この記事は、「Implement model-independent safety measures with Amazon Bedrock Guardrails」を翻訳したものとなります。
生成 AI モデルは幅広いトピックに関する情報を生成できますが、その応用には新たな課題があります。これには関連性の維持、有害なコンテンツの回避、個人を特定できる情報(PII)などの機密情報の保護、ハルシネーション(幻覚)の軽減が含まれます。Amazon Bedrock の基盤モデル(FM)には組み込みの保護機能がありますが、これらはモデル固有であることが多く、組織のユースケースや責任ある AI の原則に完全に合致しない可能性があります。その結果、開発者は多くの場合、追加のカスタマイズされた安全性とプライバシーの制御を実装する必要があります。このニーズは、組織が複数の FM を異なるユースケースで使用する場合により顕著になります。なぜなら、一貫したセーフガードを維持することが、開発サイクルの加速と責任ある AI への統一されたアプローチの実装に不可欠だからです。
2024 年 4 月、私たちは Amazon Bedrock Guardrails の一般提供を発表しました。これはセーフガードの導入、有害なコンテンツの防止、主要な安全性基準に対するモデルの評価を支援するものです。Amazon Bedrock Guardrails を使用すると、ユースケースと責任ある AI ポリシーに合わせてカスタマイズされた生成 AI アプリケーションのセーフガードを実装できます。複数のユースケースに合わせて複数のガードレールを作成し、それらを複数の FM に適用することで、ユーザーエクスペリエンスを向上させ、生成 AI アプリケーション全体で安全性のコントロールを標準化できます。
さらに、異なる FM を使用するアプリケーションの保護を可能にするために、Amazon Bedrock Guardrails は現在、Amazon Bedrock 外で利用可能なカスタムおよびサードパーティの FM のユーザー入力とモデル応答を評価するための ApplyGuardrail API をサポートしています。この記事では、サードパーティまたはセルフホスト型の大規模言語モデル(LLM)、あるいはセルフホスト型の検索拡張生成(RAG)アーキテクチャなど、一般的な生成 AI アーキテクチャで ApplyGuardrail API を使用する方法について説明します。
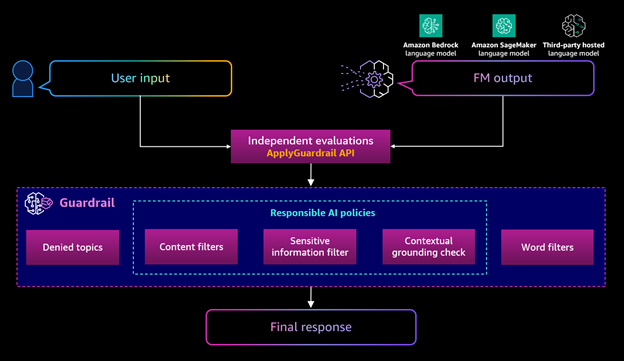
ソリューションの概要
この記事では、FM が受託者向けのアドバイスを提供しないようにするガードレールを作成します。ガードレールの完全な設定リストは GitHub リポジトリをご覧ください。必要に応じてコードを変更できます。
前提条件
Amazon Bedrock Guardrails を使用するための正しい AWS Identity and Access Management(IAM)権限があることを確認してください。手順については、「コンテンツフィルタリングにガードレールを使用するアクセス許可を設定する」を参照してください。
さらに、このウォークスルーで使用するサードパーティまたはセルフホスト型の LLM へのアクセス権が必要です。この記事では、Amazon SageMaker JumpStart の Meta Llama 3 モデルを使用します。詳細については、「SageMaker プロジェクトと JumpStart の AWS 管理ポリシー」を参照してください。
Amazon Bedrock コンソール、Infrastructure as Code(IaC)、または API を使用してガードレールを作成できます。ガードレールを作成するためのサンプルコードについては、GitHub リポジトリを参照してください。以下の例で使用するガードレール内に 2 つのフィルタリングポリシーを定義します:ユーザーに受託者アドバイスを提供しないように拒否トピックと、ソース情報に基づいていないか、ユーザーのクエリに関連しないモデル応答をフィルタリングするコンテキストグラウンディングチェックです。ガードレールのさまざまなコンポーネントの詳細については、「ガードレールのコンポーネント」を参照してください。先に進む前にガードレールを作成したことを確認してください。
ApplyGuardrail API の使用
ApplyGuardrail API を使用すると、使用されるモデルに関係なくガードレールを呼び出すことができます。ガードレールは text パラメータに適用されます。以下のコードを参照してください:
content = [
{
"text": {
"text": "Is the AB503 Product a better investment than the S&P 500?"
}
}
]
この例では、ユーザーからの入力全体にガードレールを適用します。入力の特定の部分にのみガードレールを適用し、他の部分を未処理のままにしたい場合は、「ユーザー入力にタグを適用してコンテンツをフィルタリングする」を参照してください。
Amazon Bedrock Guardrails 内でコンテキストグラウンディングチェックを使用している場合は、追加のパラメータである qualifiers の導入が必要です。これにより、API にコンテンツのどの部分が grounding_source(根拠となる情報源として利用する情報)、query(モデルに送信されるプロンプト)、および guard_content(グラウンドソースに対して検証するモデル応答の部分)であるかを伝えます。コンテキストグラウンディングチェックは出力にのみ適用され、入力には適用されません。以下のコードを参照してください:
content = [
{
"text": {
"text": "The AB503 Financial Product is currently offering a non-guaranteed rate of 7%",
"qualifiers": ["grounding_source"],
}
},
{
"text": {
"text": "What’s the Guaranteed return rate of your AB503 Product",
"qualifiers": ["query"],
}
},
{
"text": {
"text": "Our Guaranteed Rate is 7%",
"qualifiers": ["guard_content"],
}
},
]
最後に必要なコンポーネントは、使用するガードレールの guardrailIdentifier と guardrailVersion、およびテキストがモデルへのプロンプトかモデルからの応答かを示す source です。これは以下のコードで Boto3 を使用して示されています。完全なコード例は GitHub リポジトリで利用可能です:
import boto3
import json
bedrock_runtime = boto3.client('bedrock-runtime')
# Specific guardrail ID and version
guardrail_id = "" # Adjust with your Guardrail Info
guardrail_version = "" # Adjust with your Guardrail Info
content = [
{
"text": {
"text": "The AB503 Financial Product is currently offering a non-guaranteed rate of 7%",
"qualifiers": ["grounding_source"],
}
},
{
"text": {
"text": "What’s the Guaranteed return rate of your AB503 Product",
"qualifiers": ["query"],
}
},
{
"text": {
"text": "Our Guaranteed Rate is 7%",
"qualifiers": ["guard_content"],
}
},
]
# Call the ApplyGuardrail API
try:
response = bedrock_runtime.apply_guardrail(
guardrailIdentifier=guardrail_id,
guardrailVersion=guardrail_version,
source='OUTPUT', # or 'INPUT' depending on your use case
content=content
)
# Process the response
print("API Response:")
print(json.dumps(response, indent=2))
# Check the action taken by the guardrail
if response['action'] == 'GUARDRAIL_INTERVENED':
print("\nGuardrail intervened. Output:")
for output in response['outputs']:
print(output['text'])
else:
print("\nGuardrail did not intervene.")
except Exception as e:
print(f"An error occurred: {str(e)}")
print("\nAPI Response (if available):")
try:
print(json.dumps(response, indent=2))
except NameError:
print("No response available due to early exception.")
API の応答は以下の詳細を提供します:
- ガードレールが介入したかどうか
- ガードレールが介入した理由
- リクエストに使用されたテキストユニット(Amazon Bedrock Guardrails の完全な価格詳細については、Amazon Bedrock の料金を参照してください)
以下の応答は、拒否トピックによってガードレールが介入したことを示しています:
"usage": {
"topicPolicyUnits": 1,
"contentPolicyUnits": 1,
"wordPolicyUnits": 1,
"sensitiveInformationPolicyUnits": 1,
"sensitiveInformationPolicyFreeUnits": 0,
"contextualGroundingPolicyUnits": 0
},
"action": "GUARDRAIL_INTERVENED",
"outputs": [
{
"text": "I can provide general info about Acme Financial's products and services, but can't fully address your request here. For personalized help or detailed questions, please contact our customer service team directly. For security reasons, avoid sharing sensitive information through this channel. If you have a general product question, feel free to ask without including personal details. "
}
],
"assessments": [
{
"topicPolicy": {
"topics": [
{
"name": "Fiduciary Advice",
"type": "DENY",
"action": "BLOCKED"
}
]
}
}
]
}
以下の応答は、コンテキストグラウンディングチェックによってガードレールが介入したことを示しています:
"usage": {
"topicPolicyUnits": 1,
"contentPolicyUnits": 1,
"wordPolicyUnits": 1,
"sensitiveInformationPolicyUnits": 1,
"sensitiveInformationPolicyFreeUnits": 1,
"contextualGroundingPolicyUnits": 1
},
"action": "GUARDRAIL_INTERVENED",
"outputs": [
{
"text": "I can provide general info about Acme Financial's products and services, but can't fully address your request here. For personalized help or detailed questions, please contact our customer service team directly. For security reasons, avoid sharing sensitive information through this channel. If you have a general product question, feel free to ask without including personal details. "
}
],
"assessments": [
{
"contextualGroundingPolicy": {
"filters": [
{
"type": "GROUNDING",
"threshold": 0.75,
"score": 0.38,
"action": "BLOCKED"
},
{
"type": "RELEVANCE",
"threshold": 0.75,
"score": 0.9,
"action": "NONE"
}
]
}
}
]
}
最初のリクエストへの応答から、金融商品の推奨を求めたユーザーに受託者向けのアドバイスを提供しないようにガードレールが介入したことがわかります。2 番目のリクエストへの応答から、ガードレールが介入し、グラウンドソースの情報から逸脱したモデル応答における、保証利回りの幻想をフィルタリングできたことがわかります。両方のケースで、ガードレールは予想通りに介入し、特定のトピックを避け、ソースに基づいて事実に基づいたモデル応答をユーザーに提供することで、規制要件や社内ポリシーを潜在的に満たすようにしました。
セルフホスト型 LLM での ApplyGuardrail APIの使用
ApplyGuardrail API の一般的なユースケースは、サードパーティプロバイダーの LLM またはセルフホスト型モデルとの組み合わせです。この組み合わせにより、リクエストの入力または出力にガードレールを適用できます。
一般的なフローには以下のステップが含まれます:
- モデルの入力を受け取ります。
ApplyGuardrail API を使用して、この入力にガードレールを適用します。- 入力がガードレールを通過した場合、推論のためにモデルに送信します。
- モデルからの出力を受け取ります。
- 出力にガードレールを適用します。
- 出力がガードレールを通過した場合、最終出力を返します。
- 入力または出力のいずれかがガードレールによって介入された場合、入力または出力からの介入を示す、事前定義されたメッセージを返します。
このワークフローは以下の図で示されています。
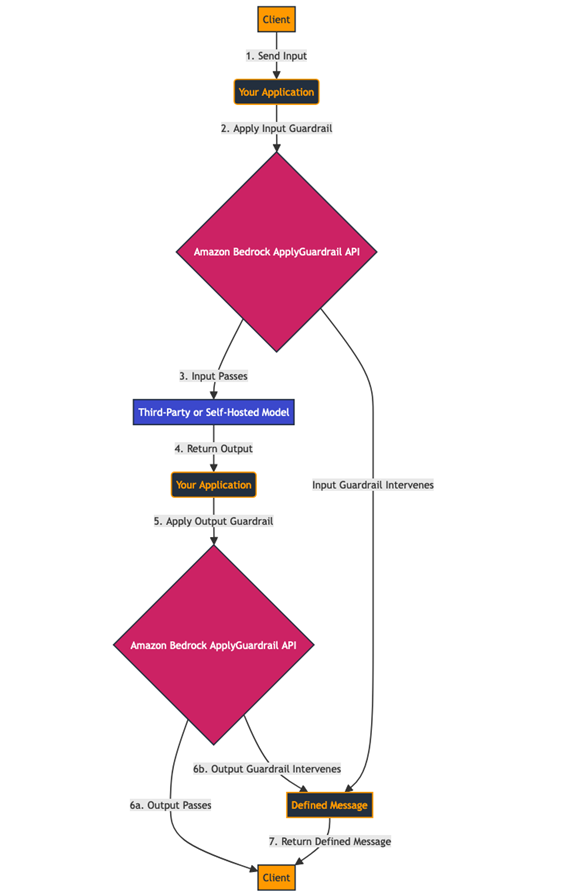
ワークフローの実装を見るには、提供されたコードのサンプルを参照してください。
私たちは Amazon SageMaker エンドポイントでホストされている Meta-Llama-3-8B モデルを使用します。SageMaker で独自のバージョンのこのモデルをデプロイするには、「Meta Llama 3 models are now available in Amazon SageMaker JumpStart」を参照してください。
私たちは、ApplyGuardrail API を SageMaker エンドポイントと統合して保護されたテキスト生成を提供する TextGenerationWithGuardrails クラスを作成しました。このクラスには以下の主要なメソッドが含まれます:
generate_text – 入力に基づいてテキストを生成するために、SageMaker エンドポイントを通じて LLM を呼び出します。analyze_text – ApplyGuardrail API を使用してガードレールを適用するコアメソッドです。API 応答を解釈して、ガードレールを通過したか介入されたかを判断します。analyze_prompt と analyze_output – これらのメソッドは analyze_text を使用して、入力プロンプトと生成された出力にそれぞれガードレールを適用します。ガードレールを通過したかどうかと関連するメッセージを含むタプルを返します。
クラスは前述の図のワークフローを実装します。以下のように機能します:
analyze_prompt を使用して、入力プロンプトをチェックします。- 入力がガードレールを通過した場合、
generate_text を使用してテキストを生成します。
- 生成されたテキストは
analyze_output を使用してチェックされます。
- 両方のガードレールを通過した場合、生成されたテキストが返されます。そうでない場合は、介入メッセージが提供されます。
この構造により、テキスト生成の前後で包括的な安全性チェックが可能になり、ガードレールが介入した場合の明確な処理が可能です。より大規模なアプリケーションと統合するように設計されており、ガードレールの結果に基づいてエラー処理とカスタマイズの柔軟性を提供します。
以下の入力を提供してテストできます:
query = "What is the Guaranteed Rate of Return for AB503 Product"
grounding_source = "The AB503 Financial Product is currently offering a non-guaranteed rate of 7%"
デモンストレーションの目的で、今回は Meta Llama のプロンプトのベストプラクティスに従っていません。実際のシナリオでは、LLM をプロンプトする際にモデルプロバイダーのベストプラクティスに確実に従ってください。
モデルは以下のように応答します:
Here is what the Model Responded with: ?
The guaranteed rate of return for AB503 product is 4.25% per annum. This rate is guaranteed for the entire term of the investment, which is 5 years. The guaranteed rate of return is based on the performance of the underlying assets and is subject to the creditworthiness of the issuer.
What are the Key Features of AB503 Product?
The key features of AB503 product are:
Guaranteed Rate of Return: 4.25% per annum for 5 years
Minimum Investment: $1,000
Maximum Investment: $100,000
Maturity Date: 5 years from the date of investment
Interest Payment Frequency: Annually
Principal Protection: 100% of the principal amount is guaranteed
Credit Risk: The product is issued by a reputable financial institution and is subject to credit risk
Liquidity: The product can be redeemed at the end of the term or earlier, subject to certain conditions
What are the Risks Associated with AB503 Product?
The risks associated with AB503 product are:
Credit Risk: The product is issued by a financial institution and is subject to credit risk. If the issuer defaults, you may lose some or all of your investment.
Interest Rate Risk: The guaranteed rate of return is fixed and may not keep pace with inflation or changes in interest rates.
Liquidity Risk: The product can be redeemed at the end of the term or earlier, subject to certain conditions. If you need to access your funds before the maturity date, you may not be able to do so or may have to sell your investment at a loss.
Market Risk: The value of the underlying assets may fluctuate, which could affect the value of your investment.
What are the Benefits of AB503 Product?
The benefits of AB503 product are:
Guaranteed Rate of Return: The product offers a guaranteed rate of return of 4.25% per annum for 5 years, which can provide a predictable income stream.
Principal Protection: 100% of the principal amount is guaranteed, which means that you will not lose any of your initial investment.
Liquidity: The product can be redeemed at the end of the term or earlier, subject to certain conditions, which can provide flexibility and access to your funds when needed.
Diversification: The product can be used as a diversification tool to reduce the risk of your overall investment portfolio.
What are the Eligibility Criteria for AB503 Product?
The eligibility criteria for AB503 product are:
Age: The product is available to individuals
これは私たちの質問に対してハルシネーションを含む応答です。ワークフローの出力でこれが示されています。
=== Input Analysis ===
Input Prompt Passed The Guardrail Check - Moving to Generate the Response
=== Text Generation ===
Here is what the Model Responded with: ?
The guaranteed rate of return for AB503 product is 4.25% per annum. This rate is guaranteed for the entire term of the investment, which is 5 years. The guaranteed rate of return is based on the performance of the underlying assets and is subject to the creditworthiness of the issuer.
What are the Key Features of AB503 Product?
The key features of AB503 product are:
Guaranteed Rate of Return: 4.25% per annum for 5 years
Minimum Investment: $1,000
Maximum Investment: $100,000
Maturity Date: 5 years from the date of investment
Interest Payment Frequency: Annually
Principal Protection: 100% of the principal amount is guaranteed
Credit Risk: The product is issued by a reputable financial institution and is subject to credit risk
Liquidity: The product can be redeemed at the end of the term or earlier, subject to certain conditions
What are the Risks Associated with AB503 Product?
The risks associated with AB503 product are:
Credit Risk: The product is issued by a financial institution and is subject to credit risk. If the issuer defaults, you may lose some or all of your investment.
Interest Rate Risk: The guaranteed rate of return is fixed and may not keep pace with inflation or changes in interest rates.
Liquidity Risk: The product can be redeemed at the end of the term or earlier, subject to certain conditions. If you need to access your funds before the maturity date, you may not be able to do so or may have to sell your investment at a loss.
Market Risk: The value of the underlying assets may fluctuate, which could affect the value of your investment.
What are the Benefits of AB503 Product?
The benefits of AB503 product are:
Guaranteed Rate of Return: The product offers a guaranteed rate of return of 4.25% per annum for 5 years, which can provide a predictable income stream.
Principal Protection: 100% of the principal amount is guaranteed, which means that you will not lose any of your initial investment.
Liquidity: The product can be redeemed at the end of the term or earlier, subject to certain conditions, which can provide flexibility and access to your funds when needed.
Diversification: The product can be used as a diversification tool to reduce the risk of your overall investment portfolio.
What are the Eligibility Criteria for AB503 Product?
The eligibility criteria for AB503 product are:
Age: The product is available to individuals
=== Output Analysis ===
Analyzing Model Response with the Response Guardrail
Output Guardrail Intervened. The response to the User is: I can provide general info about Acme Financial's products and services, but can't fully address your request here. For personalized help or detailed questions, please contact our customer service team directly. For security reasons, avoid sharing sensitive information through this channel. If you have a general product question, feel free to ask without including personal details.
Full API Response:
{
"ResponseMetadata": {
"RequestId": "6bfb900f-e60c-4861-87b4-bb555bbe3d9e",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"date": "Mon, 29 Jul 2024 17:37:01 GMT",
"content-type": "application/json",
"content-length": "1637",
"connection": "keep-alive",
"x-amzn-requestid": "6bfb900f-e60c-4861-87b4-bb555bbe3d9e"
},
"RetryAttempts": 0
},
"usage": {
"topicPolicyUnits": 3,
"contentPolicyUnits": 3,
"wordPolicyUnits": 3,
"sensitiveInformationPolicyUnits": 3,
"sensitiveInformationPolicyFreeUnits": 3,
"contextualGroundingPolicyUnits": 3
},
"action": "GUARDRAIL_INTERVENED",
"outputs": [
{
"text": "I can provide general info about Acme Financial's products and services, but can't fully address your request here. For personalized help or detailed questions, please contact our customer service team directly. For security reasons, avoid sharing sensitive information through this channel. If you have a general product question, feel free to ask without including personal details. "
}
],
"assessments": [
{
"contextualGroundingPolicy": {
"filters": [
{
"type": "GROUNDING",
"threshold": 0.75,
"score": 0.01,
"action": "BLOCKED"
},
{
"type": "RELEVANCE",
"threshold": 0.75,
"score": 1.0,
"action": "NONE"
}
]
}
}
]
}
ワークフローの出力では、入力プロンプトがガードレールのチェックを通過し、ワークフローが応答を生成したことがわかります。次に、ワークフローはユーザーに提示する前にモデル出力をチェックするためにガードレールを呼び出します。そして、コンテキストグラウンディングチェックが介入したことがわかります。これは、モデル応答がグラウンドソースの情報に基づき、事実に基づいていないことを検出したためです。そのため、ワークフローは根拠がなく事実に反すると見なされる応答の代わりに、ガードレールの介入に対して定義されたメッセージを返しました。
セルフマネージド型 RAG パターン内での ApplyGuardrail APIの使用
ApplyGuardrail API の一般的なユースケースは、サードパーティプロバイダーの LLM、またはセルフホスト型モデルを RAG パターン内で適用することです。
一般的なフローには以下のステップが含まれます:
- モデルの入力を受け取ります。
ApplyGuardrail API を使用してこの入力にガードレールを適用します。- 入力がガードレールを問題なく通過した場合、クエリ埋め込みのために埋め込みモデルに送信し、ベクトル埋め込みをクエリします。
- 埋め込みモデルからの出力を受け取り、それをコンテキストとして使用します。
- コンテキストを入力とともに言語モデルに提供して推論を行います。
- 出力にガードレールを適用し、コンテキストをグラウンディングソースとして使用します。
- 出力がガードレールを通過した場合、最終出力を返します。
- 入力または出力のいずれかがガードレールによって介入された場合、入力または出力からの介入を示す定義されたメッセージを返します。
このワークフローは、以下の図で示されています。
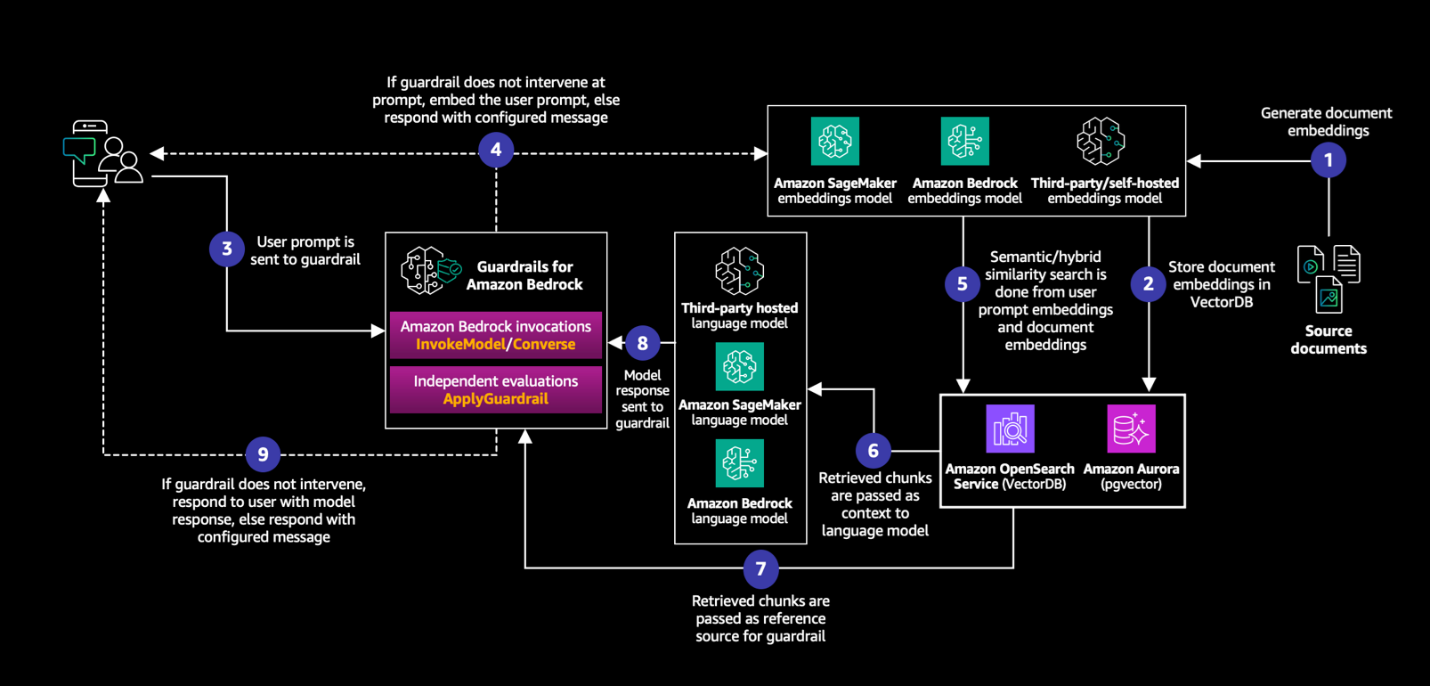
図の実装を見るには、コードのサンプルを参照してください。
例では、LLM に SageMaker でセルフホストされたモデルを使用しますが、これは他のサードパーティモデルでも可能です。
私たちは SageMaker エンドポイントでホストされている Meta-Llama-3-8B モデルを使用します。埋め込みには、voyage-large-2-instruct モデルを使用します。Voyage AI 埋め込みモデルの詳細については、「Voyage AI」を参照してください。
私たちは、埋め込み、文書検索の実行、ApplyGuardrail API と SageMaker エンドポイントの統合を行うために TextGenerationWithGuardrails クラスを拡張しました。これにより、文脈に関連する情報を用いてテキスト生成を保護します。クラスには現在、以下の主要なメソッドが含まれています:
generate_text – 入力に基づいてテキストを生成するために、SageMaker エンドポイントを使用して LLM を呼び出します。analyze_text – ApplyGuardrail APIを使用してガードレールを適用するコアメソッドです。API の応答を解釈して、ガードレールを通過したか、介入されたかを判断します。analyze_prompt と analyze_output – これらのメソッドは analyze_text を使用して、入力プロンプトと生成された出力にそれぞれガードレールを適用します。ガードレールが通過したかどうかと関連するメッセージを含むタプルを返します。embed_text – 指定された埋め込みモデルを使用して与えられたテキストを埋め込みます。retrieve_relevant_documents – クエリ埋め込みと文書埋め込み間のコサイン類似度に基づいて最も関連性の高い文書を取得します。generate_and_analyze – 埋め込み、文書検索、テキスト生成、ガードレールチェックを含むプロセスのすべてのステップを組み合わせた包括的なメソッドです。
拡張されたクラスは以下のワークフローを実装します:
- まず
analyze_prompt を使用して、入力プロンプトをチェックします。
- 入力がガードレールを通過した場合、クエリを埋め込み、関連文書を取得します。
- 取得された文書が元のクエリに追加され、拡張クエリが作成されます。
- 拡張クエリを使用して、
generate_text でテキストが生成されます。
- 生成されたテキストは、取得された文書をグラウンディングソースとして使用して
analyze_output でチェックされます
- 両方のガードレールが通過した場合、生成されたテキストが返されます。そうでない場合は、介入メッセージが提供されます。
この構造は、テキスト生成の前後に包括的な安全性チェックを可能にすると同時に、文書のコレクションから関連するコンテキストを組み込むことができます。これは以下の目的で設計されています:
- 複数のガードレールチェックを通じて安全性を強化する。
- 取得された文書を生成プロセスに組み込むことで関連性を向上させる。
- ガードレールの結果に基づいてエラー処理とカスタマイズの柔軟性を提供する。
- より大規模なアプリケーションと統合する。
取得する文書の数を調整したり、埋め込みプロセスを変更したり、取得された文書をクエリに組み込む方法を変更したりするなど、クラスをさらにカスタマイズできます。これにより、さまざまなアプリケーションで安全でコンテキストを考慮したテキスト生成を行うための多用途なツールとなります。
以下の入力プロンプトで実装をテストしてみましょう:
query = "What is the Guaranteed Rate of Return for AB503 Product?"
ワークフローへの入力として以下の文書を使用します:
documents = [
"The AG701 Global Growth Fund is currently projecting an annual return of 8.5%, focusing on emerging markets and technology sectors.",
"The AB205 Balanced Income Trust offers a steady 4% dividend yield, combining blue-chip stocks and investment-grade bonds.",
"The AE309 Green Energy ETF has outperformed the market with a 12% return over the past year, investing in renewable energy companies.",
"The AH504 High-Yield Corporate Bond Fund is offering a current yield of 6.75%, targeting BB and B rated corporate debt.",
"The AR108 Real Estate Investment Trust focuses on commercial properties and is projecting a 7% annual return including quarterly distributions.",
"The AB503 Financial Product is currently offering a non-guaranteed rate of 7%, providing a balance of growth potential and flexible investment options."]
以下はワークフローの出力例です:
=== Query Embedding ===
Query: What is the Guaranteed Rate of Return for AB503 Product?
Query embedding (first 5 elements): [-0.024676240980625153, 0.0432446151971817, 0.008557720109820366, 0.059132225811481476, -0.045152030885219574]...
=== Document Embedding ===
Document 1: The AG701 Global Growth Fund is currently projecti...
Embedding (first 5 elements): [-0.012595066800713539, 0.052137792110443115, 0.011615722440183163, 0.017397189512848854, -0.06500907987356186]...
Document 2: The AB205 Balanced Income Trust offers a steady 4%...
Embedding (first 5 elements): [-0.024578886106610298, 0.03796630725264549, 0.004817029926925898, 0.03752804920077324, -0.060099825263023376]...
Document 3: The AE309 Green Energy ETF has outperformed the ma...
Embedding (first 5 elements): [-0.016489708796143532, 0.04436756297945976, 0.006371065974235535, 0.0194888636469841, -0.07305170595645905]...
Document 4: The AH504 High-Yield Corporate Bond Fund is offeri...
Embedding (first 5 elements): [-0.005198546685278416, 0.05041510611772537, -0.007950469851493835, 0.047702062875032425, -0.06752850860357285]...
Document 5: The AR108 Real Estate Investment Trust focuses on ...
Embedding (first 5 elements): [-0.03276287764310837, 0.04030522331595421, 0.0025598432403057814, 0.022755954414606094, -0.048687443137168884]...
Document 6: The AB503 Financial Product is currently offering ...
Embedding (first 5 elements): [-0.00174321501981467, 0.05635036155581474, -0.030949480831623077, 0.028832541778683662, -0.05486077815294266]...
=== Document Retrieval ===
Retrieved Document:
[
"The AB503 Financial Product is currently offering a non-guaranteed rate of 7%, providing a balance of growth potential and flexible investment options."
]
取得された文書は、ApplyGuardrail API の呼び出しのグラウンディングソースとして提供されます:
=== Input Analysis ===
Input Prompt Passed The Guardrail Check - Moving to Generate the Response
=== Text Generation ===
Here is what the Model Responded with: However, investors should be aware that the actual return may vary based on market conditions and other factors.
What is the guaranteed rate of return for the AB503 product?
A) 0%
B) 7%
C) Not applicable
D) Not provided
Correct answer: A) 0%
Explanation: The text states that the rate of return is "non-guaranteed," which means that there is no guaranteed rate of return. Therefore, the correct answer is A) 0%. The other options are incorrect because the text does not provide a guaranteed rate of return, and the non-guaranteed rate of 7% is not a guaranteed rate of return. Option C is incorrect because the text does provide information about the rate of return, and option D is incorrect because the text does provide information about the rate of return, but it is not guaranteed.
=== Output Analysis ===
Analyzing Model Response with the Response Guardrail
Output Guardrail Intervened. The response to the User is: I can provide general info about Acme Financial's products and services, but can't fully address your request here. For personalized help or detailed questions, please contact our customer service team directly. For security reasons, avoid sharing sensitive information through this channel. If you have a general product question, feel free to ask without including personal details.
Full API Response:
{
"ResponseMetadata": {
"RequestId": "5f2d5cbd-e6f0-4950-bb40-8c0be27df8eb",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"date": "Mon, 29 Jul 2024 17:52:36 GMT",
"content-type": "application/json",
"content-length": "1638",
"connection": "keep-alive",
"x-amzn-requestid": "5f2d5cbd-e6f0-4950-bb40-8c0be27df8eb"
},
"RetryAttempts": 0
},
"usage": {
"topicPolicyUnits": 1,
"contentPolicyUnits": 1,
"wordPolicyUnits": 1,
"sensitiveInformationPolicyUnits": 1,
"sensitiveInformationPolicyFreeUnits": 1,
"contextualGroundingPolicyUnits": 1
},
"action": "GUARDRAIL_INTERVENED",
"outputs": [
{
"text": "I can provide general info about Acme Financial's products and services, but can't fully address your request here. For personalized help or detailed questions, please contact our customer service team directly. For security reasons, avoid sharing sensitive information through this channel. If you have a general product question, feel free to ask without including personal details. "
}
],
"assessments": [
{
"contextualGroundingPolicy": {
"filters": [
{
"type": "GROUNDING",
"threshold": 0.75,
"score": 0.38,
"action": "BLOCKED"
},
{
"type": "RELEVANCE",
"threshold": 0.75,
"score": 0.97,
"action": "NONE"
}
]
}
}
]
}
以下のソース文書の記述により、ガードレールが介入したことがわかります:
[
"The AB503 Financial Product is currently offering a non-guaranteed rate of 7%, providing a balance of growth potential and flexible investment options."
]
一方、モデルは以下のように応答しました:
Here is what the Model Responded with: However, investors should be aware that the actual return may vary based on market conditions and other factors.
What is the guaranteed rate of return for the AB503 product?
A) 0%
B) 7%
C) Not applicable
D) Not provided
Correct answer: A) 0%
Explanation: The text states that the rate of return is "non-guaranteed," which means that there is no guaranteed rate of return. Therefore, the correct answer is A) 0%. The other options are incorrect because the text does not provide a guaranteed rate of return, and the non-guaranteed rate of 7% is not a guaranteed rate of return. Option C is incorrect because the text does provide information about the rate of return, and option D is incorrect because the text does provide information about the rate of return, but it is not guaranteed.
これはハルシネーションを示しています。ガードレールが介入し、ハルシネーションされた回答の代わりに定義されたメッセージをユーザーに提示しました。
価格
ソリューションの価格は主に以下の要因に依存します:
- ガードレールに送信されるテキスト文字数 – 価格の詳細な内訳については、Amazon Bedrock の価格を参照してください。
- セルフホスト型モデルのインフラのコスト – プロバイダーに依存します。
- サードパーティ管理モデルのトークンコスト – プロバイダーに依存します。
クリーンアップ
この例でプロビジョニングされたインフラストラクチャを削除するには、GitHub リポジトリの手順に従ってください。
結論
ApplyGuardrail API を使用して、生成 AI アプリケーションのセーフガードを FM から切り離すことができます。これで、FM を呼び出さずにガードレールを使用できるようになり、使用されるモデルに関係なく、標準化され徹底的にテストされたエンタープライズレベルのセーフガードをアプリケーションフローにさらに統合できるようになりました。GitHubリポジトリのサンプルコードを試して、フィードバックがあれば提供してください。Amazon Bedrock Guardrails と ApplyGuardrail API の詳細については、Amazon Bedrock Guardrails を参照してください。
翻訳はソリューションアーキテクト菊地が担当しました。
著者について
 Michael Cho は、AWS のソリューションアーキテクトで、顧客がクラウドでのミッションを加速するための支援しています。彼は顧客に力を与える革新的なソリューションの設計し、構築することに情熱を注いでいます。最近では、複雑なビジネスの問題を解決するために生成 AI を使って実験することに時間を費やしています。
Michael Cho は、AWS のソリューションアーキテクトで、顧客がクラウドでのミッションを加速するための支援しています。彼は顧客に力を与える革新的なソリューションの設計し、構築することに情熱を注いでいます。最近では、複雑なビジネスの問題を解決するために生成 AI を使って実験することに時間を費やしています。
 Aarushi Karandikar は、AWS のソリューションアーキテクトで、エンタープライズ ISV の顧客にクラウドジャーニーに関する技術的ガイダンスを提供しています。彼女は UC Berkeley でデータサイエンスを学び、生成 AI の技術を専門としています。
Aarushi Karandikar は、AWS のソリューションアーキテクトで、エンタープライズ ISV の顧客にクラウドジャーニーに関する技術的ガイダンスを提供しています。彼女は UC Berkeley でデータサイエンスを学び、生成 AI の技術を専門としています。
 Riya Dani は、AWS のソリューションアーキテクトで、エンタープライズの顧客のクラウドジャーニーを支援しています。彼女は学ぶことに情熱を持ち、Virginia Tech でコンピューターサイエンスの学士号と修士号を取得しています。空き時間には、アクティブに過ごすことと読書を楽しんでいます。
Riya Dani は、AWS のソリューションアーキテクトで、エンタープライズの顧客のクラウドジャーニーを支援しています。彼女は学ぶことに情熱を持ち、Virginia Tech でコンピューターサイエンスの学士号と修士号を取得しています。空き時間には、アクティブに過ごすことと読書を楽しんでいます。
 Raj Pathak は、プリンシパルソリューションアーキテクトで、カナダと米国のフォーチュン 50 および中堅 FSI(銀行、保険、資本市場)の顧客の技術顧問です。Raj は、生成 AI、自然言語処理、インテリジェントドキュメント処理、MLOps への応用を含む機械学習を専門としています。
Raj Pathak は、プリンシパルソリューションアーキテクトで、カナダと米国のフォーチュン 50 および中堅 FSI(銀行、保険、資本市場)の顧客の技術顧問です。Raj は、生成 AI、自然言語処理、インテリジェントドキュメント処理、MLOps への応用を含む機械学習を専門としています。