Artificial Intelligence
Category: Amazon SageMaker Data Wrangler
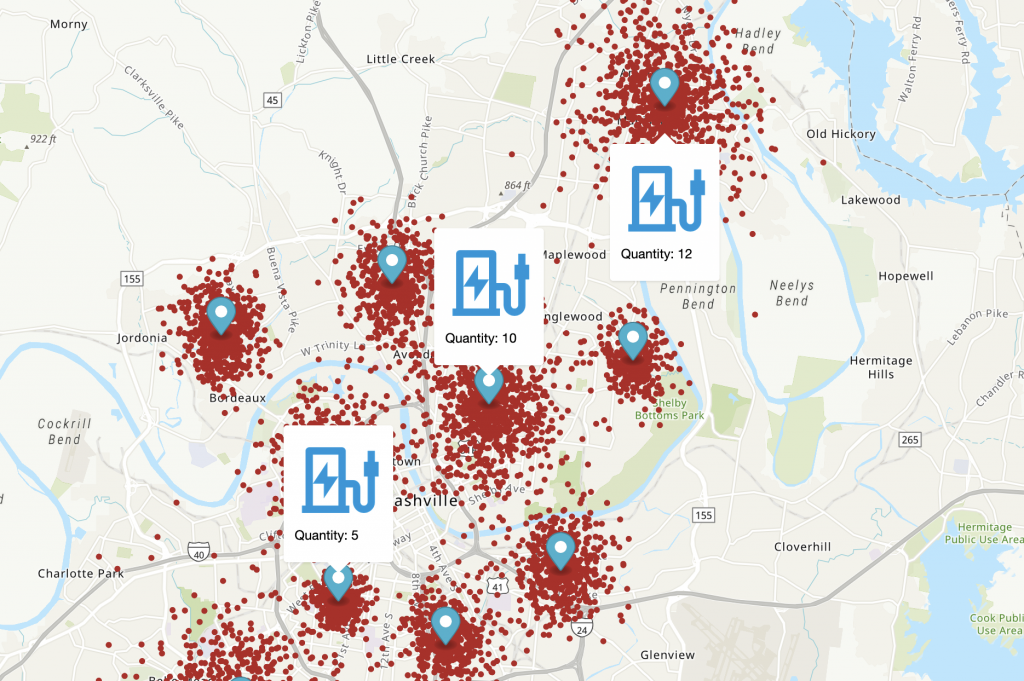
Plan the locations of green car charging stations with an Amazon SageMaker built-in algorithm
While the fuel economy of new gasoline or diesel-powered vehicles improves every year, green vehicles are considered even more environmentally friendly because they’re powered by alternative fuel or electricity. Hybrid electric vehicles (HEVs), battery only electric vehicles (BEVs), fuel cell electric vehicles (FCEVs), hydrogen cars, and solar cars are all considered types of green vehicles. […]

Accelerate data preparation using Amazon SageMaker Data Wrangler for diabetic patient readmission prediction
Patient readmission to hospital after prior visits for the same disease results in an additional burden on healthcare providers, the health system, and patients. Machine learning (ML) models, if built and trained properly, can help understand reasons for readmission, and predict readmission accurately. ML could allow providers to create better treatment plans and care, which […]

Schedule an Amazon SageMaker Data Wrangler flow to process new data periodically using AWS Lambda functions
Data scientists can spend up to 80% of their time preparing data for machine learning (ML) projects. This preparation process is largely undifferentiated and tedious work, and can involve multiple programming APIs and custom libraries. Announced at AWS re:Invent 2020, Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare data for […]
Develop and deploy ML models using Amazon SageMaker Data Wrangler and Amazon SageMaker Autopilot
Data generates new value to businesses through insights and building predictive models. However, although data is plentiful, available data scientists are far and few. Despite our attempts in recent years to produce data scientists from academia and elsewhere, we still see a huge shortage that will continue into the near future. To accelerate model building, […]

Prepare data from Snowflake for machine learning with Amazon SageMaker Data Wrangler
Data preparation remains a major challenge in the machine learning (ML) space. Data scientists and engineers need to write queries and code to get data from source data stores, and then write the queries to transform this data, to create features to be used in model development and training. All of this data pipeline development […]

Prepare data for predicting credit risk using Amazon SageMaker Data Wrangler and Amazon SageMaker Clarify
For data scientists and machine learning (ML) developers, data preparation is one of the most challenging and time-consuming tasks of building ML solutions. In an often iterative and highly manual process, data must be sourced, analyzed, cleaned, and enriched before it can be used to train an ML model. Typical tasks associated with data preparation […]

Enable cross-account access for Amazon SageMaker Data Wrangler using AWS Lake Formation
Amazon SageMaker Data Wrangler is the fastest and easiest way for data scientists to prepare data for machine learning (ML) applications. With Data Wrangler, you can simplify the process of feature engineering and complete each step of the data preparation workflow, including data selection, cleansing, exploration, and visualization through a single visual interface. Data Wrangler […]
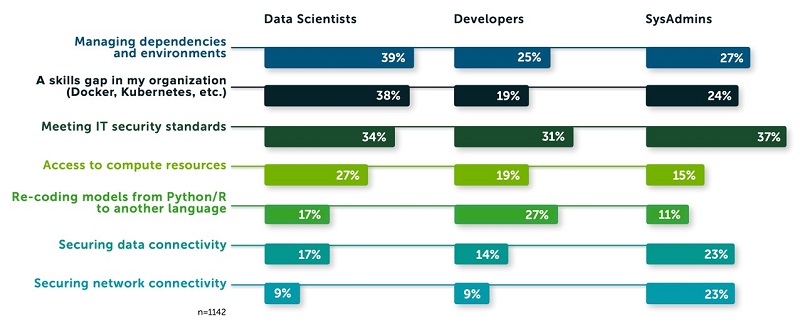
Exploratory data analysis, feature engineering, and operationalizing your data flow into your ML pipeline with Amazon SageMaker Data Wrangler
According to The State of Data Science 2020 survey, data management, exploratory data analysis (EDA), feature selection, and feature engineering accounts for more than 66% of a data scientist’s time (see the following diagram). The same survey highlights that the top three biggest roadblocks to deploying a model in production are managing dependencies and environments, […]