Category: Amazon Athena
Amazon Athena – 10가지 성능 향상 팁
Amazon Athena는 표준 SQL을 통해 Amazon S3에 저장된 데이터를 쉽게 분석 할 수 있는 대화식 쿼리 서비스입니다. Athena는 서버리스(Serverless) 서비스로서, 관리해야 할 분석 서버 인프라가 없으며, 실행 쿼리에 대해서만 비용을 지불하고, 사용 방법도 매우 쉽습니다. Amazon S3에 있는 데이터 파일을 지정하고, 이에 대한 스키마를 정의한 후, 표준 SQL을 사용하여 쿼리를 하기만 하면 됩니다.
이 블로그 게시물에서는 Athena의 SQL 쿼리 성능을 향상 시킬 수있는 10 가지 팁을 알려드립니다. 특정 쿼리를 튜닝하는 것과 관련된 측면에 중점을 두어 설명합니다. Amazon Athena는 Presto를 사용하여 SQL 쿼리를 실행하므로 Amazon EMR에서 Presto를 실행하는 경우에도 이 팁들이 유용할 수 있습니다.
이 글을 읽기 앞서 우선 여러분이 Parquet, ORC, 텍스트 파일, Avro, CSV, TSV 및 JSON과 같은 다양한 파일 형식에 대한 지식이 있다고 가정합니다.
I. 스토리지 모범 사례
이 섹션에서는 Athena를 최대한 활용할 수 있도록 데이터를 구조화하는 방법에 대해 설명합니다. 데이터가 Amazon S3에 저장되는 경우 Spark, Presto 및 Hive와 같은 Amazon EMR 데이터 처리 응용 프로그램에도 동일한 방법을 적용 할 수 있습니다.
1. 데이터 분할(Partitioning)
데이터 분할 이른바 파티셔닝은 날짜, 국가, 지역 등의 컬럼 값을 기반으로 테이블을 부분적으로 나눕니다. 테이블 생성 시 이를 정의하면 쿼리 당 스캔 되는 데이터 양을 줄여 성능을 향상 시킬 수 있습니다. 파티션을 기반으로 필터를 지정하여 쿼리가 검색하는 데이터의 양을 제한 할 수 있습니다. 자세한 내용은 데이터 분할을 참조하십시오.
Athena는 다음 명명 규칙 중 하나를 따르는 Hive 파티셔닝을 지원합니다.
a) 분할 칼럼 이름 뒤에 등호 ( ‘=’)를 입력 한 다음 값을 입력하십시오.
s3://yourBucket/pathToTable/<PARTITION_COLUMN_NAME>=<VALUE>/<PARTITION_COLUMN_NAME>=<VALUE>/
데이터 집합이 위의 형식으로 분할 된 경우, MSCK REPAIR 테이블 명령을 실행하여 테이블에 테이블을 자동으로 추가 할 수 있습니다.
b) 데이터의 “path”가 위의 형식을 따르지 않으면 각 파티션에 대해 ALTER TABLE ADD PARTITION 명령을 사용하여 수동으로 파티션을 추가 할 수 있습니다. 예를 들면,
s3://yourBucket/pathToTable/YYYY/MM/DD/
Alter Table <tablename> add Partition (PARTITION_COLUMN_NAME = <VALUE>, PARTITION_COLUMN2_NAME = <VALUE>) LOCATION ‘s3://yourBucket/pathToTable/YYYY/MM/DD/’;
참고 : 위의 방법론을 사용하면 참조 할 값으로 위치를 매핑 할 수 있습니다.
다음 예제는 S3 버킷에 저장된 비행기 운항 정보 테이블의 연도 기반으로 데이터가 분할 되는 방법을 보여줍니다.
‘WHERE’절에서 칼럼을 사용하여 쿼리에서 검색되는 파티션을 제한 할 수 있습니다.
SELECT dest, origin FROM flights WHERE year = 1991여러 칼럼을 파티션 키로 사용할 수 있고, 특정 값에 대해 데이터를 스캔 할 수도 있습니다.
s3://athena-examples/flight/parquet/year=1991/month=1/day=1/
s3://athena-examples/flight/parquet/year=1991/month=1/day=2/
분할 할 칼럼을 결정할 때 다음 사항을 고려하십시오.
- 필터로 사용되는 칼럼 분할의 좋은 후보입니다.
- 파티셔닝은 비용이 듭니다. 테이블의 파티션 수가 증가하면 파티션 메타 데이터를 검색하고 처리하는 데, 소요되는 오버 헤드가 커지고 파일 크기가 작아집니다. 파티션을 너무 세밀하게 사용하면 초기 이점을 없앨 수도 있습니다.
- 데이터가 하나의 파티션 값으로 크게 왜곡되어 대부분의 쿼리가 해당 값을 사용하면, 오히려 오버 헤드가 초기 이점을 없앨 수 있습니다.
예제 살펴 보기
아래 테이블은 분할 된 테이블과 분할 되지 않은 테이블 간의 쿼리 실행 시간을 비교합니다. 두 테이블 모두 압축되지 않은 74GB 데이터를 텍스트 형식으로 저장합니다. 파티션 된 테이블은 l_shipdate 컬럼으로 파티션되며 2526 개의 파티션을 가집니다.
| 쿼리 | 파티션하지 않은 테이블
|
비용 | 파티션한 테이블 | 비용 | 절감 정도 | ||
| 실행 시간 | 스캔데이터 | 실행 시간 | 스캔데이터 | ||||
| SELECT count(*) FROM lineitem WHERE l_shipdate = '1996-09-01' | 9.71 seconds | 74.1 GB | $0.36 | 2.16 seconds | 29.06 MB | $0.0001 | 99% cheaper
77% faster |
| SELECT count(*) FROM lineitem WHERE l_shipdate >= '1996-09-01' AND l_shipdate < '1996-10-01' | 10.41 seconds | 74.1 GB | $0.36 | 2.73 seconds | 871.39 MB | $0.004 | 98% cheaper
73% faster |
그러나 파티셔닝에는 다음 실행 시간에 표시된 것과 같은 패널티가 있습니다. 따라서 데이터를 과도하게 분할하지 않도록 하십시오.
| 쿼리 | 파티션하지 않은 테이블
|
비용 | 파티션한 테이블 | 비용 | 절감 정도 | ||
| 실행 시간 | 스캔데이터 | 실행 시간 | 스캔데이터 | ||||
| SELECT count(*) FROM lineitem; | 8.4 seconds | 74.1 GB | $0.36 | 10.65 seconds | 74.1 GB | $0.36 | 27% slower |
2. 파일 압축 및 분할
데이터를 압축하면 파일이 최적 크기이거나 분할 할 수 있는 경우 쿼리 속도를 크게 높일 수 있습니다. 데이터 크기가 작을수록 S3에서 Athena까지 네트워크 트래픽 역시 감소합니다.
Splittable 파일을 사용하면 Athena의 실행 엔진이 파일 읽기를 분할하여 병렬 처리를 높일 수 있습니다. 분할 할 수 없는 파일이 하나 있는 경우 다른 리더가 유휴 상태 인 동안 싱글 리더만 파일을 읽을 수 있습니다. 모든 압축 알고리즘이 분할 가능하지는 않습니다. 다음 표는 일반적인 압축 형식과 해당 특성을 나열합니다.
| 알고리즘 | 분할 가능? | 압축 비율 | 압축 및 해제 속도 |
| Gzip (DEFLATE) | No | High | Medium |
| bzip2 | Yes | Very high | Slow |
| LZO | No | Low | Fast |
| Snappy | No | Low | Very fast |
일반적으로 알고리즘의 압축 비율이 높을수록 데이터 압축 및 압축 해제에 더 많은 CPU가 필요합니다.
Athena의 경우 기본적으로 데이터를 압축하고 분할 할 수 있는 Apache Parquet 또는 Apache ORC를 사용하는 것이 좋습니다. 그렇지 않은 경우라면, 최적의 파일 크기로 BZip2 또는 Gzip을 시도하십시오.
3. 파일 크기 최적화
데이터를 병렬적으로 읽거나 데이터 블록을 순차적으로 읽을 수 있을 때, 쿼리를 효율적으로 실행합니다. 파일의 크기에 관계없이 파일 형식이 분할 가능하면 병렬 처리에 도움이 됩니다.
그러나, 파일 크기가 128MB 보다 작으면 실행 엔진은 S3 파일 열기, 디렉토리 나열, 객체 메타 데이터 가져 오기, 데이터 전송 설정, 파일 헤더 읽기, 압축 딕셔너리 읽기 등 추가 작업에 시간을 더 쓸 수 있습니다. 반면, 파일이 분할 가능하지 않고, 파일이 너무 크면 싱글 리더가 전체 파일 읽기를 완료 할 때까지 쿼리 처리가 대기하여 병렬 처리가 줄어들 수 있습니다.
작은 파일 문제를 해결하는 한 가지 방법은 EMR에서 S3DistCP 유틸리티를 사용하는 것입니다. 이를 통해 작은 파일을 더 큰 오브젝트로 결합 할 수 있습니다. S3DistCP는 또한 HDFS에서 S3, S3에서 S3, S3에서 HDFS로 최적화 된 방식으로 많은 양의 데이터를 이동하는 데 사용할 수 있습니다.
대용량 파일의 장점은 아래와 같습니다.
- 더 빠른 목록
- 더 적은 S3 요청
- 관리 할 메타 데이터 감소
예제 살펴 보기:
아래 표는 두 테이블 간의 쿼리 실행 시간을 비교합니다. 하나는 큰 단일 파일로, 다른 하나는 작은 파일입니다. 두 테이블 모두 7GB의 데이터를 포함하며 텍스트 형식으로 저장됩니다.
| 쿼리 | 파일 수 | 실행 시간 |
| SELECT count(*) FROM lineitem | 5000 files | 8.4 초 |
| SELECT count(*) FROM lineitem | 1 file | 2.31 초 |
| 속도 증가 | 72% 속도 증가 |
4. 컬럼 데이터 저장소 생성 최적화
Apache Parquet과 Apache ORC 는 인기 있는 컬럼 데이터 저장소입니다. 열 단위 압축, 다양한 인코딩, 데이터 유형에 기반한 압축 및 술어 푸시 다운(predicate pushdown)을 사용하여 효율적으로 데이터를 저장하는 기능을 제공합니다. 분할 역시 가능합니다. 일반적으로 압축률을 높이거나 데이터 블록을 건너 뛰는 것은 S3에서 적은 바이트를 읽음으로써 쿼리 성능이 향상된다는 것을 의미합니다.
조정할 수 있는 매개 변수 중 하나는 블록 크기 또는 스트라이프 크기입니다. ORC의 마루 또는 스트라이프 크기의 블록 크기는 바이트 단위로 한 블록에 들어갈 수있는 최대 행 수를 나타냅니다. 블록 / 스트라이프 크기가 클수록 각 블록에 더 많은 행을 저장할 수 있습니다. 기본적으로 Parquet 블록 크기는 128MB이고 ORC 스트라이프 크기는 64MB입니다. 여러 열이있는 테이블을 사용하는 경우 더 큰 블록 크기를 사용하여 각 열 블록이 효율적인 순차 I / O를 허용하는 크기로 유지되도록하는 것이 좋습니다.
조정할 수있는 또 다른 매개 변수는 데이터 블록의 압축 알고리즘입니다. Parquet 기본값은 Snappy이지만 비압축, GZIP 및 LZO 기반 압축도 지원합니다. ORC는 ZLIB를 기본으로 비압축 및 스냅을 지원합니다. 10GB 이상의 데이터가 있는 경우 기본 압축 알고리즘으로 시작하고, 다른 압축 알고리즘으로 테스트하는 것이 좋습니다.
Parquet/ORC 파일 형식은 모두 술어 푸시 다운 (혹은 predicate filtering)을 지원합니다. Parquet/ORC는 둘 다 칼럼 값을 나타내는 데이터 블록을 가지며, 각 블록은 최대/ 최소값과 같은 블록 통계를 보유합니다. 쿼리가 실행될 때, 이러한 통계는 블록을 읽거나 건너 뛸지 여부를 결정합니다. 건너 뛸 블록 수를 최적화 하는 한 가지 방법은 ORC 또는Parquet 파일을 작성하기 전에 일반적으로 필터링 된 칼럼을 식별하고 정렬하는 것입니다. 이렇게 하면 블록 내의 최소 값과 최대 값 사이의 범위가 각 블록 내에서 가능한 작게 유지됩니다.
기존 데이터를 Amazon EMR의 Spark 또는 Hive를 사용하여 Parquet 또는 ORC로 변환 할 수 있습니다. 자세한 내용은 Amazon Athena 블로그 게시물을 사용하여 S3의 데이터 분석을 참조하십시오.
- aws-blog-spark-parquet-conversion (Spark GitHub)
- Converting to Columnar Formats (Hive 사용)
II. 퀴리 모범 사례
Athena는 Presto를 사용합니다. 따라서 Presto의 작동 방식을 이해하고 쿼리를 최적화하는 방법을 통해 여러 가지 성능 향상 결과을 얻을 수 있습니다.
5. ORDER BY 최적화
ORDER BY 절은 쿼리 결과를 정렬 순서대로 반환합니다. 정렬을 수행하기 위해 Presto는 모든 데이터 행을 단일 작업자에게 전송 한 다음 정렬해야 합니다. 이로 인해 Presto에 대한 메모리 부담이 발생할 수 있으며 이로 인해 쿼리 실행 시간이 오래 걸릴 수 있습니다. 게다가 쿼리가 실패 할 수 있습니다.
ORDER BY 절을 사용하여 위 또는 아래 N 값을 확인하는 경우, LIMIT 절을 사용하면 단일 작업을 수행하는 대신 정렬 작업을 수행하여 개별 작업자를 제한하여 정렬 비용을 크게 줄일 수 있습니다.
예제 살펴 보기:
Dataset: 7.25 GB 테이블, 비 압축, 텍스트 데이터 포맷, ~6천만 행
| 쿼리 | 실행 시간 |
| SELECT * FROM lineitem ORDER BY l_shipdate | 528 초 |
| SELECT * FROM lineitem ORDER BY l_shipdate LIMIT 10000 | 11.15 초 |
| 속도 감소 | 98% 단축 |
6. joins 최적화
두 테이블을 Join 할 때 Join 왼쪽에 큰 테이블을 지정하고 오른쪽에 작은 테이블을 지정하십시오. Presto는 오른쪽 테이블을 작업자 노드에 배포 한 다음, 테이블을 왼쪽으로 스트리밍하여 조인을 수행합니다. 오른쪽에 있는 표가 더 작으면 사용되는 메모리가 적어지고 조회가 더 빨리 실행됩니다.
예제 살펴 보기:
Dataset: 74 GB 데이터, 비 압축 및 텍스트 데이터, ~602백만 행
| 쿼리 | 실행 시간 |
| SELECT count(*) FROM lineitem, part WHERE lineitem.l_partkey = part.p_partkey | 22.81 초 |
| SELECT count(*) FROM part, lineitem WHERE lineitem.l_partkey = part.p_partkey | 10.71 초 |
| 속도증가 | ~53% 속도 증가 |
예외는 여러 테이블을 함께 결합 할 때 교차 결합이 발생할 수 있다는 것입니다. Presto는 아직 조인 순서 재 지정을 지원하지 않으므로 왼쪽에서 오른쪽으로 조인을 수행합니다. 따라서, 두 테이블이 함께 지정되지 않았는지 확인하면서도 크로스 조인을 발생시키면서 테이블을 가장 큰 테이블부터 가장 작은 테이블까지 지정해야합니다.
예제 살펴 보기:
Dataset: 9.1 GB 데이터, 비 압축 및 텍스트 데이터, ~76백만 행
| 질의 | 실행 시간 |
| SELECT count(*) FROM lineitem, customer, orders WHERE lineitem.l_orderkey = orders.o_orderkey AND customer.c_custkey = orders.o_custkey | 타임아웃 |
| SELECT count(*) FROM lineitem, orders, customer WHERE lineitem.l_orderkey = orders.o_orderkey AND customer.c_custkey = orders.o_custkey | 3.71 초 |
7. GROUP BY 최적화
GROUP BY는 GROUP BY를 한 칼럼을 기반으로, 각 행을 메모리의 GROUP BY 값에 보유하는 작업자 노드에 배포합니다. 행을 처리 할 때 GROUP BY 칼럼을 메모리에서 조회하고 값을 비교합니다. GROUP BY 열이 일치하면 그 값은 함께 집계됩니다.
따라서, 쿼리에서 GROUP BY를 사용하는 경우 분산성이 가장 높은 카디널리티 (Cardinality 즉, 고유 값의 대부분이 균등하게 분산)별로 칼럼을 정렬합니다.
가능한 한 GROUP BY 절 내에서 문자열 대신 숫자를 사용하는 것이 하나의 다른 최적화입니다. 숫자는 저장할 메모리가 적고 문자열보다 비교가 빠릅니다.
또 다른 최적화는 행에 메모리가 있고 GROUP BY 절에 대해 집계 될 때 필요한 메모리 양을 줄이기 위해 SELECT 문의 칼럼 수를 제한하는 것입니다.
8. LIKE 최적화
문자열 열에서 여러 값을 필터링 할 때는 일반적으로 LIKE 보다 여러 번 RegEx를 사용하는 것이 좋습니다. LIKE 할 내용이 많고, 문자열 열이 클수록 RegEx를 사용하면 절약 효과가 커집니다.
예제 살펴 보기:
Dataset: 74 GB 테이블, 비 압축, 텍스트 포맷, ~600백만행
| 쿼리 | 실행 시간 |
| SELECT count(*) FROM lineitem WHERE l_comment LIKE '%wake%' OR l_comment LIKE '%regular%' OR l_comment LIKE '%express%' OR l_comment LIKE '%sleep%' OR l_comment LIKE '%hello% | 20.56 초 |
| SELECT count(*) FROM lineitem WHERE regexp_like(l_comment, 'wake|regular|express|sleep|hello') | 15.87 초 |
| 속도 향상 | 17% 향상 |
9. 근사 함수 사용
대용량 데이터 세트를 탐색하는 일반적인 사용 사례는 COUNT (DISTINCT 열)를 사용하여 특정 열의 고유 값 수를 찾는 것입니다.
웹 페이지에 방문하는 고유 사용자 수를 살펴 보겠습니다. 정확한 숫자가 필요하지 않을 때 – 예를 들어, 어떤 웹 페이지에 대해 찾고 싶다면 approx_distinct ()를 사용해보십시오. 이 함수는 전체 문자열 대신 값의 고유 해시를 계산하여 메모리 사용을 최소화하려고 시도합니다. 단점은 2.3 %의 표준 오류가 있다는 것입니다.
예제 살펴 보기:
Dataset: 74 GB 테이블, 비 압축, 텍스트 포맷, ~600백만행
| 쿼리 | 실행 시간 |
| SELECT count(distinct l_comment) FROM lineitem; | 13.21 초 |
| SELECT approx_distinct(l_comment) FROM lineitem; | 10.95 초 |
| 속도향상 | 17% 증가 |
자세한 내용은 Presto 설명서의 집계 함수를 참조하십시오.
10. 필요한 칼럼만 사용
쿼리를 실행할 때 최종 SELECT 문을 모든 칼럼을 선택하는 대신 필요한 칼럼만으로 제한하십시오. 칼럼의 수를 줄이면 전체 쿼리 실행 파이프 라인을 통해 처리해야 하는 데이터의 양이 줄어 듭니다. 특히 많은 수의 칼럼과 문자열 기반 칼럼이있는 테이블을 쿼리 할 때 유용합니다.
예제 살펴보기:
Dataset: 7.25 GB 테이블, 비 압축, 텍스트 데이터 포맷, ~6천만 행
| 쿼리 | 실행 시간 |
| SELECT * FROM lineitem, orders, customer WHERE lineitem.l_orderkey = orders.o_orderkey AND customer.c_custkey = orders.o_custkey; | 983 초 |
| SELECT customer.c_name, lineitem.l_quantity, orders.o_totalprice FROM lineitem, orders, customer WHERE lineitem.l_orderkey = orders.o_orderkey AND customer.c_custkey = orders.o_custkey; | 6.78 초 |
| Savings / Speedup | 145x faster |
이 글에서는 Presto 엔진을 사용하여 Amazon Athena에서 대화형 분석을 최적화 하는 모범 사례에 대해 설명했습니다. Presto를 Amazon EMR에서 사용할 때도 이와 동일한 방법을 적용 할 수 있습니다.
– Manjeet Chayel (Solutions Architect ) 및 Mert Hocanin (EMR Big Data Architect);
이 글은 AWS BigData Blog의 Top 10 Performance Tuning Tips for Amazon Athena의 한국어 번역입니다.
Amazon Athena 초간단 사용기
지난 2016년 11월 28일부터 12월 2일에 걸쳐 개최된 글로벌 컨퍼런스 AWS re:Invent 2016에서는 20여개가 넘는 신규 기능 및 서비스가 발표되었습니다. 크게 나눠 보았을때 기존 서비스에 추가된 기능(새로운 EC2 타입 등)을 제외한다면 가장 많은 주목을 받은 부분은 딥러닝에 기반한 인공 지능 서비스(Amazon Rekognition, Polly, Lex 등)들과 데이터에 기반한 분석 서비스였습니다.
이 중 기존에 인프라나 비즈니스 운영을 관리하시는 분들이 가장 많이 관심을 가진 서비스가 바로 Amazon Athena 발표입니다. Athena는 Amazon S3 스토리지에 저장된 다양한 포맷의 기초 데이터, 예를 들어 csv, tsv, txt, CRC, Parquet 등에 대해 바로 표준 SQL 문을 사용해 데이터를 검색 및 분석할 수 있는 서비스입니다.
Amazon Athena의 기반 기술 및 장점
Amazon Athena는 페타바이트 규모의 데이터에 대해 표준 SQL 문에 기반한 질의를 수행할 수 있습니다. S3 를 스토리지로 사용하기 때문에 99.999999999%에 달하는 S3의 내구성이 그대로 데이터에 적용됩니다. 또한 데이터 소스에 대응하는 테이블 메타 정보만 생성하면 바로 쿼리를 수행할 수 있으며, 쿼리 수행 속도 또한 매우 빠릅니다.
가격 또한 매우 큰 이점으로 작용합니다. 매번 쿼리를 수행할 때 스캔하는 데이터의 양에 따라 과금되며, 미리 서버를 준비할 필요가 없어 고정 비용이 발생하지 않습니다. 비용은 S3에서 스캔하는 데이터 1TB당 5 달러입니다.
또한, Athena는 여러 가용영역에 걸친 컴퓨팅 자원을 준비해 두고 여러분의 쿼리를 처리합니다. 아래와 같이 크게 두 가지의 오픈소스 기술이 Athena에 적용되어 있습니다.

[그림 1] Athena의 적용 기반 기술
Presto는 인 메모리 분석 쿼리 엔진으로 ANSI-SQL이 호환됩니다. 또한 Hive는 DDL 관련 기능을 처리하는 것을 담당합니다. 복잡한 데이터 타입, 여러 포맷, 데이터 파티셔닝, 테이블 생성 등과 관련된 부분을 담당합니다.
Athena가 유용한 부분을 살펴보기 위해서는 다른 서비스, 예를 들어 유사한 AWS의 다른 빅 데이터 분석 서비스인 EMR, Redshift 와 어떤 차이점이 있는지 살펴보는 것이 좋겠습니다.
| Athena | EMR | Redshift |
| SQL 지원의 쿼리 서비스
S3에 데이터 존재 바로 실행 서버리스 쿼리 수행에 따른 과금 |
단순 SQL 만이 아니라, 여러 배치 잡을 수행 가능 (딥 러닝 트레이닝, 파일 변환/복사 등)
다양한 플랫폼을 사용해서 워크로드에 따라서 다양하게 구성 할 수 있음 데이터가 반드시 S3 에 있을 필요는 없음. 서버 클러스터 존재 클러스터 시간당 과금 |
여러 데이터 소스에 대해 구조화된 데이터를 집적. 전형적인 D/W 워크로드에 적합.
서버 클러스터 존재 시간당 과금 |
Athena를 적용할 수 있는 대표적인 분야는 각종 로그 분석입니다. 과거 대량 로그 분석에는 EMR 혹은 Redshift를 사용해야 했는데, EMR은 다양한 프레임워크 선택에서, Redshift는 비용에서 상대적으로 사용자가 부담을 가질 수 있었습니다. 이제는 Athena를 통해 손쉽고 저렴하게 분석을 할 수 있습니다.
물론 로그 분석 이외에도 ETL 적용이 부담스럽거나 어려운 워크로드, 기존에 Hive, Spark를 사용했던 워크로드들도 Athena가 대체할 수 있는 대상입니다.
Athena 바로 사용해 보기
서울 리전에 여러분의 데이터가 존재한다고 합시다. 현재 Athena는 2개 리전(버지니아, 오레곤)에서 사용할 수 있습니다. 따라서 서울 리전의 버킷을 버지니아 리전으로 리전간 복제(CRR, Cross Region Replication)합니다. 이것은 버킷의 프로퍼티에서 지정할 수 있습니다. CRR을 하기 위해서는 먼저 버킷의 버저닝을 활성해야 합니다. 활성 버튼을 누르고 나면 그림 2와 같이 설정을 할 수 있습니다.

그림2. CRR 설정
버킷 내 데이터의 양에 따라 다르지만 리전 간 복제 설정 시점 이후로 만들어진 신규 로그 파일에 대해서 버지니아의 대상 버킷으로 복제가 완료됩니다. 이렇게 복제가 완료된 후 Athena에서 데이터베이스와 테이블을 생성하면 됩니다.
예를 들어 로우 데이터가 csv파일이라고 합시다. 여러 파일이 버킷의 특정 폴더에 존재한다면, 데이터 소스를 다음과 같이 지정하면 해당 폴더 안의 파일 전체를 지정하게 됩니다.
S3:\\<버킷이름>\< 폴더이름>\
그림 3은 테이블을 새롭게 생성하는 화면입니다. 데이터베이스 이름은 새롭게 생성할 수도 있고 기존의 데이터베이스 이름을 사용할 수도 있습니다.

그림 3. 테이블의 생성
이렇게 테이블을 생성하고 나면, 각 칼럼들을 지정하게 됩니다. 그림 4는 소스 타입을 지정하는 부분입니다.
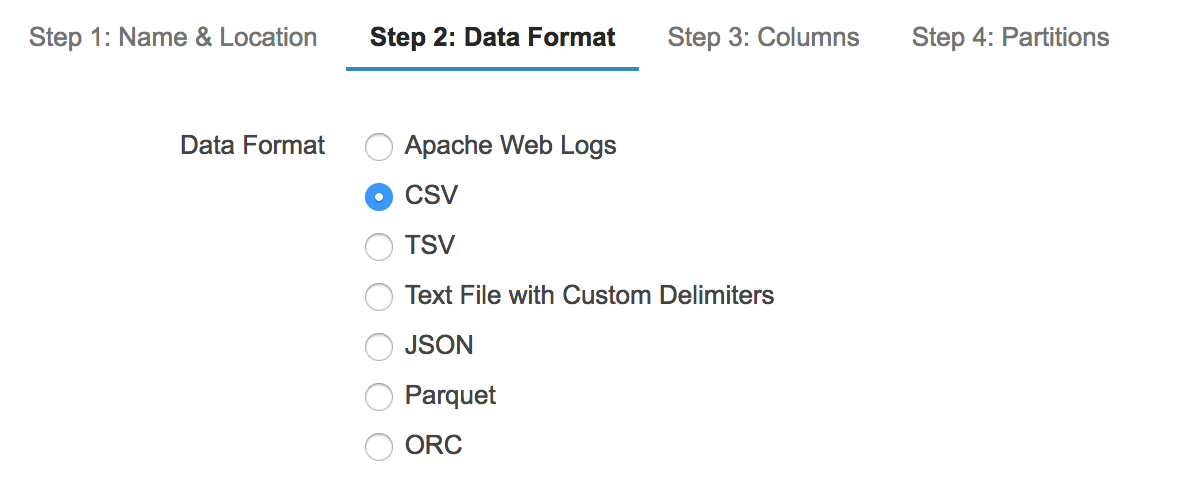
그림 4. 소스 타입 지정
그림 5.는 칼럼을 지정하는 과정입니다. 여기까지만 하면 기본적으로 쿼리를 수행할 수 있습니다.

그림 5. 칼럼 지정
이렇게 만들고 나면 바로 쿼리를 수행할 수 있습니다. 수행의 한 예제가 그림 6입니다.
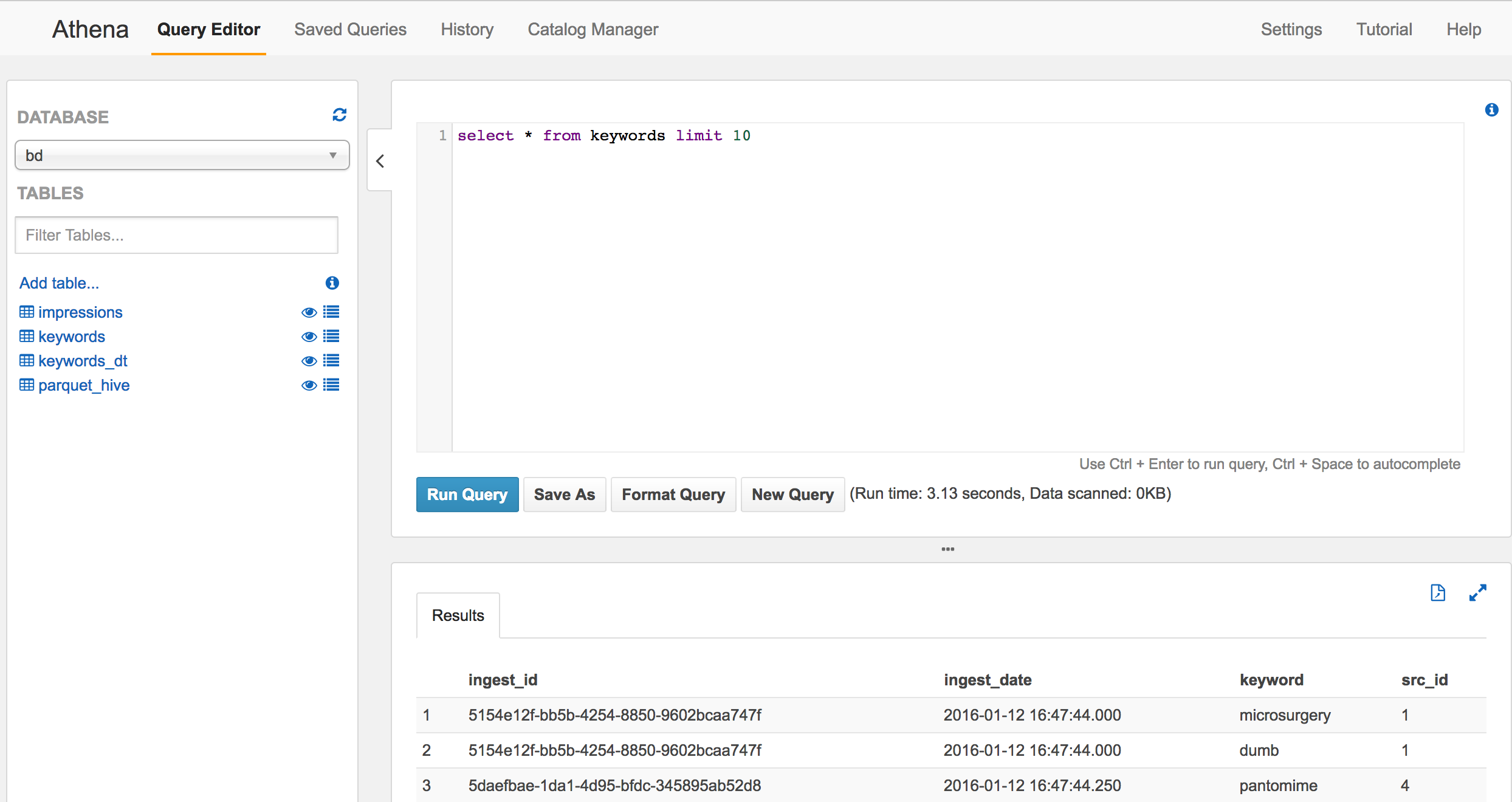
그림 6. 기본 쿼리의 수행
지금까지 Athena의 특성과 다른 서비스와의 비교를 살펴보았습니다. 이제 여러분의 S3 에 존재하는 데이터를 대상으로 바로 쿼리를 사용할 수 있으므로, 보다 손쉽게 데이터 분석과 관리가 가능합니다. 다음 포스팅에서는 Athena 활용에 도움이 되도록 보다 고급 예제, 파티셔닝, CRC, Parquet으로의 전환, 최적화 방법 등에 대해 살펴보도록 하겠습니다.
본 글은 아마존웹서비스 코리아의 솔루션즈 아키텍트가 국내 고객을 위해 전해 드리는 AWS 활용 기술 팁으로, 이번 포스팅은 박선용 솔루션즈 아키텍트께서 작성해주셨습니다.

Amazon Athena – 초단위 페타바이트급 동적 데이터 질의 서비스
(과거 1.44MB 플로피 디스크를 썼던 경험이 무색하게) 매일 우리는 매우 빠른 데이터량 성장에 놀라게 됩니다. 일상적으로 대량의 로그를 쌓고 질의하는 작업과 정형 혹은 반정형 데이터의 크기는 이미 페타바이트 규모입니다. 우리는 데이터의 위치를 찾아 로딩한 후 인덱싱을 통해 검색하는 일련의 과정을 빠르게 작업할 수 있는 방법을 찾고 있습니다. 이를 위해 높은 수준의 클라우드 솔루션을 가지고 있으며 모든 것이 수 분안에 처리될 수 있습니다.
Amazon Athena 소개
Amazon Athena는 Amazon S3에 저장되어 있는 페타데이터 규모의 데이터를 별도의 클러스터 구성 및 관리를 하지 않더라도 동적 질의를 할 수 있는 신규 서비스입니다. Amazon S3에 위치한 데이터를 지정만 하면, 내부 필드를 자동으로 인지해서 질의를 수행할 수 있습니다. 데이터를 옮기거나 별도 인덱스를 구성할 필요 없이 한 곳에서 할 수 있습니다.
Athena는 동적 질의 편집기를 통해 여러분이 손쉽게 작업을 할 수 있도록 도움을 주고 있으며, 표준 ANSI SQL 및 JOIN, 윈도 함수 등 고급 기능을 수행할 수 있습니다. Athena는 페이스북이 공개한 Presto를 기반으로 대부분 DDL (Data Definition Language)을 포함하는 PrestoSQL 역시 지원합니다.
Athena 서비스에 이면에서는 여러분이 보낸 질의를 병렬적으로 수백 또는 수천개의 코어를 통해 작업하여 결과를 (동적 혹은 JDBC/ODBC 커넥터를 통해) 초단위로 제공합니다.
Athana가 S3에 저장된 데이터를 직접 참조함으로서, 확장성 및 유연성 그리고 데이터 내구성, 데이터 보호 관점에서 이점을 얻을 수 있습니다. 예를 들어 KMS를 기반한 서버사이드 암호화를 통해 데이터 접근을 위해 IAM 정책을 정할 수 있습니다.
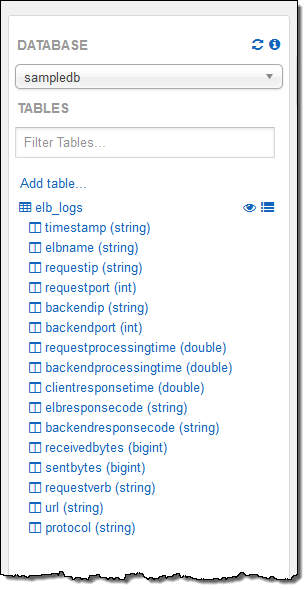
또한, Apache 로그, CSV, TSV, 일반 텍스트, JSON, Orc, Parquet 등 다양한 데이터 포맷을 지원할 뿐만 아니라 하나 이상의 S3 객체를 테이블로 지정할 수 있습니다. 각 Athena 데이터베이스는 하나 이상의 테이블로 구성되어 있는데 카탈로그 매니저를 통해 데이터 소스를 파악하고 추적할 수 있습니다.
Athena 사용해 보기
AWS 관리 콘솔을 통해 Amazon Athena 서비스를 선택하면, 아래와 같이 질의 편집기를 처음 보실 수 있습니다.
저의 계정은 이미 샘플 데이터베이스를 설정을 하였고, 데이터 베이스 내에는 elb_logs라는 테이블이 있습니다. 이제 간단한 질의문를 선택해서 Run Query를 누르면 됩니다. 몇 초 안에 결과가 바로 콘솔에 보이는 것을 보실 수 있습니다. 이제 결과를 CSV 파일 형태로 다운로드 할 수도 있습니다.
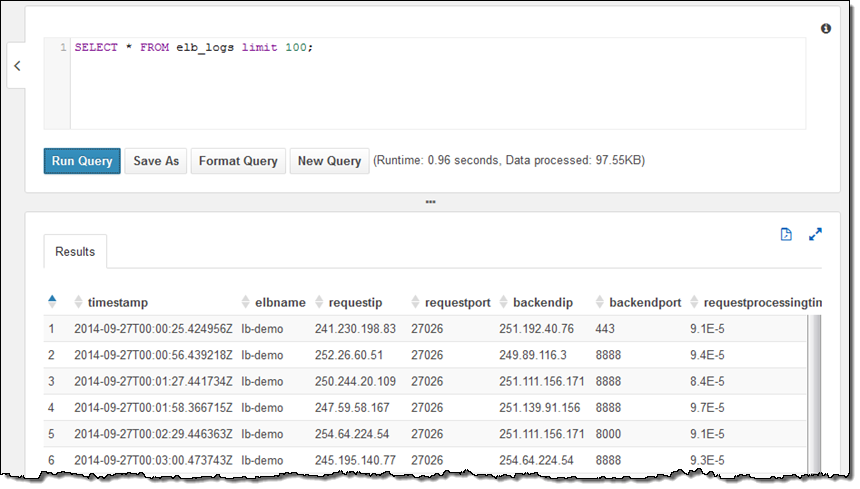
샘플 테이블은 Elastic Load Balancing의 로그 파일로서 HTTP 상태 코드로 분석할 수 있습니다.
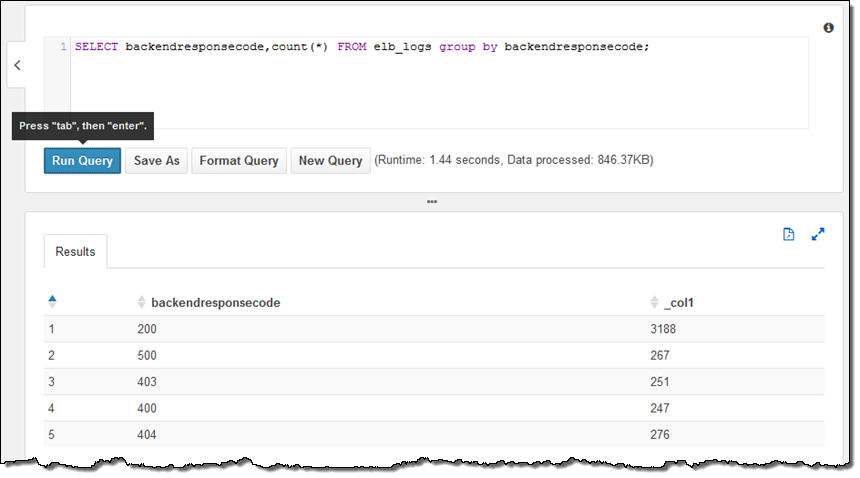
URL은 아래와 같습니다.
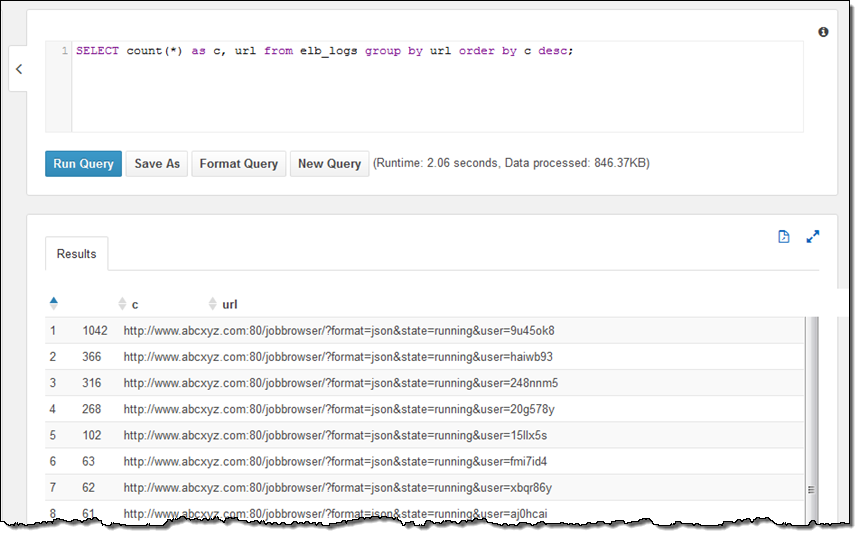
테이블 정의 지점은 S3 버킷이고 버킷 내 모든 객체를 encompass 합니다. 만일 새로운 로그 파일이 동적 세션에 들어오게 되면, 자동으로 순서에 따라 질의가 포함됩니다. (테이블 정의에 대해서는 아래에서 설명하겠습니다.)
콘솔에서 테이블 설명을 하기 위한 질의문을 실행 해보겠습니다. 그리고, 테이블과 필드명을 선택해서 질의에 값을 넣을 수 있습니다.
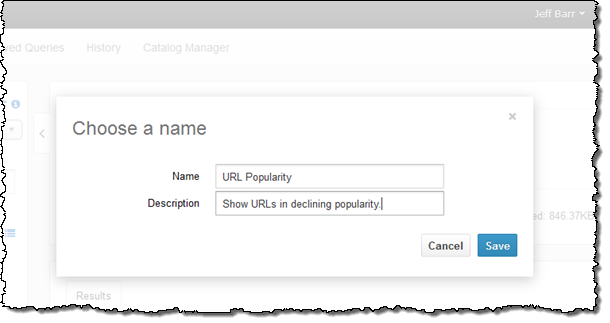
질의문을 저장하여 제가 원하는 작업을 마칩니다.
다음으로는 어떻게 데이터베이스를 만들고, 직접 데이터를 참조시키는지에 대해 배워 보겠습니다. 여기에는 두 가지 방법이 있습니다. 하나는 DDL 정의를 하는 것과 단계적 마법사 기능입니다. 동료로 부터 아래와 같은 간단한 샘플 DDL을 받았습니다.
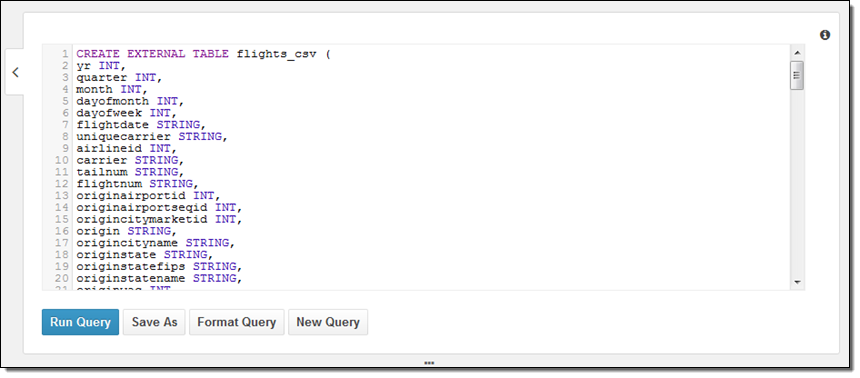
더 관심 있는 것은 질의문이구요. 아래와 같이 구성할 수 있습니다.
PARTITIONED BY (year STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
LOCATION 's3://us-east-1.elasticmapreduce.samples/flights/cleaned/gzip/';
데이터는 연간으로 분리되어 있기 때문에, 메타 데이터 설정을 마무리하기 위해 아래 부속 질의를 하나 더 해야 합니다.
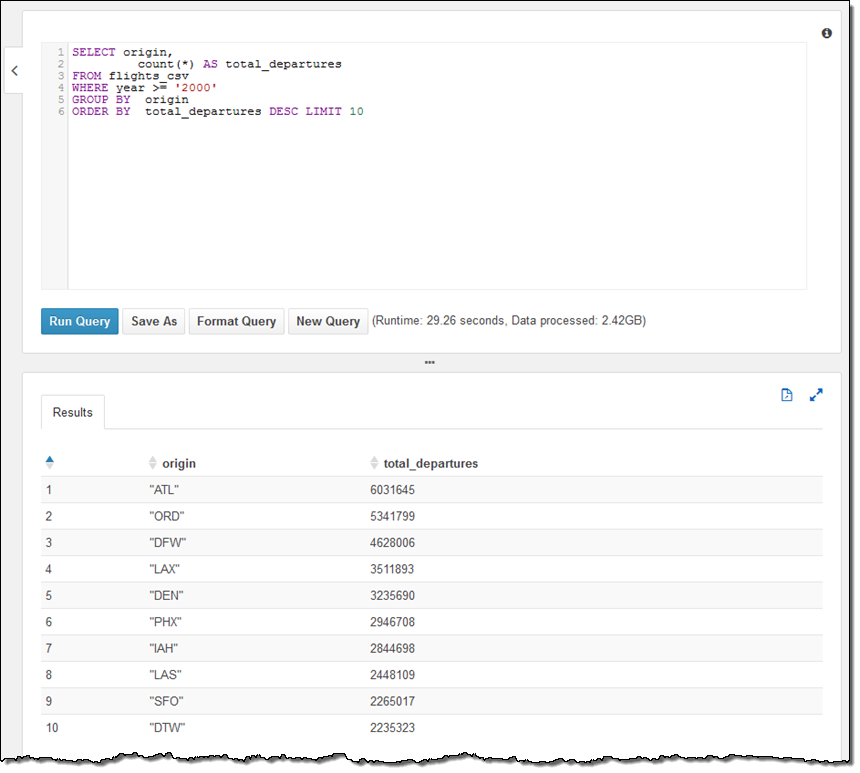
MSCK REPAIR TABLE flights_csv;위 예제는 2000년 부터 지금까지 가장 인기 있는 출발 공항이 있는 도시 10개를 추출하는 질의문입니다.
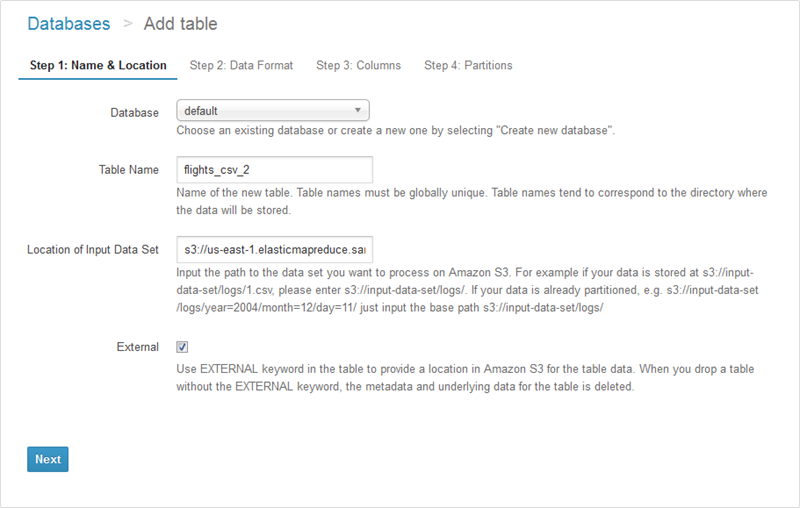
또한, Athena가 제공하는 테이블 마법사를 통해 (Catalog Manager에서 접근 가능) 테이블을 생성할 수 있습니다. 이 경우, 테이블 이름과 원하는 위치를 지정해주면 됩니다.
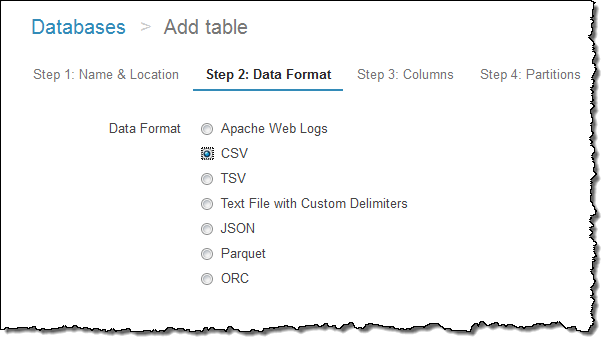
그다음 포맷을 지정합니다.
각 컬럼의 이름과 형식을 지정합니다.
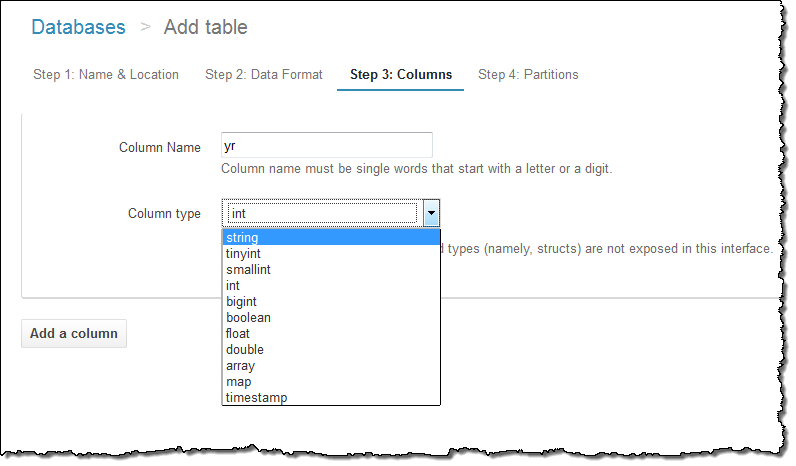
파티션 모델을 지정합니다.
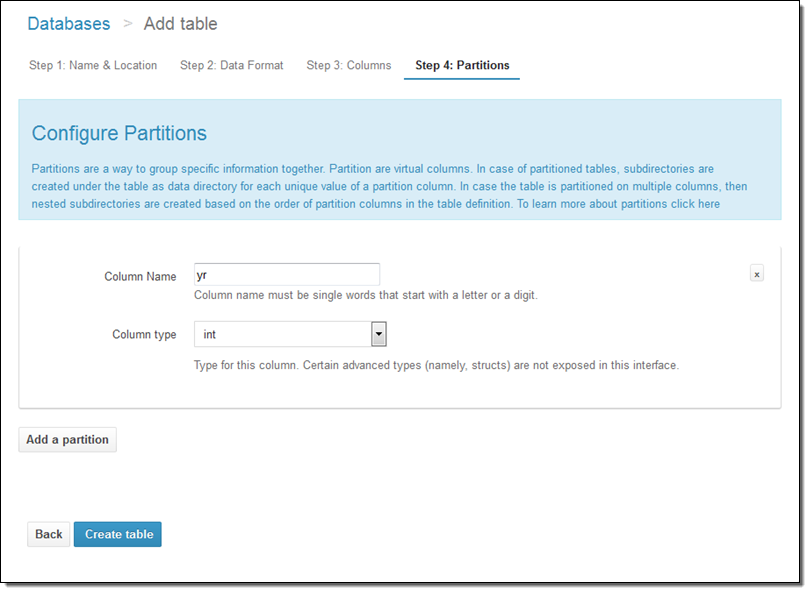
Athena는 그 밖에도 많은 신선한 기능이 있는데, 향후에 더 자세히 알려드릴려고 합니다. 우선 그 중에서도 질의 저장 기능, 질의 기록, 및 Catalog Manager에 대해서만 잠깐 살펴 보겠습니다.
앞에서 보셨다시피 Saved Queries를 누르면, 질의 시 저장했던 질의문을 모두 보실 수 있습니다.
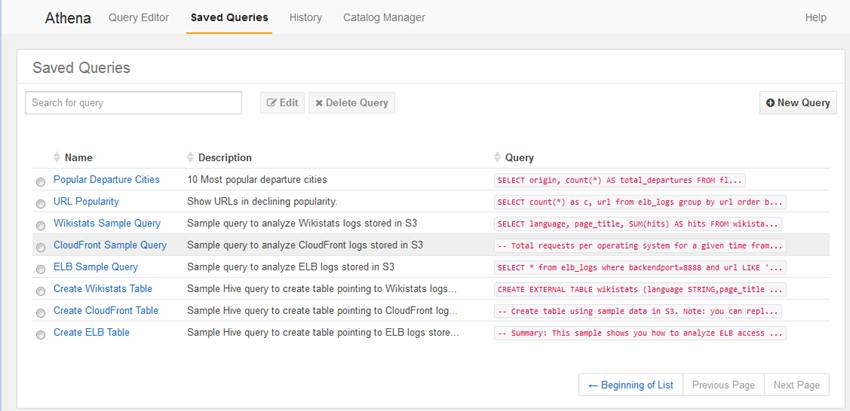
그대로 사용할 수도 있고, 편집해서 다시 질의할 수도 있습니다.
History를 누르면, 이전 질의 기록 뿐만 아니라 생성된 데이터 다운로드도 가능합니다.
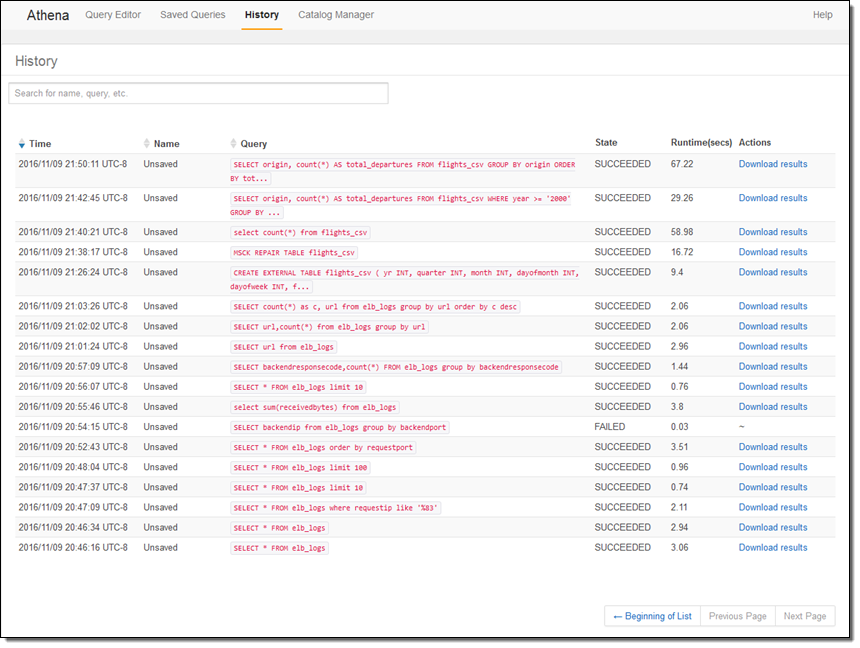
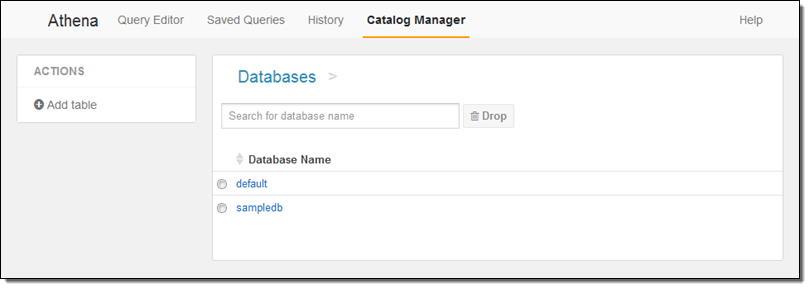
Catalog Manager에서는 기존 데이터베이스 및 신규 데이테베이스 및 테이블 생성이 가능합니다.
이 블로그 글에서 주로 화면으로 보이는 동적 기능 측면만 언급했지만, JDBC나 ODBC 커넥터를 통해 여러분이 지금 사용중인 비지니스 인텔리전스 분석 도구와 결합할 수 있다는 점을 염두해 주시기 바랍니다.
정식 출시
Amazon Athena는 US East (Northern Virginia), US West (Oregon), EU (Ireland)에 오늘 정식 출시합니다. (다른 AWS 리전에 대해서는 가능한 빠르게 출시가 가능하도록 지속적으로 확대해 나갈 예정입니다.)
— Jeff;
이 글은 AWS re:Invent 2016 신규 출시 소식으로 Amazon Athena – Interactively Query Petabytes of Data in Seconds의 한국어 번역입니다. re:Invent 출시 소식에 대한 자세한 정보는 12월 온라인 세미나를 참고하시기 바랍니다.