Front-End Web & Mobile
Getting started with JavaScript resolvers in AWS AppSync GraphQL APIs
AWS AppSync is a managed service that makes it easy to build scalable APIs that connect applications to data. Developers use AppSync every day to build GraphQL APIs that interact with datasources like Amazon DynamoDB, AWS Lambda, and HTTP APIs. For example, you can connect to an Amazon DynamoDB table, and implement your data access logic directly in your AppSync resolver.
Until now, developers could only use the Velocity Template Language (VTL) to implement their AppSync business logic. While powerful, VTL has proven challenging for many developers that are not familiar with the templating language. We are happy to announce that you can now use JavaScript to write your AppSync pipeline resolver code and AppSync function code. In this post, we’ll give you an overview of the feature, and show you how to get started with JavaScript resolvers
Quick recap
Before jumping in, let’s revisit some core AppSync concepts. AppSync allows you to define data sources, resolvers, and functions. Resolvers instruct AppSync on how to handle GraphQL requests, and map responses back to your GraphQl types. AppSync resolvers can be configured with up to 10 functions in a pipeline, each attached to a data source. When the resolver is invoked, each function is executed in sequence.
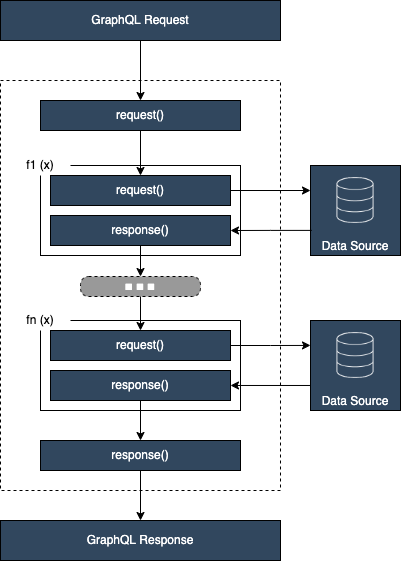
Figure 1. Pipeline resolver overview
- Interacting with DynamoDB, Amazon OpenSearch Service, AWS Lambda, and Amazon Aurora Serverless
- Interacting with HTTP APIs and passing incoming headers
- Interacting with AWS services using HTTP data sources (with AWS AppSync automatically signing requests with the provided data source role)
- Implementing access control before accessing data sources
- Implementing filtering of retrieved data prior to fulfilling a request
- Controlling caching and subscription connections in queries and mutations.
And of course, in situations where you need to implement complex business logic that is not supported by the APPSYNC_JS runtime, you can always use a Lambda data source as a proxy to interact with your target data source.
How it works
To define a resolver or function using JavaScript, you provide a code file that exports 2 functions: a request handler and a response handler. The request handler takes a context object as an argument and returns a request payload in the form of a JavaScript object used to call your data source. You can find details on supported request objects in the Resolver reference (JavaScript) documentation. The response handler receives a payload back from the data source with the result of the executed request. The response handler transforms this payload into an appropriate format and returns it.
In the example below, a request handler retrieves an item from a DynamoDB data source. In the response handler, the __typename is extracted from the category, a message is logged, and the original result along with the type is returned.
import { util } from '@aws-appsync/utils';
/**
* Request a single item with `id` from the attached DynamoDB table datasource
* @param ctx contextual information about the request
*/
export function request(ctx) {
const { args: { id } } = ctx
return {
operation: 'GetItem',
key: util.dynamodb.toMapValues(id)
}
}
/**
* Returns the result directly
* @param ctx contextual information about the response
*/
function response(ctx) {
const { result } = ctx;
// category has format: Type#subtype#
const typename = result.category.split('#')[0];
console.log(`result ${result.id} -> type: ${typename}`);
return {
...result,
__typename: typename,
};
}You define your pipeline resolver in a similar way. A pipeline resolver has “before” and “after” logic that surrounds the execution of the functions in the pipeline: its request handler is run before the first function’s request, and its response handler is run after the last function’s response. The resolver “before” logic can set up data to be used by functions in the pipeline. The resolver “after” logic is responsible for returning data that maps to the GraphQL field output type. Here is resolver code that does not have an execution logic in its request handler, and returns the result of its last function in its response handler. This resolver code is suitable for use cases where no pre- or post- data handling is required.
export function request(ctx) {
return {}
}In your code you can import and use utilities from the @aws-appsync/utils package. This package exports the util and extensions modules that provide utilities that makes it easier to interact with your data and your data sources. For example, when it comes to building DynamoDB requests, I am a big fan of the util.dynamodb.toMapValues utility. You can pass it an object of values, and it translates it into a object of values in their appropriate DynamoDB format. You can use ID generation utils like util.autoId() create a unique 128-bit randomly generated UUID. Within a code IDE like VScode, the package provides auto-completion and documentation of all the available utilities.
To define your resolvers and functions, you can use the AWS CLI, AWS Cloudformation, AWS CDK, or use the AppSync console. For example, to create a new JavaScript pipeline resolver, you simply need to specify the runtime, and the version of the runtime to use. Right now the only runtime available is APPSYNC_JS with a runtime version of “1.0.0”.
$ aws appsync create-function --api-id "<api-id>" \
--name "<function-name>" \
--code "file://<file-location>" \
--data-source-name "<data-source-name>" \
--runtime name=APPSYNC_JS,runtimeVersion=1.0.0What type of functionality is supported?
The APPSYNC_JS runtime provides functionality similar to the ECMAScript (ES) version 6.0, and supports a subset of its features. You can find a full list of features in the resolver reference documentation. Because the APPSYNC_JS runtime is designed to run within an AppSync context, there are certain JavaScript features that are not supported. For example, network and file access is not possible and async/await or promises are not available. To support your coding experience in your IDEs, you can use the new eslint plugin @aws-appsync/eslint-plugin that can warn you of unsupported features in your code. To use the linting rules in your project, start by installing the package:
If you need to set up eslint in your project. Run:
In the generated eslint configuration file, add or updates the extends property:
When you save your resolver or function JavaSCript code, the AppSync service also validates your code, thus ensuring that runtime errors do not occur due to “bad” code or code using unsupported features.
Creating your first JavaScript resolver
We recently published a pattern on Serverless Land that shows how to build an AppSync GraphQL API that publishes message to an Amazon SNS topic. Let’s use that pattern to set up a GraphQL API and walk through changing the resolver from VTL to JavaScript. The CDK stack defines an AppSync GraphQL API and sets up SNS as a HTTP data source. The schema is:
With HTTP data sources, you can easily communicate with AWS service APIs from AppSync. You set up your data source with an IAM role that grants AppSync permission to access the resource. When you make you use a GraphQl query or mutation to access the data source. AppSync signs the request using the provided role.

AppSync to SNS
To begin with, deploy the stack following the instructions at https://serverlessland.com/patterns/appsync-sns-cdk. The steps are as followed:
git clone https://github.com/aws-samples/serverless-patterns/
cd serverless-patterns/cdk-appsync-sns
npm install
npm run build
npm run cdk deployThis deploys an AppSync GraphQL API called ToSnSApi. Once deployment is done, head to the AWS AppSync console in your region, and choose ToSnSApi from the API list. In the left side menu, choose Schema. In the schema editor, click on sns next to the publish field.
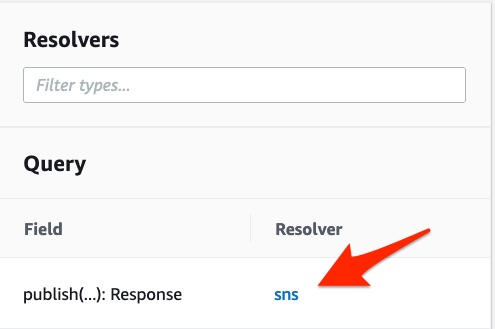
Select the publish resolver
In the resolver screen, make note and copy the SNS topic ARN. You will use it in your JavaScript resolver. Click on Convert to pipeline resolver, and choose Convert to confirm. This transforms your resolver into a JavaScript pipeline resolver and saves your current VTL code to a new function.
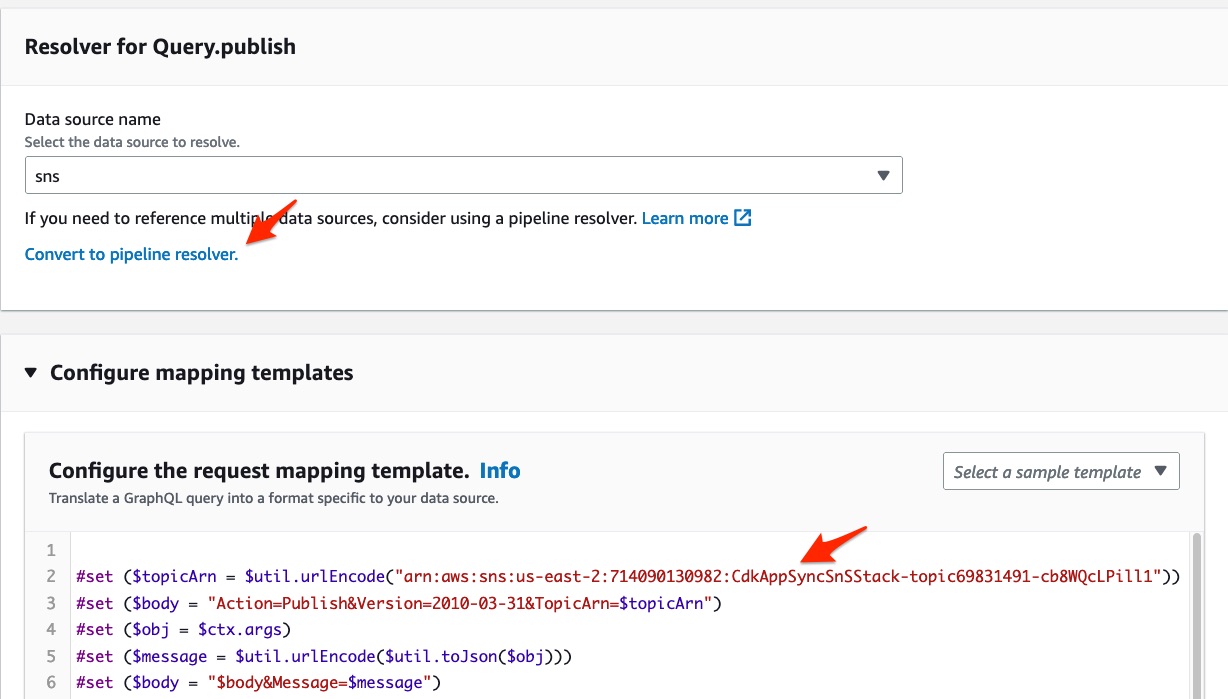
convert the resolver
Now, update your resolver code with the sample below, and replace <your-topic-arn> with your own value. Choose save. Here we are using the pipeline resolver to save the TOPIC_ARN in the stash. That way, we do not hardcode the value in our function. If we add another publish method to our schema that sends messages to another SNS topic, we can reuse the function and pass that specific topic ARN via the stash.
export function request(ctx) {
ctx.stash.TOPIC_ARN = '<your-topic-arn>'
return {};
}
export function response(ctx) {
return ctx.prev.result;
}In the Functions section below, click on your function name to navigate to the function definition.
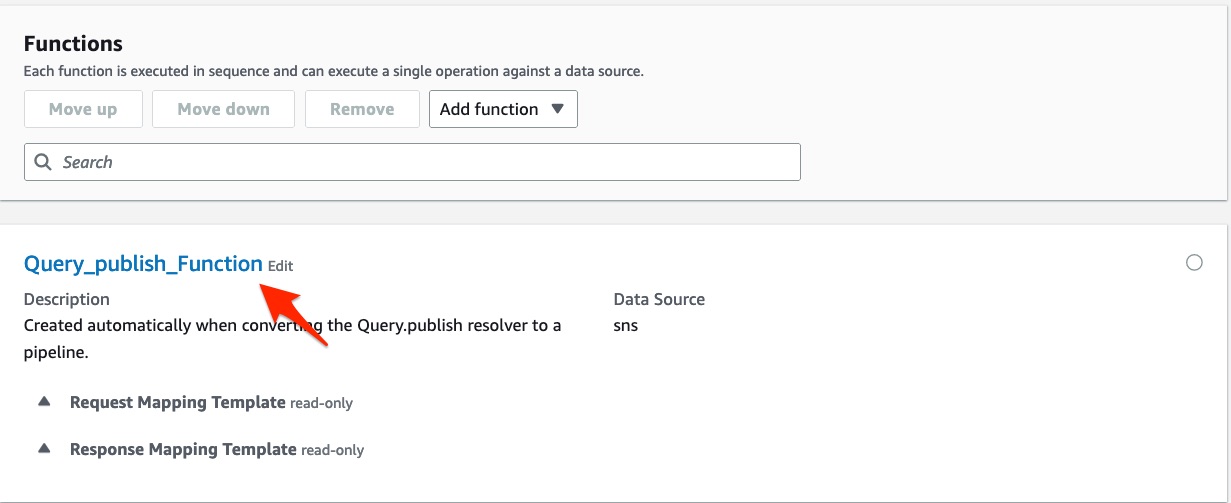
functions section
In the function screen, choose Actions in the top right menu, then choose Update Runtime and select the APPSYNC_JS runtime option. This changes your resolver configuration from VTL to APPSYNC_JS.
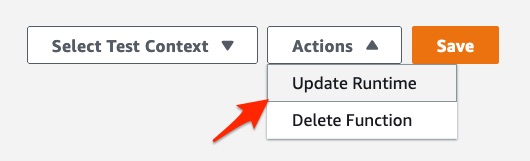
update the runtime
Update your code with the sample below and choose Save. In the code, the request handler grabs the TOPIC_ARN from the stash, and the message from the arguments. It then calls the publishToSNSRequest function to return a valid SNS publish request. In the response handler, we check the status code. if the value is 200, then the request was succesful and we extract the result from the body. Otherwise, we append an error to our GraphQL response. We use the util.xml.toMap utility to convert the XML response to a JavaScript object.
import { util } from '@aws-appsync/utils';
export function request(ctx) {
const { TOPIC_ARN } = ctx.stash;
const { message } = ctx.arguments;
return publishToSNSRequest(TOPIC_ARN, message);
}
export function response(ctx) {
const result = ctx.result;
if (result.statusCode === 200) {
// if response is 200
// Because the response is of type XML, we are going to convert
// the result body as a map and only get the User object.
const body = util.xml.toMap(result.body)
console.log('respone body -->', body)
return body.PublishResponse.PublishResult;
}
// if response is not 200, append the response to error block.
util.appendError(result.body, `${result.statusCode}`);
}
function publishToSNSRequest(topicArn, values) {
const arn = util.urlEncode(topicArn);
const message = util.urlEncode(JSON.stringify(values));
const parts = [
'Action=Publish',
'Version=2010-03-31',
`TopicArn=${arn}`,
`Message=${message}`,
];
const body = parts.join('&');
return {
method: 'POST',
resourcePath: '/',
params: {
body,
headers: {
'content-type': 'application/x-www-form-urlencoded',
},
},
};
}To use your query, click on Queries in the left side menu, and send this query:
This sends your message to your SNS topic and its subscribers. The response:
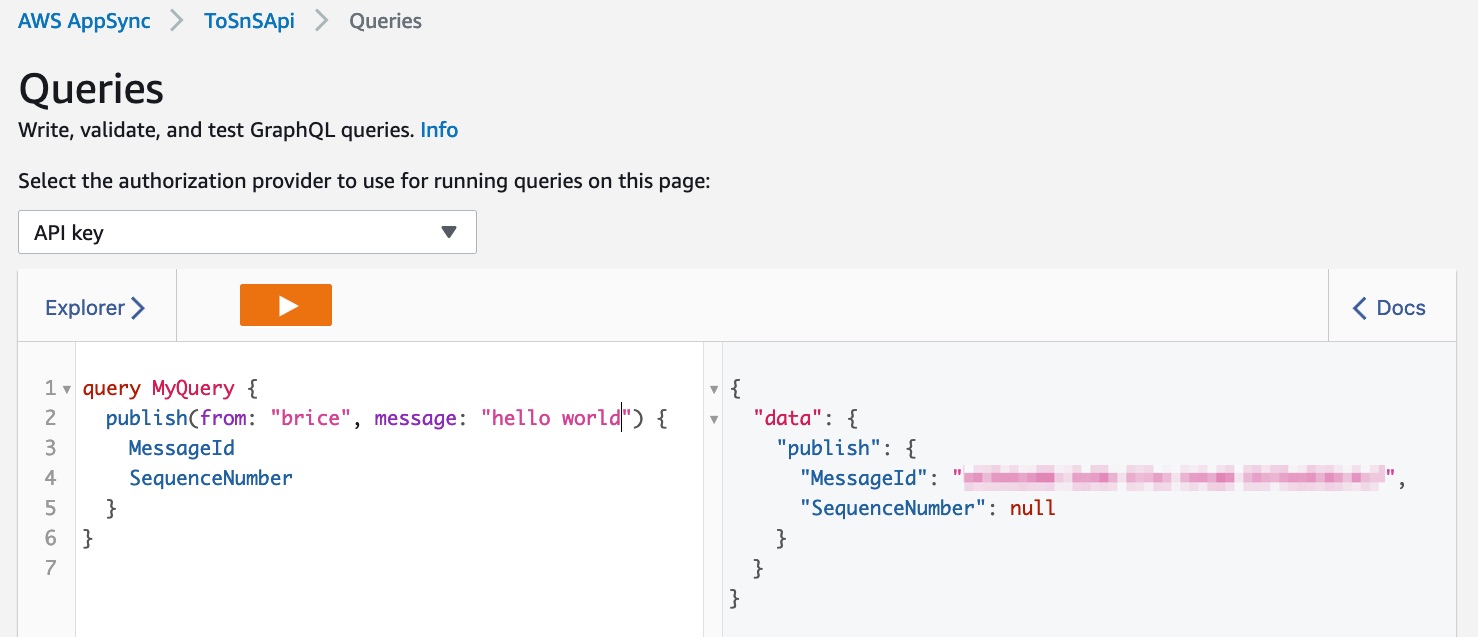
GraphQL query response
With logging enabled on the API, I can find my logs in Amazon CloudWatch Logs with the location of where the log statement was made:
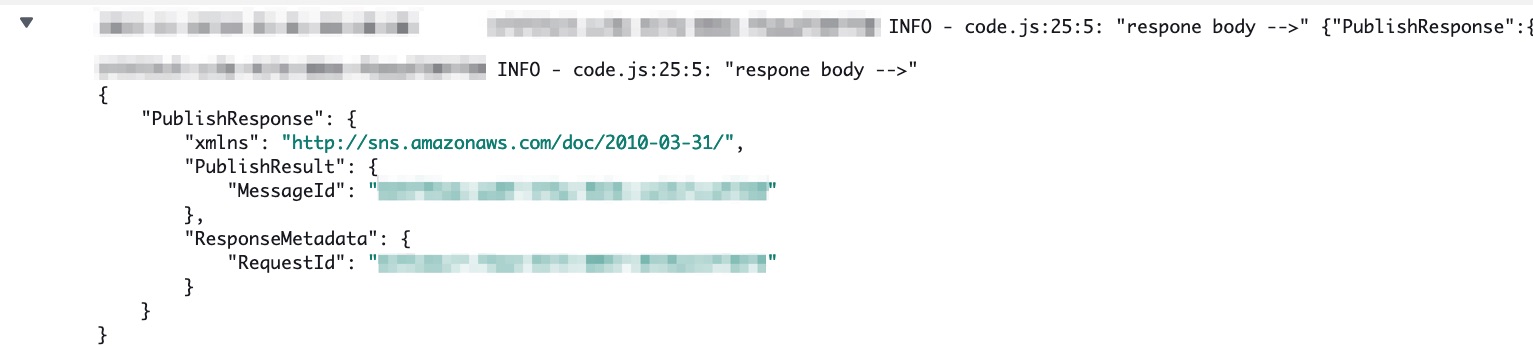
execution logs
Migrating from VTL
If you are migrating from VTL, you can get started with JavaScript in a couple of ways. Pipeline resolvers can use functions written in VTL or JavaScript, so you can start adding JavaScript functions to your existing pipeline resolvers. This helps if you want to migrate your functions progressively over time. If you are using a VTL unit resolver, you can turn it into a VTL function and add it to a JavaScript pipeline resolver. You can then validate the behavior of your entire resolver before replacing your VTL function with a JavaScript function. You can tranform your resolver in the AWS console (as shown above). Remember that valid VTL templates evaluate to JSON-encoded strings. When building a request in a function request handler or returning a result in a response handler, you should not return strings. Instead, you directly return the object that defines the request you want AppSync to make, or you return the data that is needed for your specific response.
Conclusion
With the introduction of JavaScript resolvers, developers now have access to their preferred programing language to write their AppSync business logic. The feature is now available in all regions where AppSync is supported. To get started, visit our documentation, take a look at our DynamoDB tutorial, and visit the aws-appsync-resolver-samples repo.
About the author: