Amazon Web Services ブログ
大量の音声データからインサイトを発見する
近年データドリブン経営が注目されています。多くの企業がデータの価値を理解し、各業務プロセスからデータを収集し始めました。その流れでコールセンター、各種会議または金融機関対面窓口の通話も録音され保存されていますが、それらの音声データをどう活用するかという点では、まだ課題があります。またデータアナリティクスや人工知能の開発者が音声認識、自然言語処理およびデータ分析の一連ワークフローを構築する必要があり、人材とリソースの不足によって音声データの利活用が進んでいない状況です。
このブログ記事では、AWS上で上記ワークフローを構築する方法を示しています。AWS Glueを利用して、大量の音声データに対してAmazon Transcribe を利用した文字起こしを行い、次に変換された文字に対してAWS LambdaでAmazon Comprehendを呼び出してキーワードを抽出します。最後にAmazon Athena と Amazon QuickSight を利用して会話データにおけるキーワードの出現頻度を可視化するワードクラウドを作成します。このブログで利用する音声データは Amazon Connect (クラウドベースのコンタクトセンターサービス) で記録した銀行コールセンターの会話例ですが、このアーキテクチャは他の日本語の音声データに対しても機能します。
ソリューション概要
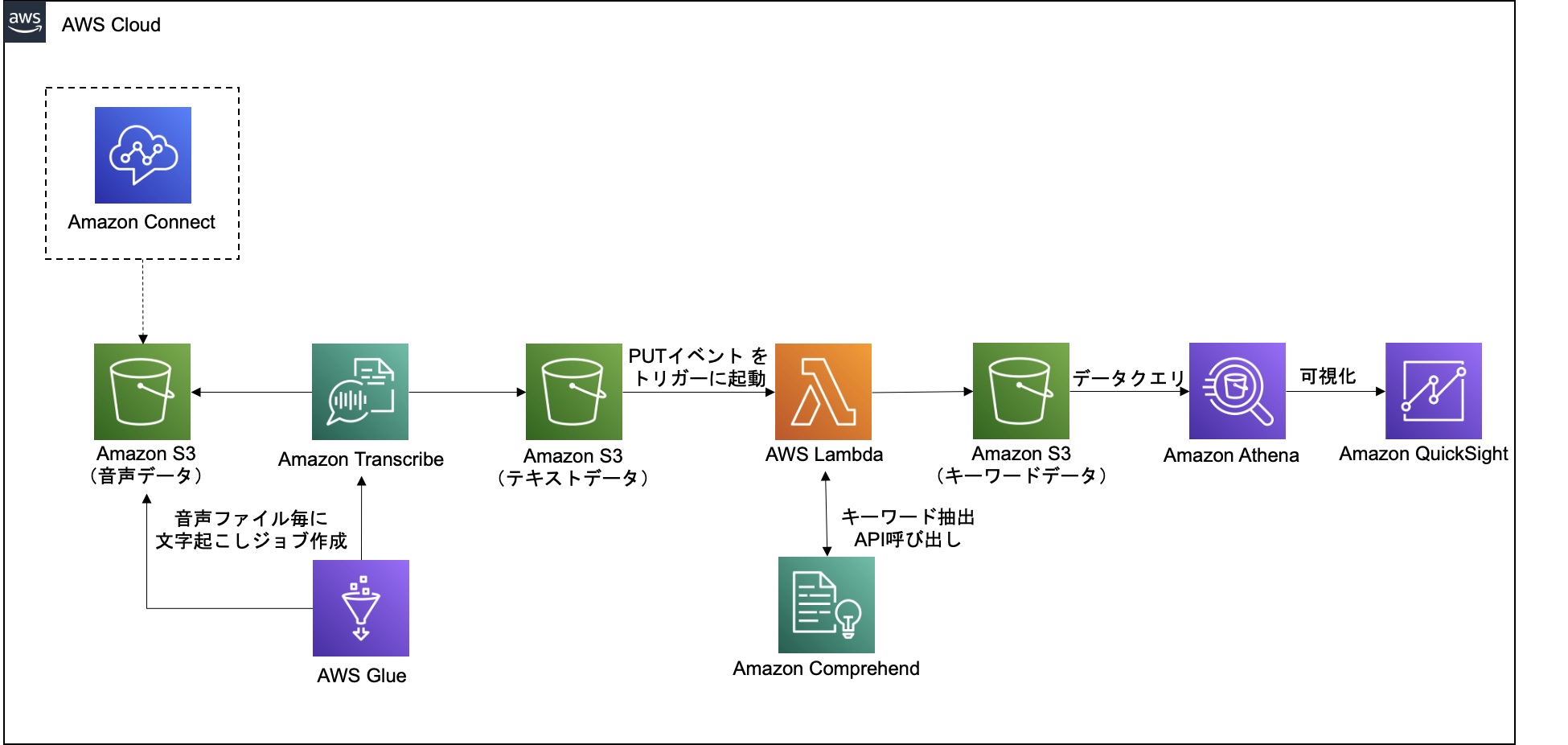
実行手順の概要
この記事では、以下の方法を示しています。
- Step1:Amazon Simple Storage Service(Amazon S3)バケットの作成
- Step2:AWS Identity and Access Management(IAM)ロールの作成
- Step3:文字起こしの実装
- AWS Glueでスクリプトを実装し、大量の音声データに対してAmazon Transcribeの文字起こしジョブを作成する。文字起こしジョブは音声をテキストデータに変換してS3に出力する。
- Step4:キーワード抽出の実装
- S3に出力されたテキストデータを対象にLambdaを起動し、Amazon ComprehendのAPIを呼び出しキーワードを抽出してS3に保存する。
- Step5:データの投入と処理の実行
- バケットに音声ファイルを投入し、文字起こしとキーワード抽出の処理を実行させる。
- Step6:分析と可視化
- AthenaでS3に保存されたキーワードデータをクエリし、QuickSightのワードクラウドでクエリ結果を可視化する。
Step1. S3バケットの作成
音声データ、テキストデータ、キーワードデータ、および後続の手順で利用するboto3ライブラリを格納するためのバケットとフォルダーをそれぞれ作成する必要があります。
作成の手順はバケットの作成をご参照ください。
Step2. 実行権限IAMロールの作成
ここではロールの作成手順を示していますが、実際の利用環境に合わせて最小限権限の見直しを推奨しております。
まずAWS Glue Jobでスクリプトを実行するために以下のアクセス権限を持つIAMロールをJobに付与する必要がります。
- S3に保存されたデータの参照権限
- Amazon Transcribeの呼び出し権限
- スクリプトのログを出力するためのAmazon CloudWatchのアクセス権限
- Amazon Transcribeのジョブに権限(S3への読み書き)を委任するための権限
最後の権限については以下のJSON ポリシーを貼り付けて、新規IAMポリシーTranscribeAssumeRolePolicyを作成する必要があります。作成の手順は[JSON] タブでのポリシーの作成方法をご参照ください。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "*",
"Condition": {
"StringEquals": {
"iam:PassedToService": "transcribe.amazonaws.com"
}
}
}
]
}以下の手順でAWS Glue Jobに付与するIAMロールを作成します。IAMロールの作成手順はAWS のサービスにアクセス許可を委任するロールの作成をご参照ください。
- ロールの作成画面で、ユースケースはGlueを選択する。
- Attachアクセス権限ポリシーでAmazonS3FullAccess、AmazonTranscribeFullAccess、CloudWatchFullAccess、および新規作成されたTranscribeAssumeRolePolicyをチェックする。
- ロール名にGlueJobRoleを入力して、ロールを作成する。
続きましてAWS Glue JobのスクリプトでAmazon Transcribe Jobに委任するためのIAMロールを作成します。Transcribeのユースケースはまだ定義されていないため、任意のユースケースを選択してIAMロールを作成してから信頼関係を編集する必要があります。
- ロールの作成画面で、ユースケースはEC2を選択する。
- Attachアクセス権限ポリシーでAmazonS3FullAccessをチェックする。
- ロール名にTranscribeJobRoleを入力して、ロールを作成する。
- 作成したロールを選択して、信頼関係を選択する。
- 信頼関係の編集を選択して、信頼ポリシーを次のコードに置き換える。
-
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "transcribe.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }
最後にLambdaに付与するIAMロールを作成します。
- IAMロールの作成画面で、ユースケースはLambdaを選択する。
- Attachアクセス権限ポリシーでAmazonS3FullAccess、ComprehendFullAccess、AWSLambdaBasicExecutionRoleをチェックする。
- ロール名にLambdaCallComprehendRoleを入力して、ロールを作成する。
Step3. 文字起こしの実装
このブログではAWS Glue StudioのJobs機能を利用し、音声データの文字変換処理を実装します。JobsではGUI画面で変換ロジックを作成することもできますが、今回のようにカスタマイズ処理を実装したい場合はPython Shell script editorを起動して新規にスクリプトを作成します。
ここで定義されたJobはサーバーレスで実行され、ユーザーはジョブの実行に費やした時間に対してのみ支払うことができます。また今回のブログでは未設定ですが、スケジュールを設定してジョブを自動実行することもできます。

ここから実装するScriptではAWS SDK for Python (Boto3) でS3やAmazon TranscribeのAPIを呼び出しますが、筆者が執筆する時点(2021年9月29日)でPython Shell scriptのboto3バージョンをboto3-1.18.50にアップデートする必要があります。事前にboto3 Download filesから最新バージョンboto3のWheelライブラリファイルをダウンロードしてS3にアップロードしてください。
まずJob detailsのタグで以下の設定を入力します。
- (Basic properties) Name:CallTranscribeJob
- (Basic properties) IAM Role:作成済みのGlueJobRole
- (Advanced properties Libraries) Referenced files path:boto3のライブラリファイルのS3 URI
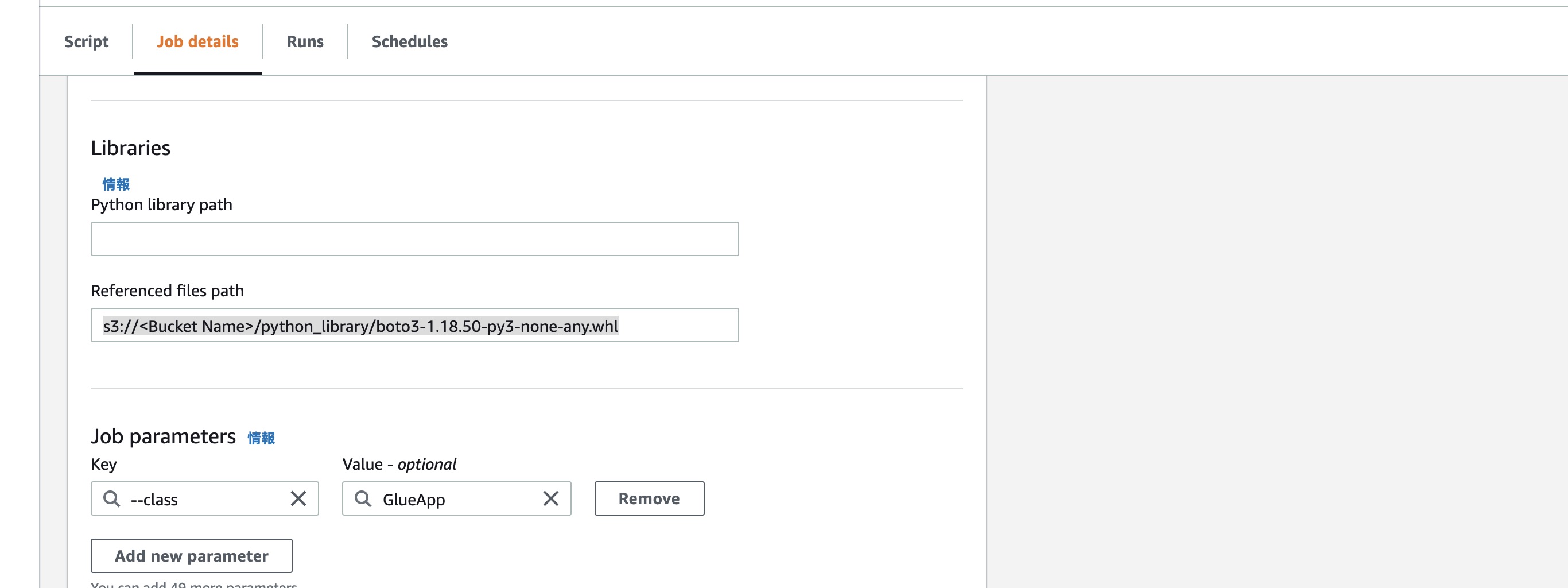
続きましてScriptタグに以下のコードを入力します。
コード中<>の部分は実際のバケット名、フォルダー名、IAMロールのARNに置き換えてください。
import json
import urllib.parse
import uuid
import sys
# Install boto3
sys.path.insert(0, '/glue/lib/installation')
keys = [k for k in sys.modules.keys() if 'boto' in k]
for k in keys:
if 'boto' in k:
del sys.modules[k]
import boto3
print('Loading function')
audio_bucket_name = '<入力の音声ファイル保存バケット名>'
audio_bucket_folder_prefix = '<音声ファイル保存バケットのフォルダーパス>' # Path ends with /
text_bukcet_name = '<出力のテキストデータ保存バケット名>'
text_bucket_folder_prefix = '<テキストデータ保存バケットのフォルダーパス>' # Path ends with /
transcribe_role_arn = '<IAMロールTranscribeJobRoleのArn>'
boto_session = boto3.session.Session()
region = boto_session.region_name
s3 = boto3.client("s3", region_name = region)
transcribe = boto3.client('transcribe')
def callTranscriptionJob(key):
randomName = str(uuid.uuid4())
response = transcribe.start_transcription_job(
TranscriptionJobName=randomName,
JobExecutionSettings={
# Enables you to submit jobs beyond the limit for concurrent jobs (100).
'AllowDeferredExecution': True,
'DataAccessRoleArn': transcribe_role_arn
},
LanguageCode='ja-JP',
Media={
'MediaFileUri': 's3://' + audio_bucket_name + '/' + key,
},
OutputBucketName=text_bukcet_name,
OutputKey=text_bucket_folder_prefix + randomName + '.json',
Settings={
'ShowSpeakerLabels': False,
'ChannelIdentification': False,
'ShowAlternatives': False,
},
)
if __name__ == '__main__':
continuationToken = None
# List objects present in a bucket
while True:
# Enables you to get s3 objects beyond the limit for 1000 objects one time.
if continuationToken is None:
response = s3.list_objects_v2(Bucket=audio_bucket_name,
Prefix=audio_bucket_folder_prefix)
else:
response = s3.list_objects_v2(Bucket=audio_bucket_name,
Prefix=audio_bucket_folder_prefix,
ContinuationToken=continuationToken)
if 'Contents' in response:
for item in response['Contents']:
# print(item['Key'])
if not item['Key'][-1] == '/':
callTranscriptionJob(item['Key'])
if 'NextContinuationToken' in response:
continuationToken = response['NextContinuationToken']
else:
continuationToken = None
breakこれで文字起こし処理の実行準備が完了しました。このスクリプトはS3バケットのフォルダーに保存されている全ての音声データを対象にAmazon Transcribeの文字起こしジョブを起動します。文字起こしジョブは非同期で実行されるため、スクリプトの実行が完了しても一部の文字起こしジョブはまだ実行中の可能性があります。
Amazon Transcribeのジョブは音声ファイルを解析し、文字に変換して.json形式のファイルに出力します。今回のスクリプトで使われておりませんが、カスタム語彙、スピーカー識別や文字変換の候補を出力する機能も提供されております。詳細についてstart_transcription_jobのboto3 Docをご参照ください。
Step4. キーワード抽出の実装
Amazon TranscribeのジョブはS3にテキストデータを出力し、出力イベント(Put Event)をトリガーに、キーワード抽出機能をLambda関数で実装します。
- Lambdaのダッシュボードで、関数の作成ボタンをクリックする。
- 一から作成をそのまま選択して、基本的な情報の部分で以下の情報を入力する:
- 関数名:CallComprehendFunction
- ランタイム:Python 3.9
- アクセス権限実行ロール:既存のロールを使用する
- 作成済みのLambdaCallComprehendRoleを選択する。
- 関数の作成ボタンをクリックする。

続きまして、Lambda関数にトリガーを追加します。
- 設定からトリガーを選択して、トリガーを追加ボタンをクリックする。
- トリガーの設定でプールダウンからS3を選択する。
- 以下の情報を入力、または選択する:
- バケット:<出力のテキストデータ保存バケット>
- イベントタイプ:PUT
- プレフィックス:<テキストデータ保存バケットのフォルダーパス>
- サフィックス:.json
- 再帰呼び出しの確認にチェックを入れて、追加ボタンをクリックする。

最後にコードタブを選択して、コードソースに以下のコードを貼りづけます。コード中<>の部分は実際のバケット名、フォルダー名に置き換えてください。
import json
import urllib.parse
import boto3
import csv
import io
import datetime
print('Loading function')
keyword_bucket_name = '<キーワードデータ保存バケット名>'
keyword_bucket_folder_prefix = "<キーワードデータ保存バケットのフォルダーパス>" # Path ends with /
# remove the stop word from the keyword list
jp_stop_word = [
'お', 'お時間', '時間', 'お名前', '名前', 'お電話', '電話', 'お電話番号', '電話番号', 'ご住所', '住所',
'誕生日', '生年月日', 'これ', 'それ'
]
boto_session = boto3.session.Session()
region = boto_session.region_name
s3 = boto3.client("s3", region_name = region)
comprehend = boto3.client('comprehend')
def list_to_csv(outputList):
output = io.StringIO()
writer = csv.writer(output, quoting=csv.QUOTE_NONNUMERIC)
for one_line_of_data in outputList:
writer.writerow(one_line_of_data)
return (output.getvalue())
def lambda_handler(event, context):
outputList = []
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'],
encoding='utf-8')
objectName = key.split('/')[-1]
response = s3.get_object(Bucket=bucket, Key=key)
body = response['Body'].read()
# get the transcript from the json file
transcripts = json.loads(
body.decode('utf-8'))['results']['transcripts'][0]['transcript']
# call comprehend detect_key_phrases API
result = comprehend.detect_key_phrases(Text=transcripts, LanguageCode='ja')
for r in result["KeyPhrases"]:
# print(r)
if not outputList:
outputList.append(list(r.keys()))
if r['Text'] not in jp_stop_word:
outputList.append(list(r.values()))
# export keyword to S3 in csv file
response = s3.put_object(Body=list_to_csv(outputList),
Bucket=keyword_bucket_name,
Key=keyword_bucket_folder_prefix +
objectName.replace('.json', '.csv'))
print(response)このスクリプトはキーワード中のノイズを除去するため、日本語のストップワードをjp_stop_wordに定義しています。音声会話の内容に合わせてストップワードをカスタマイズしてください。 このスクリプトはS3バケットのPUTイベントをトリガーに実行され、.json形式のテキストファイルを解析し、キーワードを抽出して.csv形式で指定のS3バケットに出力します。 transcribe.start_transcription_jobと違い、comprehend.detect_key_phrasesのAPIはキーワード抽出結果を同期的に返しますので、Lambdaの処理でキーワード抽出結果を加工して出力ができます。Amazon Comprehendはキーワードを抽出する機能以外に、エンティティの抽出やセンチメント分析などにも対応しています。詳細についてはComprehend boto3 Docをご参照ください。
Step5. データの投入と処理の実行
音声データからキーワードを抽出するための準備ができましたので、バケットに音声データを投入し、AWS Glue Studioで作成したジョブを実行してみてください。現在Trasncribeがサポートする音声データの形式およびファイルサイズについての制限などはバッチ転写のコンテナとフォーマットの公式資料ごご参照ください。
手元に音声会話データがない場合は、こちらの銀行コールセンターの会話例をご利用できます。音声データ右端のボタンからダウンロードください。こちらのデータは銀行コールセンターの会話例をAmazon Connectで再現し、音声を記録したものになります。
AWS Glue Studioジョブの実行状況はMonitoringタブ、またはジョブを選択してRunsタブから確認できます。テキストデータがバケットに出力されていなく、実行が失敗した場合はCloudwatch logsを選択して、エラーログを確認ください。
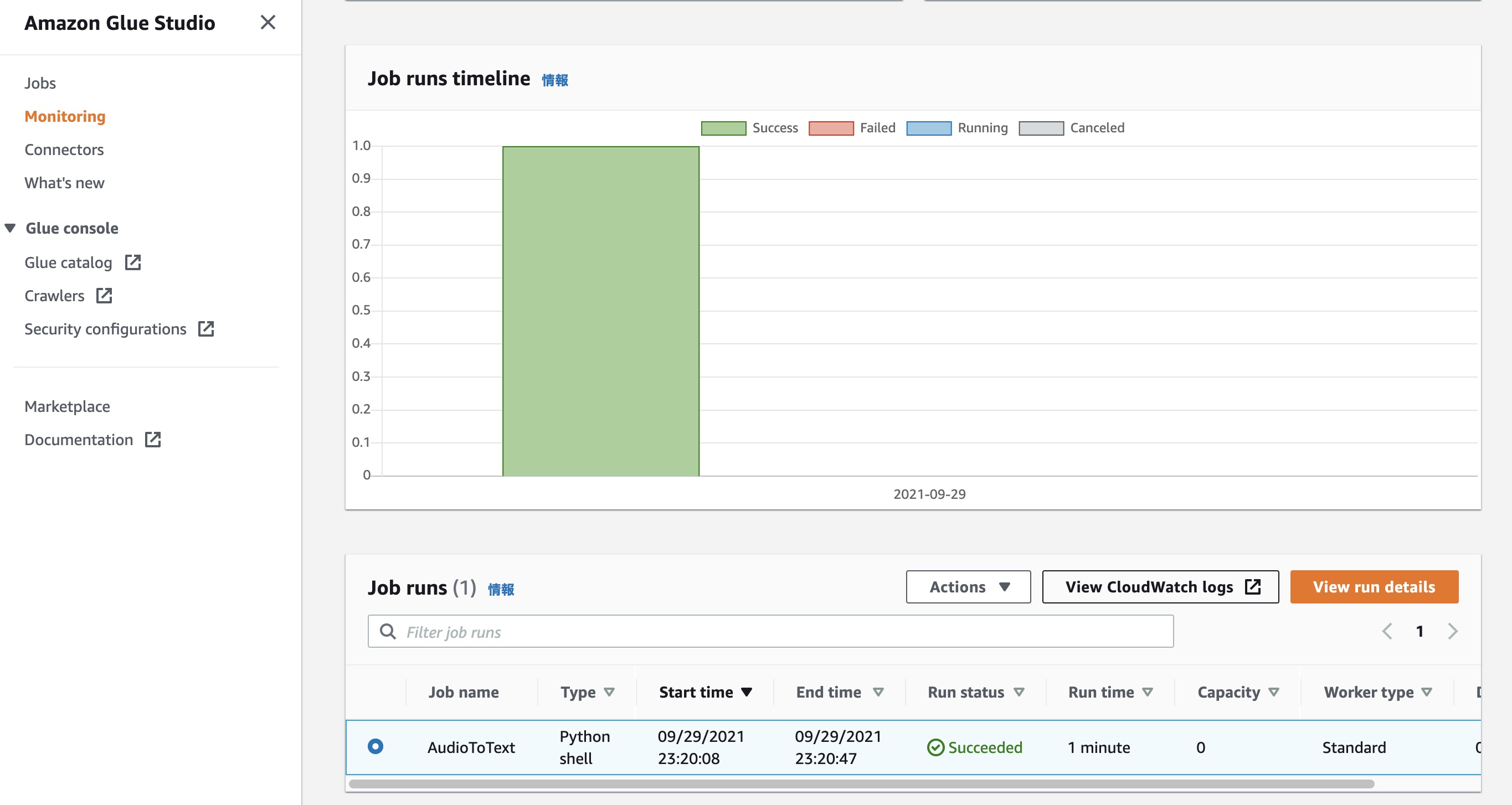

AWS Glue Studioジョブの実行が完了したらRun statusがSucceededになります。このジョブによってAmazon Transcribeの文字起こしジョブが音声ファイルの数分生成され実施されます。生成された文字起こしジョブは非同期で実行されるため、まだ処理中の可能性があり、その実行状況はTranscribe jobsの画面で確認できます。
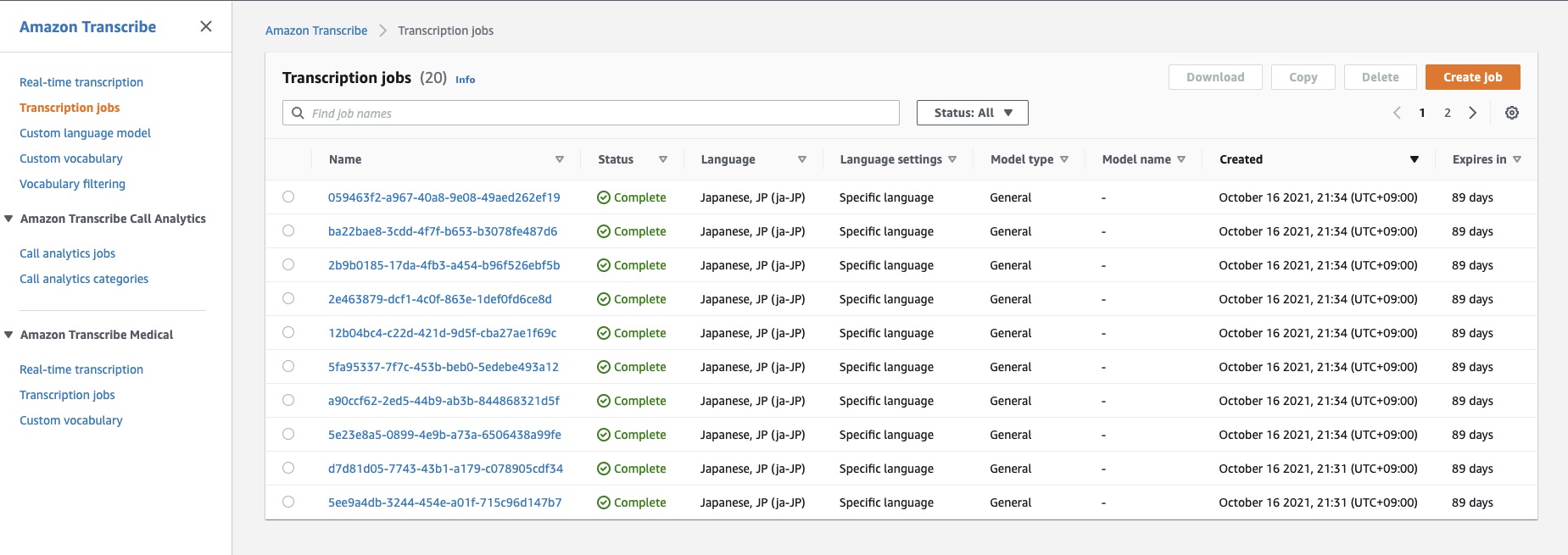
Amazon Transcribe文字起こしジョブは変換結果のテキストデータをS3バケットに出力し、キーワード抽出のLambda関数がその出力イベントをトリガーに起動します。Lambda関数の実行状況もLambdaのモニタリングタブから確認ができます。キーワードデータがバケットに出力されていなく、実行が失敗した場合はCloudwatch logsを選択して、エラーログを確認ください。
Step6. 分析と可視化の実装
これからはS3バケットに出力された.csv形式のキーワードデータをAthenaでクエリします。 現在の AWS リージョンで Athena コンソールを初めて使用する場合は、Athenaご利用開始にあたっての手順を参照してセットアップしてください。
セットアップ済みの場合、Athenaのクエリエディタで以下のScriptをそれぞれ入力・実行してください。コード中<>の部分は実際のキーワードデータ保存場所のS3 URIに置き換えてください。keyword_dbデータベースとKeyWordTableテーブルをそれぞれ作成します。KeyWordTableテーブルは.csv形式のキーワードデータをベースに作成され、データもテーブルにインポートされます。
CREATE DATABASE IF NOT EXISTS keyword_db;CREATE EXTERNAL TABLE IF NOT EXISTS keyword_db.KeyWordTable ( `Score` float, `Text` string, `BeginOffset` int, `EndOffset` int
)
ROW FORMAT SerDe 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES ( 'serialization.format' = ',', 'field.delim' = ','
)
LOCATION '<キーワードデータ保存場所のS3 URI>'
TBLPROPERTIES ('skip.header.line.count'='1','has_encrypted_data'='false')Athenaの設定が完了したら、次はQuickSightでデータソースをAthenaに指定します。
QuickSightを初めて利用する場合はAmazon QuickSight のセットアップの手順を参照して、セットアップする必要があります。このブログで利用する機能はスタンダード版でも利用できますが、本番環境でのデータ分析はエンタープライズエディションを推奨します。
まずQuickSightからAthenaにアクセスできるように、QuickSightのアクセス権限を設定する必要があります。
- QuickSightの画面にログインする。
- 画面右上のユーザー名をクリックして、QuickSightの管理を選択する。
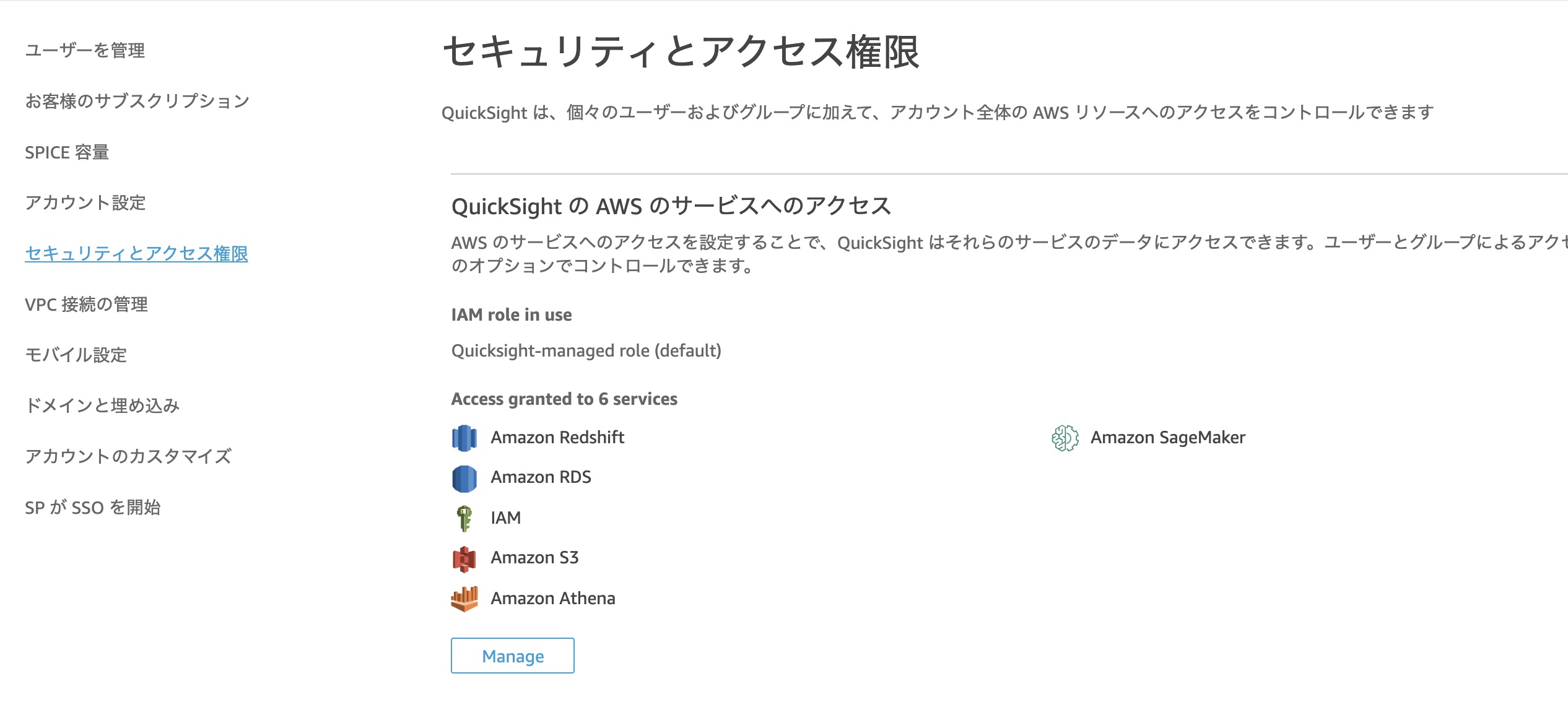
- 左のメニューからセキュリティとアクセス権限を選択し、QuickSight の AWS のサービスへのアクセスの画面から管理を選択する。
- AthenaとS3をチェックして保存ボタンをクリックする。
- QuickSight の AWS のサービスへのアクセスの画面でAthenaが追加されたことを確認する。
アクセス権限の追加が完了したら、次の手順でAthenaのデータセットを追加します。
- QuickSightのホーム画面で、新しいデータセットボタンをクリックする。
- Athenaを選択する。
- データソース名にKeyWordDataSourceを入力して、データソースを作成ボタンをクリックする。
- データベースはkeyword_db、テーブルはKeyWordTableを選択する。
- ディフォルト設定のままでVisualizeボタンをクリックする。

ダイレクト SQL クエリを使用するのではなくデータをデータセットにインポートすると、その格納方法のためにデータはSPICEデータになります。詳細はSPICE へのデータのインポートをご参照ください。
SPICEへのインポートはデータ量によって処理時間が変わります。インポート処理が完了したら、データセットが100%になり、右上のポップアップメッセージにインポートの完了が表示されます。
最後にQuickSightの分析編集画面でキーワード頻度の可視化を作成します。
- 編集画面左下のビジュアルタイプからWord Cloud(クラウドアイコン)を選択する。
- フィールドリストからtextをグループ化条件の青枠の箱にドラッグする。
- グラフエリア左上のタイトルをクリックして、キーワード出現頻度に変更する。
- (ワードクラウドにOtherという単語が大きく表示されている場合)生成されたワードクラウドの右の「…」を選択し、「その他」のカテゴリを表示を選択する。
- 必要に応じてダッシュボードの公開や分析を共有する。
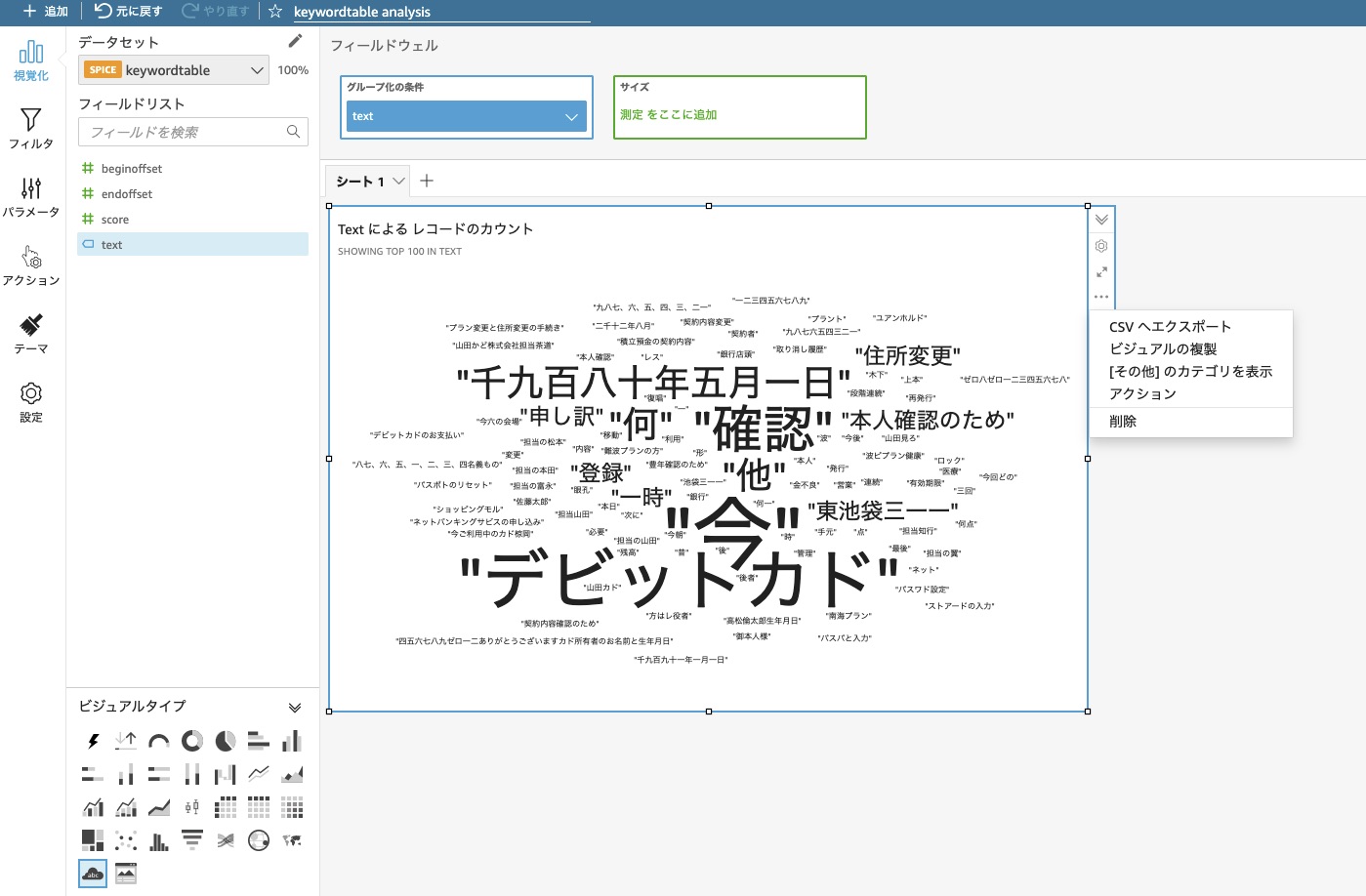
ワードクラウド以外に、ピボットテーブルや棒グラフからも出現頻度を確認することができます。他の種類のビジュアルタイプでキーワードデータの可視化も試してみてください 。
QuickSightで分析を作成する際にキーワードデータはまだ未作成、またはキーワードデータが更新され、可視化結果を更新したい場合はデータセットを選択して、今すぐ更新ボタンをクリックしてください。
最後に
このソリューションを継続的に利用する予定がない場合、余計な料金が発生しないように、今回作成したリソースを削除しましょう。
まとめ
このブログ記事では、大量の音声データを文字に変換し、キーワードの出現頻度を可視化するソリューションを実装しました。このソリューションは以下の機能を提供しました。
- 蓄積された大量の音声データを文字に変換する。
- 変換された文字データからキーワードを抽出する。
- キーワードの出現頻度を可視化する。
是非、このソリューションを利用して、各種音声データのインサイト発見を試してみてください。