムログと Amazon Elasticsearch Service (Amazon ES) を使用して運用ダッシュボードを作成する方法を紹介します。このアーキテクチャでは、Kinesis Data Firehose を Kinesis Data Stream のコンシューマーとして設定する方法、Kinesis Firehose 内で Lambda 関数を使用してログを処理したり、ログ形式を更新する方法について説明します。また Kinesis Firehose が Elasticsearch にデータを配信できない場合のバックアップ先として S3 バケットを設定する方法も示します。その後、承認されたユーザーで Kibana インターフェイスにログインし、リアルタイムログからダッシュボードを構築して、運用上の問題に対処できるようにします。

以下のステップに従って、このログパイプラインを設定できます。
リージョンはバージニア北部リージョンを想定しておりますが、他のリージョンで構築される場合は各サービスのクォータにご注意ください。
ステップ 1: Kinesis Data Stream のプロビジョニング
1) Amazon Kinesis コンソールに移動し、Data streams を選択して、Create data stream をクリックします。

2) 次のページで、Data stream name に cloudfront-real-time-log-data-stream と名前を付け、Number of open shards に 200 を入力します。
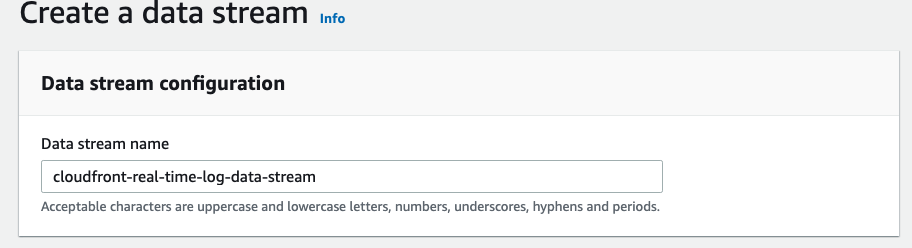

3) Create Data Stream をクリックします。
4) Kinesis Data Stream をプロビジョニングした後、必要に応じて Data retention period(データ保持期間)を長くすることもできます。デフォルトは 24 時間で、168 時間に延ばすことができます。Enhanced(シャードレベル)メトリクスを有効にするオプションもあります。
ステップ 2: CloudFront ディストリビューションでリアルタイムログを有効にする
最初に CloudFront ディストリビューションを作成する必要があります。こちらの CloudFormation テンプレート を使用すると、ディストリビューションをすばやく作成できます。ディストリビューションでリアルタイムログを有効にするには、CloudFront 側で設定をする必要があります。ログ設定はディストリビューションの作成または更新中に作成するか、CloudFront コンソールの Logs セクションの Real-time log configuration で設定を作成できます。
全てのフィールドをデフォルト設定のままにし、サンプリングレートをデフォルトの 100 のままにします。サンプリングレートを設定することで、設定した割合のログレコードを受け取ることができます。例えば、トラフィック量が多く全てのログデータを処理したくない場合があります。この場合はハイレベルの傾向分析を行うために、ログ全体に対して必要な割合をサンプリングすることを選択できます。
リアルタイムログの転送先 Endpoint には、前のステップで作成した cloudfront-real-time-log-data-stream という名前の Kinesis Data Stream の ARN を指定します。Distribution のセクションでログを生成したい CloudFront distribution と Cache Behavior(s) を選択します。
既存のディストリビューションで Cache Behavior を編集または作成するとき、または新しいディストリビューションを作成するときに、リアルタイムログ設定をアタッチできます。次の例では Cache Behavior を編集する際に、リアルタイムログ設定をアタッチできることが分かります。Create new configuration ボタンをクリックすると、上に示したリアルタイムログ設定セクションにリダイレクトされます。


ステップ 3: Elasticsearch に配信する前に Kinesis Firehose でレコードを処理する Lambda 関数をプロビジョニングする
1) AWS Lambda コンソールに移動し Create function をクリックします。
2) Author from scratch を選択します。
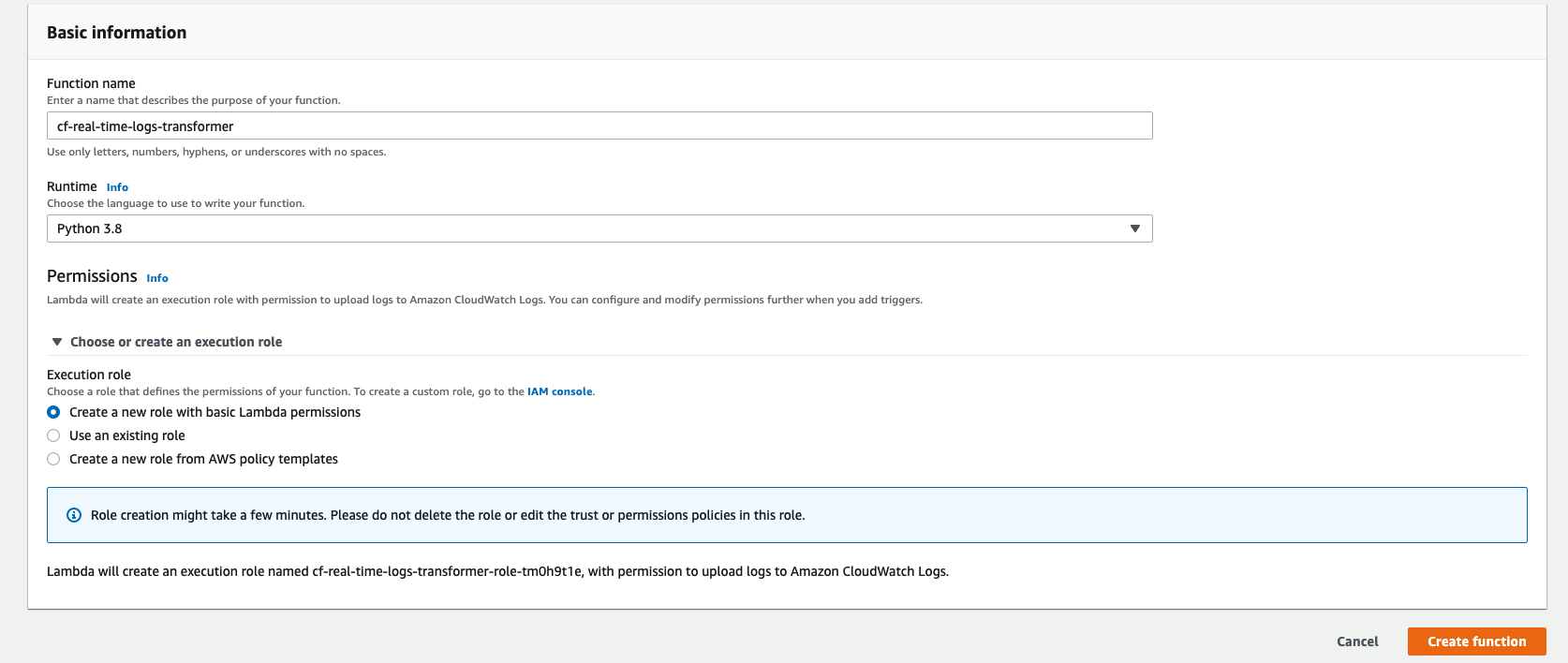
3) Basic information セクションで、以下の操作を行います。
a) 関数の名前として cf-real-time-logs-transformer を使用します。
b) Runtime として Python 3.8 を選択します。
4) Permissions セクションで次の操作を行います。
a) Create a new role with basic Lambda permissions を Execution role として選択します。
5) Create function をクリックします。
6) 上記のステップから Lambda 関数が作成され、関数の Configuration タブが開きます。
7) Function code セクションで、デフォルトで生成されたコードを次のコードに上書きします。
import base64
import json
print("Loading function")
def lambda_handler(event, context):
output = []
# Based on the fields chosen during the creation of the
# Real-time log configuration.
# The order is important and please adjust the function if you have removed
# certain default fields from the configuration.
realtimelog_fields_dict = {
"timestamp": "float",
"c-ip": "str",
"time-to-first-byte": "float",
"sc-status": "int",
"sc-bytes": "int",
"cs-method": "str",
"cs-protocol": "str",
"cs-host": "str",
"cs-uri-stem": "str",
"cs-bytes": "int",
"x-edge-location": "str",
"x-edge-request-id": "str",
"x-host-header": "str",
"time-taken": "float",
"cs-protocol-version": "str",
"c-ip-version": "str",
"cs-user-agent": "str",
"cs-referer": "str",
"cs-cookie": "str",
"cs-uri-query": "str",
"x-edge-response-result-type": "str",
"x-forwarded-for": "str",
"ssl-protocol": "str",
"ssl-cipher": "str",
"x-edge-result-type": "str",
"fle-encrypted-fields": "str",
"fle-status": "str",
"sc-content-type": "str",
"sc-content-len": "int",
"sc-range-start": "int",
"sc-range-end": "int",
"c-port": "int",
"x-edge-detailed-result-type": "str",
"c-country": "str",
"cs-accept-encoding": "str",
"cs-accept": "str",
"cache-behavior-path-pattern": "str",
"cs-headers": "str",
"cs-header-names": "str",
"cs-headers-count": "int",
}
for record in event["records"]:
# Extracting the record data in bytes and base64 decoding it
payload_in_bytes = base64.b64decode(record["data"])
# Converting the bytes payload to string
payload = "".join(map(chr, payload_in_bytes))
# dictionary where all the field and record value pairing will end up
payload_dict = {}
# counter to iterate over the record fields
counter = 0
# generate list from the tab-delimited log entry
payload_list = payload.strip().split("\t")
# perform the field, value pairing and any necessary type casting.
# possible types are: int, float and str (default)
for field, field_type in realtimelog_fields_dict.items():
# overwrite field_type if absent or '-'
if payload_list[counter].strip() == "-":
field_type = "str"
if field_type == "int":
payload_dict[field] = int(payload_list[counter].strip())
elif field_type == "float":
payload_dict[field] = float(payload_list[counter].strip())
else:
payload_dict[field] = payload_list[counter].strip()
counter = counter + 1
# JSON version of the dictionary type
payload_json = json.dumps(payload_dict)
# Preparing JSON payload to push back to Firehose
payload_json_ascii = payload_json.encode("ascii")
output_record = {
"recordId": record["recordId"],
"result": "Ok",
"data": base64.b64encode(payload_json_ascii).decode("utf-8"),
}
output.append(output_record)
print("Successfully processed {} records.".format(len(event["records"])))
return {"records": output}8) Basic settings セクションで、Edit ボタンをクリックして Timeout の値をデフォルトの 3 秒から 1 分に伸ばし、画面の一番上にある Save ボタンをクリックして関数を保存します。
ステップ 4: Kinesis Firehose の送信先として Elasticsearch とバックアップ S3 バケットをプロビジョニングする
1) Elasticsearch Service コンソールで Create a new domain をクリックします。
2) 画面(Step 1: Choose deployment type)の Choose deployment type セクションで、Development and testing を選択します。
3) Version セクションの Elasticsearch バージョンをデフォルト(latest)のままにしておきます。
4) Next をクリックします。

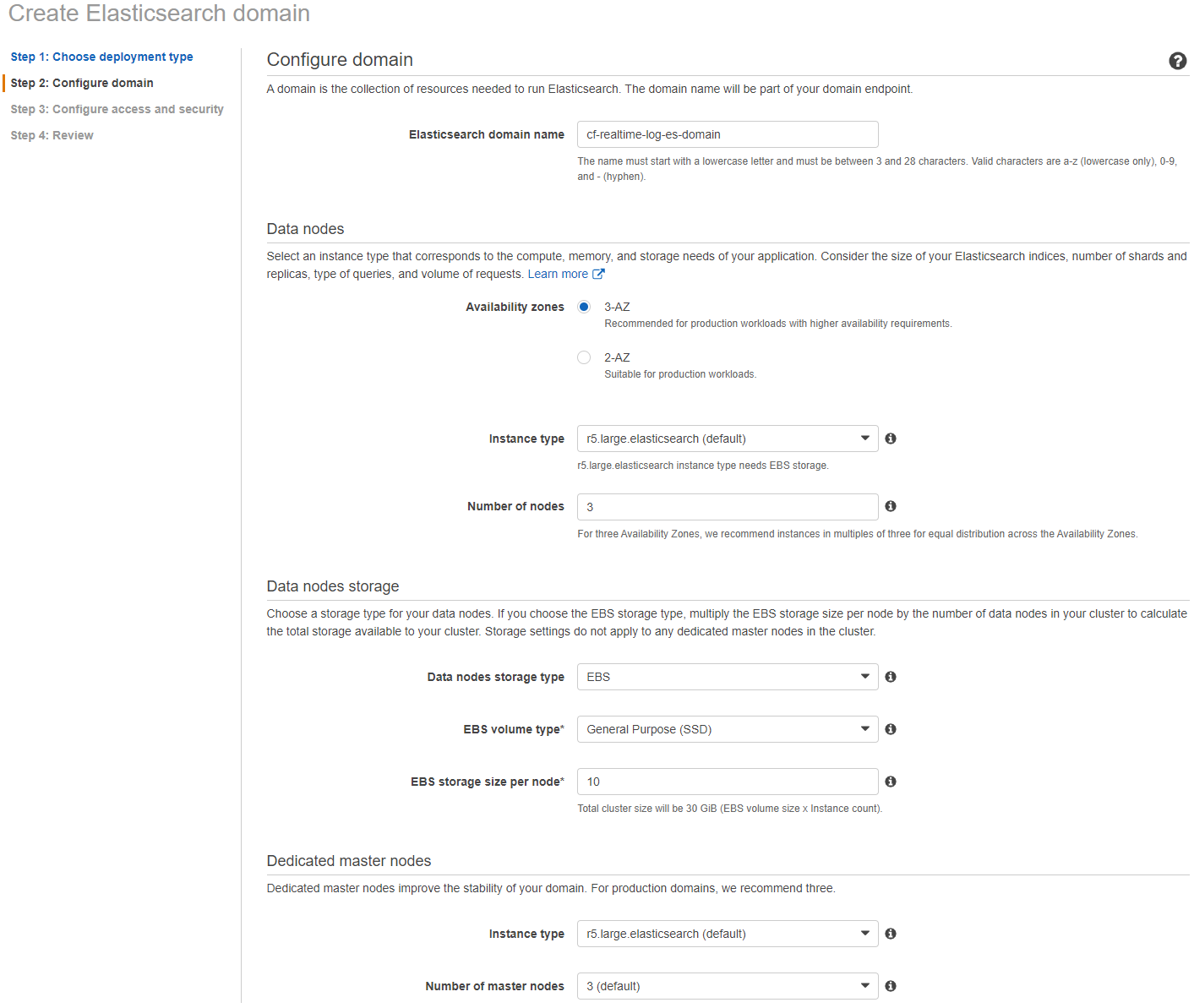
5) 次の画面(Step 2: Configure domain)で以下の操作を行います。
a) Configure domain セクションで、Elasticsearch ドメイン名を cf-realtime-log-es-domain とします。
b) Data nodes セクションの Instance type と Number of nodes はデフォルト設定のままにしておきます。
c) Data nodes storage セクションと Dedicated master nodes セクションもデフォルト設定のままにしておきます。
d) Next をクリックします。
6) 次の画面(Step 3: Configure access and identity)で以下の操作を行います。
a) Network configuration で Public access を選択します。
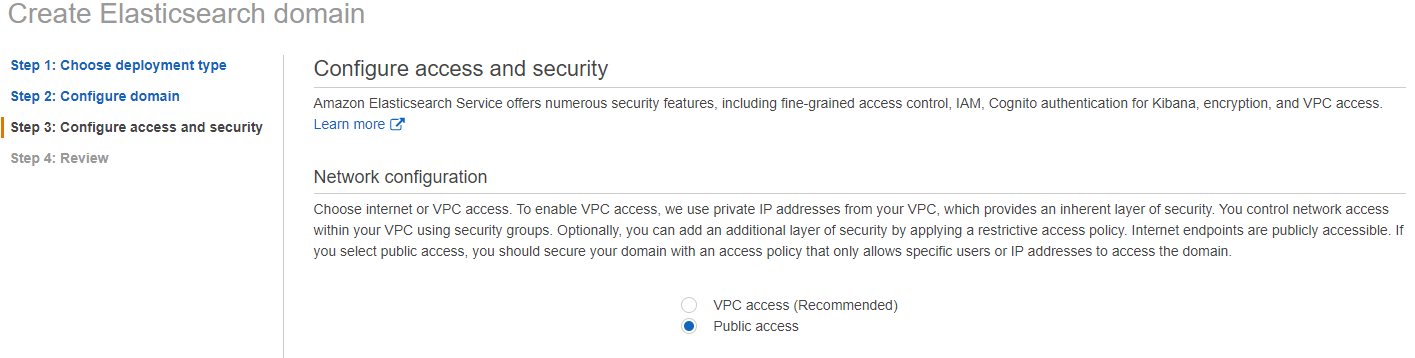
b) Fine-grained access control-powered by Open Distro for Elasticsearch セクションで、Enable fine-grained access control にチェックを入れます。また Create master user を選択し Master username、Master password、Confirm master password フィールドに入力します。
(重要: Kibana ダッシュボードにアクセスするために、必ず認証情報を保存してください)

c) Access policy セクションで Domain access policy の Allow open access to the domain を選択します。

d) 同じ画面(Step 3: Configure access and identity)の他の設定をデフォルトのままにして、Next をクリックします。
7) 次の画面(Step 4: Review)で、設定を再確認し Confirm をクリックします。
8) Elasticsearch のプロビジョニングにはおおよそ 10 分ほどかかります。ドメインが Active になったら Kinesis Firehose のプロビジョニングに進みます。

9) Kinesis Data Stream および Elasticsearch クラスタと同じリージョンにバックアップ用の S3 バケットを作成してください。Kinesis Firehose が Elasticsearch クラスタにログを配信できない場合、このバケットをレコードのバックアップ先とします。
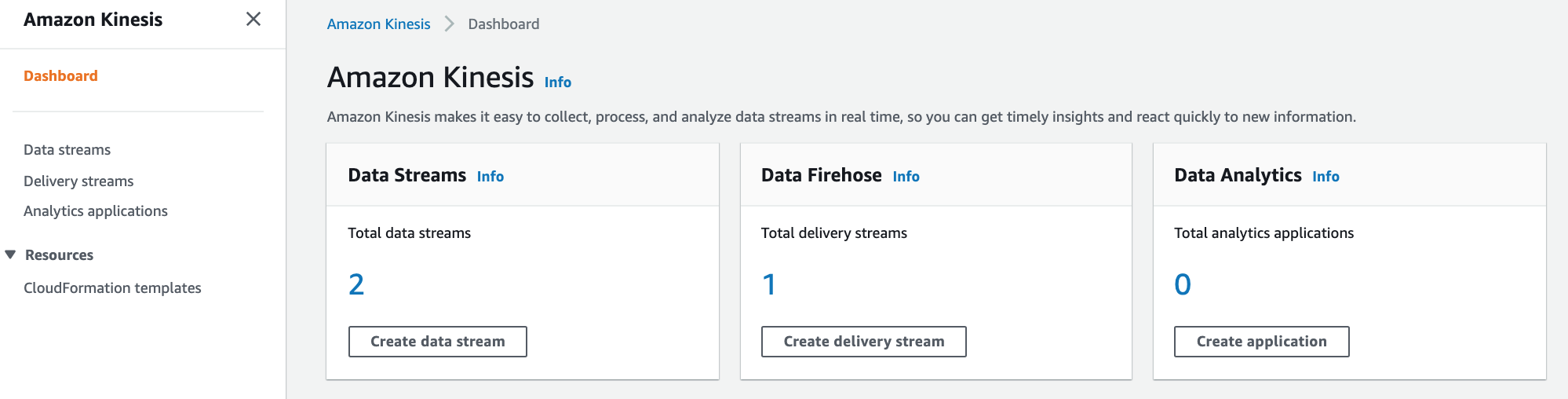
ステップ 5: 分析パイプラインをセットアップするため Kinesis Data Firehose をプロビジョニングする
1) Kinesis コンソールの Dashboard で、Create delivery stream をクリックします。
2) 次の画面(Step 1: Name and source)で以下の操作を行います。
a) New delivery stream セクションで、Delivery stream name を cloudfront-real-time-log-data-kinesis-firehose-consumer とします。

b) Choose a source セクションで Kinesis Data Stream を選択し、cloudfront-real-time-log-data-stream を Kinesis data stream から選択します(前のステップ 1 でプロビジョニングしたものです)。
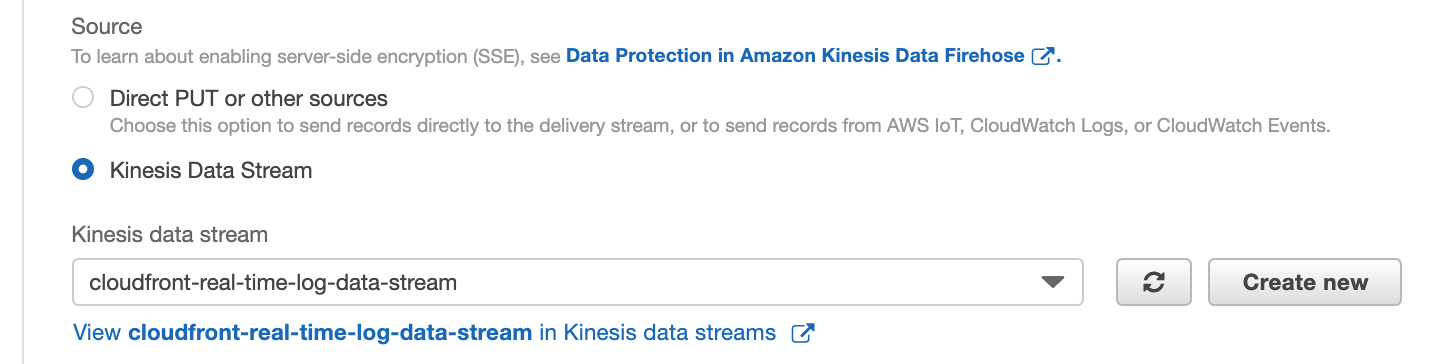
c) Next をクリックします。
3) 次の画面(Step 2: Process record)の Transform source records with AWS Lambda セクションで以下の操作を行います。
a) Data transformation にて Enabled を選択します。
b) ステップ 3 で作成した Lambda 関数 cf-real-time-logs-transformer を選択します。
c) Next をクリックします。

4) 次の画面(Step 3: Choose a destination)で以下の操作を行います。
a) Choose a destination セクションで、Amazon Elasticsearch を選択します。

b) Amazon Elasticsearch Service destination セクションで、次の操作を行います。
i) Domain として cf-realtime-log-es-domain を選択します。
ii) Index に realtime と入力します。

c) S3 backup セクションで Failed records only を選択し、ステップ 4 で作成したバックアップ用の S3 バケットを選択します。

d) Next をクリックします。
5) 次の画面(Step 4: Configure settings)で、すべての設定をデフォルトのままにして Next をクリックします。
(Permissions セクションには、Kinesis Firehose が他のサービスとやり取りする時に引き受ける IAM ロールが作成されます。このロールの ARN の例は以下のようになります: arn:aws:iam::111222333444:role/service-role/KinesisFirehoseServiceRole-cloudfront-re-us-west-2-111222333444)
6) 次の画面(Step 5: Review)で、設定を再確認し Create delivery stream をクリックします。Kinesis Data Firehose リソースが配置されたら、次のステップに進みましょう。
ステップ 6: Elasticsearch にプッシュするため Kinesis Data Firehose サービスロールを登録する
上記のステップ 4 (6)(b) で Elasticsearch ドメインのアクセスコントロールのために設定したマスターユーザー名とパスワードを使用して、Kibana ダッシュボードにアクセスし、Kinesis Data Firehose に設定したサービスロールで Elasticsearch にインデックスを作成して、データを書き込むために必要な設定変更を実施します。以下に手順を示します。
1) Kibana に移動します(URL は Amazon Elasticsearch Service コンソールにあります)。
ステップ 4 でプロビジョニングされた Elasticsearch ドメインのコンソールで、Kibana フィールドの右にある URL を選択します。
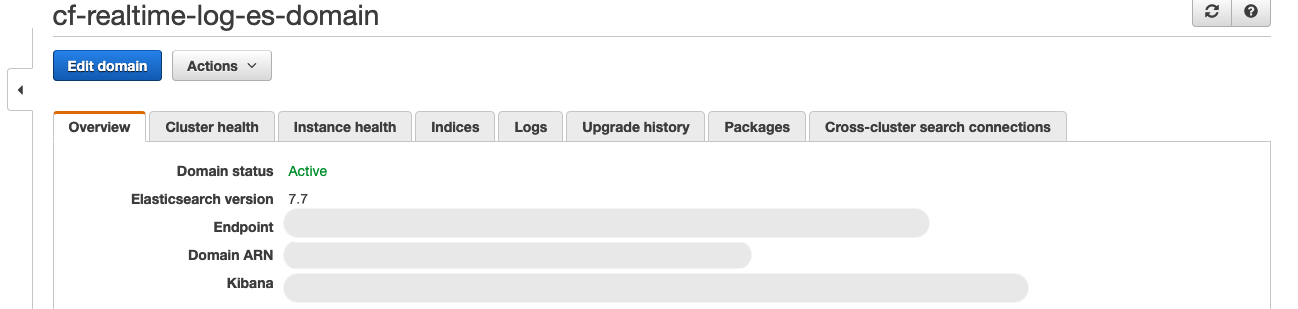
2) Amazon Elasticsearch Service エンドポイントの作成時にセットアップした、マスターユーザー名とパスワードを入力して Kibana にログインします。
3) Security で Roles を選択します。


4) + アイコンをクリックして、新しいロールを追加します。
a) ロールに名前を付けます。例 : firehose-role
b) Cluster Permissions タブの Cluster-wide permissions で、Action Groups をクリックして cluster_composite_ops および cluster_monitor を追加します。

c) Index Permissions タブで、Add index permissions をクリックします。
d) Index Patterns を選択し、realtime* と入力します。
e) Permissions: Action Groups で 3 つのアクショングループ crud, create_index および manage を追加します。
f) Save Role Definition をクリックします。
5) 次のステップでは、Kinesis Data Firehose が使用する IAM ロールを、先ほど作成したロールにマッピングします。
a) Security で Role Mappings を選択します。+ ボタンを押します。
b) 先ほど作成した firehose-role を選択します。
c) Backend roles に、Kinesis Data Firehose が Amazon ES および S3 に書き込むために使用する IAM ロールの ARN を入力します。
arn:aws:iam::<aws_account_id>:role/service-role/<KinesisFirehoseServiceRole>
これは、ステップ 5 で Kinesis Data Firehose リソースを作成するときに作成された IAM サービスロールの ARN と同じです。
例:(arn:aws:iam::111222333444:role/service-role/KinesisFirehoseServiceRole-cloudfront-re-us-east-1-111222333444)
d) Submit をクリックします。
ステップ 7: Amazon ES でダッシュボードを構築する
Amazon ES を使用してデータの傾向を観察し、複数のグラフをダッシュボードに組み込むことができます。例えば、様々な地理的リージョンから送信されたリクエストの数を確認することができます。
1) Kibana ダッシュボードの Visualize セクションに移動し、新しい Visualization を作成します。生成したい Visualization のタイプを指定します。例えば Region Map を選択すると下記のマップを作成できます。
Kibana で作成した Index Pattern を指定します。Metrics の下の Aggregation で Count を選択し、Bucket の Aggregation に Terms、Field に c-country.keyword を指定します。左上の Save ボタンをクリックすると、タイトルを指定して Visualization を保存することができます。

2) もう 1 つの例として、どのリージョンのビューアーで最もレイテンシが発生しているかを確認したい場合、棒グラフで Visualization を作成し、追跡したい値の範囲を設定できます。この例では time-taken フィールドに範囲を設定し、国ごとのリクエスト数を調べています。

3) Visualizations を組み合わせて、運用イベントに関する関連情報を集めたダッシュボードに組み込むことができます。Kibana メインページで Dashboard オプションを選択します。Create new dashboard のオプションが表示されます。

4) 先ほど作成した既存の Visualizations をダッシュボードに Add します。
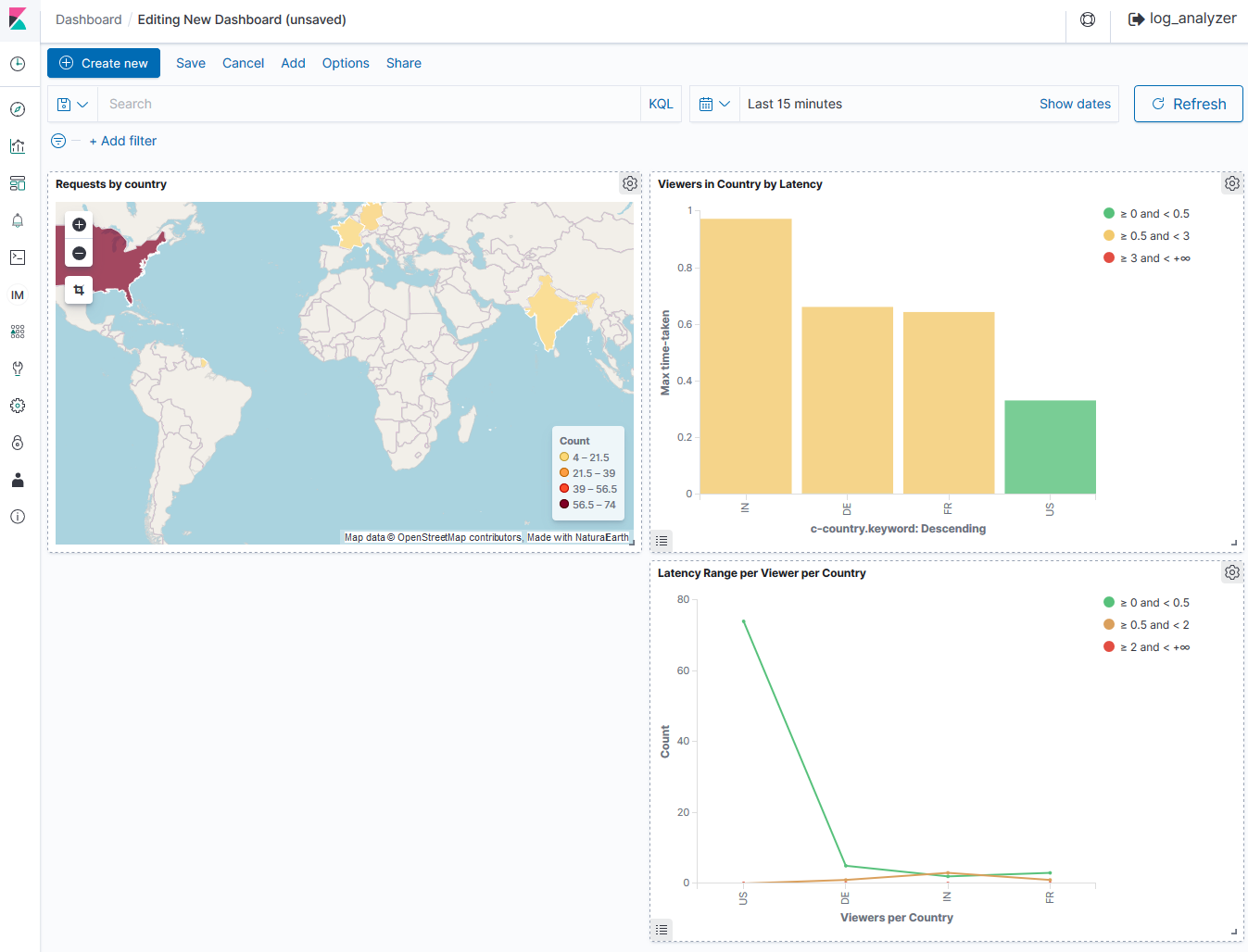
5) 下記のサンプルダッシュボードでは、国ごとのリクエスト、ビューアーに高いレイテンシが発生している国、指定したレイテンシ範囲内の国ごとのビューアー数など、様々なディメンションに焦点を当てた複数の Visualizations を適用しています。
まとめ
このブログでは、CloudFront と Amazon ES を使用して、リアルタイムのログストリーミングとダッシュボードソリューションを設定しました。リアルタイムログの機能によって、ウェブアプリケーションへのリクエストをすばやく分析できます。CloudFront ログの送信先として Amazon ES を使用する方法と、Kibana で可視化をする方法について説明しました。Kibana でリアルタイムの運用ダッシュボードを作成して、詳細なログデータを分析できます。CloudFront リアルタイムログの詳細については、 CloudFront 開発者ガイド をご覧ください。
著者について
 Mohammad Shafiullah は、AWS のシニアクラウドサポートエンジニアです。M&E セクターのテクノロジーに強い関心を持ち、CDN、ストリーミング、OTT サービス、サーバーレステクノロジーを専門としています。企業のお客様の抱える複雑な問題の根本原因を、時間をかけて調査しています。また、常に新しいテクノロジーについて学び、お客様が包括的なソリューションを構築できるようサポートしています。仕事以外では、映画を見たり、本を読んだりするのが好きですが、家族と過ごす時間を最も大切にしています。
Mohammad Shafiullah は、AWS のシニアクラウドサポートエンジニアです。M&E セクターのテクノロジーに強い関心を持ち、CDN、ストリーミング、OTT サービス、サーバーレステクノロジーを専門としています。企業のお客様の抱える複雑な問題の根本原因を、時間をかけて調査しています。また、常に新しいテクノロジーについて学び、お客様が包括的なソリューションを構築できるようサポートしています。仕事以外では、映画を見たり、本を読んだりするのが好きですが、家族と過ごす時間を最も大切にしています。
 Samrat Karak は、シアトルに拠点を置く Amazon CloudFront チームのシニアプロダクトマネージャーです。お客様の様々なユースケースを理解し、Lambda@Edge を使用したサーバーレスコンピューティングおよび製品機能を使用してそれらのユースケースを解決することに情熱を注いでいます。Samrat は、エンタープライズソリューションと AWS での製品開発とマネージメントに 13 年以上の経験があります。
Samrat Karak は、シアトルに拠点を置く Amazon CloudFront チームのシニアプロダクトマネージャーです。お客様の様々なユースケースを理解し、Lambda@Edge を使用したサーバーレスコンピューティングおよび製品機能を使用してそれらのユースケースを解決することに情熱を注いでいます。Samrat は、エンタープライズソリューションと AWS での製品開発とマネージメントに 13 年以上の経験があります。
翻訳は Solutions Architect 森 啓 が担当しました。原文はこちらです。