Amazon Web Services ブログ
Category: Database
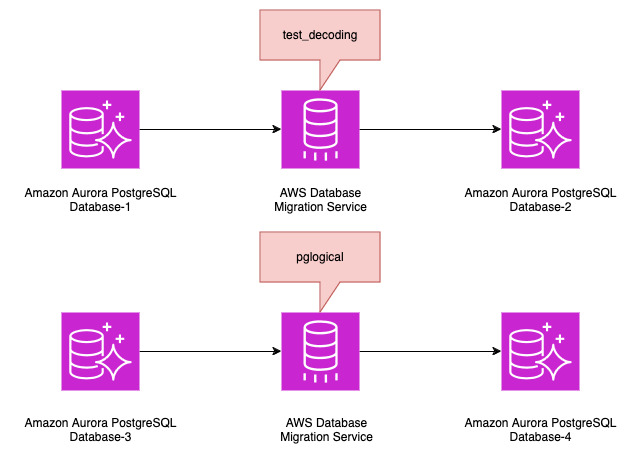
Amazon Aurora PostgreSQL での AWS DMS を使用したデータ移行における test_decoding プラグインと pglogical プラグインの比較
この記事は、”Comparison of test_decoding and pglogical […]

AWS DMS データ検証:カスタムサーバーレスアーキテクチャ
本投稿は、Anil Malakar と Mahesh Kansara と Prabodh Pawar による記 […]

AWS DMS Schema Conversion CLI を使用したデータベースの評価と移行
本投稿は、 Nelly Susanto による記事 「Assess and migrate your data […]

AWS DMS によるリアルタイムでの Iceberg の取り込み
本投稿は、 Caius Brindescu と Mahesh Kansara による記事 「Real-time […]

2025 年 10 月の AWS Black Belt オンラインセミナー資料及び動画公開のご案内
2025 年 10 月に公開された AWS Black Belt オンラインセミナーの資料及び動画についてご案内させて頂きます。

【開催報告 & 資料公開】AWS 秋の Cost Optimization 祭り 2025
「AWS 秋の Cost Optimization 祭り 2025」は、コスト最適化の最新アップデートやメソッド、生成 AI ×コスト最適化を学ぶイベントです。本ブログでは、イベント内容概要の紹介とイベントの中で各登壇者が発表した資料を公開いたします。

【寄稿】 株式会社ジャパン・インフォレックス様 : 食品業界最大の商品マスター刷新事例と、AI 時代の新たな価値創造を支えるシステムリフォーム
株式会社ジャパン・インフォレックス(以下、ジャパン・インフォレックス)は、食品業界のメーカーと卸売り等の取引先の間に立つ企業である。同社は240 万件を超える商品マスターを業界標準に基づき一元管理して提供する業界最大のデータベースセンターを保持している。このデータベースは、8,000 社超のメーカーが直接登録するデータと、大手食品卸が代行登録する共有データの 2 種類のデータで構成されている。ジャパン・インフォレックスは、食品卸売業の商品マスターセンターとして業界の標準化と合理化に貢献し、流通 BMS (流通ビジネスメッセージ標準) に準拠した共通 EDI システムで流通デジタル化の推進を担っている。本ブログではジャパン・インフォレックスが実施した商品マスター刷新事例の概要と、その中でどのように AWS が活用されているかを紹介する。

Amazon RDS for SQL Server のプロアクティブ監視をリアルタイム Slack 通知で実現
データベース監視は堅牢なアプリケーション維持に不可欠であり、モダンな監視ソリューションによってプロアクティブな問題検出と迅速な対応が可能になります。これにより従来の手動ログチェックや断片化されたツールの課題を解決し、自動化されたリアルタイム通知システムにより応答時間短縮とダウンタイム最小化を実現します。この投稿では、AWS ネイティブサービスと Slack 統合を使用して、Amazon RDS for SQL Server の効率的なサーバーレス監視システムを構築する方法を示します。

Amazon RDS for PostgreSQL および Amazon Aurora PostgreSQL データベース向け AI 搭載チューニングツール: PI Reporter
AWS では、Amazon Relational Database Service (Amazon RDS) […]

AWS DMS 拡張モニタリングを使用したリソース配分とパフォーマンス分析を理解する
本投稿は、Suchindranath Hegde と Mahesh Kansara と Balaji Bask […]