Amazon Web Services ブログ
Category: Database

Oracle ExadataをAWS Cloudに簡単に移行 – Oracle Database@AWS のご紹介
本投稿は、 Channy Yunによる記事 「Introducing Oracle Database@AWS […]

Amazon DocumentDB (with MongoDB compatibility) バージョン 3.6 の延長サポートの発表
2025 年 8 月 13 日、Amazon DocumentDB(MongoDB 互換)は、Amazon DocumentDB バージョン 3.6 が 2026 年 3 月 30 日にサポート終了を迎えることを発表しました。2026 年 3 月 31 日以降も、Amazon DocumentDB バージョン 3.6 は延長サポートで引き続き利用できます。延長サポートでは、Amazon DocumentDB バージョン 3.6 の標準サポート終了後 3 年間にわたり、重大なセキュリティ問題やバグに対する修正をパッチリリースとして提供します。

Amazon DocumentDB 3.6 を 5.0 にニアゼロダウンタイムでアップグレードする
Amazon DocumentDB (with MongoDB compatibility) は、エンタープライズワークロードのスケーリングのために設計された、フルマネージド型のネイティブJSONデータベースです。MongoDB API 3.6、4.0、および5.0と同じアプリケーションコード、ドライバー、ツールを使用して、基盤となるインフラストラクチャの管理を心配することなく、Amazon DocumentDB上でワークロードの実行、管理、スケーリングを行うことができます。ドキュメント指向データベースとして、Amazon DocumentDBはJSONデータの保存、クエリ、およびインデックス作成を簡単に行えます。Amazon DocumentDB バージョン5.0では、バージョン3.6および4.0からバージョン5.0へのメジャーバージョンアップグレードを実行できるようになり、ベクトル検索、I/O最適化ストレージ、ドキュメント圧縮、テキスト検索、部分インデックスなどの最新機能を活用できます。この記事では、インプレースメジャーバージョンアップグレードとAmazon DocumentDBボリュームクローニングを使用して、Amazon DocumentDB 3.6から5.0へのニアゼロダウンタイムでのアップグレード方法を探ります。

AWSは DocumentDB プロジェクトに参画し、相互運用可能なオープンソースドキュメントデータベース技術を開発します
AWS が Linux Foundation 管理下の DocumentDB オープンソースプロジェクトへの参加を発表しました。このプロジェクトは Microsoft が立ち上げ、現在は Linux Foundation に移管され、PostgreSQL ベースの MongoDB 互換ドキュメントデータベースを提供します。AWS の参加理由は主に三つあります。まず MongoDB API との完全互換性を目指すことで、どの環境でも同じ互換性とパフォーマンスを提供できること。次に Microsoft や Yugabyte など複数の企業が参加することで、オープンソースによるイノベーションが加速すること。そして PostgreSQL を基盤としており、AWS の PostgreSQL コミュニティへの豊富な貢献経験を活かせることです。なお、同名ながら Amazon DocumentDB と Linux Foundation の DocumentDB プロジェクトは内部構造が異なりますが、AWS は両方に継続投資する方針です。Amazon DocumentDB のイノベーションをオープンソースプロジェクトに貢献し、同時にオープンソース版の機能をマネージドサービスに取り入れていくことで、お客様にさらなる選択肢と価値を提供していきます。

AWS Weekly Roundup: Amazon EC2、Amazon Q Developer、IPv6 更新など (2025 年 9 月 1 日)
9 月 1 日週の私の LinkedIn フィードは、シアトルで開催された AWS Heroes Summit […]
ニフティ株式会社、Oracle Database Enterprise Edition からAmazon Aurora PostgreSQLへの移行によりメンテナンス時の対応コストを50%削減
ニフティ株式会社は、基幹ポイントサービス「ニフティポイントクラブ」をOracle DatabaseからAurora PostgreSQLへ移行しました。本ブログでは、をOracle Database Enterprise EditionからAurora PostgreSQLへ移行した際のエピソードについてご紹介します。

AWS Weekly Roundup: Amazon Aurora 10 周年記念、Amazon EC2 R8 インスタンス、Amazon Bedrock など (2025 年 8 月 25 日)
8 月 25 日週の Weekly Roundup の準備をしながら、過去 10 年間にデータベーステクノロジ […]
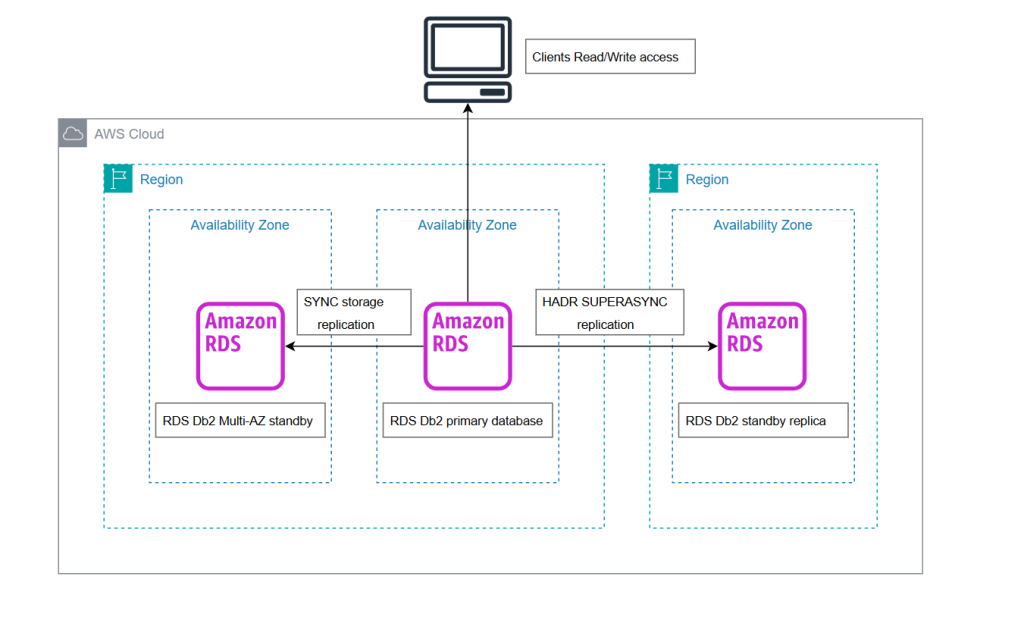
クロスリージョンのスタンバイレプリカによるAmazon RDS for Db2の高可用性と高速な災対切り替えの実現
この投稿では、RDS for Db2 インスタンスのスタンバイレプリカを構成する方法をご紹介します。
また、スタンバイレプリカのセットアップ、モニタリング、管理に関するベストプラクティスについても説明します。
この機能を使用することで、RDS for Db2 インスタンスを設定して、別のリージョンにスタンバイレプリカを保持することができます。

Amazon Aurora DSQL のセキュリティ対策:アクセス制御のベストプラクティス
本記事は、2025 年 8 月 15 日に公開された Securing Amazon Aurora DSQL: […]

Amazon ElastiCache for Redis OSS バージョン 4 および 5 の延長サポートの紹介
Amazon ElastiCache が Redis OSS バージョン 4 および 5 に対する Extended Support(延長サポート)を発表しました。Redis OSS v4 と v5 は 2020 年と 2022 年にコミュニティのサポート終了を迎えましたが、ElastiCache は顧客が自分のペースでアップグレードできるよう引き続きサポートしてきました。標準サポートは 2026 年 1 月 31 日に終了しますが、新たに提供される Extended Support により、2029 年 1 月 31 日まで重要なセキュリティアップデート、バグ修正、継続的なサポートを受けることができます。2026 年 2 月 1 日以降、アップグレードされていない Redis OSS v4 および v5 クラスターは、継続的な可用性とセキュリティを確保するため、自動的に Extended Support に登録されます。AWS は標準サポート終了を計画のマイルストーンとして捉え、Redis OSS v4 および v5 クラスターを ElastiCache for Valkey または Redis OSS v6 以降にアップグレードすることを強く推奨しています。アップグレードには Modify API または Service Update API を使用でき、既存のエンドポイントとクラスター構成を維持したままバージョン移行が可能です。