Amazon Web Services ブログ
AWS 上で Autonomous Driving Data Framework (ADDF) を使用した、カスタマイズされたワークフローの開発とデプロイ
このブログは、Develop and deploy a customized workflow using Autonomous Driving Data Framework (ADDF) on AWS を翻訳したのものです。
自動運転車は、死亡事故や負傷事故に対する信頼性を実証するために、何億マイル、時には何千億マイルも走行する必要があります。そして、仮想テストやシミュレーション、数学的モデリングや分析、シナリオや挙動テストなど、実世界でのテストを補完する代替の方法が必要とされています。今回の AWS re:Invent のセッションでは、安全で高性能な自動運転システムを開発するために、BMW グループが世界中のお客様のコネクテッドカーから 10 億 km を超える匿名化された認識データをどのように収集しているかを学びました。
Autonomous Driving Data Framework (ADDF) は現在、このリファレンスソリューションを実用化し、あらかじめ構築されたサンプルデータ、集中管理されたデータストレージ、データ処理のためのパイプライン、可視化のためのメカニズム、検索用インターフェース、シミュレーションワークロード、分析用インターフェース、そして、事前構築済みのダッシュボードを提供しています。モデルのトレーニング、合成データの生成、シミュレーションといった下流のワークロードのために、検索可能でかつ高精度なラベルが付与されたシナリオベースのデータを処理し、提供をすることを目標としています。
ユースケースとソリューションの概要
ADDF の最初のリリースでは、以下の 4 つのユースケースをカバーしています (図1)。
- シーンの検出と検索: データの取り込み後、取り込まれた各ファイルからメタデータを抽出し、シーン検出用パイプラインを用いて、車線内に人物がいるというシナリオなど、関心のあるシーンを見つけ出します。検出されたシーンのメタデータは Amazon DynamoDB に格納され、Amazon OpenSearch サービスを通じて利用できます。これにより、ユーザーはシーンのメタデータを基に、データレイク内の関連する入力データを検索して探し出すことができます。
- データの可視化: ADDF は Webviz ベースのデータ可視化モジュールを備えており、データレイクから ROS バッグファイルをストリーミングし、ブラウザ上で可視化することができます。この可視化モジュールは、前述のステップで検出した特定のシーンのストリーミングをサポートしており、ユーザーがファイルの検証やデバッグを行うことができます。
- シミュレーション: ADDF を使用することで、ユーザーは取り込まれたデータに対してコンテナ化されたワークロードを大規模に実行することができます。シミュレーションモジュールは、Amazon Managed Workflows for Apache Airflow (Amazon MWAA) を使用したハイレベルなワークフローのオーケストレーション機能を備えており、 AWS Batch やマネージドの Kubernetes サービスである Amazon Elastic Kubernetes Service (Amazon EKS) などのスケーラブルな並列処理に最適化した専用のサービスに、計算集約型のシミュレーションタスクを任せることができます。
- 開発とデプロイ: AWS のオープンソースプロジェクトである CodeSeeder と SeedFarmer を使うことで、1 から 3 で紹介したモジュールのブートストラップ、開発、デプロイを実行することができます。CodeSeeder は、AWS CodeBuild を利用して、個々のモジュールをリモートでデプロイします。これにより、 AWS Cloud Development Kit (AWS CDK), AWS CloudFormation, Terraform といった共通の infrastructure as code とデプロイのためのメカニズムを用いて、各モジュールをデプロイすることができます。SeedFarmer では宣言型マニフェストを利用して ADDF のデプロイメントを定義し、モジュールのデプロイ、削除、変更の検出、および、状態管理のオーケストレーションを行います。SeedFarmer を用いることで、ADDF のデプロイメントについて、自動化した GitOps に基づく管理を行うことができます。

図1: ADDF のユースケース
このソリューションのアーキテクチャ (図2) は、下記の 6 つの重要な要素から構成されています。
- コード開発のためのユーザーインターフェース (AWS Cloud9)、KPI のレポーティング (Amazon QuickSight)、シナリオ検索と可視化のための Web アプリケーション、デプロイ用ツール (SeedFarmer CLI)、モデリング (Jupyter Notebook) です。
- シーンの検出と検索、ROS バッグファイルの仮想化、EKS によるシミュレーションの 3 つのワークフローが事前に構築されています。ロードマップには追加予定のワークフローが3つあり、モデルの学習、自動ラベリング、KPI 計算のワークフローを今後追加予定です。
- オーケストレーションサービスとしては Amazon MWAA を採用し、そのバックエンドとして柔軟性の高いコンピュートサービス(AWS Batch、Amazon EKS、Amazon EMR)を使用しています。
- メタデータストレージとしては、運転データ用には AWS Glue Data Catalog、ファイルおよびデータリネージ用に Amazon Neptune、運転メタデータ用に Amazon DynamoDB、OpenScenario 検索用には Amazon OpenSearch Service を用いています。
- Amazon Simple Storage Service (Amazon S3) を生データ用のデータストレージ、Amazon Redshift を数値センサーデータ用のデータストレージとして使用しています。
- CI/CD の自動化には、AWS CDK、AWS CodeBuild、AWS CodeSeeder を用いています。

図 2: ADDF ソリューションの概要
デモ用ノートブックを用いた、評価用の ADDF 環境をデプロイする
前提条件
デプロイを簡素化し、依存関係や前提条件の数を減らすために、ADDF では 2 つの AWS のオープンソースプロジェクトを利用しています。AWS CodeBuild 上で Python コードのリモート実行を可能にする CodeSeeder、CodeSeeder を用いた ADDF モジュールのデプロイをオーケストレーションする SeedFarmer の 2 つです。
CodeSeeder と SeedFarmer を活用することにより、ローカル環境で必要な前提ソフトウェアを以下のみに減らすことができます。
- Python バージョン 3.7 以上
- git CLI
- AWS クレデンシャル
- AWS CLI
- aws-cdk CLI バージョン 2.20
デプロイメント
ステップ 1: ADDF のリポジトリを GitHub からクローンします。最新の公式リリースブランチをチェックアウトすることを推奨しています。また、ADDF はお客様自身の git リポジトリに結びついた自動化された CI/CD プロセスによって管理することを意図しているため、私たちのリモート GitHub リポジトリをアップストリームのリモートリポジトリとして設定することをお勧めします。
git clone --origin upstream --branch
release/0.1.0 https://github.com/awslabs/autonomous-driving-data-frameworkステップ 2: Python の仮想環境を作成し、依存関係をインストールします。
cd autonomous-driving-data-framework
python3 -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt有効な AWS クレデンシャルがあることを確認し、デフォルトのリージョンを設定して、CDK をブートストラップします。CDK のブートストラップは、AWS CDK を以前同じアカウント/リージョンで使用したことがない場合にのみ必要です。
export AWS_DEFAULT_REGION=<<REGION>>
cdk bootstrap aws://<<ACCOUNT_NUMBER>>/<<REGION>>上記の
ACCOUNT_NUMBERとREGIONを置き換えてブートストラップする必要があります。
ステップ 3: ADDF で使用するシークレットを AWS Secrets Manager に作成します。作成したシークレットは以下で使用されます。
- JupyterHub
- VS Code
- OpenSearch Proxy
- Docker Hub (オプション)
シークレットを簡単に作成できるようにスクリプトを用意してあります (最初のスクリプトでは jq ツールを使用しています)。
source ./scripts/setup-secrets-example.sh # This sets up the first three credentials.
./scripts/setup-secrets-dockerhub.sh # This will prompt for username and password.
ステップ 4: モジュールを選択し、デプロイを開始します。ADDF は様々なモジュールから構成されており、いわゆるマニフェストの中でオンにするモジュールを選択することができます。./manifests フォルダにサンプルのマニフェストが置いてあります。サンプルのマニフェストをコピーして、環境固有のマニフェストを作成することをお勧めします。
cp -R manifests/example-dev manifests/demo
sed -i .bak "s/example-dev/demo/g" manifests/demo/deployment.yamlここでは、demo フォルダをウォークスルーのために使用します。demo フォルダにはモジュールをデプロイするためのドライバとして deployment.yaml マニフェストが格納されています。このマニフェストを編集することで、ADDF のデプロイメントに含めたいモジュールを選択することができます。より詳細な設定オプションについては、リポジトリ内のドキュメントを参照してください。ここでは話を簡単にするため、提供されたマニフェストをそのまま使用してデプロイします。
seedfarmer apply ./manifests/demo/deployment.yaml上記のコマンドにオプションで `
--debugフラグを渡すと、デバッグレベルの出力を得ることができます。また、
--dry-runフラグを渡すことで、モジュールをデプロイする際に発生するアクションプランを把握・プレビューすることができます。
上記のコマンドを実行した結果、デプロイに成功すると、図 3 のようにデプロイされた ADDF のモジュール一覧を見ることができます。

図3: デプロイされたモジュール一覧
ユースケースについてのデモ
JupyterHub へのログイン
ADDF のデプロイに成功すると、 Amazon EKS 上にデプロイされた JupyterHub モジュールにアクセスすることができます。 下記の指示に従って JupyterHub のダッシュボードにアクセスできます。
JupyterHub はデモに関連するワークロードにのみ使用することを推奨しています。本番用データが関連してくるデータやサービスと本番レベルのやりとりをする際に使用することは推奨していません。デモ以外のワークロードに関しては Amazon EMR Studio を使用することを推奨しています。
-
- URL https://console.aws.amazon.com/ec2/ から Amazon EC2 のコンソールを開きます。
- ナビゲーションバー上で、ADDF をデプロイしたリージョンを選択し、JupyterHub 用に作成したロードバランサーのDNS 情報を取得します。
- 下記のように、
k8s-jupyterから始まる名前のロードバランサーを選択します。k8s-jupyterh-jupyterh-XXXXXXXXX.us-west-2.elb.amazonaws.com - このロードバランサーの DNS 名をコピーして、以下のように
jupyterを追記します。k8s-jupyterh-jupyterh-XXXXXXXXX.us-west-2.elb.amazonaws.com/jupyter - 次にプロンプトが立ち上がるので、JupyterHub の
usernameとpasswordを入力します。これらの情報は、最初にヘルパースクリプトのsetup-secrets-example.shを実行した際に作成されたもので、AWS Secrets Manager に保存されています。AWS Secrets Manager のコンソールから取得することができ、コンソール上で検索バーからjh-credentialsを選択してクレデンシャルを取得します。 - JupyterHub 環境へのログインが完了すると、サンプルのノートブックを作成できます。
シーン検出用パイプラインの実行
-
- 公開されている 2 つのサンプル用 ROS バッグファイル (ファイル 1 とファイル 2 )をダウンロードし、
datalake-bucketsモジュールによってデプロイされたraw-bucketにコピーします。バケット名はaddf-demo-raw-bucket-<<hash>>という命名パターンで特定できます。ダウンロードしたファイルをrosbag-scene-detectionというプレフィックスの配下にコピーしてください。 - 上記のファイルがアップロードされると、AWS Step Functions によってシーン検出用モジュールが起動され、このモジュール固有の DynamoDB テーブルである
Rosbag-BagFile-MetadataおよびRosbag-Scene-Metadataに結果が格納されます。以下は、scene-detectionパイプラインが正常に実行されたときのスクリーンショット(図4)です。
- JupyterHub ノートブック内で後述のコマンドを実行する前提として、以下のようにいくつかのバイナリをインストールする必要があります。
-
pip install boto3 pandas awscli
-
- 以下のコマンドを実行することで、OpenSearch ドメインに対してクエリを実行し、テーブルの一覧を取得することができます。
wget -qO- \ --no-check-certificate \ https://vpc-addl-example-dev-core-opens- <<XXXXXXXX>>.<<region>>.es.amazonaws.com /_cat/indices?h=index上記のコマンドの OpenSearch ドメインとテーブル名を、使用しているアカウントにデプロイされているリソースの物理的な IDとリージョンを使って置き換えてください。
- 名前が
rosbag-metadata-scene-search-<<date>>で始まるテーブルを選択し(テーブル名をコピーします)、下記のようにクエリを構築します。wget -qO- \ --output-document=query_results.json \ --no-check-certificate \ "https://vpc-addl-example-dev-core-opens- <<XXXXXXXX>>.<<region>>.es.amazonaws.com/rosbag-metadata- scene-search--<<date>>/_search?pretty=true”上記のコマンドの OpenSearch ドメインとテーブル名を、使用しているアカウントにデプロイされているリソースの物理的な IDとリージョンを使って置き換えてください。
- 公開されている 2 つのサンプル用 ROS バッグファイル (ファイル 1 とファイル 2 )をダウンロードし、
このユースケースでは、ROS バッグファイル向けのエンドツーエンドのシーン検出用パイプラインを提供しています。S3 からROS バッグファイルを取り込み、トピックデータを Parquet 形式に変換し、Amazon EMR 上の PySpark を使ってシーン検出を実行しています。これにより、Amazon OpenSearch が DynamoDB を介してシーンの記述にアクセスすることができるようになります。
ROS バックファイルを可視化する
Amazon API Gateway を用いたプライベート REST API に対してクエリを実行することで Webviz のエンドポイントを生成し、クエリ文のパラメータである scene-id と record-id を付加して最終的なエンドポイントを構築し、署名付き URL を取得することができます。
wget -qO- \
"https://XXXXXX.execute-api.<<region>>.amazonaws.com/get-
url?scene_id=small2__2020-11-19-16-21-
22_4_PersonInLane_1.6058245149E9&record_id=small2__2020-11-19-
16-21-22_4"上記のコマンドのプライベート REST API リンクを、使用しているアカウントにデプロイされているリソースの物理的な IDとリージョンで置き換えてください。
そして、レスポンスボディから url キーの値をコピーして、Google Chrome ブラウザ(推奨)で開きます。URL の読み込みが完了すると、Webviz のカスタムレイアウトを JSON 形式の設定としてインポートすることができます。このカスタムレイアウトには、我々の ROS バッグのフォーマットに特有のトピック構成とウィンドウレイアウトが含まれており、お客様の ROS バッグのトピックに応じて変更する必要があります。カスタムレイアウトをインポートするには、以下の手順に従ってください。
- Config → Import/Export Layout を選択します。
- layout.json の内容を
autonomous-driving-data-framework/modules/demo-only/rosbag-webviz/layout.jsonからコピーして、ポップアップウィンドウに貼り付け、内容を実行してください。
図 5 のように、検出されたシーンの出力例が表示されているはずです。

図5: Amazon S3 からストリーミングされた ROS バッグファイルの可視化例
パイプラインのカスタマイズ
コードベースは管理のために分割されています。デプロイメント(deployment)はグループ(groups)によって構成されており、グループはモジュール(modules)によって構成されています。コードはモジュールに格納されており、グループとデプロイメントは論理的な分割を行うためのものです。モジュールは、異なるグループに属する他のモジュールに依存することができます(たとえば、ネットワークモジュールは他のモジュールから再利用できます)が、あるグループの一部として宣言されたモジュールは、同じグループ内で依存関係を宣言することはできません。依存関係をネイティブに処理するために、グループは指定された順序でデプロイされ、その逆の順序で削除されます。モジュールのリストとその順番を決定する際、順番は重要です(例えば、VPC を必要とする計算リソースをデプロイする前に、ネットワーキングモジュールをデプロイする必要があります)。モジュールは、カスタマイズのための入力パラメータと、他のモジュールで利用することができる出力パラメータを定義することが可能で、コードベースのモジュールが互いに抽象化されたレベルとなります。言い換えると、同じデプロイメント内の他のモジュールに影響を与えることなく、デプロイされたモジュールを変更することができます(例えば、新しい機能を追加したり、入力パラメータを変更したり)。
マニフェストによって、プロジェクト内の各モジュールの入力が定められています。プライマリマニフェスト(図 6 の deployment.yaml) によって、デプロイメントの名前(プロジェクトとも呼ばれます)、デプロイメント内のグループとその順序、および各グループのマニフェストが存在する場所が指定されています。

図6: プライマリマニフェストファイル
各グループのマニフェスト内では、モジュール、コードの場所、および Key-Value 形式の入力パラメータが定義されています(ここで別のグループからあるモジュールの出力を参照することもできます)。
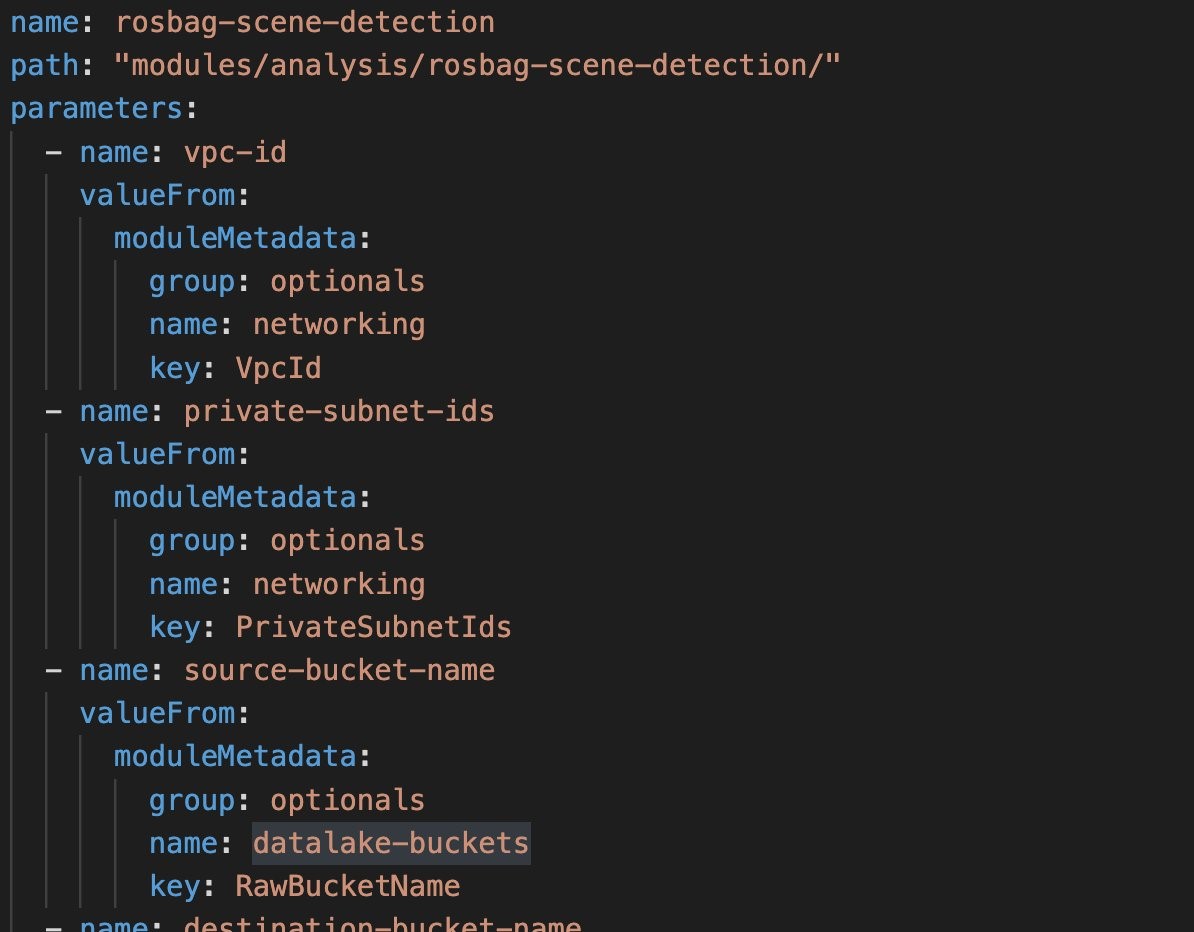
図7: あるモジュールのマニフェストファイル
では基本的な理解ができたところで、私たちにとってどのような利点があるのかを探ってみましょう。モジュール rosbag-scene-detection は manifests/demo/rosbag-modules.yaml (図 7)で定義されており、コードは modules/analysis/rosbag-scene-detection に配置されています。モジュールがデプロイされた後にデータ処理の新しいステップを追加する等、コードを修正したい場合は、コードに変更を加えて保存します。変更を有効にしデプロイするためには、ターミナルからデプロイを再実行する必要があります。
seedfarmer apply ./manifests/demo/deployment.yamlSeedFarmer はモジュールのコードベースに変更があったことを検出し、モジュールを再デプロイします。バックグラウンドで、SeedFarmer は deployment.yaml の内容を既にデプロイされているものと比較し、(deployment.yaml 内で指定された順序で)変更を適用しています。各モジュールはそれぞれに一定の抽象化がされており、変更のあったモジュールだけが再デプロイされ、変更のないモジュールは変更されません。
クリーンアップ
指定されたデプロイメントデモのモジュールを削除するには、以下のコマンドを実行します。
seedfarmer destroy demoカスタマイズしている場合は、
demoという文字列を設定した環境名で置き換えてください。上記のコマンドにオプションで`--debugフラグを渡すと、デバッグレベルの出力を得ることができます。
展望と結論
ADDF は、ADAS に関するワークロード用のオープンソースフレームワークで、すぐに利用できます。このブログでは、まず、そのアーキテクチャとどのようなユースケースがカバーされているかを説明しました。次に、ADDF をゼロからデプロイして素早く使い始める方法を説明しました。そして最後に、個々のニーズに合わせてシーン検出用パイプラインをカスタマイズする方法を説明しました。
ASAM Test Specification のスタディグループが提供するテスト戦略に関するブループリントには、自動運転車や運転機能を安全かつ確実に検証するためのテスト手法とユースケースが定義されています。ADDF は、シナリオベースのテストやフォールトインジェクションを含むテスト手法を網羅しています。私たちは、より多くのワークフロー、マルチテナント、合成シーンの生成など、お客様の要望に応えるため、ADDF の拡張と開発に取り組んでいます。
OEM や Tier-N サプライヤー、そしてスタートアップ企業は、このオープンソースのソリューションの恩恵を受けることができます。私たちはオープンソースを強く支持しており、コミュニティからのフィードバックや貢献を重視しています。
参考
- Reference Architecture for Autonomous Driving Data Lake
- Field Notes: Building an Autonomous Driving and ADAS Data Lake on AWS
- Field Notes: Building an automated scene detection pipeline for Autonomous Driving – ADAS Workflow
- Field Notes: Deploying Autonomous Driving and ADAS Workloads at Scale with Amazon Managed Workflows for Apache Airflow
- Field Notes: Building an Automated Image Processing and Model Training Pipeline
- Field Notes: Deploy and Visualize ROS Bag Data on AWS using rviz and Webviz for Autonomous Driving
- Developing a Platform for Software-defined Vehicles with Continental Automotive Edge (CAEdge)
- How to Run Massively Scalable ADAS Simulation Workloads on CAEdge
このブログはソリューションアーキテクトの畔栁竜生、國政丈力、渡邊翼とスペシャリストの橘幸彦が翻訳を担当しました。