Amazon Web Services ブログ
Amazon SageMaker による FairMOT モデルのトレーニングとデプロイ
この記事は “ Train and deploy a FairMOT model with Amazon SageMaker ” を翻訳したものです。
ビデオ解析におけるマルチオブジェクト・トラッキング ( MOT ) は、スポーツ中継、製造、監視、交通モニタリングなど、多くの産業で需要が高まっています。例えば、スポーツ中継では、サッカー選手をリアルタイムで追跡し、スピードや移動距離などの身体的パフォーマンスをリアルタイムに分析することができます。
従来は、 MOT を object detection と association の 2 つのタスクに分離して考える手法が主流でした。まず、 object detectionタスクでオブジェクトを検出します。 association タスクは、検出したオブジェクトごとに画像領域から re-identification ( re-ID ) 特徴を抽出し、 re-ID 特徴から検出した各オブジェクトを既存の追跡に関連付けをしたり、新しい追跡を作成したりします。多数のオブジェクトが存在する環境下でリアルタイムに推論を行うことは困難です。これは、 2 つのタスクそれぞれで特徴を抽出し、 association タスクでは各オブジェクトに対して re-ID 特徴の抽出を実行する必要があるためです。いくつかの提案されているワンショット MOT 手法の中には、オブジェクト検出ネットワークに re-ID のためのブランチを追加し、 object detection と association を同時に行うものがあります。これにより、推論時間は短縮されますが、追跡の性能は犠牲になります。
FairMOT は、オブジェクト検出と re-ID 特徴抽出のための 2 つのブランチを持つワンショット MOT 手法です。 FairMOT は 2 ステップの手法よりも高い性能を持ち、 MOT challenge datasets では約 30 FPS の速度を実現しました。この性能向上により、 MOT は多くの産業分野で活躍することができます。
Amazon SageMaker は、すべての開発者やデータサイエンティストに向けた、機械学習 ( ML ) モデルの準備、構築、訓練、デプロイを迅速に行う機能を提供するフルマネージドサービスです。 SageMaker は、 ML モデルのトレーニングとデプロイを加速するために利用可能な、いくつかの組み込みアルゴリズムとコンテナイメージを提供します。さらに、 FairMOT のようなカスタムアルゴリズムについても、カスタムビルドの Docker コンテナイメージによりサポートされます。
この記事では、 SageMaker を使用して FairMOT モデルをトレーニングおよびデプロイし、ハイパーパラメータチューニングにより最適化し、バッチモードと同様にリアルタイムで予測を行う方法について説明します。
ソリューションの概要
私たちのソリューションは、次のようなハイレベルなステップで構成されています。
- リソースをセットアップする。
- SageMaker を使用して、 MOT challenge dataset で FairMOT モデルをトレーニングし、ハイパーパラメータを調整する。
- リアルタイム推論を実行する。
- バッチ推論を実行する。
前提条件
作業を開始する前に、以下の前提条件を満たしてください。
- AWS アカウントを作成、または既存の AWS アカウントを使用します。
- トレーニングジョブ用に最低 1 つの ml.p3.16xlarge インスタンスが利用可能であることを確認します。
- 推論エンドポイント用に、最低 1 つの ml.p3.2xlarge インスタンスが利用可能であることを確認します。
- 処理ジョブのために、最低 1 つの ml.p3.2xlarge インスタンスが利用可能であることを確認します。
上記のインスタンスサイズでのモデルのトレーニング、デプロイ、または処理ジョブの実行が初めての場合、 SageMaker トレーニングジョブのサービスクオータ増加を要求する必要があります。
リソースのセットアップ
すべての前提条件をクリアしたら、必要なリソースをデプロイする準備が整いました。
- SageMaker notebook インスタンスを作成します。このタスクでは、 ml.t3.medium インスタンスタイプを推奨します。デフォルトのボリュームサイズは 5 GB ですが、100 GB まで増やします。 AWS Identity and Access Management ( IAM ) ロールは、既存のロールを選択するか、新しいロールを作成し、 AmazonSageMakerFullAccess および AmazonElasticContainerRegistryPublicFullAccess ポリシーをロールにアタッチします。
- 作成したノートブックに GitHub レポジトリをクローンします。
- Amazon Simple Storage Service ( Amazon S3 ) のバケットを新規に作成するか、既存のバケットを使用します。
FairMOT モデルのトレーニング
FairMOT モデルの学習には、 fairmot-training.ipynb ノートブックを使用します。以下の図は、このコードで実装されている論理的な処理フローの概要です。

Initialize SageMaker セクションでは、 S3 バケットの場所とデータセット名を定義し、データセット全体でのトレーニング( half_val パラメータを 0 に設定)または、学習と検証に分けたトレーニング( half_val を 1 に設定)を選択しています。ハイパーパラメータのチューニングする際は、後者のモードを使用します。
次の Stage dataset セクションでは、 prepare-s3-bucket.sh スクリプトが MOT challenge からデータセットをダウンロードし、変換した後に S3 バケットにアップロードしています。今回はモデルのトレーニングに MOT 17 と MOT 20 のデータセットを使用しますが、他の MOT データセットでトレーニングを試みてもよいでしょう。
Build and push training container image セクションでは、 FairMOT の学習アルゴリズムが入ったカスタムコンテナイメージを作成します。 Docker イメージの定義は container-dp フォルダ内にあります。このコンテナイメージは約 13.5 GB の容量を消費するため、 prepare-docker.sh スクリプトはローカルのテンポラリ Docker イメージのデフォルトディレクトリを変更し、「 no space 」エラーを回避します。 build_and_push.sh コマンドは、コンテナのビルドと Amazon Elastic Container Registry ( Amazon ECR ) へのプッシュを実行します。 Amazon ECR コンソールで結果を確認することができます。
最後に、 Define a training job セクションで、モデルのトレーニングを開始します。 SageMaker コンソールの Training Jobs ページでモデルのトレーニング状況を観ることができます。モデルは最初に In progress のステータスを表示し、約 3 時間で Completed に変わります(ノートブックをそのまま実行している場合)。次のスクリーンショットに示すように、トレーニングジョブの詳細ページで対応するトレーニングメトリクスにアクセスすることができます。

トレーニングメトリクス
FairMOT のモデルは、バックボーンネットワークをベースに、その上にオブジェクト検出と re-ID のブランチを配置しています。オブジェクト検出ブランチには、 heatmaps 、 object center offsets 、 bounding box sizes を推定するための 3 つの並列ヘッドがあります。学習段階において、各ヘッドは対応する loss をそれぞれ持ちます。 heatmaps は hm_loss 、 object center offsets は offset_loss 、 bounding box sizes は wh_loss です。 re-ID ブランチには、re-ID 特徴をトレーニングするための id_loss があります。これら 4 つの loss に基づいて、ネットワーク全体の loss が計算されます。トレーニング時には、訓練データと検証データの両方において、全ての loss がモニタリングされます。ハイパーパラメータのチューニングの際には、 ObjectiveMetric を利用し最適なモデルを選択します。
トレーニングジョブが完了したら、ジョブの詳細ページの出力セクションに表示されるモデルの URI をメモします。
最後に、このノートブックの末尾にある、 SageMaker のハイパーパラメータ最適化 ( HPO ) を紹介します。ハイパーパラメータの適切な組み合わせは ML モデルの性能を向上させますが、手作業で見つけるのは時間がかかります。 SageMaker のハイパーパラメータチューニングは、このプロセスを自動化するのに役立ちます。各チューニング用ハイパーパラメータの範囲と objective metric を設定するだけで、あとは HPO が行います。
このプロセスを加速するために、 SageMaker HPO は複数のトレーニングジョブを並行して実行することができます。最終的に、最良なトレーニングジョブがモデルに最適なハイパーパラメータを提供し、それらをデータセット全体に対するトレーニングに使用することができます。
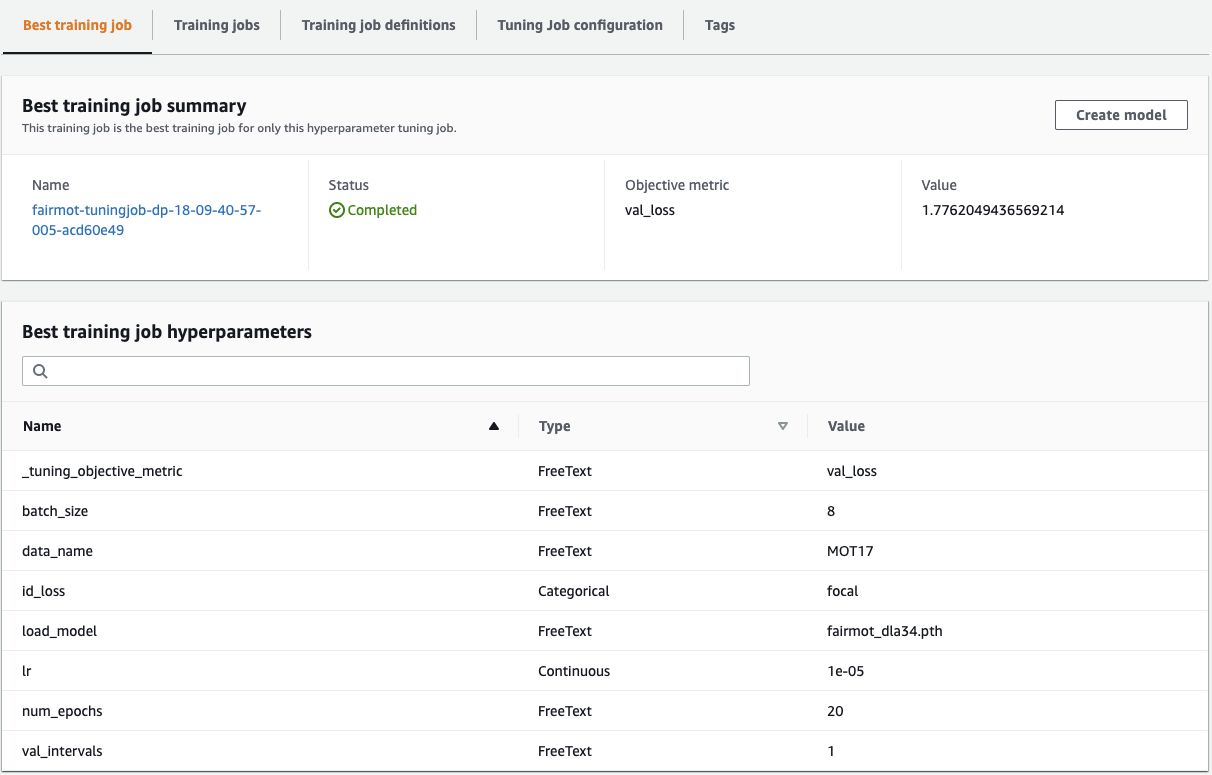
リアルタイム推論の実行
このセクションでは、 fairmot-inference.ipynb ノートブックを使用します。トレーニング時のノートブックと同様に、まず SageMaker のパラメータを初期化し、カスタムコンテナイメージを構築します。その後、推論コンテナを先の手順で構築したモデルとともにデプロイします。モデルの場所は s3_model_uri 変数で参照されますが、正しい URI にリンクされていることを再確認してください(必要に応じて手動で調整してください)。
次の図は、推論フローを表しています。
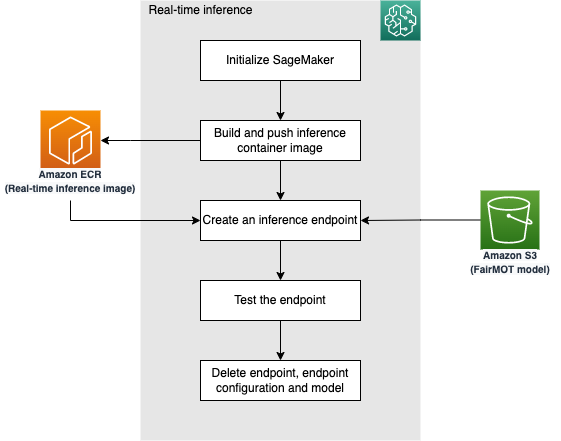
カスタムコンテナが SageMaker の推論エンドポイントにデプロイされたら、テストの準備が整います。まず、 MOT 16-03 からテスト動画をダウンロードします。次に、推論ループ内で OpenCV を使ってビデオをフレームに分割し、 base64 に変換し、デプロイされた推論エンドポイントを呼び出して予測を行います。
次のコードは、 SageMaker SDK で実装されたロジックを示しています。
frame_path = # the path of a frame
with open(frame_path, "rb") as image_file:
img_data = base64.b64encode(image_file.read())
data = {"frame_id": frame_id}
data["frame_data"] = img_data.decode("utf-8")
if frame_id == 0:
data["frame_w"] = frame_w
data["frame_h"] = frame_h
data["batch_size"] = 1
body = json.dumps(data).encode("utf-8")
os.remove(frame_path)
response = client.invoke_endpoint(
EndpointName=endpoint_name, ContentType="application/json", Accept="application/json", Body=body
)
body = response["Body"].read()出力結果として作成される動画は、 {root_directory}/datasets/test.mp4 に保存されます。以下はサンプルフレームです。連続するフレームの同一人物は、一意の ID を持つ bounding box で囲まれています。

バッチ推論の実行
フレームごとの推論エンドポイントを用いた FairMOT モデルの実装と検証を行ったので、ビデオ全体を一括で処理できるコンテナを構築します。これにより、より複雑なビデオ処理パイプラインの一段階として FairMOT を利用することができます。 fairmot-batch-inference.ipynb ノートブックにあるように、この目標を達成するために SageMaker processing job を使用します。
先の手順と同様に、 SageMaker の初期化とカスタムコンテナイメージの構築から始めます。今回は、フレームごとの推論ループをコンテナ内部 ( predict.py スクリプト ) にカプセル化しました。テストデータは MOT 16-03 で、 S3 バケットにあらかじめステージングされています。前のステップと同様に、 s3_model_uri 変数が正しいモデル URI を参照していることを確認します。
SageMaker processing jobs は、入出力データの配置に Amazon S3 を利用しています。次の図は、ワークフローを示しています。
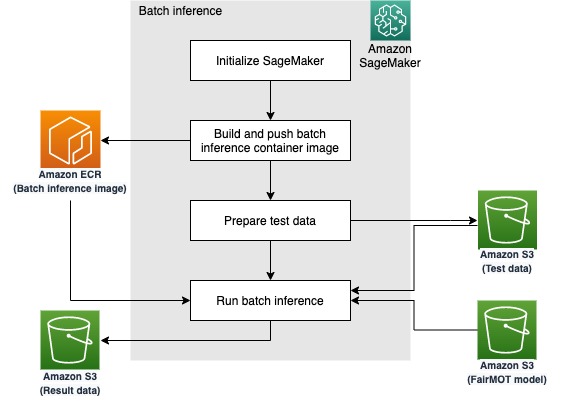
Run batch inference セクションでは、 ScriptProcessor のインスタンスを作成し、入出力データのパスとターゲットとなるモデルを定義します。そして処理を実行すると、結果の動画が変数 s3_output で定義された場所に配置されます。先の手順で生成されたビデオと同じ結果となります。
クリーンアップ
不要なコストを避けるため、推論エンドポイントを含めこのソリューションの一部として作成したリソースを削除してください。
まとめ
この記事では、 SageMaker を使って FairMOT をベースにしたオブジェクトトラッキングモデルをトレーニング・デプロイする方法を紹介しました。同様のアプローチで他のカスタムアルゴリズムを実装することができます。今回の例では公開されているデータセットを使用しましたが、お客様がお持ちのデータセットでも同じことが実現できます。 Amazon SageMaker Ground Truth はラベリングを支援し、 SageMaker custom containers は実装をよりシンプルにします。
著者について
Gordon Wang
Gordon Wang は Amazon Web Services のプロフェッショナルサービスチームでデータサイエンティストとして活躍しています。メディア、製造、エネルギー、ヘルスケアなど、さまざまな業界のお客様をサポートしています。コンピュータビジョン、ディープラーニング、 MLOps に情熱を注いでおり、余暇にはランニングとハイキングを嗜んでいます。
翻訳は Solutions Architect 片山洋平が担当しました。原文はこちらです。