AWS Database Blog
Category: Amazon DynamoDB
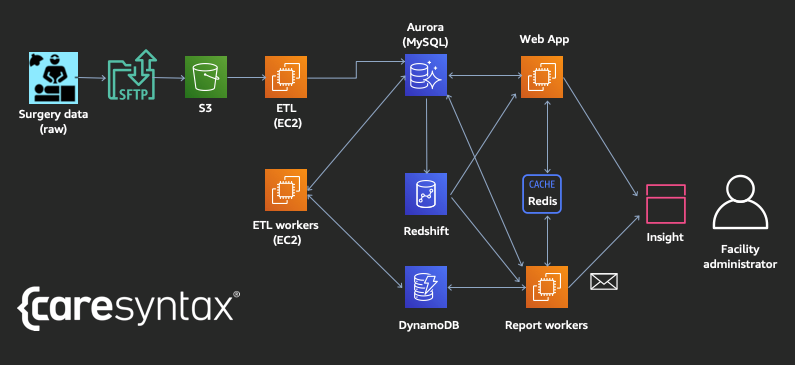
How caresyntax uses managed database services for better surgical outcomes
This is a guest post from Ken Wu, Chief Technology Officer, and Steve Gordon, Director of Engineering at caresyntax. caresyntax provides the needed tools to make surgery smarter and safer. Our solutions use IoT, analytics, and AI technologies to automate clinical and operational decision support for surgical teams and support all outcome contributors. We help […]

Backfilling an Amazon DynamoDB Time to Live (TTL) attribute with Amazon EMR
If you have complex data types such as maps and lists in your Amazon DynamoDB data, refer to Part 2 of this series. Bulk updates to a database can be disruptive and potentially cause downtime, performance impacts to your business processes, or overprovisioning of compute and storage resources. When performing bulk updates, you want to […]

Data modeling with NoSQL Workbench for Amazon DynamoDB
When using a NoSQL database such as Amazon DynamoDB, I tend to make different optimization choices than what I am accustomed to with relational databases. At the beginning, it was not easy for me, because my relational database experience was telling me to do things differently. To help with that, AWS released NoSQL Workbench for […]

Implementing bulk CSV ingestion to Amazon DynamoDB
June 2023: Amazon DynamoDB can now import Amazon S3 data into a new table. DynamoDB import from S3 helps you to bulk import terabytes of data from Amazon S3 into a new DynamoDB table with no code or servers required. November 2022: This post was reviewed and updated for accuracy. This post reviews what solutions […]

Running spiky workloads and optimizing costs by more than 90% using Amazon DynamoDB on-demand capacity mode
November 2024: This post was reviewed and updated for accuracy. This is a guest post by Keisuke Utsumi, a Software Engineer with TVer Technologies Inc. In their own words, “TVer Technologies Inc. offers interactive entertainment services to users using a synchronized website with a TV broadcast.” TVer Technologies Inc. provides website and app-based interactive content […]
Restore Amazon DynamoDB backups to different AWS Regions with custom table settings
Amazon DynamoDB backup and restore provides simple, fully automated features to create continuous and on-demand backups of your DynamoDB tables and then restore data from those backups. With point-in-time recovery (PITR), you can create continuous backups of your DynamoDB table data. DynamoDB can back up your data with per-second granularity to restore to any given second […]
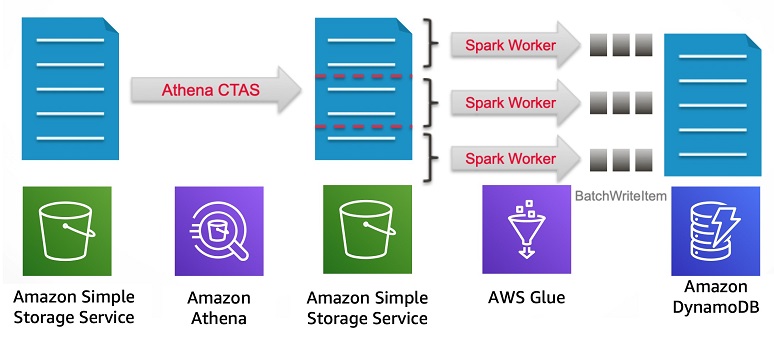
How realtor.com maximized data upload from Amazon S3 into Amazon DynamoDB
This is a customer post by Arup Ray, VP Data Technology at realtor.com, and Daniel Whitehead, AWS Solutions Architect. Arup Ray would like to acknowledge Anil Pillai, Software Development Engineer at Amazon, for his pioneering contributions to this project during his former tenure at realtor.com as Senior Principal Data Engineer. realtor.com , operated by Move, Inc., […]
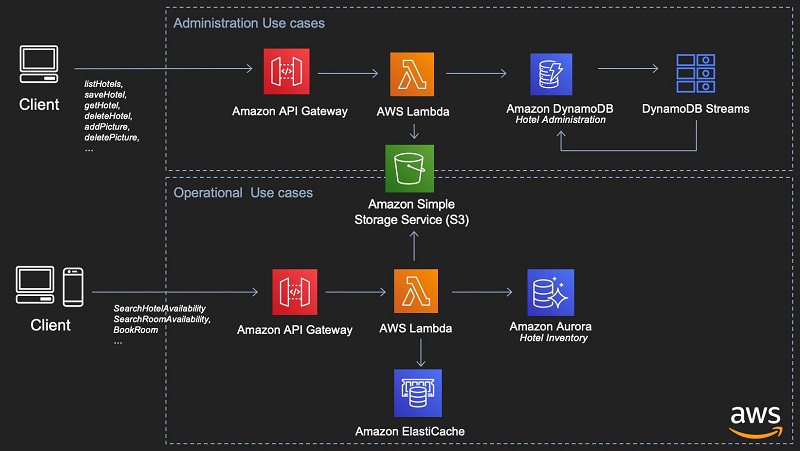
Building enterprise applications using Amazon DynamoDB, AWS Lambda, and Go
Amazon DynamoDB is a fully managed service that delivers single-digit millisecond performance at any scale. It is fully managed, highly available through behind-the-scene Multi-AZ data replication, supports native write-through caching with Amazon DynamoDB Accelerator (DAX) as well as multiple global secondary indexes. Developers can interact with DynamoDB using the AWS SDK in a rich set […]

Make a New Year’s resolution: Follow Amazon DynamoDB best practices
As the new year begins, we encourage you to make a resolution to follow Amazon DynamoDB best practices. Following these best practices can help you maximize performance and minimize throughput costs when working with DynamoDB. Click the following links to learn more about each best practice in the DynamoDB documentation. Design and use partition keys […]

The top 20 most-viewed Amazon DynamoDB documentation pages in 2019
The following 20 pages were the most viewed Amazon DynamoDB documentation pages in 2019. I have included a brief description with each link to explain what each page covers. Use this list to see what other AWS customers have been viewing and perhaps to pique your own interest in a topic you’ve been meaning to explore. […]