AWS Big Data Blog
Extract Oracle OLTP data in real time with GoldenGate and query from Amazon Athena
This post describes how you can improve performance and reduce costs by offloading reporting workloads from an online transaction processing (OLTP) database to Amazon Athena and Amazon S3. The architecture described allows you to implement a reporting system and have an understanding of the data that you receive by being able to query it on arrival. In this solution:
- Oracle GoldenGate generates a new row on the target for every change on the source to create Slowly Changing Dimension Type 2 (SCD Type 2) data.
- Athena allows you to run ad hoc queries on the SCD Type 2 data.
Principles of a modern reporting solution
Advanced database solutions use a set of principles to help them build cost-effective reporting solutions. Some of these principles are:
- Separate the reporting activity from the OLTP. This approach provides resource isolation and enables databases to scale for their respective workloads.
- Use query engines running on top of distributed file systems like Hadoop Distributed File System (HDFS) and cloud object stores, such as Amazon S3. The advent of query engines that can run on top of open-source HDFS and cloud object stores further reduces the cost of implementing dedicated reporting systems.
Furthermore, you can use these principles when building reporting solutions:
- To reduce licensing costs of the commercial databases, move the reporting activity to an open-source database.
- Use a log-based, real-time, change data capture (CDC), data-integration solution, which can replicate OLTP data from source systems, preferably in real-time mode, and provide a current view of the data. You can enable the data replication between the source and the target reporting systems using database CDC solutions. The transaction log-based CDC solutions capture database changes noninvasively from the source database and replicate them to the target datastore or file systems.
Prerequisites
If you use GoldenGate with Kafka and are considering cloud migration, you can benefit from this post. This post also assumes prior knowledge of GoldenGate and does not detail steps to install and configure GoldenGate. Knowledge of Java and Maven is also assumed. Ensure that a VPC with three subnets is available for manual deployment.
Understanding the architecture of this solution
The following workflow diagram (Figure 1) illustrates the solution that this post describes:
- Amazon RDS for Oracle acts as the source.
- A GoldenGate CDC solution produces data for Amazon Managed Streaming for Apache Kafka (Amazon MSK). GoldenGate streams the database CDC data to the consumer. Kafka topics with an MSK cluster receives the data from GoldenGate.
- The Apache Flink application running on Amazon EMR consumes the data and sinks it into an S3 bucket.
- Athena analyzes the data through queries. You can optionally run queries from Amazon Redshift Spectrum.
Data Pipeline

Figure 1
Amazon MSK is a fully managed service for Apache Kafka that makes it easy to provision Kafka clusters with few clicks without the need to provision servers, storage and configuring Apache Zookeeper manually. Kafka is an open-source platform for building real-time streaming data pipelines and applications.
Amazon RDS for Oracle is a fully managed database that frees up your time to focus on application development. It manages time-consuming database administration tasks, including provisioning, backups, software patching, monitoring, and hardware scaling.
GoldenGate is a real-time, log-based, heterogeneous database CDC solution. GoldenGate supports data replication from any supported database to various target databases or big data platforms like Kafka. GoldenGate’s ability to write the transactional data captured from the source in different formats, including delimited text, JSON, and Avro, enables seamless integration with a variety of BI tools. Each row has additional metadata columns including database operation type (Insert/Update/Delete).
Flink is an open-source, stream-processing framework with a distributed streaming dataflow engine for stateful computations over unbounded and bounded data streams. EMR supports Flink, letting you create managed clusters from the AWS Management Console. Flink also supports exactly-once semantics with the checkpointing feature, which is vital to ensure data accuracy when processing database CDC data. You can also use Flink to transform the streaming data row by row or in batches using windowing capabilities.
S3 is an object storage service with high scalability, data availability, security, and performance. You can run big data analytics across your S3 objects with AWS query-in-place services like Athena.
Athena is a serverless query service that makes it easy to query and analyze data in S3. With Athena and S3 as a data source, you define the schema and start querying using standard SQL. There’s no need for complex ETL jobs to prepare your data for analysis, which makes it easy for anyone familiar with SQL skills to analyze large-scale datasets quickly.
The following diagram shows a more detailed view of the data pipeline:
- RDS for Oracle runs in a Single-AZ.
- GoldenGate runs on an Amazon EC2 instance.
- The MSK cluster spans across three Availability Zones.
- Kafka topic is set up in MSK.
- Flink runs on an EMR Cluster.
- Producer Security Group for Oracle DB and GoldenGate instance.
- Consumer Security Group for EMR with Flink.
- Gateway endpoint for S3 private access.
- NAT Gateway to download software components on GoldenGate instance.
- S3 bucket and Athena.
For simplicity, this setup uses a single VPC with multiple subnets to deploy resources.
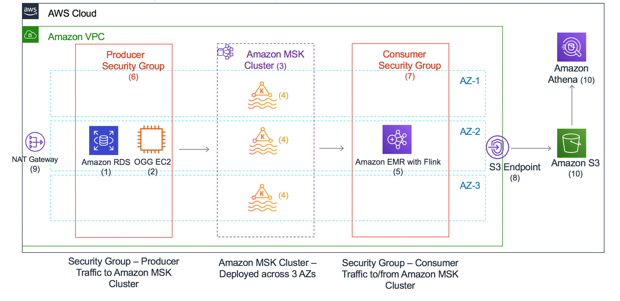
Figure 2
Configuring single-click deployment using AWS CloudFormation
The AWS CloudFormation template included in this post automates the deployment of the end-to-end solution that this blog post describes. The template provisions all required resources including RDS for Oracle, MSK, EMR, S3 bucket, and also adds an EMR step with a JAR file to consume messages from Kafka topic on MSK. Here’s the list of steps to launch the template and test the solution:
- Launch the AWS CloudFormation template in the us-east-1

- After successful stack creation, obtain GoldenGate Hub Server public IP from the Outputs tab of cloudformation.
- Login to GoldenGate hub server using the IP address from step 2 as ec2-user and then switch to oracle user.
sudo su – oracle - Connect to the source RDS for Oracle database using the sqlplus client and provide password(source).
[oracle@ip-10-0-1-170 ~]$ sqlplus source@prod - Generate database transactions using SQL statements available in oracle user’s home directory.
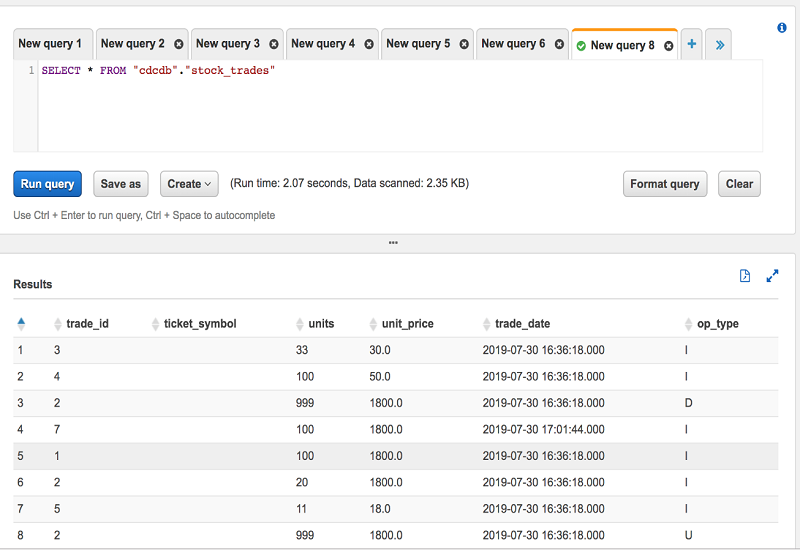
- Query STOCK_TRADES table from Amazon Athena console. It takes a few seconds after committing transactions on the source database for database changes to be available for Athena for querying.
Manually deploying components
The following steps describe the configurations required to stream Oracle-changed data to MSK and sink it to an S3 bucket using Flink running on EMR. You can then query the S3 bucket using Athena. If you deployed the solution using AWS CloudFormation as described in the previous step, skip to the Testing the solution section.
- Prepare an RDS source database for CDC using GoldenGate.The RDS source database version is Enterprise Edition 12.1.0.2.14. For instructions on configuring the RDS database, see Using Oracle GoldenGate with Amazon RDS. This post does not consider capturing data definition language (DDL).
- Configure an EC2 instance for the GoldenGate hub server.Configure the GoldenGate hub server using Oracle Linux server 7.6 (ami-b9c38ad3) image in the us-east-1 Region. The GoldenGate hub server runs the GoldenGate extract process that extracts changes in real time from the database transaction log files. The server also runs a replicat process that publishes database changes to MSK.The GoldenGate hub server requires the following software components:
- Java JDK 1.8.0 (required for GoldenGate big data adapter).
- GoldenGate for Oracle (12.3.0.1.4) and GoldenGate for big data adapter (12.3.0.1).
- Kafka 1.1.1 binaries (required for GoldenGate big data adapter classpath).
- An IAM role attached to the GoldenGate hub server to allow access to the MSK cluster for GoldenGate processes running on the hub server.Use the GoldenGate (12.3.0) documentation to install and configure the GoldenGate for Oracle database. The GoldenGate Integrated Extract parameter file is eora2msk.prm.
The logallsupcols extract parameter ensures that a full database table row is generated for every DML operation on the source, including updates and deletes.
- Create a Kafka cluster using MSK and configure Kakfa topic.You can create the MSK cluster from the AWS Management Console, using the AWS CLI, or through an AWS CloudFormation template.
- Use the list-clusters command to obtain a ClusterArn and a Zookeeper connection string after creating the cluster. You need this information to configure the GoldenGate big data adapter and Flink consumer. The following code illustrates the commands to run:
- Obtain the IP addresses of the Kafka broker nodes by using the ClusterArn.
- Create a Kafka topic. The solution in this post uses the same name as table name for Kafka topic.
- Provision an EMR cluster with Flink.Create an EMR cluster 5.25 with Flink 1.8.0 (advanced option of the EMR cluster), and enable SSH access to the master node. Create and attach a role to the EMR master node so that Flink consumers can access the Kafka topic in the MSK cluster.
- Configure the Oracle GoldenGate big data adapter for Kafka on the GoldenGate hub server.Download and install the Oracle GoldenGate big data adapter (12.3.0.1.0) using the Oracle GoldenGate download link. For more information, see the Oracle GoldenGate 12c (12.3.0.1) installation documentation.The following is the GoldenGate producer property file for Kafka (custom_kafka_producer.properties):
The following is the GoldenGate properties file for Kafka (Kafka.props):
The following is the GoldenGate replicat parameter file (rkafka.prm):
- Create an S3 bucket and directory with a table name underneath for Flink to store (sink) Oracle CDC data.
- Configure a Flink consumer to read from the Kafka topic that writes the CDC data to an S3 bucket.For instructions on setting up a Flink project using the Maven archetype, see Flink Project Build Setup.The following code example is the pom.xml file, used with the Maven project. For more information, see Getting Started with Maven.
Compile the following Java program using mvn clean install and generate the JAR file:
Log in as a Hadoop user to an EMR master node, start Flink, and execute the JAR file:
$ /usr/bin/flink run ./flink-quickstart-java-1.7.0.jar - Create the stock_trades table from the Athena console. Each JSON document must be on a new line.
For more information, see Hive JSON SerDe.
Testing the solution
To test that the solution works, complete the following steps:
- Log in to the source RDS instance from the GoldenGate hub server and perform insert, update, and delete operations on the stock_trades table:
- Monitor the GoldenGate capture from the source database using the following stats command:
- Monitor the GoldenGate replicat to a Kafka topic with the following:
- Query the stock_trades table using the Athena console.
Summary
This post illustrates how you can offload reporting activity to Athena with S3 to reduce reporting costs and improve OLTP performance on the source database. This post serves as a guide for setting up a solution in the staging environment.
Deploying this solution in a production environment may require additional considerations, for example, high availability of GoldenGate hub servers, different file encoding formats for optimal query performance, and security considerations. Additionally, you can achieve similar outcomes using technologies like AWS Database Migration Service instead of GoldenGate for database CDC and Kafka Connect for the S3 sink.
If you have any questions or feedback, please leave a comment.
About the Authors
 Sreekanth Krishnavajjala is a solutions architect at Amazon Web Services.
Sreekanth Krishnavajjala is a solutions architect at Amazon Web Services.
 Vinod Kataria is a senior partner solutions architect at Amazon Web Services.
Vinod Kataria is a senior partner solutions architect at Amazon Web Services.