Amazon Web Services ブログ
機械学習用のデータを準備するためのビジュアルインターフェイス、Amazon SageMaker Data Wrangler のご紹介
本日、Amazon SageMaker の新たな機能であるAmazon SageMaker Data Wranglerを発表できることを非常に嬉しく思います。これを利用することで、データサイエンティストやエンジニアは、ビジュアルインターフェイスを使用した機械学習 (ML) アプリケーションのデータ準備をより速く行うことができます。
データサイエンティストと機械学習エンジニアのグループに、機械学習における問題の調査に実際、どのくらい時間を費やすのかを尋ねるたびに、私はよく多くのため息と、それに続く「運が良ければ 20% です」というせりふに沿った答えを聞きます。その理由を尋ねると、答えはいつでも同じです、「データ準備に、常に時間の 80% を費やしています。」
実際、トレーニングのためのデータ準備は、機械学習のプロセスにおける重要なステップであり、そこで下手な仕事をしようとは誰も考えないでしょう。一般的なタスクは次のとおりです。
- データの特定: 未加工データの格納場所の検索、データへのアクセス
- データの可視化: データセット内の各列の統計的性質の検証、ヒストグラムの構築、外れ値の調査
- データのクリーニング: 重複の削除、欠損値のエントリの入力または削除、外れ値の削除
- データの強化および特徴エンジニアリング: 列の処理によるより表現力のある特徴データの構築、トレーニングのための特徴データのサブセットの選択
新しい機械学習プロジェクトの初期段階において、これは直感と経験が大きな役割を果たす高度な手動プロセスです。データサイエンティストは、多くの場合、pandas や PySpark などのオープンソースツールやオープンソースツールの組み合わせを使用して、さまざまなデータ変換の組み合わせを試し、モデルをトレーニングする前にデータセットを処理します。その後、予測結果を分析し、反復処理を行います。同じくらい重要ですが、このプロセスを何度も繰り返しループするのは、時間がかかり面倒であると同時に、エラーが発生しやすくなります。
ある時点で、適切なレベルの精度 (または選択した他のすべてのメトリクス) に達すると、本番環境の完全なデータセットでトレーニングしたいと考えるでしょう。しかし、まずはサンドボックス内で実験した正確なデータ準備のステップを再現および自動化する必要があります。残念ながら、この作業のインタラクティブな性質を考慮すると、慎重に文書化していても、常にエラーの余地があります。
最後に大事なことですが、最終段階に進む前に、データ処理インフラストラクチャを管理および拡張する必要があります。今考えれば、このすべてを行うには、80% の時間では十分ではないかもしれません。
Amazon SageMaker Data Wrangler のご紹介
Amazon SageMaker Data Wrangler は、機械学習用に完全に管理された統合開発環境 (IDE) である Amazon SageMaker Studio に統合されています。数回クリックするだけで、データソースへの接続、データの探索と視覚化、組み込み変換および独自の変換の適用、自動生成されたスクリプトへの結果コードのエクスポート、マネージドインフラストラクチャでの実行が可能です。各ステップをより詳しく見ていきましょう。
もちろん、データ準備は、データを特定してアクセスすることから始まります。SageMaker Data Wrangler を使用すると、導入してすぐに Amazon Simple Storage Service (S3)、Amazon Athena、Amazon Redshift、そして AWS Lake Formation に簡単かつ迅速に接続できます。Amazon SageMaker Feature Store からデータをインポートすることもできます。AWS のすべてのサービスと同様に、SageMaker Studio インスタンスにアタッチされたアクセス許可に基づいて、AWS Identity and Access Management (IAM) によってアクセス管理がおこなわれます。
データソースに接続すると、おそらくデータを視覚化する必要があります。SageMaker Data Wrangler のユーザーインターフェイスを使用すると、表のサマリー、ヒストグラム、散布図を数秒で表示できます。人気のある Altair のオープンソースライブラリで書かれたコードをコピーして実行するだけで、独自のグラフを作成することもできます。
データがどのように表示されるかをよく把握できたら、データを準備し始めます。SageMaker Data Wrangler には、データの検索と置換、列の分割や名前の変更、削除、数値のスケーリング、カテゴリ値のエンコードなど、300 以上の組み込み変換が含まれています。しなければならないのは、ドロップダウンリストで変換を選択し、必要なパラメータを入力することだけです。その後、変更をプレビューし、このデータセットの準備ステップのリストに追加するかどうかを指定できます。必要に応じて、pandas、PySpark または PySpark SQL のいずれかを使用し、独自のコードを追加してカスタム変換を実行することもできます。
処理パイプラインに変換ステップを追加すると、SageMaker Studio でその概要をグラフィカルに表示できます。また、新しいデータソースや変換ステップにおける別のグループ (たとえば、データクリーニングのグループ、特徴エンジニアリングのグループ) などの新しいステージをパイプラインに追加することもできます。直感的なユーザーインターフェイスにより、データ準備のパイプラインが目の前で形作られ、処理されたデータが正しく表示されることを即座に確認できます。
早い段階で、データ準備のステップを確実にチェックし、その予測力を理解したいと思いませんか? 次に、嬉しいお知らせです! 回帰と分類の問題タイプでは、「クイックモデル」機能を使用すると、データのサブセットを選択し、モデルをトレーニングし、予測結果に最も寄与している特徴データを特定できます。モデルを見ると、データ準備の問題をできるだけ早く簡単に診断して修正し、モデルのパフォーマンスを向上させるために追加の特徴エンジニアリングが必要かどうかを判断できます。
パイプラインに満足したら、手動のステップを忠実に再現する Python スクリプトにワンクリックでエクスポートできます。矛盾を追う時間を無駄にすることはなく、このコードを機械学習プロジェクトに直接追加できます。
さらに、処理コードを次のノートブックにエクスポートすることもできます。
- Amazon SageMaker Processing ジョブとして処理コードを実行するノートブック。
- Amazon SageMaker Pipelines のワークフローとして処理コードを実行するノートブック。
- Amazon SageMaker Feature Store に、処理された機能をプッシュするノートブック。
さて、簡単なデモを行い、SageMaker Data Wrangler でどれくらい簡単に作業できるかをお見せしましょう。
Amazon SageMaker Data Wrangler を使用する
SageMaker Studio を開き、Titanic データセットを処理するために、新しいデータフローを作成します。これには、乗客に関する情報と、難破を生き残ったかどうかを示すラベルが含まれています。

データセットは、Amazon Simple Storage Service (S3) に CSV ファイルとして格納されます。次に、適切なデータソースを選択します。
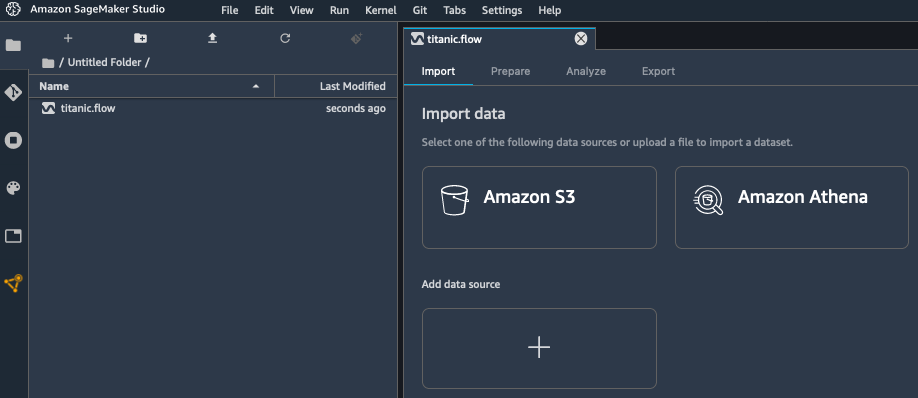
組み込みツールを使用して、S3 バケットをすばやくナビゲートし、データを含む CSV ファイルを特定します。大規模なデータセットの場合、SageMaker Data Wrangler は Parquet 形式もサポートしています。
ファイルを選択すると、SageMaker Data Wrangler で、最初の数行が表示されます。

データセットをインポートすると、データフローの初期ビューが表示されます。データセットを右クリックし、[Edit data types (データ型の編集)] を選択して、SageMaker Data Wrangler がデータセット内の各列の型を正しく検出したことを確認します。

各列をチェックすると、すべてのタイプが正しいように見えます。

データフロービューに戻り、今度は [分析の追加] を選択します。これにより、ヒストグラム、散布図などを使用してデータを視覚化できる新しいビューが開きます。たとえば、生存状況に応じた乗客の年齢分布を示すヒストグラムを作成し、その性別を使用してビンに色を付けます。もちろん、将来使用するために保存もできます。

もう一度データフロービューに戻り、[Add transform (変換の追加)] を選択してデータセットの処理を開始します。これにより、新しいビューが開き、データセットの最初の行と 300 以上の組み込み変換のリストが表示されます。

Pclass (パッセンジャークラス) はカテゴリ変数であり、one-hot エンコーディングを使用してエンコードすることにしました。これにより、異なるディメンションを表す 3 つの新しい列が作成され、それらのプレビューが可能になります。これはまさに目的のものなので、この変換を最終的に適用します。同様に、同じ変換を Sex 列に適用します。

次に、元の Pclass 列を削除します。同じ変換を使用して、Name 列も削除します。

これらの変換によりモデルの精度が増減するかどうかを簡単に理解するために、その場でモデルをトレーニングする分析を作成できます。私の問題は二項分類の問題であるため、SageMaker Data Wrangler で、F1 スコアと呼ばれるメトリクスを使用します。0.749 は良いスタートであり、追加の処理が確実に改善するでしょう。また、性別、年齢、第 3 クラスの乗客であるなど、どの特徴データが予測された結果に最も寄与しているのかを見ることもできます。

次に「エクスポート」ビューに移動して、これまでに作成したすべての変換を選択し、機械学習プロジェクトに追加します。
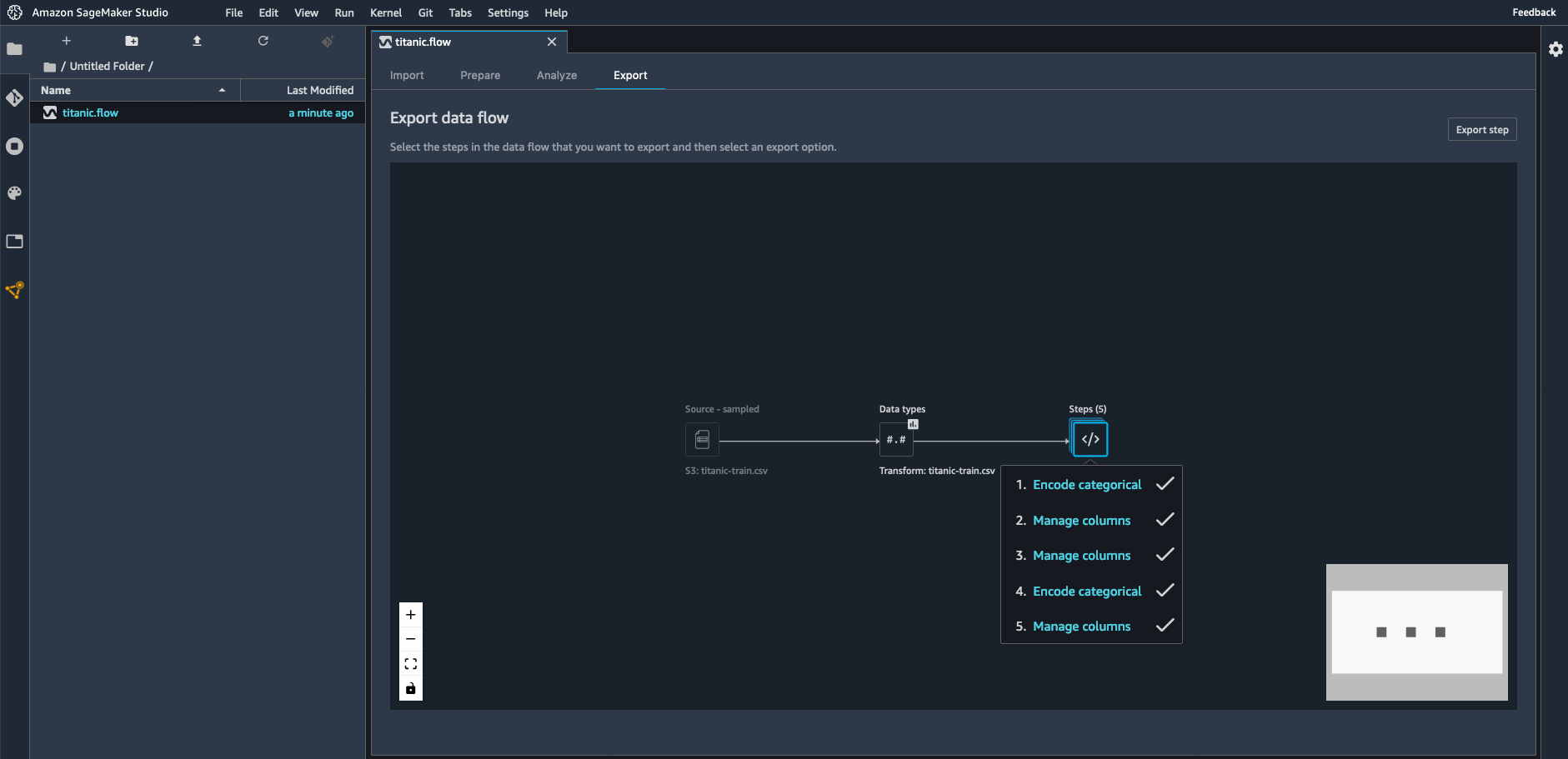
ここでは [Pythonコード] を選択してPythonスクリプトを生成します。Amazon SageMaker Processing、Amazon SageMaker Pipelines、Amazon SageMaker Feature Store ではその他のオプションを利用できます。

数秒後、スクリプトが利用可能になります。スクリプトはそのまま機械学習プロジェクトに追加することができ、データ準備のステップが、上で作成したインタラクティブな変換と確実に一致することを確認しました。
開始方法
ご覧のとおり、 Amazon SageMaker Data Wrangler を使用することで、データ準備のステップにおいて、実験や本番ですぐに使用できるコードに変換する前に、インタラクティブな作業をとても簡単に行うことができます。
この機能は、SageMaker Studio が利用可能なすべてのリージョンで本日からご利用いただけます。
ぜひお試しいただき、ご意見をお聞かせください。当社では、常にお客様からのフィードバックをお待ちしております。フィードバックは、通常の AWS サポート連絡先、または、SageMaker の AWS フォーラムを通じてお送りください。
初期のテスト段階で真摯に協力してくれた同僚の Peter Liu に感謝します。