Amazon Web Services ブログ
Category: Storage
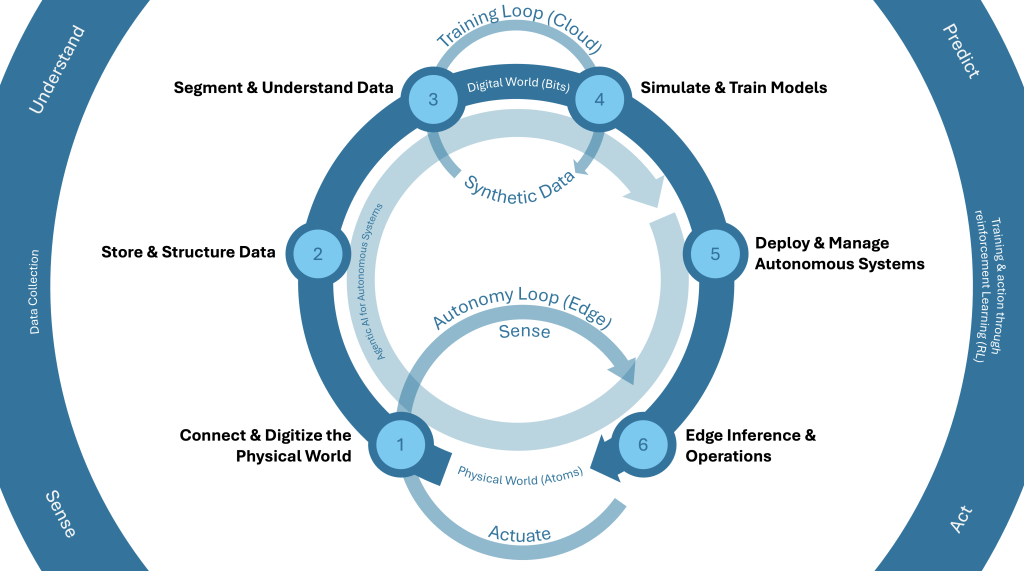
フィジカル AI: 自律型インテリジェンスに向けた次なる基盤を築く
AWS の Physical AI フレームワークは、デジタル世界と物理世界を橋渡しする自律システムを構築するための包括的なアプローチです。物理世界の接続とデジタル化、データの保存と構造化、データのセグメント化と理解、シミュレーションとトレーニング、デプロイと管理、エッジ推論と運用の 6 つの相互接続された機能を通じて、継続的な学習サイクルを作り出し、自律型経済への移行を支援します。

AWS Weekly Roundup: Amazon Bedrock エージェントワークフロー、Amazon SageMaker プライベート接続など (2026 年 2 月 2 日)
2026 年 1 月 26 日週、私たちはラバ祭りを祝いました。これは、旧正月まで残りわずかであることを告げる […]

AI を具現化するブログ: パート1 AWS Batch でロボット学習を開始する
本記事は 2025/12/02 に公開された “Embodied AI Blog Series, […]

AWS Game Dev Toolkit でゲーム開発インフラ構築を簡単に
本記事は、2026年 1 月 22 日に公開された “Game development infrastruct […]

自動車および製造業界むけ AWS re:Invent 2025 のダイジェスト
AWS の年次フラッグシップイベントである AWS re:Invent 2025 は、 2025 年 12 月 […]
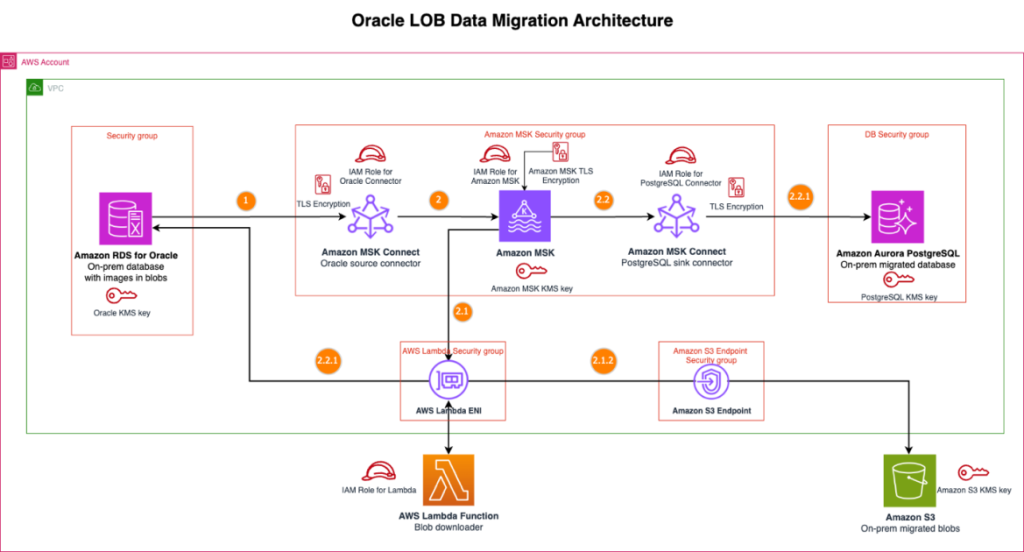
Oracle から Amazon Aurora PostgreSQL および Amazon S3 への大容量バイナリオブジェクト移行を効率化する Kafka ベースのソリューション
Amazon MSK、Amazon Aurora PostgreSQL-Compatible Edition、Amazon MSK Connect を使用して、Oracle データベースから AWS への大容量バイナリオブジェクト (LOB) 移行を効率化するストリーミングソリューションを紹介します。
Amazon S3 Tables のレプリケーションサポートと Intelligent-Tiering の発表
2025 年 12 月 2 日、 Amazon S3 Tables の 2 つの新機能を発表しました。1 つは […]

Amazon FSx for NetApp ONTAP が Amazon S3 と統合され、シームレスなデータアクセスが可能になりました
2025 年 12 月 2 日、Amazon Simple Storage Service (Amazon S […]

ブロックストレージとしての Amazon FSx for NetApp ONTAP
本ブログは、NetApp Japan が主催する Amazon FSx for NetApp ONTAP Advent Calendar 2025 の 19 日目の記事です。
皆様は Amazon FSx シリーズと聞くと、ファイルストレージサービスを想起するのではないでしょうか?私もそんな一人です。しかし、FSx シリーズの 1 つである Amazon FSx for NetApp ONTAP (FSx for ONTAP) はブロックストレージとしても利用できます。

Amazon Redshift で Apache Iceberg データをクエリするためのベストプラクティス
Amazon Redshift で Apache Iceberg データをクエリする際のベストプラクティスを紹介します。テーブル設計、パーティション化、列選択、統計生成、メンテナンス戦略、マテリアライズドビュー、レイトバインディングビューの活用方法について詳しく説明します。