Amazon Web Services ブログ
トムソンロイターが Amazon SageMaker を利用して AI プラットフォームを構築し、ML プロジェクトのデリバリーを加速させた方法
1992 年、トムソンロイター(TR)は、ほとんどの検索エンジンが Boolean 式やコネクタにしか対応していなかった当時としては革新的な、最初の AI 法律調査サービス「 WIN(Westlaw Is Natural)」をリリースしました。以来、TR は、継続的に AI プロダクトとサービスの種類を増やし、世界中の法務、税務、会計、コンプライアンス、ニュースサービスの専門家をサポートし、毎年何十億もの機械学習(ML)インサイトを生成するなど、さらに多くのマイルストーンを達成しました。
このように AI サービスが驚異的に増加する中、TR はイノベーションを効率化し、コラボレーションを促進することを次のマイルストーンとしました。より具体的には、以下のような企業のベストプラクティスを遵守しながら、ビジネス部門や AI 実務者の属人性を超えた AI ソリューションの構築と再利用を標準化することを目指しました。
- 繰り返される差別化を生まないエンジニアリング作業の自動化と標準化
- 共通のガバナンス基準に従った、機密データの隔離と制御の保証
- 拡張可能なコンピューティングリソースへの容易なアクセスの提供
これらの要件を満たすため、TR は、データサービス、実験ワークスペース、中央モデルレジストリ、モデルデプロイサービス、モデルモニタリングサービスという5つの柱を中心に、エンタープライズ AI プラットフォームを構築しました。
この記事では、TR と AWS がどのように協力し、ML 実験、トレーニング、中央モデルレジストリ、モデルデプロイ、モデルモニタリングに至る機能を提供する、TR 初の Web ベースのツールであるエンタープライズ AI プラットフォームを開発したのかについて説明します。これらの機能はすべて、TR の進化し続けるセキュリティ標準に対応し、シンプルで安全かつコンプライアンスに準拠したサービスをエンドユーザーに提供するために構築されています。また、異なるビジネスユニットにまたがって作成された ML モデルのモニタリングとガバナンスを、TR がどのように単一の管理画面で実現したかを紹介します。
課題
TR ではこれまで、ML は高度なデータサイエンティストやエンジニアを擁するチームの能力として扱われてきました。高度なスキルを持つチームは、必要に応じて複雑な ML プロセスを実装することができましたが、すぐにサイロ化されました。サイロ化されたアプローチでは、極めて重要な意思決定の予測をするための見通しの良いガバナンスが提供できない課題がありました。
TR のビジネスチームは膨大なドメイン知識を持っています。しかし、ML に必要なテクニカルスキルとエンジニアリングの重労働は、ML の力を使ってビジネス課題を解決することを困難にします。TR は、そのスキルを民主化し、組織内のより多くの人が利用できるようにしたいと考えています。
TR では、さまざまなチームがそれぞれの方法論に従っています。TR は、ML のライフサイクルにまたがる能力をユーザーに提供し、チームが差別化を生まないエンジニアリング作業の繰り返しではなく、ビジネス目標に集中できるようにして、ML プロジェクトのデリバリーを加速させたいと考えています。
さらに、データと AI 倫理に関する規制は進化し続けており、TR の AI ソリューションに共通するガバナンス標準が必要となっています。
ソリューションの概要
TR のエンタープライズ AI プラットフォームは、異なるペルソナに対してシンプルで標準化されたサービスを提供し、ML ライフサイクルの各段階に対応した機能を提供することを想定して作られました。TR は、TR のすべての要件をモジュール化する5つの主要なカテゴリを特定しました。
- データサービス – 企業のデータ資産に簡単かつ安全にアクセスできるようにする
- 実験ワークスペース – ML モデルの実験とトレーニングのための機能を提供する
- 中央モデルレジストリ – 異なるビジネスユニット間で構築されたモデルのカタログ
- モデルデプロイメントサービス – TR のエンタープライズ CI/CD プラクティスに従って、様々な推論デプロイオプションを提供する
- モデルモニタリングサービス – データとモデルの偏りやドリフトを監視する機能を提供する
次の図に示すように、これらのマイクロサービスは、いくつかの重要な原則を念頭に置いて構築されています。
- ユーザーから差別化を生まないエンジニアリングの労力を取り除く
- ボタンをクリックするだけで、必要な機能を提供する
- TR のエンタープライズ標準に従って、すべての機能をセキュアに保護し管理する
- ML 活動のための単一の管理画面の導入
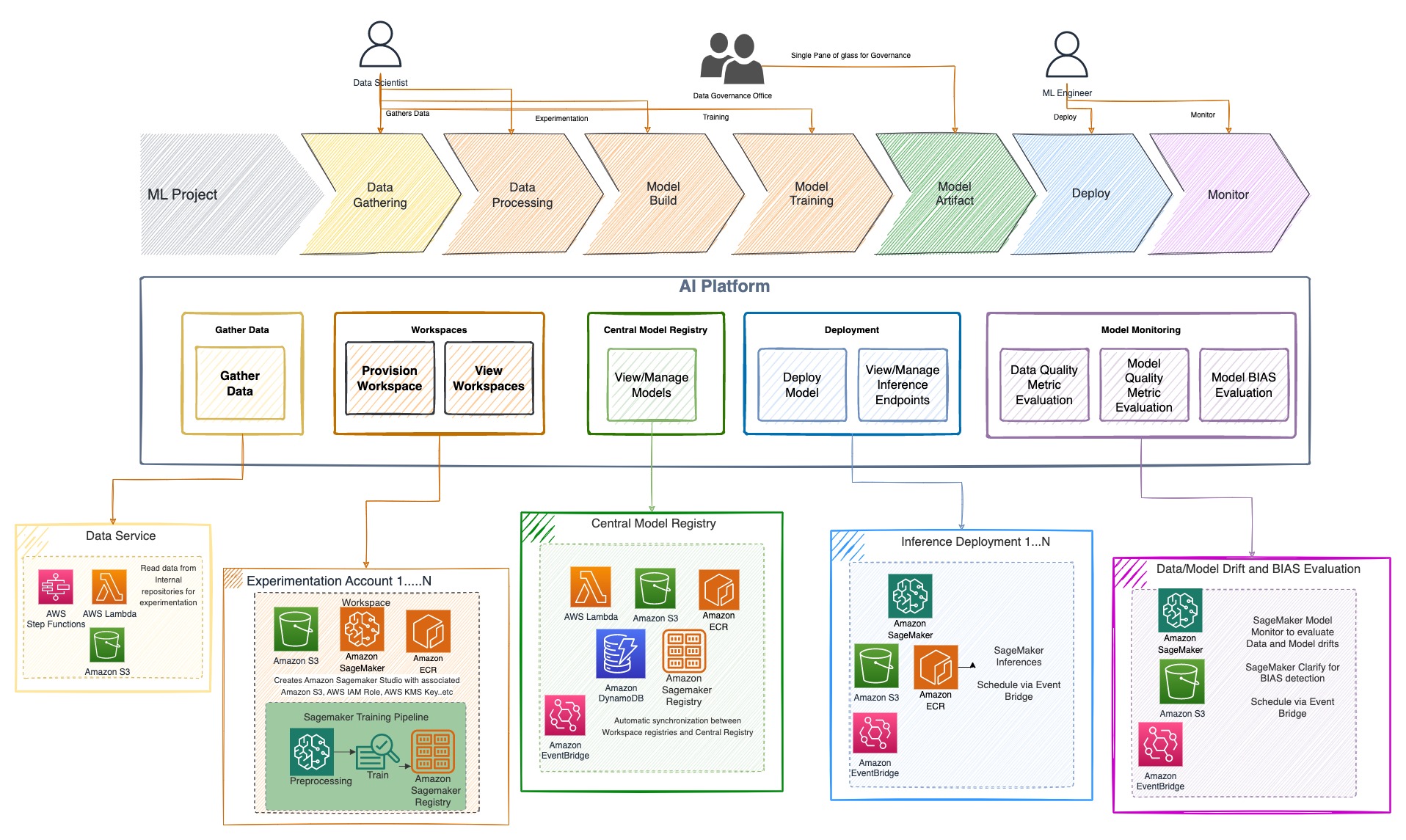
TR の AI プラットフォームマイクロサービスは、コアエンジンに Amazon SageMaker、ワークフローに AWS サーバーレスコンポーネント、CI/CD に AWS DevOps サービスを使って構築されています。実験とトレーニングには SageMaker Studio を、モデルの保存には SageMaker Model Registry を使用しています。中央のモデルレジストリは、SageMaker Model Registry と Amazon DynamoDB テーブルの両方で構成されています。モデルのデプロイには SageMaker ホスティングサービスを利用し、モデルのドリフト、バイアス、カスタムメトリック計算、および説明可能性を監視するために SageMaker Model Monitor と SageMaker Clarify を使用しています。
以下のセクションでは、これらのサービスの詳細について説明します。
データサービス
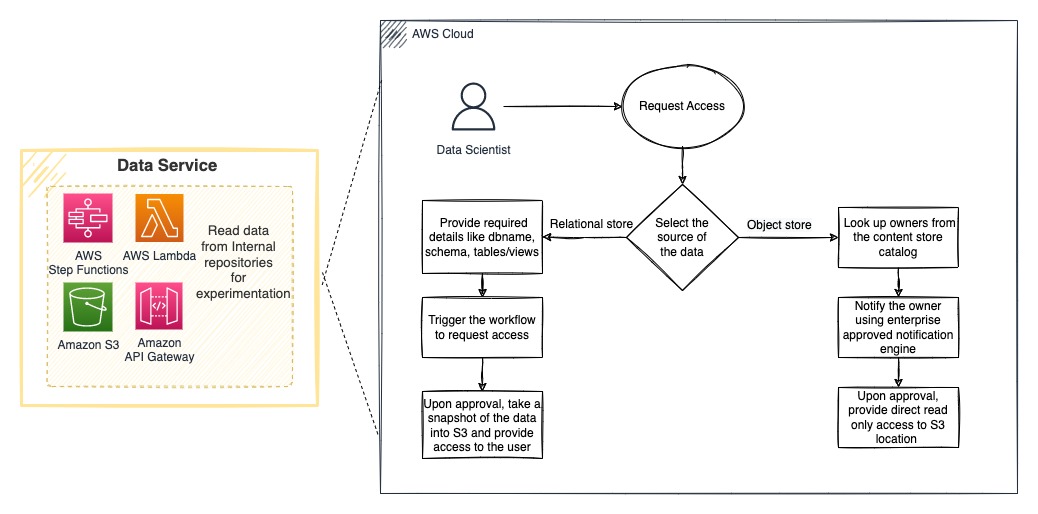
従来の ML プロジェクトのライフサイクルは、データを見つけることから始まります。一般に、データサイエンティストは、必要なときに適切なデータを見つけるために 60% 以上の時間を費やします。他の組織と同様に、TR も複数のデータストアを持ち、異なるデータ領域に対する信頼できる唯一の情報源(Single Point of Truth)として機能しています。TR は、ほとんどの ML ユースケースのデータを提供する 2 つの主要なエンタープライズデータストアを特定しました:オブジェクトストアとリレーショナルデータストアです。TR は、ユーザーの実験用ワークスペースから両方のデータストアにシームレスにアクセスできる AI プラットフォームのデータサービスを構築し、ユーザーが自分でデータを取得するための複雑なプロセスの負担を軽減しました。TR の AI プラットフォームは、データ&モデルガバナンスチームが定義したすべてのコンプライアンスとベストプラクティスに準拠しています。これには、データへの適切なアクセスを保証するための正式な承認プロセスとともに、ML 実務者がデータの倫理的かつ適切な利用を理解し遵守するための、必須のデータインパクト評価も含まれます。このサービスの中核は、すべてのプラットフォームサービスと同様に、TR と業界によって決定されたセキュリティとコンプライアンスのベストプラクティスに従っています。
Amazon Simple Storage Service (Amazon S3) のオブジェクトストレージは、コンテンツデータレイクとして機能します。TR は認証と監査可能性を保ちながらコンテンツデータレイクからユーザーの実験用ワークスペースにデータを安全にアクセスするためのプロセスを構築しました。エンタープライズリレーショナルプライマリーデータストアとして Snowflake を使用しています。AI プラットフォームデータサービスは、ユーザーのリクエストとデータ所有者の承認に基づき、データのスナップショットを提供し、ユーザーの実験ワークスペースに容易にアクセスできるようにします。
様々なソースからデータにアクセスすることは、容易に解決できる技術的な課題です。TR はそれだけでなく、データ所有者を特定し、アクセス要求を送信し、データ所有者に保留中のアクセス要求があることの通知を行い、承認状況に基づいて要求者にデータを提供するアクションを自動化する承認ワークフローを構築しました。このプロセスのすべてのイベントは、監査可能性とコンプライアンスのために追跡され、ログに記録されます。
次の図に示すように、TR はワークフローのオーケストレーションに AWS Step Functions を、機能の実行に AWS Lambda を使用しています。Amazon API Gateway は、Web ポータルからアクセスされる API エンドポイントを使用して機能を公開するために使用されます。
モデルの実験と開発
ML ライフサイクルの標準化に不可欠なのは、データサイエンティストがさまざまな ML フレームワークやデータサイズで実験できる環境です。このような安全でコンプライアンスに準拠した環境をクラウド上で数分以内に実現することで、データサイエンティストはクラウドインフラ、ネットワーク要件、セキュリティ標準対策の処理の負担から解放され、代わりにデータサイエンスの問題に集中することができます。
TR は、AWS Glue、Amazon EMR、SageMaker Studio などのサービスにアクセスできる実験ワークスペースを構築し、エンタープライズクラウドセキュリティ標準と各ビジネスユニットのアカウント分離標準に準拠したデータ処理および ML 機能を実現しています。TR は、このソリューションを導入する際に、以下のような課題に直面しました。
- 初期のオーケストレーションは完全に自動化されておらず、いくつかの手動ステップを含んでいました。問題が発生した場所を追跡するのは簡単ではありませんでした。TR は、Step Functions を使用してワークフローをオーケストレーションすることで、このエラーを克服しました。Step Functions を使うことで、複雑なワークフローの構築、状態の管理、エラー処理が非常に簡単になりました。
- 実験用ワークスペースの適切な AWS Identity and Access Management (IAM) ロール定義が困難でした。TR の社内セキュリティ標準と最小権限モデルに準拠するため、当初、ワークスペースのロールはインラインポリシーで定義されていました。その結果、インラインポリシーは時間とともに大きくなり、冗長になって、IAM ロールに許されるポリシーのサイズ制限を超えることになりました。これを軽減するため、TR は、より多くの顧客管理ポリシーを使用し、ワークスペースの役割の定義でそれらを参照するように変更しました。
- TR は、AWS アカウント レベルで適用されるデフォルトのリソース制限に達することがありました。例えば、希望するリソースタイプの制限に達したことで、SageMaker のジョブ(たとえばトレーニングジョブ)の起動に失敗することがありました。TR はこの問題について、SageMaker サービスチームと緊密に連携しました。この問題は、AWS チームが 2022 年 6 月に Service Quotas のサポート対象サービスとして SageMaker を提供開始したことで解決されました。
現在、TR のデータサイエンティストは、独立したワークスペースを作成し、必要なチームメンバーを追加して共同作業することで、ML プロジェクトを立ち上げることができます。SageMaker が提供する無制限のスケールは、さまざまなサイズのカスタムカーネルイメージにより、自在に利用できます。SageMaker Studio はすぐに TR の AI プラットフォームの重要なコンポーネントとなり、制約のあるデスクトップアプリケーションを使用していたユーザーは、スケーラブルで必要な時に利用できる専用エンジンに移行しました。次の図は、このアーキテクチャを表しています。

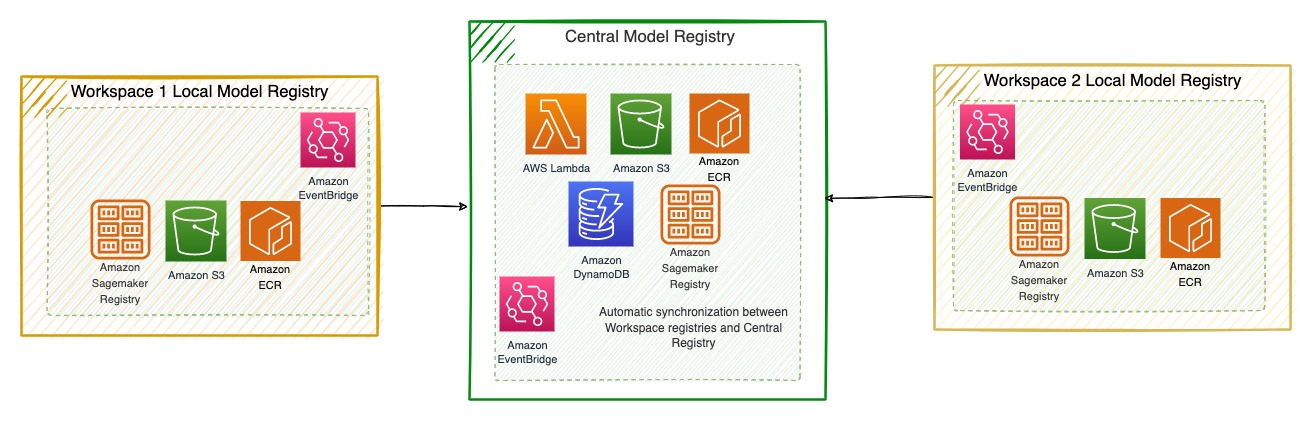
中央モデルレジストリ
モデルレジストリは、TR のすべての機械学習モデルの中央レポジトリを提供し、ビジネス機能間で標準化された方法でそれらのリスクとヘルスマネジメントを可能にし、将来的なモデルの再利用を合理化します。そのため、このサービスには次のようなことが必要でした。
- SageMaker 内外で開発された新規モデルとレガシーモデルの両方を登録する機能を提供する
- ガバナンスワークフローを実装し、データサイエンティスト、開発者、および関係者がモデルのライフサイクルを確認し、一括管理できるようにする
- メタデータやヘルスメトリクスとともに、TR 全体の全モデルを一元的に表示することで、透明性とコラボレーションを向上させる
TR は SageMaker Model Registry のみで設計を開始しましたが、TR の重要な要件の 1 つは、SageMaker 以外に作成されたモデルを登録する機能を提供することでした。TR は様々なリレーショナルデータベースを評価しましたが、レガシーソースから来るモデルのメタデータスキーマが大きく異なるため、最終的に DynamoDB を選択しました。TR はまた、ユーザーに追加の作業を課したくなかったので、Amazon EventBridge のルールと IAM ロールを使用して、AI プラットフォームワークスペースの SageMaker レジストリと SageMaker 中央レジストリの間でシームレスに自動同期を行うように実装しました。TR は DynamoDB を使用して中央レジストリを強化し、ユーザーのデスクトップで作成されたレガシーモデルを登録する機能を拡張しました。
TR の AI プラットフォーム中央モデルレジストリは、AI プラットフォームポータルに統合され、モデルの検索、モデルメタデータの更新、モデルのベースラインメトリクスと定期的なカスタムモニタリングメトリクスの把握のためのビジュアルインターフェイスを提供します。次の図は、このアーキテクチャを表しています。
モデルデプロイ
TR は、デプロイの自動化のために、大きく2つのパターンを特定しました。
- SageMaker を使って開発したモデルを SageMaker のバッチ変換ジョブで処理し、好きなスケジュールで推論を実行する方法
- オープンソースライブラリを使用してローカルで SageMaker 以外で開発したモデルを、SageMaker Processing ジョブを使用してカスタム推論コードを実行できる Bring Your Own Container アプローチにより、コードをリファクタリングせずに効率的にモデルを移行する方法
AI プラットフォームのデプロイサービスにより、TR のユーザー(データサイエンティストや ML エンジニア)はカタログからモデルを特定し、UI ドリブンなワークフローで必要なパラメータを提供することで、選択した AWS アカウントに推論ジョブをデプロイすることができます。
TR は、AWS CodePipeline や AWS CodeBuild などの AWS DevOps サービスを使って、デプロイを自動化しました。TR は Step Functions を使用して、データの読み取りと前処理から SageMaker 推論ジョブの作成までのワークフローをオーケストレーションしています。TR は、AWS CloudFormation のテンプレートを使って、必要なコンポーネントをコードとしてデプロイします。次の図は、このアーキテクチャを表しています。

モデルのモニタリング
ML ライフサイクルは、モデルを監視することなしには完了しません。TR のエンタープライズガバナンスチームは、規制上の問題に対処するために、ビジネスチームが長期にわたってモデルのパフォーマンスを監視することを義務付け、奨励しています。TR は、モデルとデータのドリフトを監視することから始めました。TR は SageMaker Model Monitor を使用して、データの基準値と Ground Truth ラベルを提供し、TR のデータと推論がどのようにドリフトしているかを定期的に監視しています。SageMaker モデルモニタリングメトリクスとともに、TR は、モデルに固有のカスタムメトリクスを開発することで、モニタリング機能を強化しました。これにより、TR のデータサイエンティストは、いつモデルを再トレーニングすべきかを理解することができます。
ドリフトモニタリングと同時に、TR はモデルのバイアスを把握することも望んでいます。SageMaker Clarify のすぐに使える機能を使って、TR のバイアスサービスを構築しました。TR はデータとモデルのバイアスの両方を監視し、それらの指標を AI プラットフォームポータルを通じてユーザーが利用できるようにしています。
すべてのチームがこれらの企業標準を採用できるように、TR はこれらのサービスを独立させ、AI プラットフォームポータルを通じて容易に利用できるようにしました。TR のビジネスチームは、ポータルにアクセスし、モデルモニタリングジョブやバイアスモニタリングジョブを独自にデプロイし、好きなスケジュールで実行することができます。ジョブのステータスや実行ごとのメトリクスは通知されます。
TR は、CI/CD デプロイ、ワークフローオーケストレーション、サーバーレスフレームワーク、および API エンドポイントに AWS サービスを使用し、以下のアーキテクチャに示すように、独立してトリガーできるマイクロサービスを構築しました。

結果と今後の改善点
TR の AI プラットフォームは、データサービス、実験ワークスペース、中央モデルレジストリ、モデルデプロイメントサービス、モデルモニタリングサービスの 5 つの主要コンポーネントすべてを搭載し、2022 年第 3 四半期に本稼働を開始しました。TR は、プラットフォームを導入するために、事業部に対して社内トレーニングを実施し、セルフガイドのトレーニングビデオを提供しました。
AI プラットフォームは、これまで存在しなかった機能を TR のチームに提供しました。コンプライアンス標準の強化、レジストリの一元化、TR 内のすべての ML モデルにわたる単一の管理画面での表示など、TR のエンタープライズガバナンスチームにとって幅広い可能性が開かれたのです。
TR は、どのような製品も最初のリリースがベストではないことを認識しています。TR のすべてのコンポーネントは異なる成熟度にあり、TR のエンタープライズ AI プラットフォームチームは、製品機能を繰り返し改善するために継続的な改善フェーズにあります。TR の現在の開発計画には、リアルタイム、非同期、マルチモデルエンドポイントなどの SageMaker 推論オプションの追加が含まれています。また、モデルモニタリングサービスの機能として、モデルの説明可能性を追加する予定です。TR は、SageMaker Clarify の説明可能性機能を利用して、社内の説明可能性サービスを開発する予定です。
まとめ
TR は、膨大な量のデータを安全に処理し、AWS の高度な機能を使用することで、ML プロジェクトをアイデアから本番まで、従来は数ヶ月かかっていたところを数週間で行うことができるようになりました。AWS サービスのすぐに使える機能により、TR のチームは ML モデルの登録と監視を初めて行うことができ、進化するモデルガバナンス標準への準拠を達成しました。TR は、データサイエンティストと製品チームが、最も複雑な問題を解決するために彼らの創造性を効果的に発揮することを可能にしました。
TR の AWS 上のエンタープライズ AI プラットフォームについてもっと知りたい方は、AWS re:Invent 2022 のセッションをご覧ください。TR が AWS Data Lab プログラムを使ってどのように機械学習の利用を加速させたかを知りたい方は、事例を参照してください。
翻訳はソリューションアーキテクト 前川 泰毅 が担当しました。原文はこちらです。