AWS Architecture Blog
Field Notes: Building an Autonomous Driving and ADAS Data Lake on AWS
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
Customers developing self-driving car technology are continuously challenged by the amount of data captured and created during the development lifecycle. This is accelerated by the need to design and launch incremental feature improvements on advanced driver-assistance systems (ADAS). Efforts to advance ADAS functionality have led to new approaches for storing, cataloging, and analyzing driving data captured from vehicles on the road today. Combining data from connected vehicle fleets transmitted over cellular networks in combination with manually ingesting data from vehicle data loggers requires a complex architecture and elastic data lake capability that only AWS provides.
This blog explains how to build an Autonomous Driving Data Lake using this Reference Architecture. We cover the workflow from how to ingest the data, prepare it for machine learning, catalog the output from ADAS systems and vehicle sensors, label it, automatically detect scenarios, and manage the various workflows required for moving it into an organized data lake construct. The AWS Autonomous Driving and ADAS Data Lake Reference Architecture was developed after working with numerous customers on the challenges they faced in achieving this. Using multiple AWS services and solution best practices, we outlined an approach we found helpful to others.
In the blog post, Autonomous Vehicle and ADAS development on AWS Part 1: Achieving Scale, we outlined the benefits having a data lake in the cloud, as opposed to building your own on-premises data lake solution.
Before we dive into the details of the reference architecture, let’s review the typical workflow of autonomous and ADAS development. The diagram below shows the following steps, much of which are common in any machine learning project:
- data acquisition and ingest,
- data processing and analytics,
- labeling, map development,
- model and algorithm development,
- simulation and validation, and
- orchestration and deployment.
This blog focuses on data ingest, data processing and analytics, labeling, and the data lake itself, as shown in the following workflow diagram:
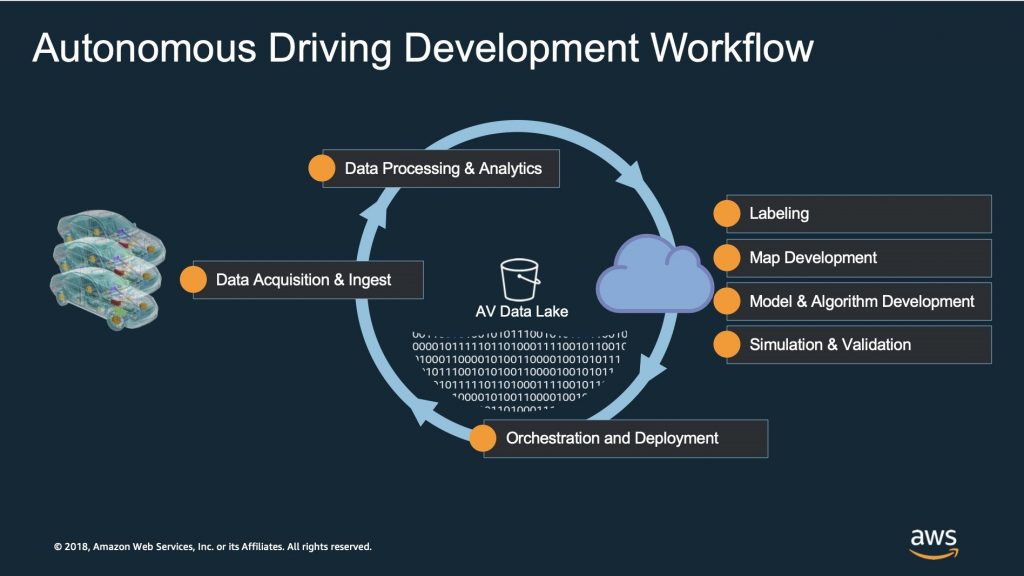
Why build a data lake for ADAS and Autonomous Driving System development?
At AWS re:Invent 2019, BMW spoke at this session; (AUT306): Creating a data-driven, cloud-native ecosystem at BMW Group where they explained the motivation for developing an enterprise-wide cloud data lake, or the Cloud Data Hub as they call it. The Cloud Data Hub ingests information from multiple lines of business including sources like manufacturing systems, logistics, customer service, after-sales, and connected vehicle sensor telemetry data.
BMW created a global organization to drive DevOps culture with a strong emphasis on tooling, data quality, and end-to-end data lineage. Their journey began in the Hadoop eco-system (Hive, HBase) with an on-premises, heterogeneous, and difficult-to-scale environment, then moved to cloud-native building blocks with a focus on data quality. Examples of benefits derived from the AWS Cloud implementation are multi-region deployments, high security standards, and compliance with local regulations. The goal is to democratize the most valuable information assets so they can be used across a broad community globally.
The BMW Cloud Data Hub is just one example of how customers manage information assets for sharing across the enterprise. Using a similar approach, the AWS Autonomous Driving and ADAS Data Lake Reference Architecture extends the data lake pattern to address specific challenges around:
- metadata and the data catalog including automated scenario detection;
- data lineage from source to semantic layer;
- data sharing with external consumers and third party service providers via Amazon SageMaker Ground Truth.
Now let’s review the details of the Autonomous Driving Data Lake Reference Architecture:

1. Ingest data from autonomous fleet with AWS Outposts for local data processing.
Sensor data is captured and written to data loggers containing multiple SSD hard drives. Once at the garage or customer facility, the hard drives are removed and inserted into copy stations. From there the data is copied to Amazon S3 or to a local storage system and AWS Outposts for pre-processing. AWS Outposts is a fully managed service that extends AWS infrastructure with AWS Services like Amazon Elastic Kubernetes Service, Amazon Relational Database Service, Amazon EMR on Amazon S3 (EMR supports EMRFS and HDFS which both natively support S3). These services are used to run data integrity checks, compress the data to remove redundant information and prepare the data for downstream AD workloads.
Using AWS DataSync, the data is synchronized at high data rates and securely between on-premises network attached storage (NAS) sources and Amazon S3. This is done over a high bandwidth connection provided by AWS Direct Connect.
2. Ingest vehicle telemetry data in real time using AWS IoT Core and Amazon Kinesis Data Firehose.
Vehicle telemetry is captured and published to the cloud using a number of different technologies, typically over HTTPS or MQTT. In this architecture, AWS IoT Greengrass provides an intelligent edge runtime in the vehicle with application logic running in Lambda functions deployed locally to filter vehicle network signals like CAN data, GPS location, ADAS system output, road condition metadata derived from cameras, and other vehicle sensor information.
AWS IoT Greengrass allows customers to deploy containers, machine learning inference models, create multiple data streams and prioritize them based on business logic you define. Eventually, the data ends up in S3 to be combined with the sensor data captured from the data logger process defined in step one above.
3. Remove and transform low quality data.
Autonomous vehicles produce terabytes of data per hour. In this trove of information, there may be redundant as well as corrupted data coming from the vehicle telemetry stream and raw sensor stack. This data needs to be normalized for optimal downstream processing. Customers use a number of technologies to do this. For example, Amazon EMR provides a runtime for high volume, complex data processing using open source Apache big data processing engines like Spark. There are a few common steps in the data transformation including;
- checking if the driving is complete by combining batch files and streaming data;
- parsing the log files based on recording formats (rosbag, mdf4, etc.);
- decoding the signals from binary formats to readable text;
- filtering inconsistent data files; and
- synchronize the timestamp of signals
EMR Launch is an open source framework developed by AWS Labs available for customers to accelerate and simplify defining, deploying, managing, and using Amazon EMR clusters with the following features:
- separating the definition of cluster security configurations (EMR Profile) and cluster resource configurations (Cluster Configuration) into reusable and shareable constructs; and
- provide a suite of tools to simplify the construction of orchestration pipelines using Amazon Step Functions (EMR Launch Function).
4. Schedule the extract, transform, load (ETL) jobs using Apache Airflow.
To create trustworthy insights and empower your next machine learning use case with a reliable data foundation you need to bring the data creation process under design control. Fundamental to this approach is a centralized, governed workflow system powered by Apache Airflow. With Airflow you can establish trust in your data processing pipelines by making the workflow part of your code base to enable transparent, repeatable, pipeline executions.
The following solution diagram shows how radar and video data processing in MDF4 format achieves the highest scalability by leveraging AWS Fargate for Amazon ECS.
- To ensure data pipeline integrity, the solution is deployed securely in an Amazon Virtual Private Cloud with end-to-end TLS and is only accessed from a private bastion host.
- The containers for Airflow Webserver, Scheduler and Worker are deployed in multiple Availability Zones for high availability.
- The communication between the components are decoupled via Amazon ElastiCache (Redis OSS).
- The status of running jobs is stored in Amazon Aurora.
- To learn more about how to leverage complex workflows and model training jobs on AWS, a future blog post will describe the detailed architecture of Apache Airflow.

5. Enrich data with map information and weather conditions based on GPS location and timestamp.
Data-sets are enriched using Amazon EMR with map or weather information from external geospatial and weather service providers and stored in Amazon S3, or database services like Amazon DynamoDB. Sensors like cameras and LiDAR could malfunction or even fail in adverse weather conditions. Advanced sensor fusing could perform the weather perception in real-time. The result of the weather perception could be verified with the real weather conditions.
6. Extract metadata into Amazon DynamoDB and Amazon Elasticsearch Service.
Using drive logs that contain the telemetry, telematics, perception, and sensor data, a catalog is built to create searchable quantitative metadata that includes speed, turning angles, location as well as simple and complex semantic descriptions of scene snippets such as “high velocity,” “left turn,” or “pedestrian.” The data lake catalog is updated with scenario data and indexed in Amazon Elastic Search for discovery by analysts and ADS engineers. The extraction process is ideally fully automated, but many higher order behavioral descriptions may require human annotations from later processing steps.
The majority of systems leverage quantitative and simple semantic descriptions for the drive data, with a clear trend towards needing higher order behaviors extracted in the data lake catalog. These more complex behaviors are ideal for enhanced searching capabilities and better validating coverage mapping. ASAM OpenSCENARIO defines a scenario description language that provides a common ontology and hierarchy for detailing the behavior of the vehicle and surroundings.
This standard provides an open approach for describing complex, synchronized maneuvers that involve multiple entities including other vehicles, vulnerable road users (VRUs) like pedestrians, bikers, construction workers, and other traffic participants. The description of a maneuver may be based on driver actions like performing a lane change by the ego, or based on the actions of others in the scenario such as a cut in from another driver. OpenSCENARIO also accounts for the appearance/description of the participant in the scene.
7. Store data lineage in Amazon Neptune and catalog data using AWS Glue Data Catalog.
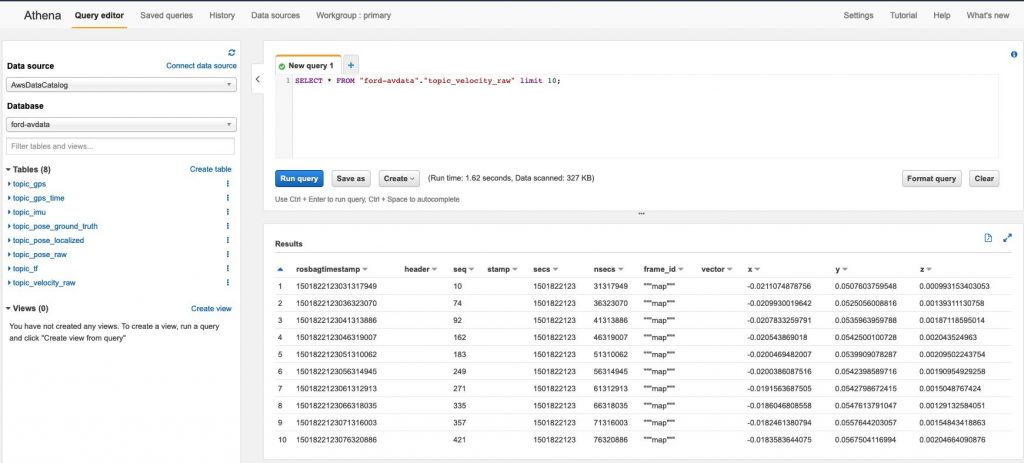
Amazon Neptune is a fully managed graph database service. It’s useful to catalog data lineage in a graph model to visualize file and object dependencies. AWS Glue is a fully managed service that provides a data catalog making assets in the data lake discoverable. Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL.
The following diagram shows how we parse data from the Ford Autonomous Vehicle Dataset in Rosbag format using Amazon EMR. We store it in Amazon S3 in parquet format, use AWS Glue Crawler to read the file schema and create the tables in the AWS Glue Data Catalog, and finally use Amazon Athena to query the velocity data.
8. Process drive data and perform deep signal validation.
Deploy your drive data signal validation code in Amazon Elastic Kubernetes Service (Amazon EKS). EKS is a managed service that makes it easy for you to run Kubernetes without needing to stand up or maintain your own Kubernetes control plane. Only a subset of the signals from the Rosbag or MDF4 files will be extracted for KPI calculation and aggregation which potentially reduces the stored data volume from gigabytes to megabytes.
9. Perform automated labeling using Amazon SageMaker Ground Truth.
Amazon SageMaker Ground Truth is a fully managed data labeling service that makes it easy to build highly accurate training datasets for machine learning. Ground Truth offers automatic data labeling and/or annotation which uses a machine learning model to label your data.
In addition, the service helps you create custom workflows for data labeling that leverage human workers from Amazon Mechanical Turk, the AWS Partner Network, or your own private workforce to improve the automated labeling accuracy. Ground Truth now supports 3D Point Cloud Labeling for task types like Object Detection, Object Tracking and Semantic Segmentation. This blog shows how to use the service with open data sets from Audi A2D2 and KITTI. Alternatively, customers can run a custom container on Amazon EKS for Ground Truth generation and labeling.
10. Provide a search function for particular scenarios using AWS AppSync.
Developers and data scientists can search for a particular scenario and all of the associated metadata related to it. AWS AppSync is a managed service that uses GraphQL to make it easy for applications to get data from a range of data sources such as Amazon DynamoDB, Amazon ES and AWS Lambda.
Additional Aspects to consider
- China: The collection of raw data that includes video, lidar, radar, and GPS data is defined as a controlled activity by the government (geographic information surveying and mapping). This is a regulated activity and must be done under the governance of local certified map providers with navigation surveying licenses.
- Data Encryption and Anonymization: Some ADS/ADAS use cases include sensitive or personal information. AWS Key Management Service (KMS) supports AWS KMS Keys. Vehicle Identification Numbers (VIN) can be anonymized by Amazon EMR jobs. This blog shows how to anonymize personal data like faces from the video using Amazon Rekognition.
- Exchange Data with partners: AWS Data Exchange is a service that makes it easy for AWS customers to securely exchange file-based data sets in the AWS Cloud. Providers in AWS Data Exchange have a secure, transparent, and reliable channel to reach AWS customers and grant existing customers their subscriptions more efficiently.
- Data Lake as code: AWS provides a full stack of DevOps tooling including AWS CodeCommit, AWS CodeBuild and AWS CodePipeline to simplify the provisioning and management infrastructure, to deploy application code, automate software release processes, and monitor application and infrastructure performance. Third party CI/CD tools like Jenkins and Zuul can be integrated as well.
Conclusion
In this post, we discussed the steps outlined in this Reference architecture to build an Autonomous Driving and ADAS Data Lake on AWS. We hope you found this interesting and helpful and invite your comments on the architecture.
Also, check out the Automotive issue of the AWS Architecture Monthly Magazine.