Amazon Web Services ブログ
製造業における全体的品質管理改善:機械学習をエッジや中央ダッシュボードに大規模活用
このブログは2022年1月12日に Julien Chidiack, Gaurav Kaila, Weibo Gu によって投稿された“Improve overall quality control in manufacturing: using ML at edge and central dashboards at scale”をソリューションアーキテクトの山田が翻訳したものです。
イントロダクション
インダストリー4.0時代に製造業が急速に進化する中、業界の専門家は産業プロセスの改善と最適化のための技術を模索しています。より良い製品を製造することは、全体的なコストの削減、収益の増加、低価格での製品の提供、市場投入までの時間の短縮とともに、業界の最優先事項の1つです。重要な品質管理プロセスを経ることにより、お客様に欠陥のない製品を提供できます。しかし、このプロセスは、依然として大部分のユースケースで主に人手に頼っています。
アマゾンウェブサービス (AWS) では、世界中のデータセンターから 200 を超えるフル機能のサービスを提供しています。さらに、AWS パートナーネットワーク (APN) には、自社のテクノロジーを AWS に対応させている何千もの独立系ソフトウェアベンダー (ISV) が含まれています。これにより、お客様に多くのワークロードをサポートできるツールとキャパシティを提供できます。また、お客様は適切なツールを使用して適切なアプリケーションをビジネスニーズに合わせてカスタマイズできます。
このブログ記事では、製造プロセスのさまざまな段階でダッシュボードで警告するなど、製造製品の欠陥を特定するために、機械学習ベースの画像検出システムをセットアップする方法を探ります。また、バックエンドセンサーの取り込み、保存、アラートアーキテクチャについても説明します。再現性のある自動メカニズムを使用することで、生産ラインでの品質チェックの回数を増やすことができるため、検査作業の改善、エラーの減少、製造チェーンの可視性の向上につながります。さらに、この自動プロセスで生成されたデータと製造装置で生成されたデータを関連づけて、生産性、可用性、品質によって評価される総合設備効率(OEE)を監視できます。データサイロを解消し、中央の製造データレイクにデータを配置することで、工場や機械の詳細データを保存しつつ、監視をエンタープライズレベルに引き上げることができます。これにより、製造プロセスをより深く理解し、データ駆動型アプローチを使用して製造プロセスを改善する方法についての洞察を得ることができます。
KPI の定義
ダッシュボードとモニタリング対象の KPI を早い段階で定義しておくと、テクノロジーの観点からそれらを逆算して、ソリューションとカスタマーエクスペリエンスを設定しやすくなります。そこで、最初に、作成したいダッシュボードと、イントロダクションで説明した課題に対処するためにモニタリングする必要のあるKPIを詳しく見ていきます。
今回のシナリオ設定例として、アルミボトルの製造プロセスを用います。ただし、基礎となる概念 (ML — データ取得 — データ分析) は変わらないため、他の製造ユースケースにも適用できることに留意してください。
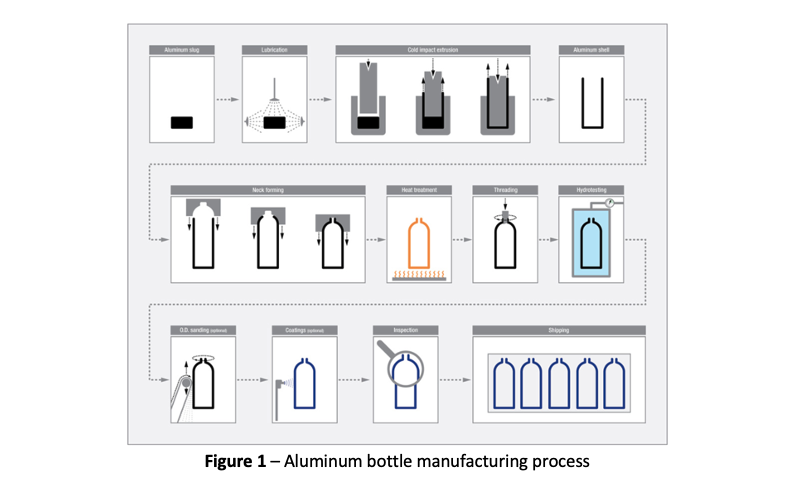 上の図1では、アルミスラグ—注油—衝撃冷間押出—アルミシェル—ネック成形—熱処理—ねじ切り—水圧試験—検査ー出荷の各製造ステップを表して、アルミボトルの製造プロセスをモデル化しました。これにより、各ステップの出力をモニタリングし、欠陥の根本原因をトレースバックして適切なレベルで対処することができます。
上の図1では、アルミスラグ—注油—衝撃冷間押出—アルミシェル—ネック成形—熱処理—ねじ切り—水圧試験—検査ー出荷の各製造ステップを表して、アルミボトルの製造プロセスをモデル化しました。これにより、各ステップの出力をモニタリングし、欠陥の根本原因をトレースバックして適切なレベルで対処することができます。
このビューはモニタリングダッシュボードに統合され、単純なデータ/ログだけではなく、より視覚的にすることで、人間による検査を補強しています。これにより、欠陥を検知した事象と、機械からの遠隔測定データに関連付けることができるため、欠陥が発生した製造ステップをすばやく特定できます。
図2(下)は、検査段階で検出された欠陥をモニタリングアラートで強調表示する方法の例です。
 これらのダッシュボードを作成するには、AWS Marketplace で利用できるデータ視覚化用のオープンソースの IoT プラットフォームである ThingsBoard を使用します。ThingsBoard には、ダッシュボードの作成を容易にするカスタムウィジェットが用意されています。また、デバイスにコマンドを送信してコマンド実行の結果を受け取ることもできます。
これらのダッシュボードを作成するには、AWS Marketplace で利用できるデータ視覚化用のオープンソースの IoT プラットフォームである ThingsBoard を使用します。ThingsBoard には、ダッシュボードの作成を容易にするカスタムウィジェットが用意されています。また、デバイスにコマンドを送信してコマンド実行の結果を受け取ることもできます。
はじめに説明したように、1つの工場での生産を現場レベルから把握することに加えて、エンタープライズレベルでの生産状態全体像も把握したいと考えています。そのために、OEEと呼ばれる指標を使用しました。これは、機械の可用性と生産性、および製品の品質に基づいて計算されます。目標は、これらの指標をさまざまなレベルで集計して、地域ごと、国ごと、工場ごとのビューを提供することです(下の図3を参照してください。ここでは、北京、バンコク、シドニー、ナイロビ、ルクセンブルグ、ブエノスアイレス、ニューヨーク、メキシコの8つの地域を対象としています)。

このダッシュボードを使用すると、地域毎の問題発生の有無をすばやく特定し、問題の概要を把握できます。私たちのプロトタイプでは、ベルトコンベアのリアルタイム速度、最大速度、モーターの状態(オン/オフ)などの指標を使用して、可用性と生産性を計算しました。現実世界の生産ラインでは、計算式にさらにメトリックを追加します。カラーゲージを見ると、さまざまな地域の生産性を比較できます。
ここで、これらの地域のいずれかをクリックすると、工場レベルでデータと進行中のアラートを示す中間ビュー (図 3 の高レベルビューと図 2 の生産チェーン) が表示されます (下の図 4 を参照)。

画面の左上には、クリックした地域に固有のOEEが表示され、可用性、生産性、品質のKPIのオンとオフを切り替えて詳細を確認することができます。左下には、検出された欠陥の数が、欠陥の種類 (塗装キズ、キャップの欠落など) でソートされています。画面の右側には、欠陥が検出された後にステータスが記載された進行中のアラートが表示されます。アラートを確認してチームに作業を割り当てすることができます。また、欠陥を確認した後にアラートを解除することもできます。
バックエンド
ダッシュボードの中身と動作について説明したので、次はその背後にあるアーキテクチャとサービスを詳しく見ていくことで (下の図 5 を参照)、こういったタイプのモニタリングプラットフォームを構築するための要件を理解します。

このセクションでは、複数のハードウェアシステムが連携して生成されたデータを使用してダッシュボードを作成します。これらには、ベルトコンベア、カメラ、エッジベースの機械学習コンピューティング(いわゆるコンピュータービジョンと呼ばれる)が含まれます。AWS IoT Core を使用してメトリクスをほぼリアルタイムでキャプチャし、AWS Transfer Family を使用して製品の新しい写真を定期的に Amazon S3 にアップロードしています。また、AWS IoT Core から Amazon Timestreamにメトリクスを送信します。これら 2 つのクラウドストレージサービス (図 5 のブロック「7」を参照) は、製造データレイクとして機能します。
1. Amazon Simple Storage Service(Amazon S3)は、業界トップクラスのスケーラビリティ、データ可用性、セキュリティ、生産性、および低コストを提供するオブジェクトストレージサービスであり、産業用データレイクに最適なストレージレイヤーです。ここでは Amazon S3 を使用して、生データや製品画像などの非構造化データを保存します。これらの画像を再利用して Amazon SageMaker の機械学習モデルをトレーニングします (これについては、以下のセクションで詳しく説明します)。
2. Amazon Timestream は、IoTやDevOpsアプリケーションのデータ収集および分析向けの、高速でスケーラブルかつサーバーレスの時系列データベースサービスです。ほぼリアルタイムの異常検出を行うことができ、最終的にはデータをミリ秒単位で利用できるようになります。
データレイクは、工場から転送されるさまざまなタイプのデータを保存するアーキテクチャの中心的な役割を果たし、コンピュータービジョンと機器データ分析という2つの主要なワークフローを実現します。
AWS でのコンピュータビジョン (CV)
製品の品質検査を自動化するには、ほぼリアルタイムの推論を行い、外部ネットワークの切断問題を防ぐために、機械学習 (ML) モデルをエッジで実行する必要があります。コンピュータービジョンは、エッジカメラ (e-CAM130 13MP) とエッジコンピューター (Jetson Xavier AGX) で構成されています。これらは、図6に示すように、プロトタイプ用にカスタムビルドされた囲いに収められ、ベルトコンベアの上に設置されます。

製品(この場合はアルミボトル)は囲いを通過し、さまざまな角度から4枚の画像をキャプチャします。取得した画像に機械学習の推論を行い、傷やキャップの欠落などの欠陥を特定するために、2 つの ML モデルを組み合わせて Jetson Xavier AGX エッジコンピューターを使用します。Amazon SageMaker を使用して一般物体検知 (SSD) アルゴリズムをトレーニングし、AWS IoT Core を使用してエッジにデプロイしました。現在の推論速度は画像あたり200ミリ秒未満です。つまり、入力画像がMLモデルで処理されるのにかかる時間は1/4秒未満です。推論結果は、ベルトコンベア速度などの追加のメタデータと組み合わされ、Jetson デバイスで実行されている AWS IoT Greengrass 経由で AWS クラウドに取り込まれます (図 5 のブロック「6」を参照)。
ハードウェアの選択は、1) 処理能力、2) コスト、3) 市場での入手のしやすさに基づいています。他の製品(Jetson Nanoなど)よりもJetson Xavier AGXデバイスを選択すると、生産性を損なうことなく複数のMLモデルを並行して実行できます。Jetson Xavier AGXデバイスはUbuntu 16.04 OSを実行し、サードパーティベンダー固有のソフトウェアに縛られることなく、カスタム機械学習コードを柔軟に実装できます。e-CAM130カメラモジュールを使用すると、最大4台のカメラをJetson Xavier AGXデバイスに接続し、1280×720の解像度で画像を入力できます。
下の画像(図7)は、MLモデルで欠陥部分が強調表示されているボトルの例です。

ベルトコンベアを通過する製品ごとに、さまざまな測定基準が記録されます。下の図 8 は、記録を表すサンプル JSON を示しています。エッジコンピュータは AWS IoT GreengrassV2 で設定され、リアルタイムデータを AWS クラウドに送信します。JSON メタデータがクラウドにアップロードされる頻度は、単位時間でベルトコンベアを通過する製品の数によって異なります。このデモでは、3 秒ごとに 1 つの JSON アップロードを行う頻度でセットアップをテストしました。
- siteId: 製造拠点の所在地
- timestamp: 商品がチェックされた日付と時刻
- productDetected: 製品が存在するかどうかを示すブーリアン型フラグ
- productionLineStatus: 製造ラインが稼働しているかどうか
- conveyerBeltSpeed: 製造ラインの速度
- cam1、cam2、cam3、cam4: システムが欠陥を検出した画像上の矩形座標のリスト。
- defectDetected: 欠陥が検出されたかどうかのブーリアン型フラグ
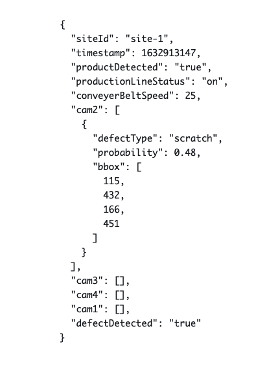
Figure 8 — Sample JSON
一連のさまざまなサービスが連携して上記のデータを保存、処理し、ThingsBoard ダッシュボードに入力します (図 5 のブロック「6」、「7」を参照)。これらのサービスを選択した動機は、サーバーレスでスケーラブルなアーキテクチャを持つことでした。
1. AWS IoT Core: 現場から全ての生のメトリクスを一箇所に集め取り込むためのリソースとして機能し、複数の後続のさまざまなサービスで処理できるようにします。
2. Amazon Kinesis Firehose: IoT Core から S3 に生のメトリクスを取り込んでデータロギングを可能にするサービス。
3. Amazon Timestream: リアルタイムデータを取り込むことができます。また、生データを集約してビジネスメトリクスに加工して下流での可視化を可能にする分析機能(Avg、Sum、Between、Between、Between、Bin、Interpolate など)も提供します。
このセットアップでは、ボトルが品質管理システムを通過する時間と、結果をクラウドにアップロードして後段の処理を行うまでの時間を含む、ボトルの品質評価を1秒ごとに実施できます。ThingsBoard ダッシュボードでは、このような 10 件の工場の結果を並行して取り込み、OEE などのビジネス関連の指標を表示できます。このアーキテクチャは、必要に応じて複数工場に展開できるように設計されています。
設備データ分析
欠陥の根本原因を突き止め、異常に対して有意義なアラートを生成するために、欠陥推論結果を製造プロセス中のリアルタイムの機器メトリクスと関連付けます。これをデータエンリッチメント(内外のデータソースからさまざまなデータセットを組み合わせる一連のプロセス)といいます。たとえば、機器のデータポイント「ベルト速度=100 rps」だけでは意味のある情報が得られませんが、機器ID、生産ラインID、タイムスタンプ、標準的な閾値、および温度や振動などのその他の関連機器データと組み合わせると、プロセス内の異常パターンを検出(または外れ値検出)するためのアルゴリズムを活用できるようになります。
そのために (図 5 のブロック「5」、「6」、「7」を参照)、エッジゲートウェイデバイスに AWS Lambda 関数をデプロイします。そのLambda関数で機器のメトリクスデータをJSON形式に集約し、データを AWS IoT Coreに送信します。AWS IoT Coreは、リアルタイムの機器メトリクス (機器 ID、ベルトコンべアの速度、生産状況など) を Amazon Timestream に送ります。
次に、Amazon CloudWatch を使用して 1 分ごとに別の AWS Lambda 関数を実行するようにスケジュールします。この関数は Amazon Timestreamから直近の 60 秒間に大量のデータを取得し、そのパケットを Amazon SQS のキューに入れます。ThingsBoard はキューからパケットを取り込み、ダッシュボードを更新します。(図5のブロック「9」を参照)
Amazon SQS を間に置く理由は、システムを疎結合にし、よりロバスト性を高め、次のようなシナリオでデータが失われないようにするためです。
— Lambda関数と ThingsBoard 間の接続上の問題が生じた場合
— ThingsBoard が過負荷状態になり、次のパケットが到着するまでデータを取り込むことができなくなった場合
通知
最後に、通知を即時に実施することで、何か異常が検出された場合に製造部門が迅速に行動するのに役立ちます。AWS Lambda 関数でビジネスロジック (例: x 分間の良品率が 80% を下回った場合) を定義し、Amazon Simple Notification Service を使用して通知を製造部門に送信します (図 4 のブロック「8」を参照)。
結論
Amazon の機械学習と IoT サービスをパートナーのソフトウェアやハードウェアと共に使用することで、生産プロセスを刷新し、製品の品質管理を改善できます。一般的には、新しいプロセスの導入は、「1 つの拠点への実証」から「多数の拠点への拡張」という流れをたどります。AWS のサービスと連携することで、企業は AWS のグローバルインフラストラクチャを活用して、1 つの拠点で複雑なソリューションを構築してテストし、同じ API を使用してすぐに他の拠点にデプロイできます。再現可能なメカニズムを使用して品質検査を自動化できることで、生産ラインでの品質チェックの数を増やすことができるため、欠陥の原因分析と予防的な検出が容易になり、最終的にはお客様の利益のために、工場から出荷される製品の全体的な品質向上につながります。
業界のユースケースをより知りたい場合は、AWS for Industrial のウェブサイトをご覧ください。
翻訳はソリューションアーキテクトの 山田航司 が担当しました。原文はこちらです。