Amazon Web Services ブログ
Category: Database

AWS DMS 実装ガイド:テスト、モニタリング、SOP による耐障害性のあるデータベース移行の構築
本投稿は、Sushant Deshmukh と Alex Anto Kizhakeyyepunnil Joyと […]

株式会社リネア様の AWS 生成 AI 事例:GraphRAGで実現するサプライチェーンリスク検知と管理への取り組み
みなさん、こんにちは。AWS ソリューションアーキテクトの古屋です。 企業のESG(環境・社会・ガバナンス)へ […]
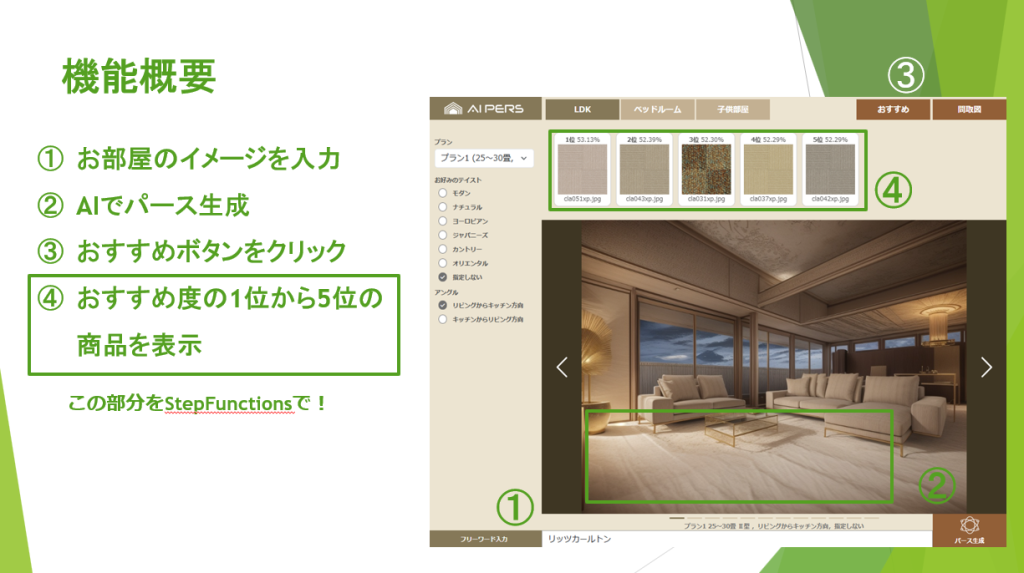
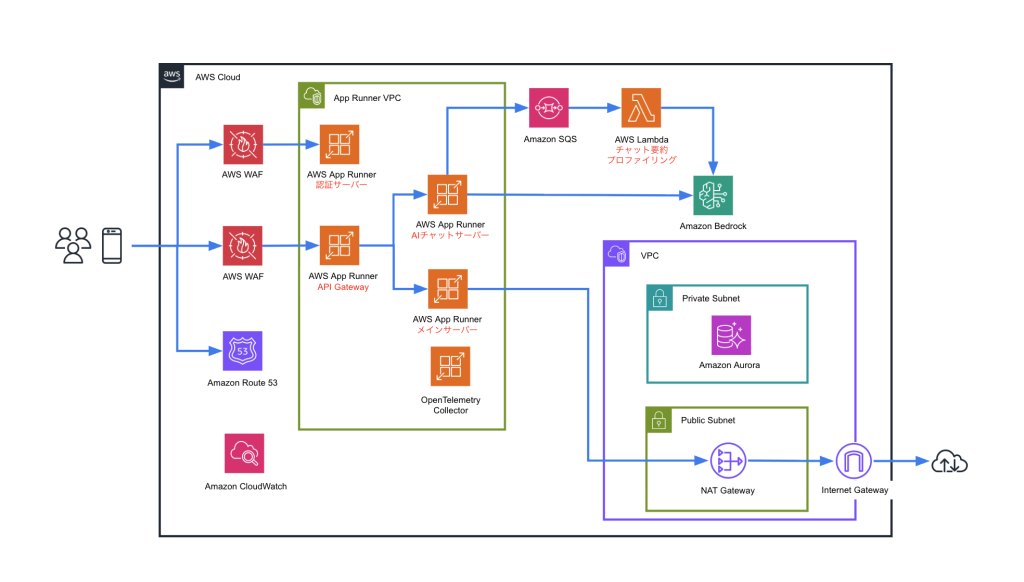
株式会社ファイン様のAWS 生成AI活用事例:建築AIパース生成サービスにレコメンドAI機能を実装。担当者の商品検索時間を75%削減し、顧客満足度も向上。
本ブログは株式会社ファイン様と Amazon Web Services Japan 合同会社が共同で執筆いたし […]

AWS DMS 3.5.4 におけるデータマスキングとパフォーマンス向上
本投稿は、Suchindranath Hegde と Mahesh Kansaraと Leonid Slepu […]

PostgreSQL のアップグレード中に AWS DMS タスクを処理するためのベストプラクティス
本投稿は、Veeramani A と Manoj Ponnurangam による記事 「Best practi […]

Amazon GameLift Servers でローンチを成功させるためのステップ:開発フェーズ
私たちはグローバルなゲームサーバーホスティングのためのフルマネージド型サービスである Amazon GameLift Servers をお勧めしています。このサービスは、オーケストレーション、グローバルなセッション配置、ゲームセッションライフサイクル管理を担うため、マルチプレイヤーゲームのローンチにおける運用作業とストレスを軽減するのに役立ちます。
このブログシリーズでは、ゲームローンチを成功させるための準備の重要な考慮事項について説明します。この最初のブログはプリプロダクションで実行すべきアクションに焦点を当て、第 2 部はプリローンチ準備 ( ローンチの 2〜3 ヶ月前 ) に焦点を当てます。これらの推奨事項は、開発初期のインテグレーションからゲームローンチまで数百のゲームスタジオをサポートした経験に基づいています。
Amazon Bedrockを活用したAWS サポート問い合わせ内容の自動集約ソリューションの実装
本稿は、JALデジタル株式会社システムマネジメント本部ハイブリッドクラウド基盤部クラウド基盤運営グループの梅本 […]
AWS Summit Japan 2025 AI健康アプリ「HugWay」を支えるAWSアーキテクチャ:テオリア・テクノロジーズの認知症プラットフォーム戦略
このブログは、テオリア・テクノロジーズ株式会社と、アマゾン ウェブ サービス ジャパン合同会社 ソリューション […]
成田空港におけるドーリー動態管理システム「DOLYS」をAWSに構築
はじめに 本稿は、日本航空株式会社デジタルEX企画部 空港オペレーショングループの橋本様よりご寄稿いただいた、 […]
【寄稿】株式会社 GEOTRA 未来の人流シミュレーションへの取組
GEOTRAは、独自の人流シミュレーションサービスの基盤としてAWSを採用し、フルマネージド型サービスを中心としたアーキテクチャを構築しています。AWS Step Functions、Amazon ECR、Amazon RDSを効果的に活用することで、GPS位置情報から「非集計トリップデータ」を安全に生成・分析しています。
AWSの採用理由は、充実したコミュニティ、サーバーレスによる運用負荷軽減などのメリットを評価いただいた。GEOTRAは、橋梁・道路建設などの影響の高精度な人流シミュレーションサービスを展開しています。