Amazon Web Services ブログ
創薬ワークフローハンズオン~ Amazon Comprehend Medicalを利用したSNS/論文分析~
創薬研究において、クラウドリソースの活用は有用です。例えば、大規模計算に必要なHPC環境を必要な時に瞬時に立ち上げて処理したり、目視による画像分類・判別を機械学習により自動化する事で、従来多くの時間がかかっていた業務を短縮することができ、創薬プロセスを飛躍的に効率化することが可能です。しかしながら、クラウドのサービスやソリューションが業務にフィットするか検証するために、計算環境や機械学習環境を構築するには手間と時間がかかります。そのため、ヘルスケア・ライフサイエンスチームでは、創薬ワークフローに対するハンズオンといった業界特化のソリューションを提供することで、機能やソリューションが業務にフィットするかユーザの方々に体感頂いております(例えば、「化合物の溶解度予測」の内容はこちらに記載しています)。今回、当該ハンズオンに対してご要望の多かった、「AWS CloudFormation (以下、CFn)によるテンプレート化」を2つのハンズオンコンテンツで実装し、数回のクリックだけでご自身の環境にDeployできるようにしました。これにより、幅広いユーザーの方に利用頂き、ソリューションを体感頂ければと思います。
創薬研究において、学術論文から新薬開発のアイデアを得る事は勿論、近年ではSNSのデータを活用して新薬開発の糸口を見つけるというように、様々なデータソースを活用した取組みが行われています。しかし、このような多様かつ大量なデータソースから必要な情報を抽出して洞察を得る事は、時間的に困難になっています。そこで、今回のソリューションでは、機械学習のサービスであるAmazon Comprehend Medicalを利用して、論文またはSNSの情報を定期的に取得・自動カテゴリ化して蓄積し、ユーザーは任意のタイミングでBIツールで可視化・分析する事で短時間で必要な情報をピックアップし、洞察を得ることができます。
免責事項:今回紹介するソリューションではAmazon Comprehend Medicalを利用しています。データの取り扱いに関して、こちらのガイドラインを事前にご確認ください。
Amazon Comprehend Medicalとは
Amazon Comprehend Medicalとは、機械学習を使用して非構造化テキストデータから医療情報を抽出する自然言語処理サービスです。例えば、以下のようなテキスト情報をAmazon Comprehend Medicalで処理すると、テキスト内の医療関連のWordを保護医療情報(PHI)、症状、薬剤などにカテゴリ化して、関連性も抽出してくれます。また、検出された情報を ICD-10-CM や RxNorm といった医療オントロジーとリンクすることも可能です。APIの詳細については、こちらを参照ください。
Mr. Smith is a 63-year-old gentleman with coronary artery disease and hypertension. CURRENT MEDICATIONS: taking a dose of LIPITOR 20 mg once daily.
ソリューションの概要
各ハンズオンのアーキテクチャは、以下になります。
Hands-on 1 (所要時間 15 min):PubMed上の医療情報の可視化・分析

Hands-on 2 (所要時間 15 min):Twitter上の医療情報の可視化・分析

両アーキテクチャは類似しており、差異は以下になります。
- データソース
- AWS Lambdaの処理内容
- Amazon Translateの有無
- Hands-on 2では、Twitterで日本語のテキスト情報を取得しています。Blog執筆時点はAmazon Comprehend Medicalが日本語サポートされていないため、Amazon Translateでテキスト情報を英語に変換する処理を加えています。Hands-on 1はデータソースが英語の論文のため、Amazon Translateを使用していません。
ワークフローは以下のStepです。
- Amazon CloudWatch Events(スケジュール実行)でAWS Lambdaを実行
- AWS Lambdaにて、データソースからAWS Lambdaの環境変数で指定したキーワード(後述するCFnのParametersで初期設定)にマッチしたデータを抽出し、Amazon Comprehend Medicaでカテゴリ化
- 処理が完了したデータをAmazon Kinesis Data Firehose経由で、Amazon S3(以下、S3)に保存
- AWS GlueでS3に保存されたデータの構造を解析し、Data Catalogを作成
- Data CatalogをもとにAmazon AthenaでS3内のデータにクエリを実行
- Amazon QuickSightで、クエリの結果を可視化・分析
前提条件
- AWS アカウントの作成
- こちらのソリューションを利用するにはAWSアカウントが必要です。作成されていない方は、こちらから作成可能です。
- Regionについて
- こちらのソリューションは、US East (N. Virginia) Regionを利用するため、後述するAmazon QuickSightのリージョンはUS East (N. Virginia) Regionをご利用ください。
- IAMについて
- このソリューションは、CFnを利用してソリューションを作成し、Amazon QuickSightで分析・可視化します。そのため、ユーザーにはこれらを実行できる適切なIAM権限を付与してください。
- (Hands-on 2のみ) Twitterアカウントの作成とTwitter APIの登録申請
- Hands-on 2ではTweepyを利用するため、事前に Twitterアカウントの作成とAPIの登録申請が必要です。
手順とセットアップ
上記で説明したソリューションのCFnテンプレートを個々に用意しております。ご興味のある、もしくは実施したいハンズオンを選択してください。CFnテンプレートにより、Amazon QuickSight以外のリソースが自動的に作成されます。後段で説明するAmazon QuickSightの設定に関しては、両ハンズオンで同様の手順となっております。
1. ソリューション環境構築
実施したいハンズオンの「Launch Stack」をクリックしてください。CFnテンプレートが起動すると、各ハンズオンごとに以下のパラメータ入力が求められますので、手順に従って入力してCreate Stackを選択してください。両ハンズオンとも3 minほどでリソースが作成されます。
Hands-on 1
![]()
- Parameters
- MaxDate:論文検索したい範囲の終了月 e.g. 2020/07
- MinDate:論文検索したい範囲の開始月 e.g. 2020/02
- Term:検索したい論文のKeyword e.g. cancer
Hands-on 2
![]()
- Parameters
- AccessToken:Twitter DeveloperのAccess Token
- AccessTokenSecret:Twitter DeveloperのAccess Token Secret
- ConsumerApiKey:Twitter DeveloperのAPI Key
- ConsumerApiSecretKey:Twitter DeveloperのAPI Secret key
- GetHashTag:検索対象のハッシュタグ(カンマ区切りで複数選択可能) e.g. #花粉症, #副作用
CFnで作成されたリソースに関しては、下図のようにCloudFormationのリソース画面で確認可能です。

2. Amazon QuickSightの設定
AWSマネージメントコンソールの検索窓から「quick」と入力し、Amazon QuickSightのページに遷移してください。ここでは、Hands-on 1についての設定手順を示しています。Amazon QuickSightのアカウントが未作成の場合は、下図のように「Sign up for QuickSight」が表示されますので、クリック後以下の「2-1. Amazon QuickSightアカウントをお持ちでない方」の手順に従って、アカウントを作成してください。既にアカウント作成済みの場合は、「2-2. Amazon QuickSightアカウントを既にお持ちの方」の手順に従って設定を行ってください。

2-1. Amazon QuickSightアカウントをお持ちでない方
Standardを選択して「Continue」をクリック。

Amazon QuickSightのregionが「US East (N. Virginia)」である事を確認し、Amazon AthenaとAmazon S3にチェックを入れて、S3 bucketには、CFnで作成されたバケットを選択(Hands-on 1だと接頭辞に“hclsworkshop1”と記載)。CFnで作成されたリソースに関しては、CloudFormationのリソース画面で確認可能です。QuickSight account nameとNotification email addressに任意の値を入力して、最後にFinishをクリックするとアカウントが作成されます。


画面右上の言語設定で「日本語」を選択して、「Go to Amazon QuickSight」をクリック。以上で設定は完了です。

2-2. Amazon QuickSightアカウントを既にお持ちの方
Amazon QuickSightの画面右上のユーザー名を選択し、「QuickSightの管理」をクリック。

「セキュリティとアクセス権限」を選択し、「選択された製品とサービス」項目の「追加または削除する」をクリック。
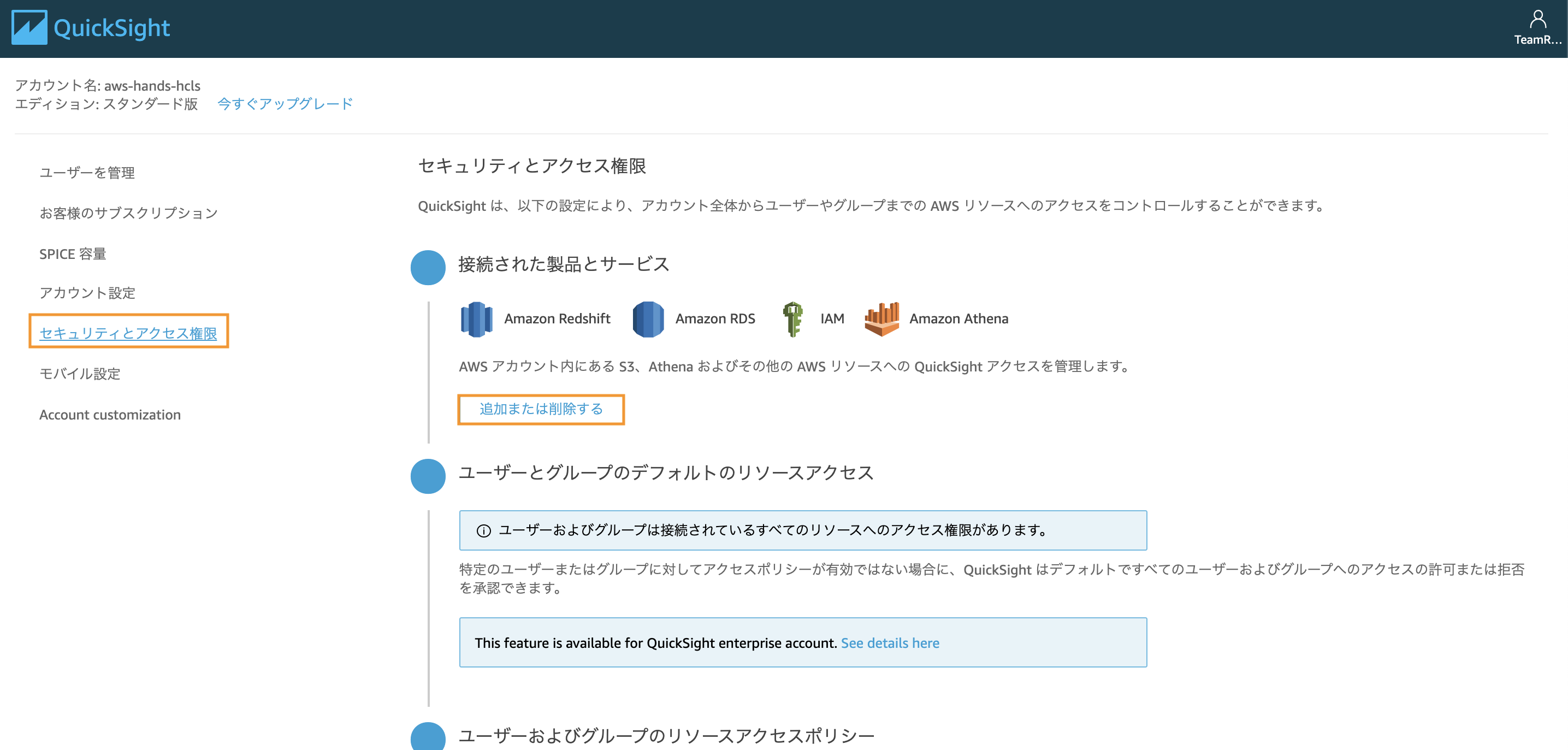
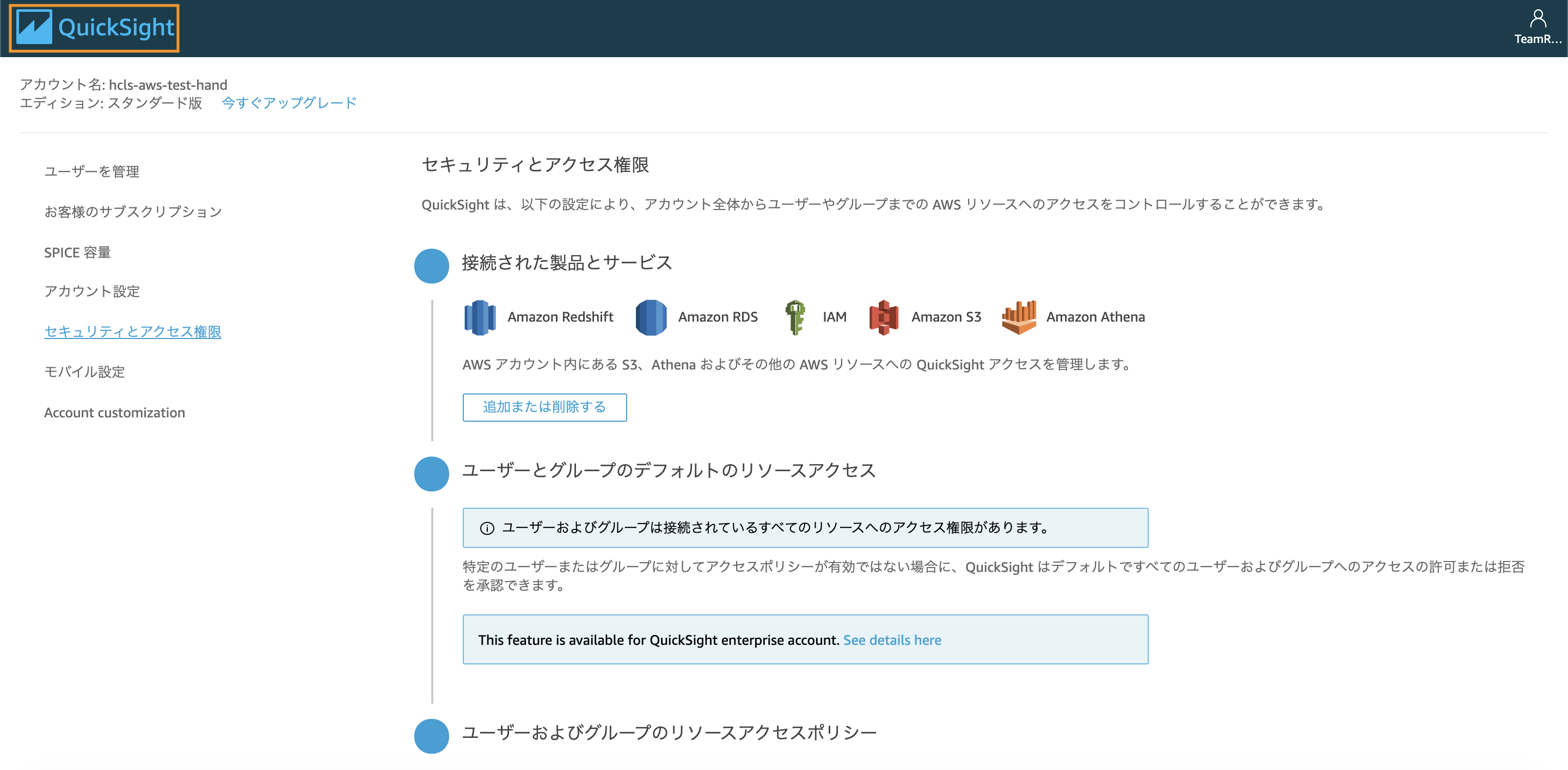
Amazon AthenaとAmazon S3にチェックを入れてください。

CFnで作成されたバケット(Hands-on 1だと接頭辞に“hclsworkshop1”と記載)にチェックを入れて、画面右下の「バケットの選択」をクリック。

画面右下の「更新」をクリックして設定完了です。

最後に、画面左上のQuickSightのアイコンをクリックしてください。
ソリューションの活用例
ここではHands-on 1のソリューション環境でのデータ分析の例を示します。Hands-on 2のソリューションに関しても、同様の手順でデータ分析が可能です。画面右上の「新しい分析」> 「新しいデータセット」の順に画面遷移し、Athenaを選択してください。

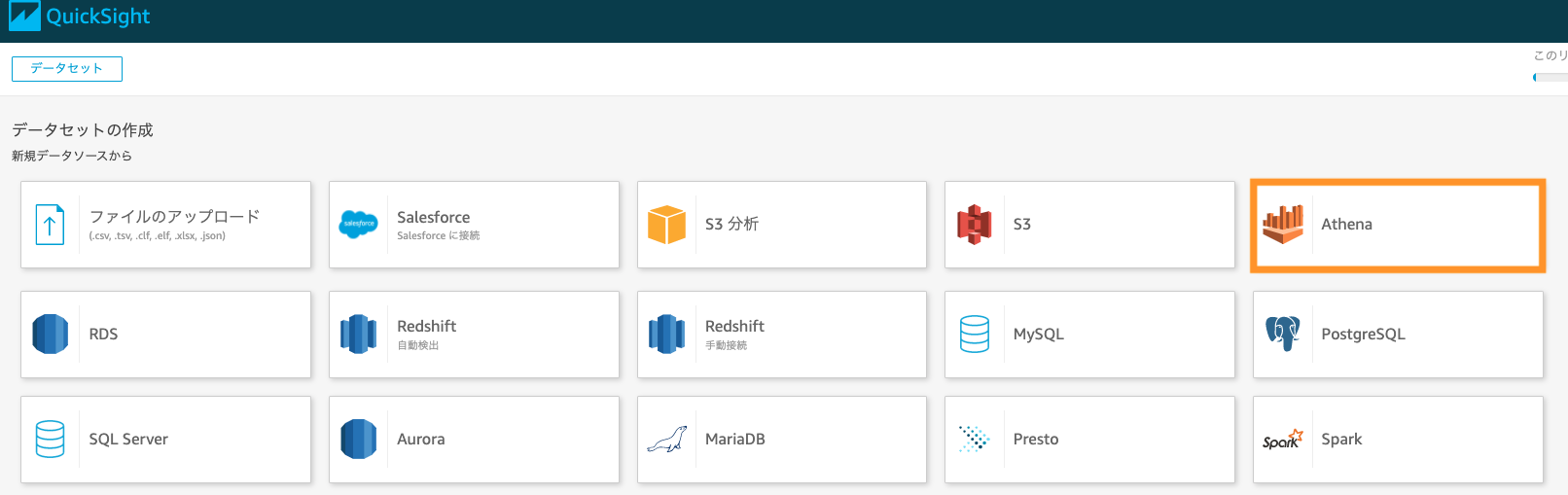
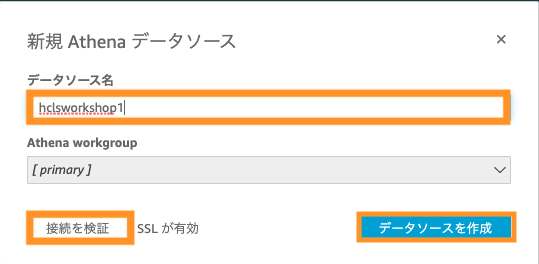
データソースに任意の値を入力して、画面左下の「接続を検証」をクリック。「検証済み」の表示後、画面右下の「データソースを作成」をクリック。
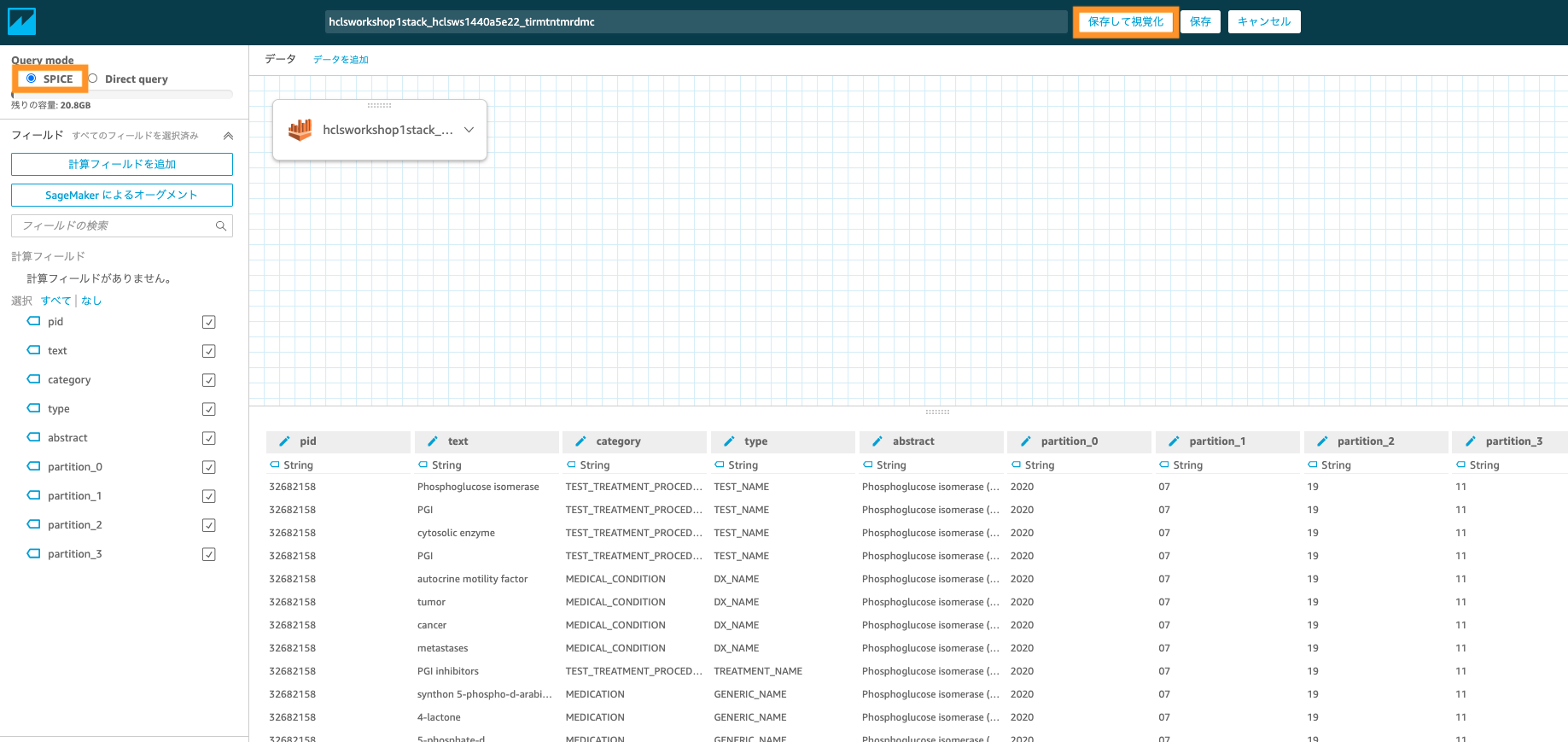
クローラで作成されたデータベース(Hands-on 1だと、hcls-ws1-db)を選択し、表示されるテーブルを選択。最後に「データの編集/プレビュー」をクリック。

画面左上のSPICEを選択し、画面上部の「保存して視覚化」をクリック。
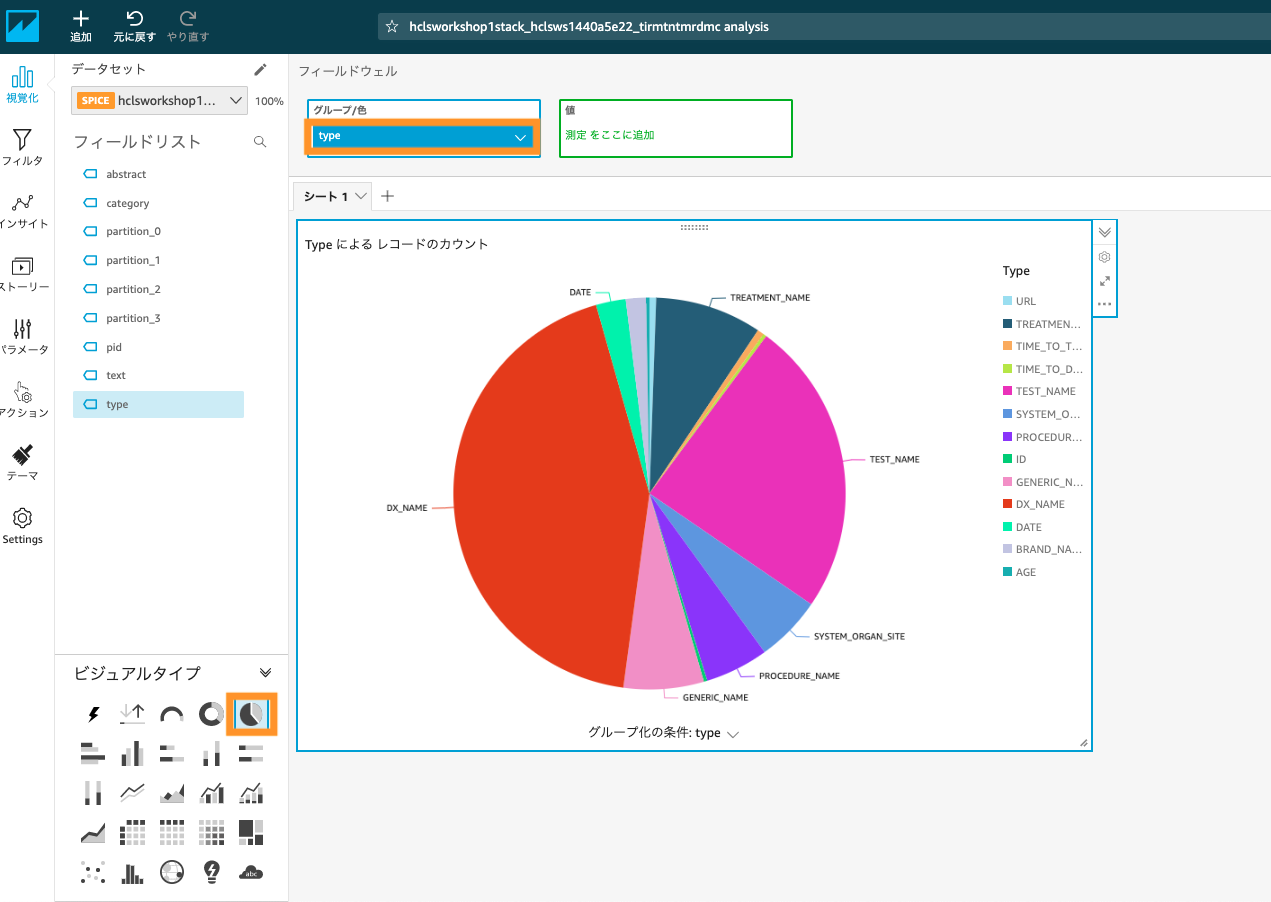
左下のビジュアルタイプから「円グラフ」を選択し、フィールドリストのtypeをクリック(または、フィールドウェルにある「グループ/色」にDrag&Drop)。そうすると、Abstractに含まれる医療情報の種類の割合が表示できます。
次にフィールドリストのtextを、先ほど移動したtype直下にDragすると「ドリルダウンレイヤーの追加」が表示されます。この状態でDropします。

さらに、フィールドリストのabstractを先ほど移動したtextの直下にDrag&Drop。

ここで例えば、TREATMENT_NAMEでタグづけされたKeywordを検索したい場合には、円グラフのTREATMENT_NAMEをクリックし、「textまでドリルダウン」をクリック。

そうすると、TREATMENT_NAMEでタグづけされたKerwordが一覧表示されます。更にそのKeywordが記述されている論文のAbstractを表示したい場合(今回はradiotherapy)、円グラフのradiotherapyをクリックして「abstractまでドリルダウン」をクリック。

最終的に、数クリックでTREATMENT_NAMEかつradiotherapyに関連するAbstractまで参照する事ができます。

まとめ
このように数クリックで、Amazon Comprehend Medicalを利用した特定のデータソース内の医療情報自動抽出・タグづけを行う環境をDeployし、データの可視化・分析することができます。ヘルスケア・ライフサイエンスチームでは、このように業界特化の「創薬ワークフローハンズオン」を用意しております。幅広いユーザーの方々にソリューションを活用頂ければ幸いです。
著者について

小泉 秀徳 (Hidenori Koizumi) は、ヘルスケア・ライフサイエンスチームのソリューションアーキテクトです。生物学・化学のバックグラウンドを活かしたソリューション作成を得意としています。最近は、React Nativeを利用したモバイル開発も行なっており、ヘルスケアアプリに関心があります。