AWS Database Blog
Best practices for securing sensitive data in AWS data stores
An effective strategy for securing sensitive data in the cloud requires a good understanding of general data security patterns and a clear mapping of these patterns to cloud security controls. You then can apply these controls to implementation-level details specific to data stores such as Amazon Relational Database Service (Amazon RDS) and Amazon DynamoDB.
This blog post focuses on general data security patterns and corresponding AWS security controls that protect your data. While I mention Amazon RDS and DynamoDB in this post, I cover the implementation-specific details related to these services in two subsequent posts, Applying best practices for securing sensitive data in Amazon RDS and Applying best practices for securing sensitive data in Amazon DynamoDB.
The AWS Cloud Adoption Framework
The AWS Cloud Adoption Framework (AWS CAF) provides guidance and best practices to help you build a comprehensive approach to cloud computing across your organization. Within this framework, the Security Perspective of the AWS CAF covers five key capabilities:
- AWS Identity and Access Management (IAM): Define, enforce, and audit user permissions across AWS services, actions, and resources.
- Detective control: Improve your security posture, reduce the risk profile of your environment, and gain the visibility you need to spot issues before they impact your business.
- Infrastructure security: Reduce the surface area of the infrastructure you manage and increase the privacy and control of your overall infrastructure on AWS.
- Data protection: Implement appropriate safeguards that help protect data in transit and at rest by using natively integrated encrypted services.
- Incident response: Define and execute a response to security incidents.as a guide for security planning.
The first step when implementing security based on the Security Perspective of the AWS CAF is to think about security from a data perspective.
Instead of thinking about on-premises and off-premises data security, think about the data you are protecting, how it is stored, and who has access to it. The following three categories help you think about security from a data perspective:
- Data classification and security-zone modeling.
- Defense in depth.
- Swim-lane isolation.
In the rest of this post, I look at each of these categories in detail.
Data classification and security-zone modeling
Data classification
Not all data is created equal, which means classifying data properly is crucial to its security. As part of this classification process, it can be difficult to accommodate the complex tradeoffs between a strict security posture and a flexible agile environment.
A strict security posture, which requires lengthy access-control procedures, creates stronger guarantees about data security. However, such a security posture can work counter to agile and fast-paced development environments, where developers require self-service access to data stores. Design your approach to data classification to meet a broad range of access requirements.
In most cases, how you classify data doesn’t have to be as binary as public or private, so add an appropriate level of fidelity to your data classification model. As you can see in the following diagram, data comes in various degrees of sensitivity and you might have data that falls in all of the different levels of sensitivity and confidentiality. Design your data security controls with an appropriate mix of preventative and detective controls to match data sensitivity appropriately.
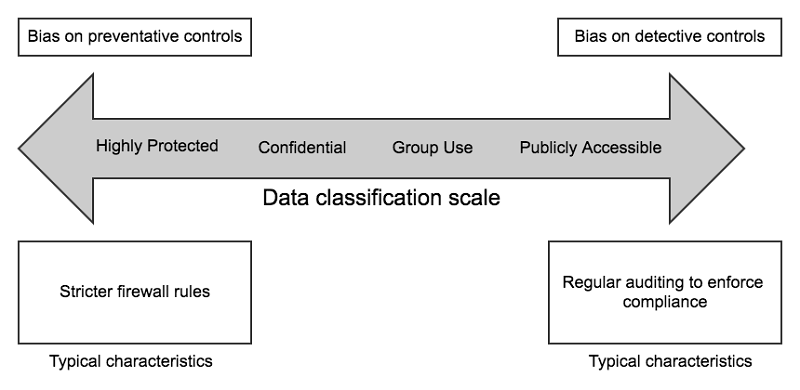
Security-zone modeling
Another perspective on data security is to consider how and from where data can be accessed. A security zone provides a well-defined network perimeter that implements controls to help protect all assets within it. A security zone also enables clarity and ease of reasoning for defining and enforcing network flow control into and out of the security zone based on its characteristics.
For example, all assets that persist sensitive data might be grouped together in a secured zone. You can create a layered network flow control architecture of other security zones that sit on top of the secured zone. An example would include a restricted zone for application-logic assets and an external zone for internet-facing assets. You can define a network flow control policy through AWS network access control lists (ACLs) in combination with a complementary IAM policy. With these, you enforce access to the secured zone only from the restricted zone and never from the internet-facing external zone. This approach places your sensitive data two security layers beneath internet accessibility, as illustrated in the following diagram.
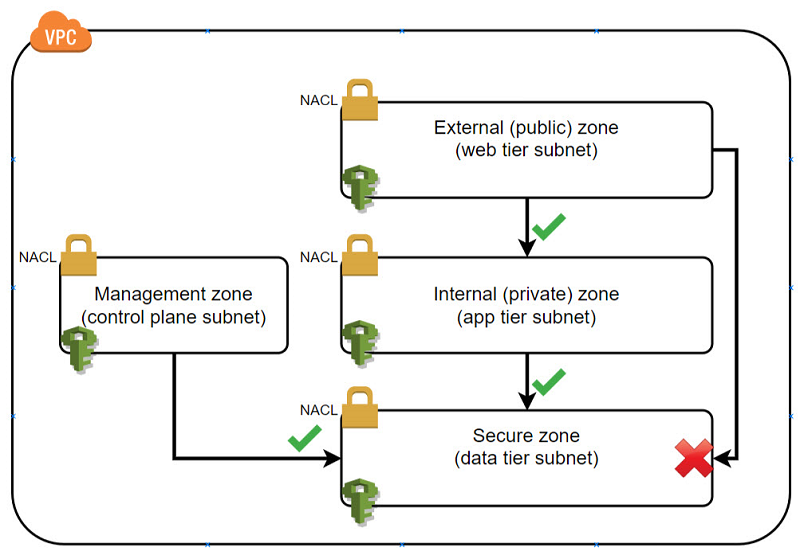
When combined with a data classification model, security-zone modeling can enable data access policies to be multifaceted. Data classification enables you to define appropriate security zones for data. Security zones give you the flexibility to apply the appropriate level of network flow controls and access policy controls to the data.
Defense in depth
The concept of defense in depth refers to layering multiple security controls together in order to provide redundancy in case a single security control fails. You can apply two categories of security controls to your systems to enable defense in depth:
- Preventative: These controls encompass the AWS CAF Security Perspective capabilities of IAM, infrastructure security, and data protection.
- Detective: These controls detect changes to configurations or undesirable actions and enable timely incident response. Detective controls work with preventative controls to provide an overall security posture.
In an effective security posture, you need both preventative and detective security controls because the business and technology landscape is both dynamic and evolutionary.
Preventative controls
You can layer three main categories of preventative controls:
- IAM
- Infrastructure security
- Data protection (encryption and tokenization)
The sequence in which you layer the controls together can depend on your use case. For example, you can apply IAM controls either at the database layer or at the start of user activity—or both. To present a mental model to you, the following illustration shows one way you can layer controls to help secure access to your data.
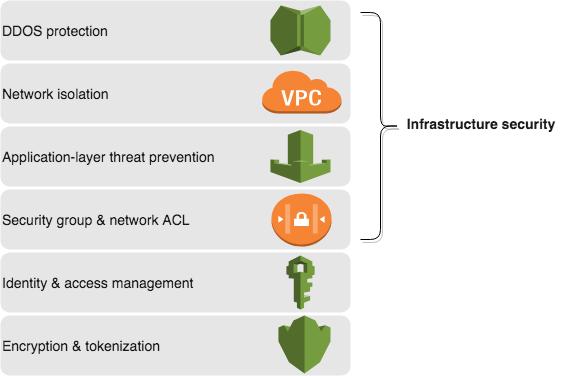
Let’s look at each of these control layers in detail.
DDOS protection: A distributed denial of service (DDOS) attack can overwhelm your database through your application. Help protect your application and database from Layer 3 and Layer 4 volumetric attacks by using services such as AWS Shield with a content-delivery network service such as Amazon CloudFront. For more information, see AWS Best Practices for DDOS resiliency.
Network isolation: One of the most fundamental ways to help secure your database is either to place it in a virtual private cloud (VPC) or make it accessible only from your VPC via VPC endpoints. This is applicable to regional services such as DynamoDB and Amazon S3.
In both cases, the traffic to and from your database remains within your network and is not exposed externally. As a result, access to the database can be restricted to internal resources in your VPC. This enables easier implementation of fine-grained network access control to your database.
Application-layer threat prevention: This layer applies indirectly to your database via the application layer. The argument here is that you are only as secure as your weakest link. Applications have “front door” access to the database, so you want to ensure that you protect your application from threats such as SQL injection.
Protect your application from such threats by enabling AWS WAF on the Application Load Balancer or your CloudFront distribution. This helps to mitigate against application-level attacks such as SQL injection or the OWASP top 10 application vulnerabilities. You also can enable database firewall application solutions such as those available from the AWS Marketplace.
Security group and network ACL: Restricting network traffic to your database ensures that only legitimate traffic is allowed into the database and all other traffic is blocked, which helps reduce attack vectors. You can use network ACLs to implement a zone-based model (web/application/database) and use security groups to provide microsegmentation for components of the application stack. Read more about security zone modeling in the “Using Security Zoning and Network Segmentation” section of the AWS Security Best Practices whitepaper.
By setting up security groups for each of your applications, you can model network security for your database by configuring the security groups to allow ingress traffic only from selected application security groups. This approach also eliminates the complexity of having to manage the network security of your database by using application Classless Inter-Domain Routing (CIDR) ranges. For more information about how to configure security groups, see Working with Security Groups.
Identity and access management (IAM): To enable a strong yet flexible mechanism for authentication, separate management flow (database administration tasks) from application flow (application access to data). For management flow, consider using IAM and implementing multi-factor authentication for authentication and authorization. The following code example is an IAM policy for Amazon RDS that enables a limited set of management functions and can be attached to an IAM user, group, or a role.
For application flow, apply the principle of least privilege to corresponding database access credentials.
Initiate database connections and operations for the more privileged management flows from a dedicated network zone. The zone should be deemed appropriate for management flows and is separate from application flows (as per security-zone modeling mentioned earlier in this post). This approach limits the potential for damage to your environment if an application is compromised because management credentials and operations are separated from the application credentials and operations. Optionally, you could implement a database firewall solution from AWS Marketplace as a policy enforcement point to ensure that the types of database commands executed from a given security zone are appropriate for that security zone.
When a database requires credentials that are not integrated with IAM, consider using a secrets management system. Systems such as AWS Secrets Manager or AWS Systems Manager Parameter Store help securely store, rotate, and allow runtime access to applications of database credentials.
Encryption and tokenization: Data encryption and tokenization help protect against risks such as data exfiltration through unauthorized access mechanisms. Enable data encryption both at rest and in transit (I plan to cover the details of how to do this in Amazon RDS and Amazon DynamoDB in subsequent blog posts).
Consider also how the master encryption key is generated and the lifecycle is managed. A simple and robust mechanism for encryption key management is through AWS Key Management Service (AWS KMS). AWS KMS supports customer master keys (CMK) and has integration with Amazon S3, Amazon EMR, Amazon Redshift, Amazon RDS, and DynamoDB (see region support) for data encryption using keys managed in AWS KMS.
Consider application-level (also known as client-side) encryption with AWS KMS managed encryption keys. However, whether you use application-level encryption might depend on factors such as the highly protected classification of parts of the data, the need for end-to-end encryption, and the inability of the backend infrastructure to support end-to-end encryption. Consider this option carefully because it can potentially limit the native functions a database can perform on the application-encrypted data.
Finally, tokenization is an alternative to encryption that helps to protect certain parts of the data that has high sensitivity or a specific regulatory compliance requirement such as PCI. Separating the sensitive data into its own dedicated, secured data store and using tokens in its place helps you avoid the potential cost and complexity of end-to-end encryption. It also allows you to reduce risk with temporary, one-time-use tokens.
Detective controls
The effective application of detective controls allows you to get the information you need to respond to changes and incidents. A robust detection mechanism with integration into a security information and event monitoring (SIEM) system enables you to respond quickly to security vulnerabilities and the continuous improvement of the security posture of your data.
Let’s examine some of the detective controls that you can implement:
Detection of unauthorized traffic: Continuous monitoring of VPC flow logs enables you to identify and remediate any security anomalies. Amazon GuardDuty is a managed service that provides managed threat intelligence in the cloud. GuardDuty takes feeds from VPC flow logs, AWS CloudTrail, and DNS logs. It uses machine learning, pattern-based signatures, and external threat intelligence sources to provide you with actionable findings. You can consume these findings as Amazon CloudWatch events to drive automated responses.
Configuration drift: Configuration drift is the condition in which a system’s current security configuration drifts away from its desired hardened state. Configuration drift can be caused by modifications to a system subsequent to its initial deployment. To ensure the integrity of the security posture of your databases, you have to identify, report, and remediate configuration drift. You can use AWS Config with DynamoDB to detect configuration drift easily at the table level and with Amazon RDS for database instances, security groups, snapshots, subnet groups, and event subscriptions.
Fine-grained audits: Consider enabling audits on both management and application flows to your database. The scope of auditing database access and usage also might require gradual fine-tuning based on your specific environment and usage Auditing can carry a performance tradeoff and varying degrees of auditing scope are available, depending on the database you use.
You might start by capturing all direct data definition language (DDL) and data manipulation language (DML) statements as well as database administration events on your database (especially in the early stages of your production rollout). You then can narrow the conditions gradually as usage becomes clear and you become more confident in your security design.
In Amazon RDS you can use CloudTrail to log all calls to Amazon RDS API, such as CreateDBInstance, StartDBInstance and StopDBInstance. Additionally, if your database engine supports it, you can either use configuration-driven SQL auditing of the individual database management system engine or system audit tables to audit SQL queries running against your databases. I plan to discuss these in detail in a subsequent post.
You can use CloudWatch to set up alert rules that create real-time Amazon SNS notifications or execute an AWS Lambda function create a security incident in your ticketing system or trigger an event in your SIEM system. Also, you can configure CloudTrail to send event logs to CloudWatch. Amazon Aurora MySQL, Amazon RDS MySQL, and MariaDB can publish database instance log events, which contain audited SQL queries, directly to CloudWatch.
Swim-lane isolation
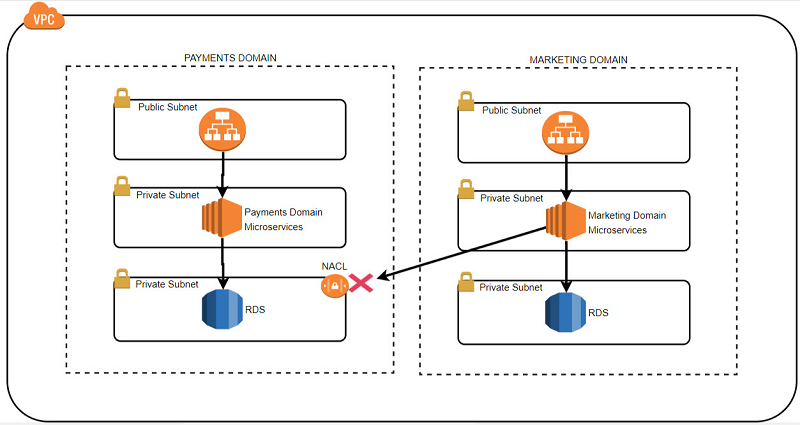
Swim-lane isolation can be best explained in the context of domain-driven design. If you think about grouping microservices into domains that resemble your business model, you can also think about the security of the data stores attached to each of those microservices from the context of a business domain. This enables you to achieve two things:
- Enforce a pure microservices data-access pattern to ensure that microservice data store access is available only through the owning microservice APIs.
- Ensure that sensitive data from one microservice domain does not leak out through another microservice domain.
Consider the scenario of a typical organization that collects, persists, and exposes through APIs data of a variety of sensitivity and confidentiality levels. For example, a bank might have data stores for the payment domain APIs that hold highly sensitive data. The bank also might have APIs in the marketing domain that expose publicly available data on the company’s website.
Additionally, the payment domain APIs might have higher security and nonfunctional requirements compared to the marketing domain APIs that operate on less sensitive data. In this example, then, swim-lane isolation would create a strict network separation (a network swim lane) between the two domains. In this way, there is no ability for a request being processed in the marketing domain to traverse and directly access the data stores of the payment domain.
You can achieve this swim-lane isolation through a combination of applying appropriate IAM controls and network flow controls. The network flow controls include a network ACL on the entire subnet of your data store layer, or allow access to your data store only from the payment domain VPC endpoint and deny all traffic from origins. For more information, see VPC Endpoints and Network ACLs.
Summary
In this blog post, I explored some of the best practices for securing data on AWS and how you can implement them. I also explained the AWS CAF and the five key capabilities within the AWS CAF Security Perspective: AWS IAM, detective control, infrastructure security, data protection, and incident response.
The security best practices in this post tie back to some of the key capabilities of the Security Perspective. The capabilities include defining IAM controls, multiple ways to implement detective controls on databases, strengthening infrastructure security surrounding your data via network flow control, and data protection through encryption and tokenization.
For more information about security best practices for your data, see the AWS Security Best Practices whitepaper and the Overview of AWS Security – Database Services whitepaper.
In part 2 of this series, I demonstrate how to implement these concepts to Amazon RDS databases.
Finally, in part 3 of this series, I demonstrate how you can also implement these concepts in Amazon DynamoDB as well.
About the Author
 Syed Jaffry is a solutions architect with Amazon Web Services. He works with Financial Services customers to help them deploy secure, resilient, scalable and high performance applications in the cloud.
Syed Jaffry is a solutions architect with Amazon Web Services. He works with Financial Services customers to help them deploy secure, resilient, scalable and high performance applications in the cloud.