Amazon Web Services 한국 블로그
Amazon Timestream – 시계열 데이터 베이스 서비스 정식 출시
시계열은 매우 일반적인 데이터 형식 중 하나로서, 시간이 지남에 따라 상황이 어떻게 변하는지 확인 가능합니다. 일반적으로 산업용 기계 및 IoT 디바이스, IT 인프라 스택(하드웨어, 소프트웨어 및 네트워킹 구성 요소 등), 시간에 따른 결과를 공유하는 애플리케이션 등이 있습니다. 데이터 모델이 범용 데이터베이스에 적합하지 않기 때문에 시계열 데이터를 효율적으로 관리하는 것은 쉽지 않습니다.
이러한 요구 사항에 맞는 Amazon Timestream을 오늘 정식 출시합니다. Timestream은 빠르고 확장 가능한 서버리스 시계열 데이터베이스 서비스로, 매일 수조 개의 시계열 이벤트를 손쉽게 수집 및 저장하고 관계형 데이터베이스 비용의 1/10 수준의 비용으로 1,000배 더 빠르게 처리할 수 있습니다.
이것이 가능한 이유는 Timestream이 데이터를 관리하는 방식, 즉 최근 데이터는 메모리에 보관되고 기록 데이터는 사용자가 정의한 보존 정책에 따라 비용 최적화된 스토리지로 이동되는 방식에 있습니다. 모든 데이터는 항상 동일한 AWS 리전의 여러 AZ(가용 영역) 에 자동으로 복제됩니다. 새 데이터는 메모리 저장소에 기록되며, 여기서 데이터는 작업 성공을 반환하기 전에 세 개의 AZ에 복제됩니다. 데이터 복제는 쿼럼 기반이므로 노드 또는 전체 AZ가 손실되어도 내구성이나 가용성이 저하되지 않습니다. 또한 추가 예방 조치로 메모리 저장소의 데이터는 Amazon Simple Storage Service(S3)에 지속적으로 백업됩니다.
쿼리는 스토리지 위치를 지정하지 않아도 여러 티어의 최근 데이터와 기록 데이터를 자동으로 액세스하고 결합하며, 시계열 관련 기능을 지원하여 거의 실시간으로 데이터의 추세와 패턴을 식별하는 데 도움이 됩니다.
선결제 비용은 없으며 작성, 저장 또는 쿼리하는 데이터에 대해서만 지불합니다. 기본 인프라를 관리하지 않아도 부하에 따라 Timestream이 용량 조정을 위해 자동으로 확장 또는 축소됩니다.
Timestream은 널리 사용되는 데이터 수집, 시각화 및 기계 학습 서비스와 통합되므로 기존 애플리케이션과 새 애플리케이션 모두에서 쉽게 사용할 수 있습니다. 예를 들어 AWS IoT Core, Amazon Kinesis Data Analytics for Apache Flink, AWS IoT Greengrass 및 Amazon MSK에서 직접 데이터를 수집할 수 있습니다. Amazon QuickSight에서 Timestream에 저장된 데이터를 시각화하고, 이상 탐지 등을 위해 Amazon SageMaker를 사용하여 기계 학습 알고리즘을 시계열 데이터에 적용할 수 있습니다. Timestream 세분화된 AWS Identity and Access Management(IAM) 권한을 사용하여 AWS Lambda 함수에서 데이터를 쉽게 수집하거나 쿼리할 수 있습니다. AWS에서는 Apache Kafka, Telegraf, Prometheus 및 Grafana 같은 오픈 소스 플랫폼으로 Timestream을 사용할 수 있는 도구를 제공하고 있습니다.
Amazon Timestream 사용해 보기
Timestream 콘솔에서 데이터베이스 생성(Create database)을 선택합니다. 표준 데이터베이스(Standard database) 또는 샘플 데이터로 채워진 샘플 데이터베이스(Sample database)를 선택할 수 있습니다. 여기에서는 표준 데이터베이스를 선택하고 이름을 MyDatabase로 지정하겠습니다.

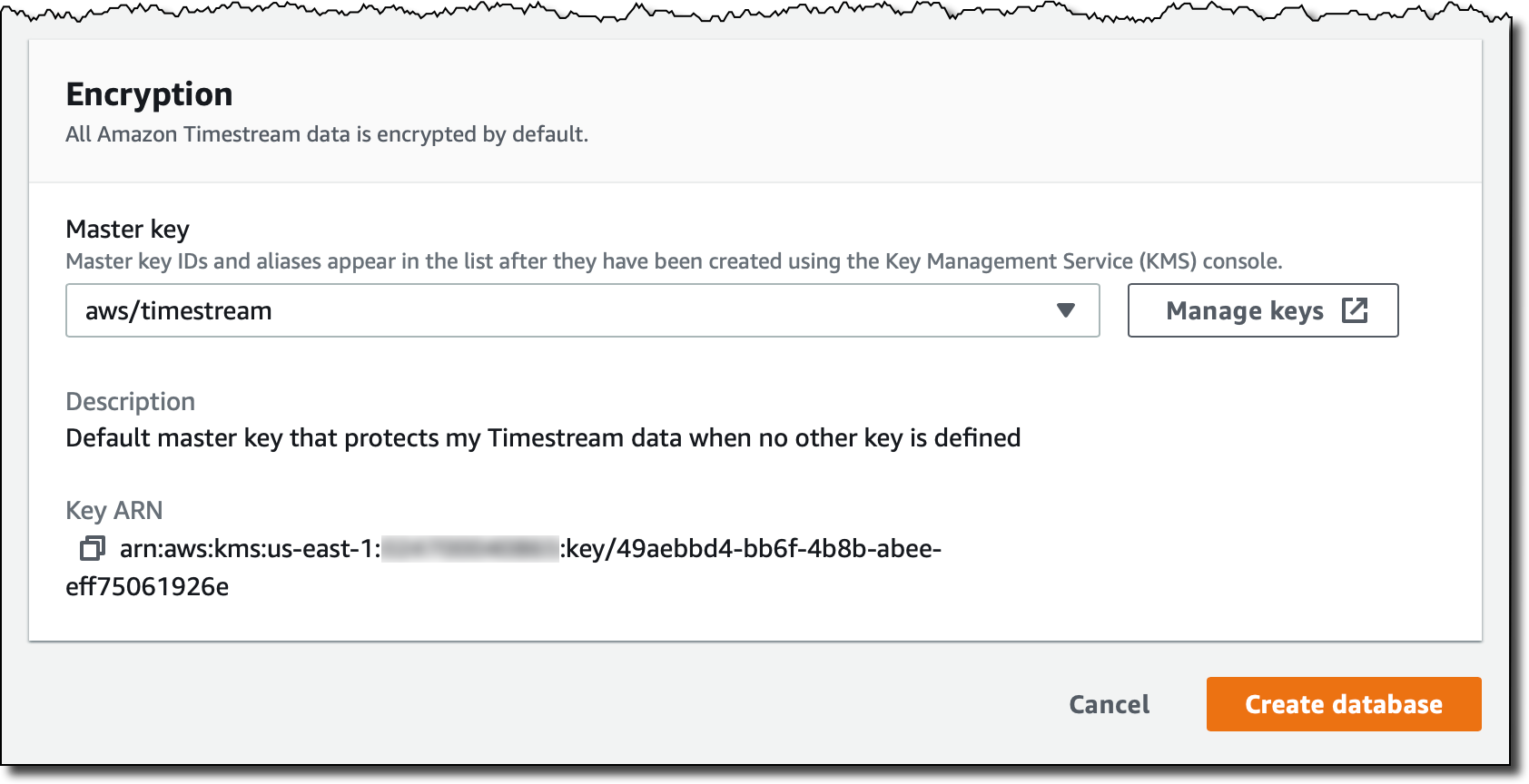
모든 Timestream 데이터는 기본적으로 암호화(encrypted)되어 있습니다. 여기에서는 기본 마스터 키를 사용하지만 AWS Key Management Service(KMS)를 사용하여 생성한 고객 관리형 키를 사용할 수도 있습니다. 이렇게 하면 마스터 키의 교체를 제어할 수 있으며 누가 마스터 키를 사용하거나 관리할 수 있는 권한이 있는지 제어할 수 있습니다.
데이터베이스 생성을 완료했습니다. 지금은 데이터베이스가 비어 있습니다. 테이블 생성(Create table)을 선택하고 이름을 MyTable로 지정합니다.

각 테이블에는 고유한 데이터 보존 정책이 있습니다. 첫 번째 데이터는 메모리 저장소(memory store)에 수집됩니다. 데이터는 이 저장소에서 최소 1시간에서 최대 1년까지 저장될 수 있습니다. 그 후, 데이터는 자동으로 자기 저장소(magnetic store)로 옮겨집니다. 데이터는 이 저장소에서 최소 하루에서 최대 200년까지 유지될 수 있으며 그 후에 삭제됩니다. 여기에서는 메모리 저장소 보존 1시간과 자기 저장소 보존 5년을 선택하겠습니다.

Timestream에 데이터를 쓸 때에는 메모리 저장소의 보존 기간보다 오래된 데이터를 삽입할 수 없습니다. 예를 들어, 여기에서는 1시간 이상된 레코드를 삽입할 수 없습니다. 마찬가지로, 미래의 타임스탬프를 가진 데이터도 삽입할 수 없습니다.
이제 테이블을 생성합니다. 보시는 바와 같이 데이터 스키마를 묻는 메시지가 표시되지 않았습니다. Timestream은 데이터를 수집할 때 자동으로 이를 추론합니다. 이제 테이블에 데이터를 넣어보겠습니다!
Amazon Timestream에 데이터 로드
Timestream 테이블의 각 레코드는 시계열의 단일 데이터 포인트이며 다음을 포함합니다.
- 측정 이름(measure name), 유형(type) 및 값(value). 각 레코드는 단일 측정이 포함될 수 있지만 동일한 테이블에 서로 다른 측정 이름과 유형을 저장할 수 있습니다.
- 측정 값이 수집된 시간의 타임스탬프(timestamp)(나노초 단위).
- 측정을 설명하고 데이터를 필터링하거나 집계하는 데 사용할 수 있는 0개 이상의 차원(dimensions). 테이블의 레코드는 서로 다른 차원을 가질 수 있습니다.
예를 들어 서버에서 CPU, 메모리, 스왑 및 디스크 사용률을 수집하는 간단한 모니터링 애플리케이션을 구축해 보겠습니다. 각 서버는 호스트 이름으로 식별되며 국가 및 도시로 표시된 위치를 가집니다.
이 경우 차원은 모든 레코드에 대해 동일합니다.
countrycityhostname
테이블의 레코드는 다른 대상을 측정할 것입니다. 여기에서는 다음과 같은 측정 이름을 사용하겠습니다.
cpu_utilizationmemory_utilizationswap_utilizationdisk_utilization
측정 유형은 모두 DOUBLE입니다.
모니터링 애플리케이션은 Python을 사용하겠습니다. 모니터링 정보를 수집하는 데에는 다음 명령을 통해 설치할 수 있는 psutil 모듈을 사용합니다.
다음은 collect.py 애플리케이션의 코드입니다.
import time
import boto3
import psutil
from botocore.config import Config
DATABASE_NAME = "MyDatabase"
TABLE_NAME = "MyTable"
COUNTRY = "UK"
CITY = "London"
HOSTNAME = "MyHostname" # socket.gethostname()을 사용하여 동적으로 만들 수 있습니다.
INTERVAL = 1 # Seconds
def prepare_record(measure_name, measure_value):
record = {
'Time': str(current_time),
'Dimensions': dimensions,
'MeasureName': measure_name,
'MeasureValue': str(measure_value),
'MeasureValueType': 'DOUBLE'
}
return record
def write_records(records):
try:
result = write_client.write_records(DatabaseName=DATABASE_NAME,
TableName=TABLE_NAME,
Records=records,
CommonAttributes={})
status = result['ResponseMetadata']['HTTPStatusCode']
print("Processed %d records. WriteRecords Status: %s" %
(len(records), status))
except Exception as err:
print("Error:", err)
if __name__ == '__main__':
session = boto3.Session()
write_client = session.client('timestream-write', config=Config(
read_timeout=20, max_pool_connections=5000, retries={'max_attempts': 10}))
query_client = session.client('timestream-query')
dimensions = [
{'Name': 'country', 'Value': COUNTRY},
{'Name': 'city', 'Value': CITY},
{'Name': 'hostname', 'Value': HOSTNAME},
]
records = []
while True:
current_time = int(time.time() * 1000)
cpu_utilization = psutil.cpu_percent()
memory_utilization = psutil.virtual_memory().percent
swap_utilization = psutil.swap_memory().percent
disk_utilization = psutil.disk_usage('/').percent
records.append(prepare_record('cpu_utilization', cpu_utilization))
records.append(prepare_record(
'memory_utilization', memory_utilization))
records.append(prepare_record('swap_utilization', swap_utilization))
records.append(prepare_record('disk_utilization', disk_utilization))
print("records {} - cpu {} - memory {} - swap {} - disk {}".format(
len(records), cpu_utilization, memory_utilization,
swap_utilization, disk_utilization))
if len(records) == 100:
write_records(records)
records = []
time.sleep(INTERVAL)collect.py 응용 프로그램을 시작하겠습니다. 100개의 레코드마다 MyData 테이블에 데이터가 기록됩니다.
이제 Timestream 콘솔에는 수집된 데이터를 기반으로 자동으로 업데이트되는 MyData 테이블의 스키마가 표시됩니다.
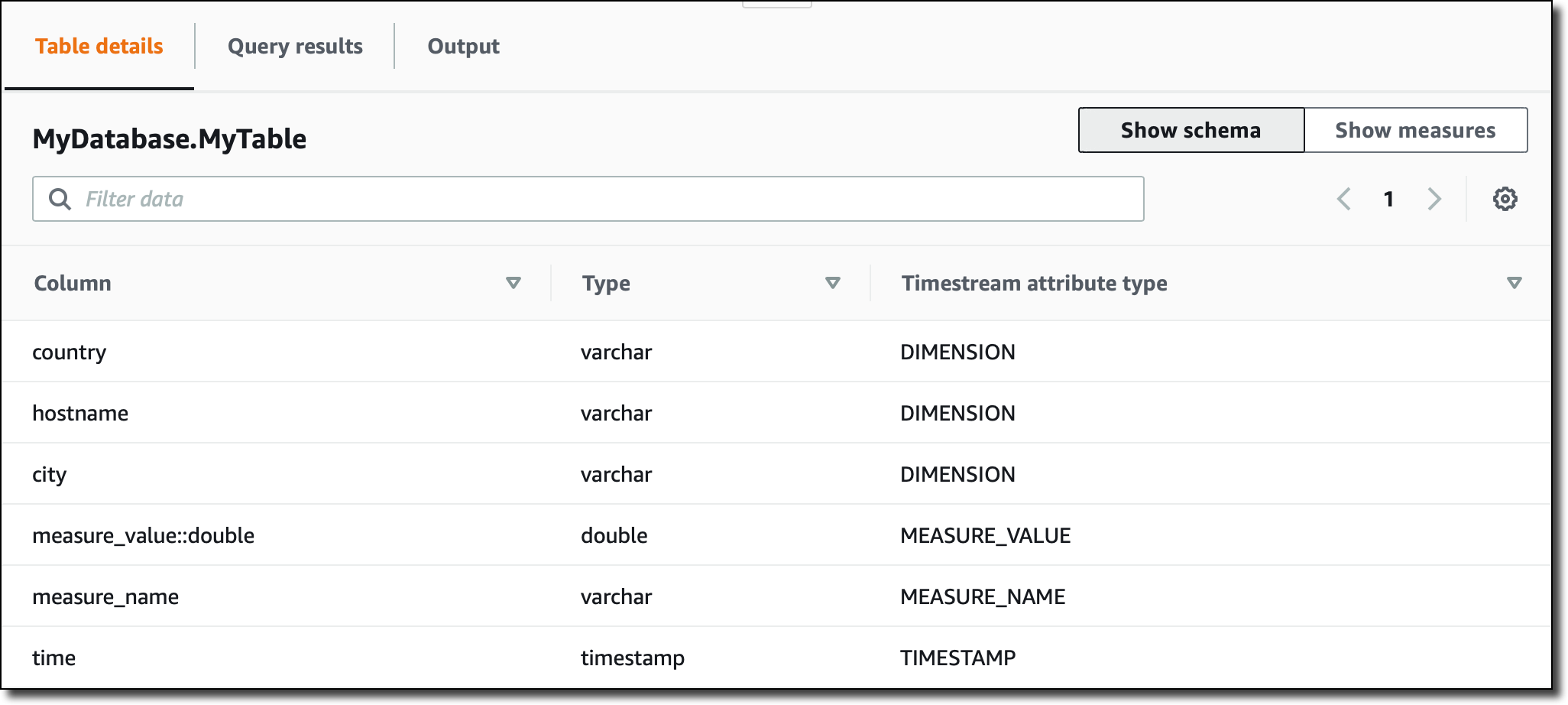
테이블의 모든 측정은 DOUBLE 유형이므로 measure_value::double 열에는 모든 측정에 대한 값이 포함됩니다. 측정이 다른 유형(예: INT 또는 BIGINT)인 경우 더 많은 열(예: measure_value::int 및 measure_value::bigint)이 표시될 것입니다.
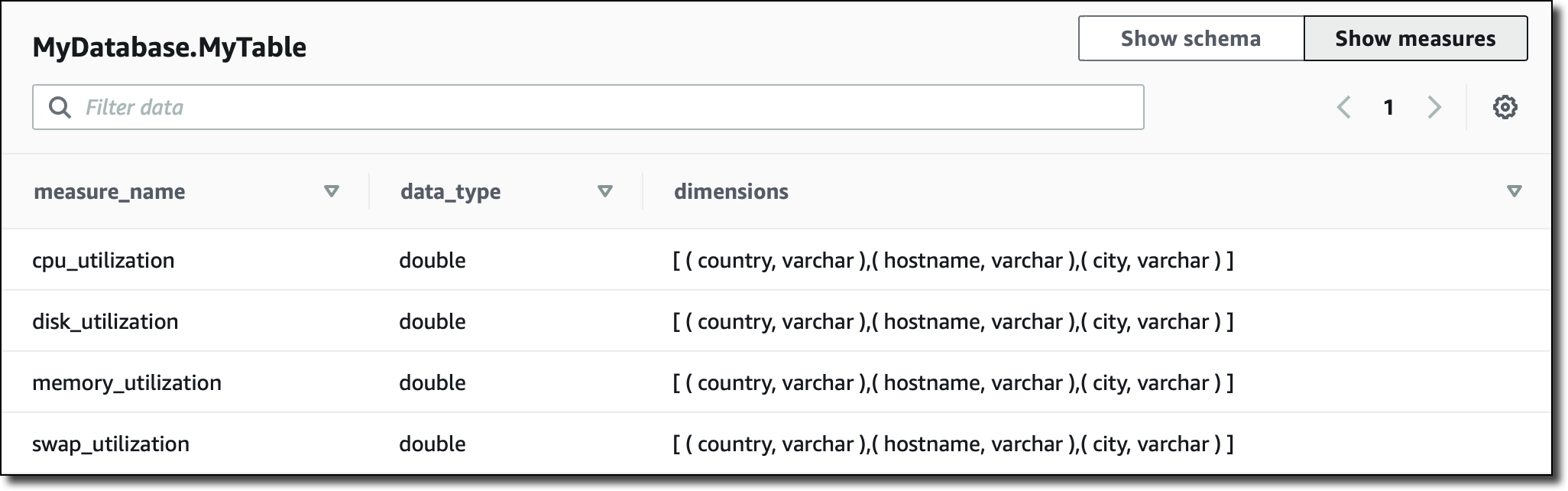
콘솔에서는 테이블에 있는 측정, 해당 데이터 유형 및 해당 측정에 사용된 차원에 대한 요약 정보도 볼 수 있습니다.
콘솔에서 데이터 쿼리
SQL을 사용하면 시계열 데이터를 쿼리할 수 있습니다. 메모리 저장소는 빠른 시점 쿼리에 최적화되어 있으며 자기 저장소는 빠른 분석 쿼리에 최적화되어 있습니다. 그러나 쿼리에 데이터 위치를 지정하지 않아도 쿼리는 모든 저장소(메모리 및 자기)의 데이터를 자동으로 처리합니다.
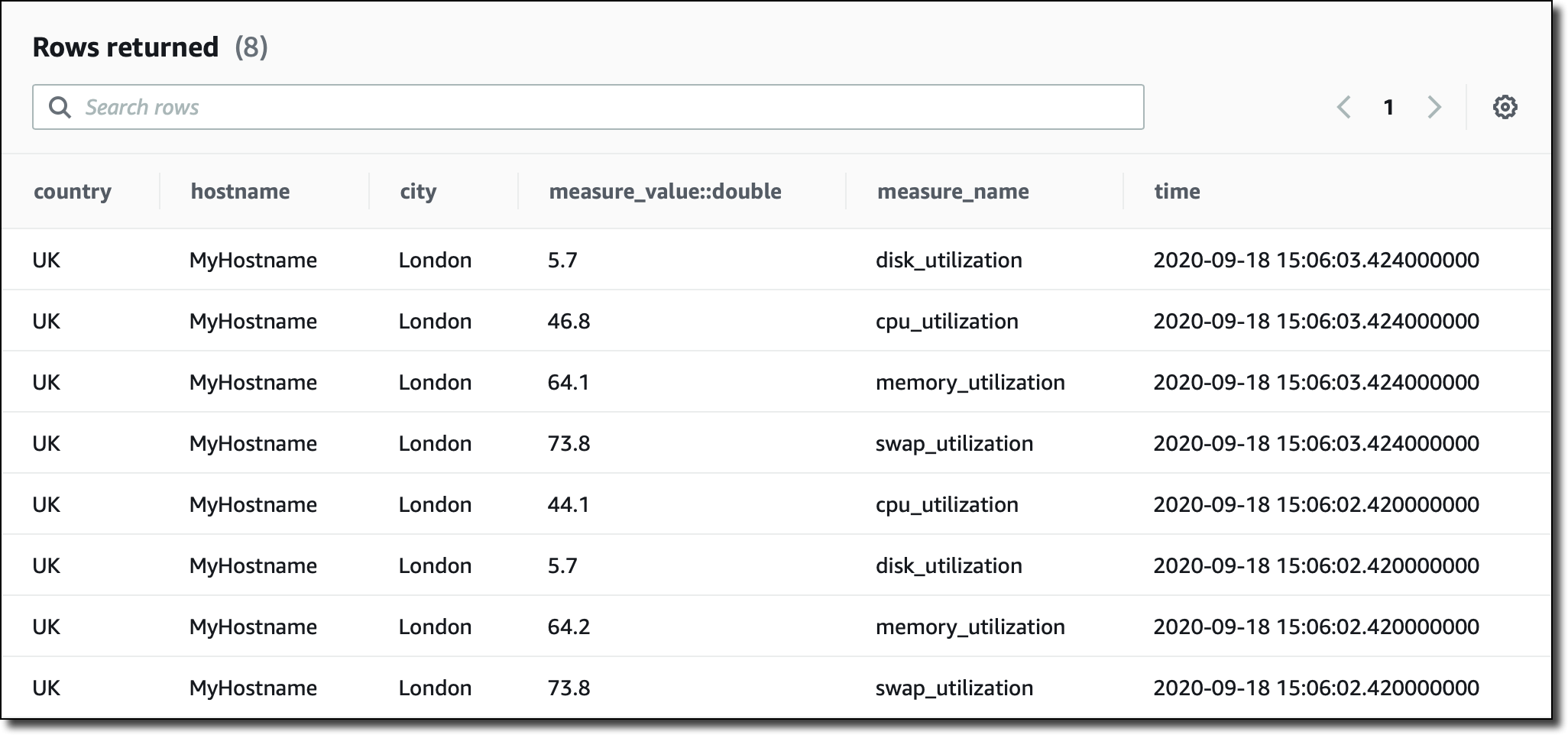
여기에서는 콘솔에서 직접 쿼리를 실행하지만 JDBC 연결을 사용하여 쿼리 엔진에 액세스할 수도 있습니다. 테이블에서 가장 최근 레코드를 보는 기본 쿼리로 시작하겠습니다.
조금 더 복잡한 것을 시도해 보겠습니다. 지난 2시간 동안 5분 간격으로 집계된 평균 CPU 사용률을 호스트 이름별로 확인하고 싶습니다. measure_name의 내용을 기반으로 레코드를 필터링합니다. bin() 함수를 사용하여 간격 크기의 배수로 시간을 반올림하고 함수 ago()를 사용하여 타임스탬프를 비교합니다.
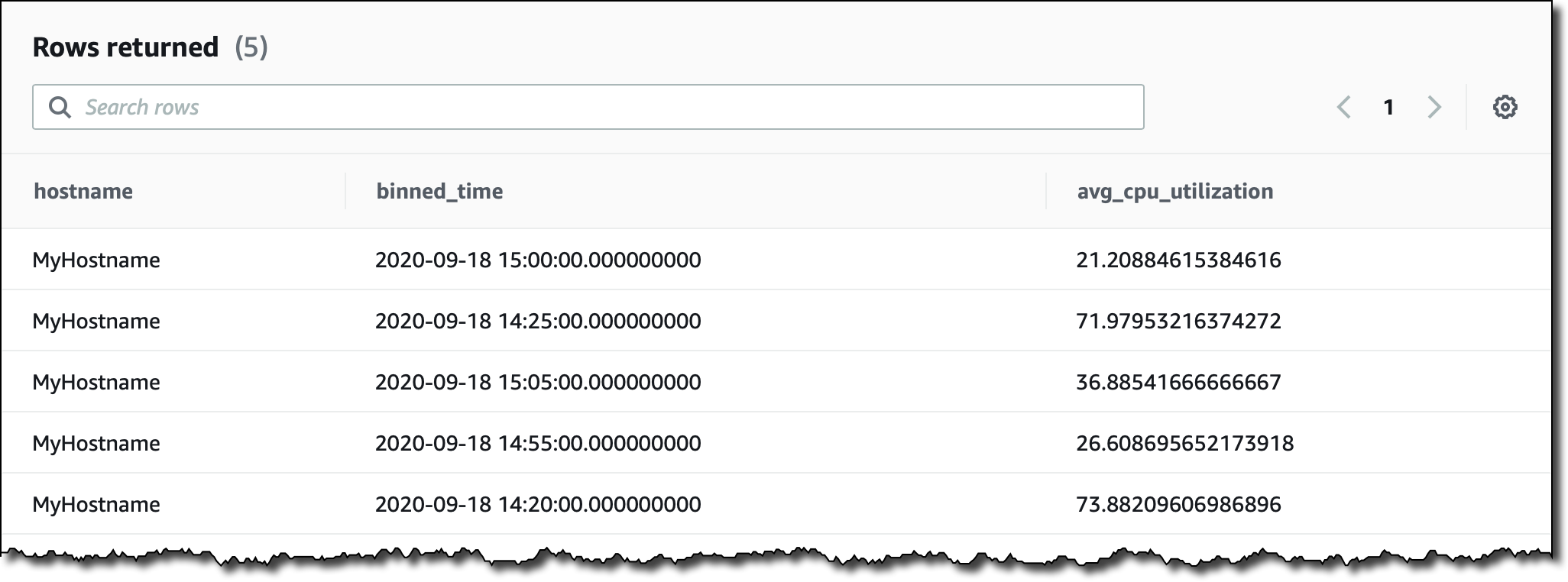
시계열 데이터를 수집할 때 일부 값을 놓칠 수 있습니다. 이것은 특히 분산 아키텍처 및 IoT 디바이스에서 매우 일반적으로 발생합니다. Timestream에는 선형 보간(interpolation)을 사용하거나 앞으로 전달된 마지막 관측을 사용하는 등 누락된 값을 채우는 데 사용할 수 있는 몇 가지 흥미로운 함수가 있습니다.
그 외에도 Timestream은 수학 표현식을 사용하고, 문자열, 배열 및 날짜/시간 값을 조작하고, 정규 표현식을 사용하고, 집계/기간을 사용하는 데 도움이 되는 많은 함수를 제공합니다.
Timestream으로 수행할 수 있는 작업을 경험하려면 샘플 데이터베이스(sample database)를 만들고 AWS에서 제공하는 두 개의 IoT 및 DevOps 데이터 세트를 추가할 수 있습니다. 그런 다음 콘솔 쿼리 인터페이스의 샘플 쿼리(sample queries)에서 고급 기능 중 일부를 엿볼 수 있습니다.

Grafana와 함께 Amazon Timestream 사용
Timestream의 가장 흥미로운 측면 중 하나는 여러 플랫폼과의 통합입니다. 예를 들어 Grafana 7.1 이상을 사용하여 시계열 데이터를 시각화하고 경고를 생성할 수 있습니다. Timestream 플러그인은 Grafana 오픈 소스 에디션의 일부입니다.
데이터베이스에 새 GrafanaDemo 테이블을 추가하고 또 다른 샘플 애플리케이션을 사용하여 데이터를 지속적으로 수집합니다. 이 애플리케이션은 수천 개의 호스트에서 실행되는 마이크로서비스 아키텍처에서 수집된 성능 데이터를 시뮬레이션합니다.
Amazon Elastic Compute Cloud(EC2) 인스턴스에 Grafana를 설치하고 Grafana CLI를 사용하여 Timestream 플러그인을 추가합니다.
SSH 포트 포워딩을 사용하여 랩톱에서 Grafana 콘솔에 액세스합니다.
Grafana 콘솔에서 올바른 AWS 자격 증명과 Timestream 데이터베이스 및 테이블로 플러그인을 구성합니다. 이제 성능 데이터가 지속적으로 수집되는 GrafanaDemo 테이블의 데이터를 사용하여 Timestream 플러그인의 일부로 배포되는 샘플 대시보드를 선택할 수 있습니다.

정식 출시
Amazon Timestream는 미국 동부(버지니아 북부), 유럽(아일랜드), 미국 서부(오레곤) 및 미국 동부(오하이오)에서 지금 사용할 수 있습니다. Timestream은 콘솔, AWS CLI(명령줄 인터페이스), AWS SDK 및 AWS CloudFormation과 함께 사용할 수 있습니다. Timestream에서는 쓰기 횟수, 쿼리로 스캔한 데이터 및 사용된 스토리지를 기준으로 비용을 지불합니다. 자세한 내용은 요금 페이지를 참조하십시오.
Github 리포지토리에서 더 많은 샘플 애플리케이션을 찾을 수 있습니다. 더 자세히 알아보려면 설명서를 참조하세요. 데이터 수집, 보존, 액세스 및 스토리지 계층화를 비롯한 시계열 작업이 그 어느 때보다 쉬워졌습니다. 앞으로 이 서비스를 통해 무엇을 구축할지에 대한 계획을 공유해주세요!
— Danilo