Amazon Web Services ブログ
新規 – 生成系 AI および HPC アプリケーションを加速するための NVIDIA H100 Tensor Core GPU を搭載した Amazon EC2 P5 インスタンス
2023 年 3 月、AWS と NVIDIA は、複雑さを増す大規模言語モデル (LLM) のトレーニングと生成系 AI アプリケーションの開発用に最適化された、最もスケーラブルでオンデマンドの人工知能 (AI) インフラストラクチャの構築に焦点を当てたマルチパートコラボレーションを発表しました。
NVIDIA H100 Tensor Core GPU と AWS の最新のネットワーキングとスケーラビリティを搭載した Amazon Elastic Compute Cloud (Amazon EC2) P5 インスタンスを事前に発表しました。これにより、最大規模の機械学習 (ML) モデルの構築とトレーニングにおいて最大 20 エクサフロップスのコンピューティングパフォーマンスが実現されます。この発表は、AWS と NVIDIA が 10 年以上にわたって協力してきた成果であり、クラスター GPU (cg1) インスタンス (2010)、G2 (2013)、P2 (2016)、P3 (2017)、G3 (2017)、P3dn (2018)、G4 (2019)、P4 (2020)、G5 (2021)、および P4de インスタンス (2022) 全体でビジュアルコンピューティング、AI、およびハイパフォーマンスコンピューティング (HPC) クラスターを提供しています。
最も注目すべきは、ML モデルのサイズが現在何兆ものパラメータに達していることです。しかし、この複雑さのために顧客のトレーニング時間が長くなり、最新の LLM が数か月にわたってトレーニングされるようになっています。HPC の顧客も同様の傾向を示しています。HPC の顧客データ収集の忠実度が高まり、データセットがエクサバイト規模に達するにつれて、顧客はますます複雑化するアプリケーション全体でソリューションまでの時間を短縮できる方法を求めています。
EC2 P5 インスタンスの紹介
7月26日、Amazon EC2 P5 インスタンスが一般提供されることを発表しました。これは、AI/ML および HPC ワークロードにおける高いパフォーマンスとスケーラビリティに対するお客様のニーズに応える次世代 GPU インスタンスです。P5 インスタンスは最新の NVIDIA H100 Tensor Core GPU を搭載しており、前世代の GPU ベースのインスタンスと比較して、トレーニング時間を最大 6 倍 (数日から数時間に) 短縮できます。このパフォーマンスの向上により、お客様はトレーニングコストを最大 40% 削減できます。
P5 インスタンスには、640 GB の高帯域幅 GPU メモリ、第 3 世代 AMD EPYC プロセッサ、2 TB のシステムメモリ、および 30 TB のローカル NVMe ストレージを備えた 8 基の NVIDIA H100 Tensor Core GPU が搭載されています。また、P5 インスタンスは GPUDirect RDMA をサポートし、3200 Gbps の総ネットワーク帯域幅を提供します。これにより、ノード間通信で CPU をバイパスすることで、レイテンシーを低減し、パフォーマンスを効率的にスケールアウトできます。
これらのインスタンスの仕様は次のとおりです。
| インスタンス
サイズ |
vCPU | メモリ
(GiB) |
GPUs
(H100) |
ネットワーク帯域幅
(Gbps) |
EBS 帯域幅
(Gbps) |
ローカルストレージ
(TB) |
| P5.48xlarge | 192 | 2048 | 8 | 3200 | 80 | 8 x 3.84 |
P5 インスタンスと NVIDIA H100 Tensor Core GPU が以前のインスタンスとプロセッサとどのように比較されるかを示す簡単なインフォグラフィックを次に示します:
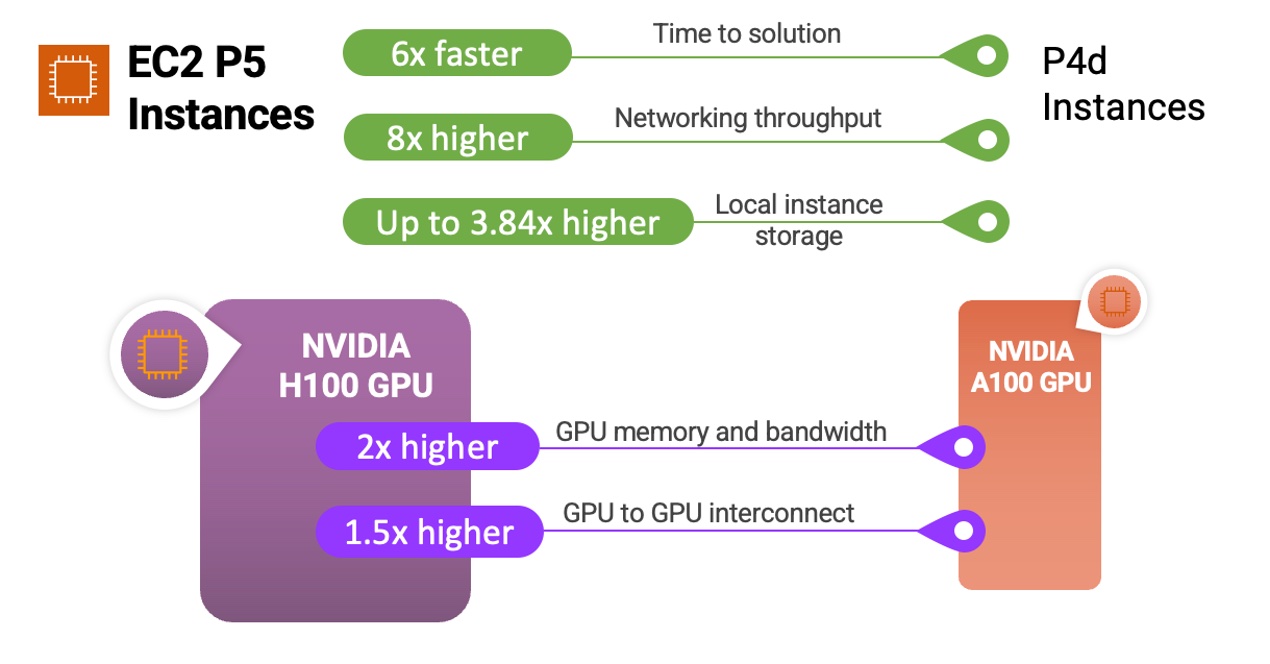
P5 インスタンスは、質問応答、コード生成、動画と画像の生成、音声認識など、最も要求が厳しく計算量の多い生成系 AI アプリケーションの背後で複雑さを増している LLM やコンピュータビジョンモデルのトレーニングと推論の実行に最適です。P5 では、これらのアプリケーション全体で、前世代の GPU ベースのインスタンスと比較して、トレーニングにかかる時間が最大 6 倍短くなります。トランスフォーマーモデルのバックボーンを使用する多くの言語モデルで一般的な、低精度の FP8 データ型をワークロードで使用できるお客様は、NVIDIA トランスフォーマーエンジンのサポートを通じてパフォーマンスが最大 6 倍向上するというさらなるメリットが得られます。
P5 インスタンスを使用している HPC のお客様は、医薬品の発見、耐震分析、天気予報、財務モデリングなど、要求の厳しいアプリケーションをより大規模にデプロイできます。ゲノムシーケンシングや高速データ分析などのアプリケーションにダイナミックプログラミング (DP) アルゴリズムを使用しているお客様は、新しい DPX 命令セットのサポートを通じて P5 のさらなるメリットも得られます。
これにより、お客様は、以前は到達できないと思われた問題領域を探索し、より迅速にソリューションを繰り返して行い、よりすばやく市場に投入することができます。
インスタンスの仕様の詳細および p4d.24xlarge と新しい p5.48xlarge のインスタンスタイプの比較を以下に示します。
| 機能 | p4d.24xlarge | p5.48xlarge | 比較 |
| アクセラレータの数とタイプ | 8 x NVIDIA A100 | 8 x NVIDIA H100 | – |
| サーバーあたり FP8 テラフロップス | – | 16,000 | 640% 対 100 FP 16 |
| サーバーあたり FP16 テラフロップス | 2,496 | 8,000 | |
| GPU メモリ | 40 GB | 80 GB | 200% |
| GPU メモリ帯域幅 | 12.8 TB/秒 | 26.8 TB/秒 | 200% |
| CPU ファミリー | インテルカスケードレイク | AMD Milan | – |
| vCPU | 96 | 192 | 200% |
| 合計システムメモリ | 1152 GB | 2048 GB | 200% |
| ネットワークスループット | 400 Gbps | 3200 Gbps | 800% |
| EBS スループット | 19 Gbps | 80 Gbps | 400% |
| ローカルインスタンスストレージ | 8 TB NVMe | 30 TB NVMe | 375% |
| GPU から GPU への相互接続 | 600 GB/秒 | 900 GB/秒 | 150% |
第 2 世代の Amazon EC2 UltraClusters と Elastic Fabric Adaptor
P5 インスタンスは、マルチノード分散トレーニングおよび緊密に結合された HPC ワークロードに対して、市場をリードするスケールアウト機能を提供します。第 2 世代の Elastic Fabric Adaptor (EFA) テクノロジーを使用して最大 3,200 Gbps のネットワークを実現しており、これは P4d インスタンスと比較して 8 倍です。
大規模で低レイテンシーを求めるお客様のニーズに応えるため、P5 インスタンスは第 2 世代 EC2 UltraCluster にデプロイされています。これにより、最大 20,000 基以上の NVIDIA H100 Tensor Core GPU でより低いレイテンシーを実現できるようになりました。クラウドで最大規模の ML インフラストラクチャを提供する EC2 UltraClusters の P5 インスタンスは、合計で最大 20 エクサフロップスのコンピューティング機能を提供します。

EC2 UltraClusters は Amazon FSx for Lustre を使用しています。これは、最も人気の高い高性能並列ファイルシステム上に構築されたフルマネージド共有ストレージです。FSx for Lustre を使用すると、大量のデータセットをオンデマンドで大規模にすばやく処理し、ミリ秒未満のレイテンシーを実現できます。FSx for Lustre の低レイテンシーで高スループットの特性は、EC2 UltraClusters 上の深層学習、生成系 AI、および HPC ワークロード向けに最適化されています。
FSx for Lustre は、EC2 UltraClusters 内の GPU と ML アクセラレータにデータを供給し続け、最も要求の厳しいワークロードを加速します。これらのワークロードには、LLM トレーニング、生成系 AI 推論、およびゲノミクスや財務リスクモデリングなどの HPC ワークロードが含まれます。
EC2 P5 インスタンスの使用を開始する
開始するには、米国東部 (バージニア北部) と米国西部 (オレゴン) リージョンの P5 インスタンスを使用できます。
P5 インスタンスを起動するときは、P5 インスタンスをサポートするために AWS Deep Learning AMI (DLAMI) を選択します。DLAMI は、ML の専門家や研究者に、事前設定された環境でスケーラブルで安全な分散型 ML アプリケーションをすばやく構築するためのインフラストラクチャとツールを提供します。
Amazon Elastic Container Service (Amazon ECS) または Amazon Elastic Kubernetes Service (Amazon EKS) のライブラリを使用して、AWS 深層学習コンテナを用いて P5 インスタンスでコンテナ化されたアプリケーションを実行できるようになります。 より管理されたエクスペリエンスのために、Amazon SageMaker 経由の P5 インスタンスを使用することもできます。これにより、開発者やデータサイエンティストは、クラスターやデータパイプラインの設定を気にすることなく、数十、数百、数千の GPU に簡単にスケーリングして、規模を問わずモデルを迅速にトレーニングできます。HPC をご利用のお客様は、AWS Batch と ParallelCluster を P5 と組み合わせて活用することで、ジョブとクラスターを効率的にオーケストレーションすることができます。
既存の P4 のお客様は、P5 インスタンスを使用するように AMI を更新する必要があります。具体的には、NVIDIA H100 Tensor Core GPU をサポートする最新の NVIDIA ドライバーを含むように AMI を更新する必要があります。また、最新の CUDA バージョン (CUDA 12)、CuDNN バージョン、フレームワークバージョン (PyTorch、Tensorflow など)、およびトポロジーファイルが更新された EFA ドライバーをインストールする必要があります。このプロセスを簡単にするために、P5 インスタンスをすぐに使用するために必要なすべてのソフトウェアとフレームワークが事前にパッケージ化された新しい DLAMI と深層学習コンテナが提供されます。
今すぐご利用いただけます
Amazon EC2 P5 インスタンスは、米国東部 (バージニア北部) と米国西部 (オレゴン) のAWS リージョンで本日よりご利用いただけます。詳細については、Amazon EC2 の料金ページを参照してください。詳細については、P5 インスタンスページにアクセスして AWS re:Post for EC2 を調べるか、通常の AWS サポートの連絡先を通じてご連絡ください。
生成系 AI が組み込まれたさまざまな AWS のサービスを選択できます。これらはすべて、生成系 AI 用の最もコスト効率の高いクラウドインフラストラクチャ上で実行されます。詳細については、AWS での生成系 AI にアクセスして、イノベーションを加速し、アプリケーションを再発明してください。
— Channy
原文はこちらです。