Amazon Web Services ブログ
Category: Database

Amazon DynamoDB のグローバルセカンダリインデックスにおけるマルチキーサポート
本ブログでは、Amazon DynamoDB のグローバルセカンダリインデックス(GSI)における複合キーの新機能についてご紹介します。これまで最大2つだった属性が、パーティションキーとソートキーそれぞれ最大4つ、合計8つまで指定できるようになりました。この機能により、従来アプリケーション側で属性を連結して複合キーを作成していた回避策が不要になり、データモデルの設計がシンプルになります。注文ダッシュボードの実装例を通じて、ステータス・日付・金額など複数の条件を組み合わせた効率的なクエリ方法や、大規模トラフィックに対応するシャーディング手法を学べます。

Amazon DynamoDB Data Model Validation Tool でデータモデリング精度の向上させる
本ブログでは、Amazon DynamoDB のデータモデル検証ツールについてご紹介します。このツールは DynamoDB MCP サーバーの新機能で、設計したデータモデルを DynamoDB local 環境で自動的にテストし、すべてのアクセスパターンが正しく動作するまで反復的に改善します。Amazon Q Developer や Amazon Bedrock と連携することで、データモデリングの設計・テスト・改善サイクルを大幅に効率化できます。従来の手動検証プロセスを自動化し、実用的で検証済みのスキーマを短時間で作成する方法を学べます。
AWS Transform がフルスタック Windows モダナイゼーション機能を発表
2025 年の 5 月、.NET アプリケーションを大規模にモダナイズするための初のエージェント型 AI サー […]

株式会社アーベルソフト様の AWS 事例「社内システムをオンプレミスから AWS へ 2 週間で移行、運用工数の 9 割以上を削減」のご紹介
本ブログは 株式会社アーベルソフト 様と Amazon Web Services Japan 合同会社が共同で […]
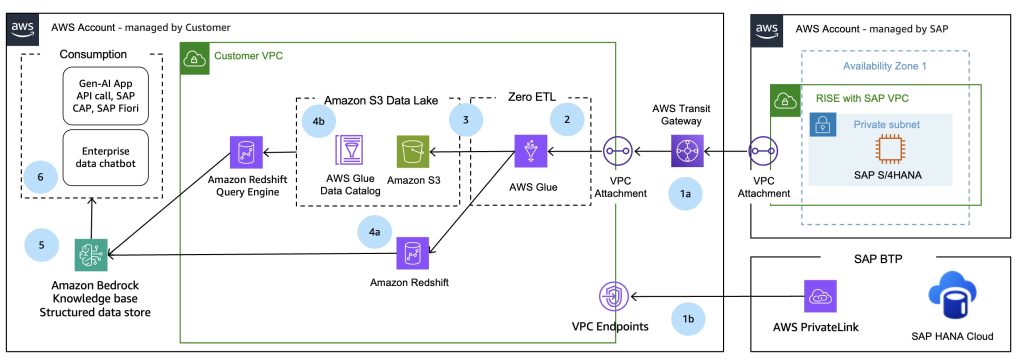
Amazon Bedrock Knowledge BasesでSAPおよびエンタープライズデータから新たな可能性を解き放つ
生成AI(Generative AI)の力とエンタープライズデータインテリジェンスを組み合わせた新しいソリューションを見てみましょう。この記事では、Amazon Bedrock Knowledge Basesが組織のSAPおよびエンタープライズデータの活用方法をどのように革新し、イノベーション、効率性、戦略的意思決定のための新たな可能性を創出しているかを探ります。自然言語クエリから自動化されたドキュメント処理、インテリジェントなインサイト生成まで、このソリューションが企業のSAP投資をAI時代の戦略的資産に変革する方法をご紹介します。

AWS Database Migration Service で PostgreSQL のテーブルをグループ毎にタスク化
本投稿は、 Manojit Saha Sardar と Chirantan Pandya による記事 「Gro […]

大容量テーブルの継続的レプリケーションを、AWS DMS の列フィルターによる並列化でパフォーマンス向上
本投稿は、Vanshika Nigam による記事 「Improve AWS DMS continuous r […]

AWS Weekly Roundup: AWS re:Invent 2025 の参加方法、Kiro GA、多くのリリース (2025 年 11 月 24 日)
2025 年 12 月 1 週は、AWS の最新ニュース、専門家によるインサイト、グローバルなクラウドコミュニ […]

グラフデータを使用した Network Digital Twin と Agentic AI を活用した被疑箇所の特定
本記事は 2025 年 8 月 18 日に公開された Beyond Correlation: Finding […]
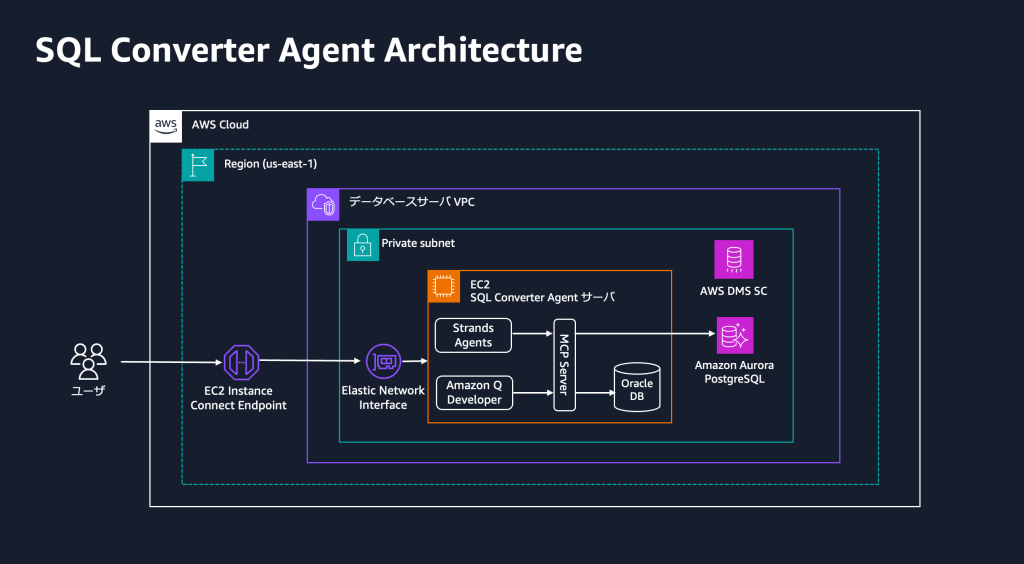
Oracle Database から Amazon Aurora PostgreSQL への移行を加速する生成 AI エージェント
本ブログは三菱電機ビルソリューションズ株式会社様と Amazon Web Services Japan 合同会 […]