AWS Database Blog
Category: Compute

Automating Amazon RDS backup and maintenance windows for Daylight Saving Time shifts
In this post, you’ll learn how to deploy a serverless solution using AWS CloudFormation that automatically adjusts RDS maintenance and backup windows for DST transitions.
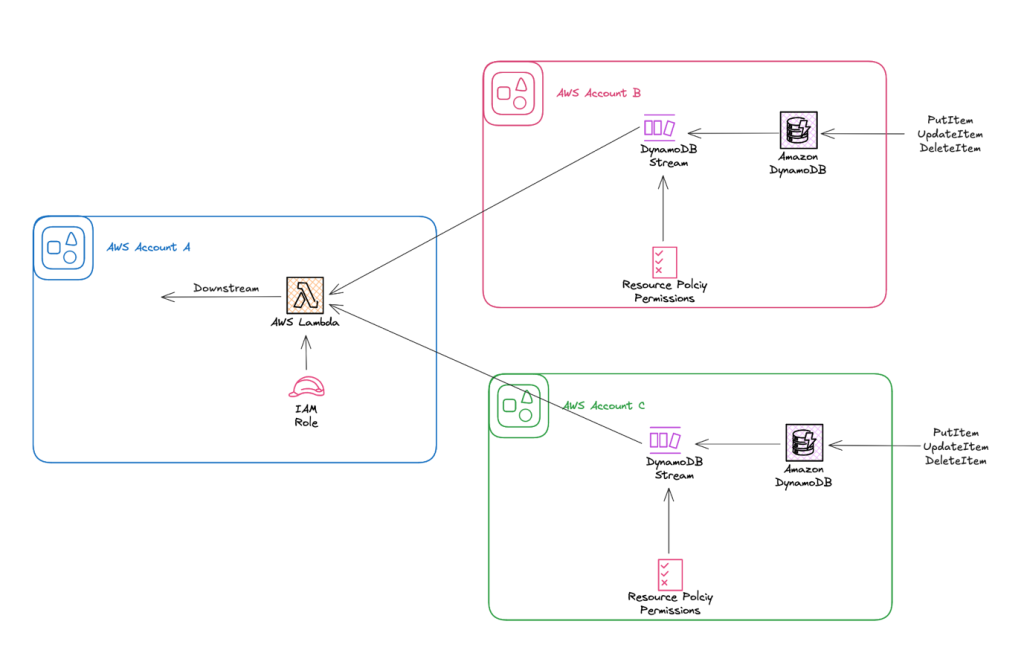
Simplify cross-account stream processing with AWS Lambda and Amazon DynamoDB
In this post, we explore how to use resource-based policies with DynamoDB Streams to enable cross-account Lambda consumption. We focus on a common pattern where application workloads live in isolated accounts, and stream processing happens in a centralized or analytics account.
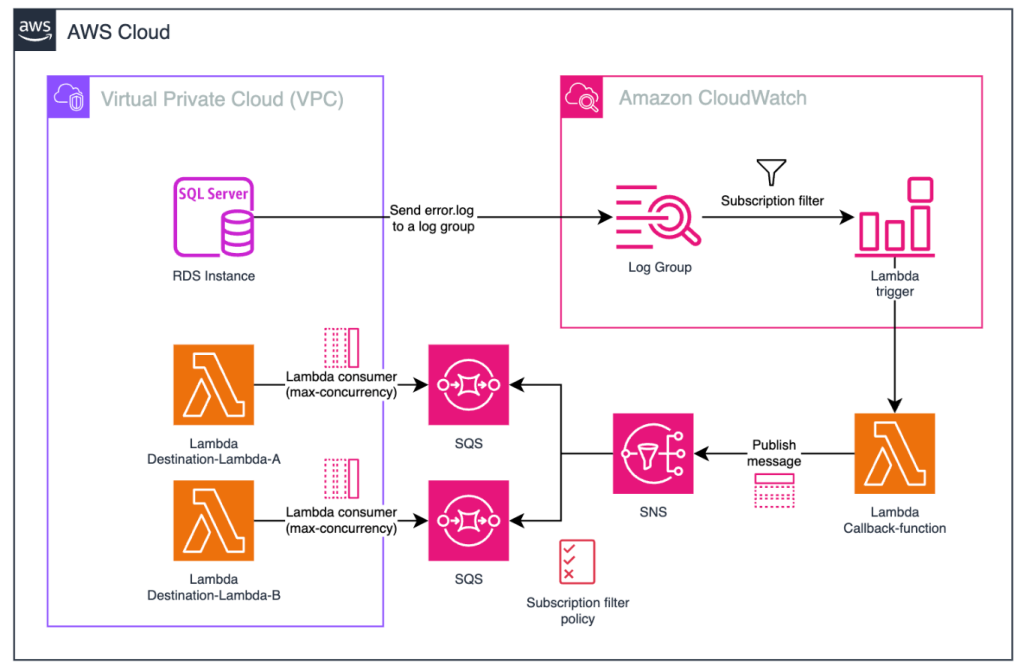
Trigger AWS Lambda functions from Amazon RDS for SQL Server database events
The ability to invoke Lambda functions in response to Amazon RDS for SQL Server database events enables powerful use cases such as triggering automated workflows, sending real-time notifications, calling external APIs, and orchestrating complex business processes. In this post, we demonstrate how to enable this integration by using Amazon CloudWatch subscription filters, Amazon SQS, and Amazon SNS to invoke Lambda functions from RDS for SQL Server stored procedures, helping you build responsive, data-driven applications.

Improve Aurora PostgreSQL throughput by up to 165% and price-performance ratio by up to 120% using Optimized Reads on AWS Graviton4-based R8gd instances
In this post, we demonstrate how your workloads can benefit from upgrading Graviton2-based R6g and R6gd instances to Graviton4-based R8gd instances with Aurora PostgreSQL 17.5 on Aurora I/O-Optimized using an Optimized Reads-enabled tiered cache.

How Omnissa saved millions by migrating to Amazon RDS and Amazon EC2
Omnissa is a digital workspace technology leader that delivers smart, seamless, and secure digital work experiences for organizations worldwide. It serves 26,000 customers, including the top seven of the Fortune 500 companies. In this post, we walk through the Omnissa’s journey of migrating its mission-critical UEM platform and self-managed SQL Server workloads from VMware Cloud on AWS (VMC-A) to Amazon RDS for SQL Server and its application servers to Amazon EC2.

GroundTruth reduces costs by 45% and improves reliability migrating from Aerospike to Amazon ElastiCache for Valkey
GroundTruth, an advertising platform leading the way in location- and behavior-based marketing, empowers brands to connect with consumers through real-world behavioral data to drive real business results. As our advertising platform scaled to process increased volume of ad requests and third-party segment ingestion, maintaining our Aerospike-based caching infrastructure introduced significant operational complexity and rising costs, while also compromising performance and limiting our ability to scale efficiently. To meet our requirements we implemented Amazon ElastiCache for Valkey, which streamlined our operations, improved reliability, and reduced costs. In this post, we walk through our migration journey, covering the migration strategy we adopted, the optimizations we made to reduce cost by 45%, reliability improvements including reducing write failures by 20x, and operational gains from managed service capabilities.

Build a dynamic workflow orchestration engine with Amazon DynamoDB and AWS Lambda
In this post, I show you how to build a serverless workflow orchestration engine that uses Amazon DynamoDB and AWS Lambda. The complete implementation is available in a GitHub repository, which includes two fully functional examples that you can deploy and run immediately to see the orchestration engine in action.

Implement event-driven architectures with Amazon DynamoDB – Part 2
In this three-part series, we explore approaches to implement enhanced event-driven patterns for DynamoDB-backed applications. In this post (Part 2), we explore another method which uses global secondary indexes (GSIs) to handle fine-grained Time to Live (TTL) requirements.

Implement event-driven architectures with Amazon DynamoDB
In this three-part series, we explore approaches to implement enhanced event-driven patterns for DynamoDB-backed applications. In this post (Part 1), we focus on improving DynamoDB’s native TTL functionality by implementing near real-time data eviction using EventBridge Scheduler, reducing the typical time to delete expired items from within a few days to less than one minute.

Getting started with Amazon EC2 bare metal instances for Amazon RDS for Oracle and Amazon RDS Custom for Oracle
In this post, we explore the support for AWS bare metal instances on Amazon EC2 bare metal Instances for Amazon RDS for Oracle and RDS Custom for Oracle.