Amazon Web Services 한국 블로그
Amazon Redshift – 데이터 레이크 내보내기 및 통합 질의 기능 출시 (서울 리전 포함)
데이터 웨어하우스는 트랜잭션 시스템 및 업무용 애플리케이션에서 생성되는 관계형 데이터를 분석하는 데 최적화된 데이터베이스입니다. Amazon Redshift는 표준 SQL과 기존 BI(비즈니스 인텔리전스) 도구를 사용하여 데이터를 간편하고 비용 효율적으로 분석할 수 있는 완전 관리형 데이터 웨어하우스입니다.
데이터 웨어하우스에 맞지 않는 구조화되지 않은 데이터로부터 정보를 얻으려면 데이터 레이크를 빌드할 수 있습니다. 데이터 레이크는 구조화된 데이터와 구조화되지 않은 데이터 모두 규모에 관계 없이 저장할 수 있는 중앙 리포지토리입니다. Amazon Simple Storage Service(S3)에 빌드된 데이터 레이크를 사용하면 빅 데이터 분석을 쉽게 실행하고 기계 학습을 사용하여, 반구조화된 데이터 세트(예: JSON, XML)와 구조화되지 않은 데이터로부터 통찰력을 얻을 수 있습니다.
오늘 AWS는 데이터 웨어하우스 관리 및 데이터 레이크와의 통합 방식을 개선하는 데 도움을 주는 두 가지 새로운 기능을 출시합니다.
- 데이터 레이크 내보내기는 Redshift 클러스터의 데이터를 분석용으로 최적화된 효율적인 개방형 열 스토리지 형식인 Apache Parquet 형식으로 S3에 언로드합니다.
- 통합 질의를 사용하면 Redshift 클러스터에서 해당 클러스터의 데이터, S3 데이터 레이크의 데이터 및 하나 이상의 PostgreSQL용 Amazon Relational Database Service(RDS) 및 PostgreSQL용 Amazon Aurora 데이터베이스의 데이터를 쿼리할 수 있습니다.
이 아키텍처 다이어그램은 이러한 기능이 작동하는 방식 및 이러한 기능을 다른 AWS 서비스와 함께 사용하는 방식을 간략하게 보여 줍니다.
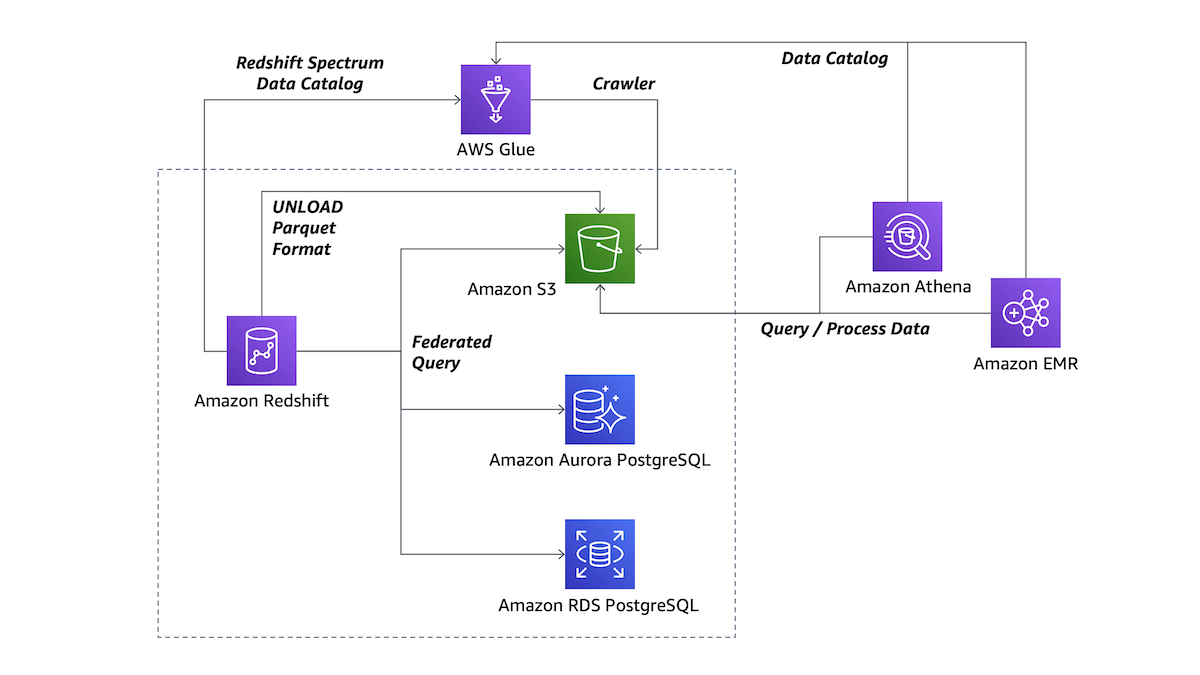
기능 사용 방법과 기능의 이점을 시작으로 다이어그램에 나와 있는 상호 작용에 대해 설명하겠습니다.
Redshift 데이터 레이크 내보내기 사용
Redshift 쿼리의 결과를 S3 데이터 레이크에 Apache Parquet 형식으로 언로드할 수 있습니다. Parquet 형식은 텍스트 형식에 비해 언로드 속도가 2배 빠르며S3에서 스토리지를 최대 6배 적게 사용합니다. 이를 통해 Redshift에서의 데이터 변환 및 보강 정보를 S3 데이터 레이크에 오픈 형식으로 저장할 수 있습니다.
그런 다음 S3에 있는 파일에서 직접 데이터를 쿼리할 수 있는 Redshift의 Redshift Spectrum 기능을 사용하여 데이터 레이크의 데이터를 분석할 수 있습니다. Amazon Athena, Amazon EMR 또는 Amazon SageMaker 같은 다른 도구로 이 작업을 수행할 수도 있습니다.
이 새로운 기능을 사용하려면 Redshift 콘솔에서 새 클러스터를 생성하고, 이 자습서에 따라 여러 장소에서 진행되는 음악 이벤트의 매출을 추적하는 샘플 데이터를 로드합니다. 이 데이터를 데이터 레이크에 저장되어 있는 이벤트에 대한 소셜 미디어 댓글과 연결하겠습니다. 각 이벤트의 관련성을 이해하려면 각 이벤트의 상대적 매출을 다른 이벤트와 비교할 수 있는 방법이 있어야 합니다.
S3로 데이터를 내보내는 쿼리를 Redshift에서 작성해보겠습니다. 데이터는 현재 여러 개의 테이블에 저장되어 있습니다. 따라서, 매출 현황을 한 눈에 파악할 수 있는 쿼리를 생성해야 합니다. sales 테이블과 date 테이블의 콘텐츠를 조인하여 이벤트의 총 매출에 대한 정보(쿼리에서 total_price) 및 모든 이벤트와 비교한 전체 총 매출의 백분위수에 대한 정보를 추가하려고 합니다.
쿼리 결과를 Parquet 형식으로 S3에 내보내기 위해 다음 SQL 명령을 사용합니다.
UNLOAD ('SELECT sales.*, date.*, total_price, percentile
FROM sales, date,
(SELECT eventid, total_price, ntile(1000) over(order by total_price desc) / 10.0 as percentile
FROM (SELECT eventid, sum(pricepaid) total_price
FROM sales
GROUP BY eventid)) as percentile_events
WHERE sales.dateid = date.dateid
AND percentile_events.eventid = sales.eventid')
TO 's3://MY-BUCKET/DataLake/Sales/'
FORMAT AS PARQUET
CREDENTIALS 'aws_iam_role=arn:aws:iam::123412341234:role/myRedshiftRole';S3 버킷에 대한 쓰기 권한을 Redshift에 부여하기 위해 AWS Identity and Access Management(IAM) 역할을 사용합니다. UNLOAD 명령의 결과는 AWS CLI(명령줄 인터페이스)를 사용하여 볼 수 있습니다. 예상대로 쿼리 출력이 Parquet 열 데이터 형식으로 내보내집니다.
$ aws s3 ls s3://MY-BUCKET/DataLake/Sales/
2019-11-25 14:26:56 1638550 0000_part_00.parquet
2019-11-25 14:26:56 1635489 0001_part_00.parquet
2019-11-25 14:26:56 1624418 0002_part_00.parquet
2019-11-25 14:26:56 1646179 0003_part_00.parquet
데이터에 대한 액세스를 최적화하려면 언로드된 데이터가 S3 버킷의 폴더에 자동으로 파티셔닝되도록 하나 이상의 파티션 열을 지정할 수 있습니다. 예를 들어 매출 데이터를 연도, 월 및 일별로 파티셔닝하여 언로드할 수 있습니다. 이렇게 하면 쿼리에 파티션 삭제 기능을 활용하여 관련 없는 파티션에 대한 스캔을 건너뜀으로써 쿼리 성능을 높이고 비용을 최소화할 수 있습니다.
파티셔닝을 사용하려면 이전 SQL 명령에 PARTITION BY 옵션을 추가한 후 데이터를 여러 디렉터리에 파티셔닝하는 데 사용할 열을 이어서 추가해야 합니다. 매출의 연도와 달력 날짜(쿼리에서 caldate)를 기준으로 출력을 파티션닝하겠습니다.
UNLOAD ('SELECT sales.*, date.*, total_price, percentile
FROM sales, date,
(SELECT eventid, total_price, ntile(1000) over(order by total_price desc) / 10.0 as percentile
FROM (SELECT eventid, sum(pricepaid) total_price
FROM sales
GROUP BY eventid)) as percentile_events
WHERE sales.dateid = date.dateid
AND percentile_events.eventid = sales.eventid')
TO 's3://MY-BUCKET/DataLake/SalesPartitioned/'
FORMAT AS PARQUET
PARTITION BY (year, caldate)
CREDENTIALS 'aws_iam_role=arn:aws:iam::123412341234:role/myRedshiftRole';
이번에는 쿼리의 출력이 여러 파티션에 저장됩니다. 예를 들어 다음은 특정 연도와 날짜에 해당하는 폴더의 콘텐츠입니다.
$ aws s3 ls s3://MY-BUCKET/DataLake/SalesPartitioned/year=2008/caldate=2008-07-20/
2019-11-25 14:36:17 11940 0000_part_00.parquet
2019-11-25 14:36:17 11052 0001_part_00.parquet
2019-11-25 14:36:17 11138 0002_part_00.parquet
2019-11-25 14:36:18 12582 0003_part_00.parquet
필요에 따라 AWS Glue를 사용하여, (온디맨드 방식 또는 일정에 따라) S3 버킷에서 데이터를 검색한 후Glue 데이터 카탈로그를 업데이트하는 크롤러를 설정할 수 있습니다. 데이터 카탈로그가 업데이트되면 Redshift Spectrum, Athena 또는 EMR을 사용하여 데이터를 쉽게 쿼리할 수 있습니다.
이제 매출 데이터를 데이터 레이크 내의 구조화되지 않은 데이터 및 반구조화된 데이터(JSON, XML, Parquet)와 함께 처리할 준비가 되었습니다. 예를 들어, 이제 EMR을 사용하는 Apache Spark 또는 모든 Sagemaker 기본 제공 알고리즘을 사용하여 데이터에 액세스하고 새로운 통찰력을 얻을 수 있습니다.
Redshift 통합 질의 사용
RDS 및 Aurora PostgreSQL 저장소에 있는 데이터를 Redshift 데이터 웨어하우스에서 직접 액세스할 수 있습니다. 이렇게 하면 데이터를 사용할 수 있는 즉시 액세스할 수 있습니다. 이제부터는 ETL 작업을 통해 데이터를 데이터 웨어하우스에 전송할 필요 없이 데이터 웨어하우스, 트랜잭션 데이터베이스 및 데이터 레이크에 있는 데이터를 처리하는 쿼리를 Redshift에서 직접 수행할 수 있습니다.
Redshift는 고급 최적화 기능을 활용하여 계산의 상당한 부분을 트랜잭션 데이터베이스에 푸시 다운하여 분산시킴으로써 네트워크를 통해 이동하는 데이터의 양을 최소화합니다.
이 구문을 사용하면 RDS 또는 Aurora PostgreSQL 데이터베이스의 외부 스키마를 Redshift 클러스터에 추가할 수 있습니다.
CREATE EXTERNAL SCHEMA IF NOT EXISTS online_system
FROM POSTGRES
DATABASE 'online_sales_db' SCHEMA 'online_system'
URI ‘my-hostname' port 5432
IAM_ROLE 'iam-role-arn'
SECRET_ARN 'ssm-secret-arn';여기서 스키마와 포트는 선택 사항입니다. 지정하지 않을 경우, 스키마의 기본값은 public이고, PostgreSQL 데이터베이스의 기본 포트는 5432입니다. Redshift는 외부 데이터베이스에 연결하는 자격 증명을 관리하는 데 AWS Secrets Manager를 사용합니다.
이 명령을 사용하면 외부 스키마의 모든 테이블을 사용할 수 있습니다. 또한 Redshift는 클러스터 또는 S3 데이터 레이크(Redshift Spectrum을 사용할 경우) 내의 데이터를 처리하는 모든 복잡한 SQL 쿼리에 이러한 테이블을 사용할 수 있습니다.
앞에서 사용한 매출 데이터 예제로 돌아가서 이제 음악 이벤트에 대한 기록 데이터의 추세와 실시간 매출을 연결할 수 있습니다. 이렇게 하면 이벤트가 기대한 만큼 성과가 있는지 여부를 파악하고 마케팅 활동을 지연 없이 조정할 수 있습니다.
예를 들어 Redshift 클러스터에서 온라인 상거래 데이터베이스를 online_system 외부 스키마로 정의한 후에는 다음과 같은 간단한 쿼리를 사용하여 이전 매출과 온라인 상거래 시스템의 매출을 비교할 수 있습니다.
SELECT eventid,
sum(pricepaid) total_price,
sum(online_pricepaid) online_total_price
FROM sales, online_system.current_sales
GROUP BY eventid
WHERE eventid = online_eventid;Redshift에서는 데이터베이스 또는 스키마 카탈로그 전체를 가져오지 않습니다. 쿼리를 실행하면 Redshift는 쿼리의 일부인 Aurora 및 RDS 테이블(보기 포함)의 메타데이터를 로컬라이즈합니다. 로컬라이즈된 이 메타데이터는 쿼리를 컴파일하고 계획을 생성하는 데 사용됩니다.
지금 이용 가능
Amazon Redshift 데이터 레이크 내보내기는 데이터 처리 파이프라인을 개선하는 새로운 도구로, Redshift 릴리스 버전 1.0.10480 이상에서 지원됩니다. AWS 리전 표에서 Redshift 가용성을 참조하고 클러스터의 버전을 확인하십시오.
Amazon Redshift의 새로운 연동 기능은 공개 평가판으로 출시되며, Redshift, S3 및 하나 이상의 RDS 및 Aurora PostgreSQL 데이터베이스에 저장되어 있는 데이터를 가져오는 데 사용할 수 있습니다.. Amazon Redshift 관리 콘솔에서 클러스터를 생성할 때 세 가지 유지 보수 트랙인 Current, Trailing 또는 Preview를 선택할 수 있습니다. 통합 질의 공개 평가판에 참여하려면 Preview 트랙 내에서 preview_features를 선택해야 합니다. 예:

이러한 기능은 데이터 처리를 간소화하며 보다 신속하게 대응할 수 있는 다양한 도구 및 데이터에 대한 단일 보기를 제공합니다. 앞으로 이 기능을 어떻게 사용할 것인지에 대해 경험을 공유해주십시오!
— Danilo